目录
- 一、【SPPELAN】模块
- 1.1【SPPELAN】模块介绍
- 1.2【SPPELAN】核心代码
- 二、添加【SPPELAN】模块
- 2.1STEP1
- 2.2STEP2
- 2.3STEP3
- 2.4STEP4
- 三、yaml文件与运行
- 3.1yaml文件
- 3.2运行成功截图
一、【SPPELAN】模块
1.1【SPPELAN】模块介绍

下图是【SPPELAN】的结构图,让我们简单分析一下运行过程和优势
处理过程:
- 分割与传递(Transition and Split):
- 首先,输入经过 Transition 模块,进行数据的转换和处理。接着,特征会被 Split(分割),将特征图分成多个部分进行独立处理。这一步将大的计算任务分散到多个独立的分支中进行处理,提升并行处理能力。
- 并行块(Parallel Blocks):
- 分割后的每个特征部分被送入不同的 Block 模块进行处理。每个 block 可以表示任意的计算模块(如卷积、注意力模块等),通过并行计算提高处理效率。图中显示了多个重复的 block,并且可以将特征多次传递给下一个 block 以提升特征提取的深度。
- 拼接(Concatenation):
- 多个 block 处理后的特征经过一个 Concatenation(拼接) 操作,将所有的并行分支的特征重新整合起来。这一步将之前独立处理的特征重新组合成统一的特征图,使得各个 block 提取到的信息能够相互补充。
- 最终传递(Final Transition):
- 最后,经过另一个 Transition 模块,将拼接后的特征进行最终处理,生成输出。这一步可以进行进一步的特征处理或降维操作,以便于后续网络层使用。
优势: - 并行计算加速:
- GELAN 模块通过将输入特征分割成多个部分并行处理,显著减少了计算时间,尤其在处理大规模数据时。这种分布式计算方式提高了整体效率,使得网络在计算复杂度上得到了优化。
- 增强特征表达:
- 不同的并行 block 可以处理特征的不同方面,使得模型能够从多维度、多尺度捕捉信息。通过整合这些特征,模型对输入数据的理解更加全面,有助于提升任务的准确性。
- 模块化设计的灵活性:
- 由于每个 block 可以是任意的计算模块,GELAN 具有很大的灵活性,可以适应不同的任务需求。例如,block 可以是卷积模块、注意力模块或其他特征提取单元,网络架构的可配置性大大提高。
- 特征信息的充分利用:
- 拼接操作确保了每个分支提取到的特征不会丢失,各个并行分支提取的特征能够相互补充和结合,从而充分利用了每个部分的信息。这一设计有助于提升模型的性能,特别是处理复杂场景或多类别任务时。

1.2【SPPELAN】核心代码
import torch
import torch.nn as nn
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class SP(nn.Module):
def __init__(self, k=3, s=1):
super(SP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=s, padding=k // 2)
def forward(self, x):
return self.m(x)
class SPPELAN(nn.Module):
# spp-elan
def __init__(self, c1, c2, c3): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = c3
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = SP(5)
self.cv3 = SP(5)
self.cv4 = SP(5)
self.cv5 = Conv(4 * c3, c2, 1, 1)
def forward(self, x):
y = [self.cv1(x)]
y.extend(m(y[-1]) for m in [self.cv2, self.cv3, self.cv4])
return self.cv5(torch.cat(y, 1))
二、添加【SPPELAN】模块
2.1STEP1
首先找到ultralytics/nn文件路径下新建一个Add-module的python文件包【这里注意一定是python文件包,新建后会自动生成_init_.py】,如果已经跟着我的教程建立过一次了可以省略此步骤,随后新建一个SPPELAN.py文件并将上文中提到的注意力机制的代码全部粘贴到此文件中,如下图所示
2.2STEP2
在STEP1中新建的_init_.py文件中导入增加改进模块的代码包如下图所示
2.3STEP3
找到ultralytics/nn文件夹中的task.py文件,在其中按照下图添加
2.4STEP4
定位到ultralytics/nn文件夹中的task.py文件中的def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)函数添加如图代码,【如果不好定位可以直接ctrl+f搜索定位】

三、yaml文件与运行
3.1yaml文件
以下是添加【SPPELAN】模块替换SPPF的yaml文件
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128,3,2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256,3,2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512,3,2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024,3,2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPELAN, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
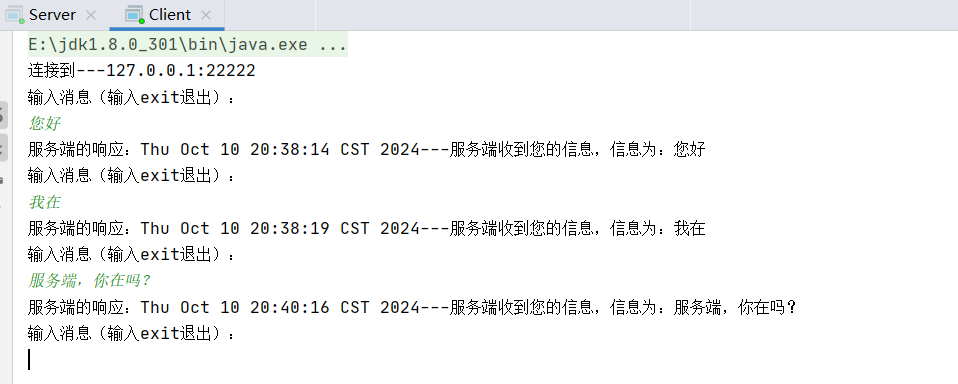
3.2运行成功截图

OK 以上就是添加【SPPELAN】模块的全部过程了,后续将持续更新尽情期待