视觉-语言模型(Vision-Language Models, VLMs)领域正迅速发展,但在数据、架构和训练方法等关键方面还未达成共识。本文旨在为构建VLM提供指南,概述当前的最先进方法,指出各自的优缺点,解决该领域的主要挑战,并为未被充分探索的研究领域提供有前途的研究方向。
Abs:https://www.arxiv.org/pdf/2408.12637
主要贡献
-
• 系统性综述:提供了对当前最先进VLM方法的全面概述,探讨了不同方法的优缺点,提出了未来的研究方向。
-
• 实践指导:详细阐述了构建Idefics3-8B模型的实际步骤,这是一种强大的VLM,显著优于其前身Idefics2-8B。
-
• 数据集贡献:创建了Docmatix数据集,用于提升文档理解能力。该数据集包含240倍于之前开放数据集的规模,共计2.4百万张图片和9.5百万对问答对,从1.3百万个PDF文档中衍生而来。
-
• 模型与数据集共享:公开了训练所用的模型和数据集,以促进社区研究和应用。
对现有技术的讨论
如何连接语言预训练模型
- • 交叉注意力架构
交叉注意力架构由Flamingo引入。视觉骨干编码的图像隐藏状态用于条件化冻结的语言模型,通过新初始化的交叉注意力层,这些层在预训练语言模型层之间交错插入。这些层中的键和值来自视觉特征,而查询来自语言输入。实践中,在LLM的每四个Transformer块之后插入一个交叉注意力块,新增的参数量大约为LLM大小的1/4。这显著增加了模型的表达能力,使其在训练期间无需解冻LLM便能取得强大性能,同时保留了预训练LLM在仅文本任务上的性能。
- • 自注意力架构
在自注意力架构(或完全自回归架构)中,视觉编码器的输出被视为tokens并与文本tokens序列连接。整个序列然后作为输入传递给语言模型。视觉tokens序列可以选择性地池化为更短的序列,提高模型在训练和推理过程中的效率。将视觉隐藏空间映射到文本隐藏空间的层被称为模态投影层。
- • 哪种架构表现最好?
研究表明,当保持骨干网络冻结时,交叉注意力架构表现显著优于自注意力架构。然而,当部分视觉编码器和语言模型使用LoRA进行训练时,尽管交叉注意力架构的参数更多,其性能反而较差。
- • 预训练骨干网络对性能的影响
研究发现,每个独立的单模态预训练骨干网络的性能与最终VLM的性能相关。例如,将LLaMA-1-7B替换为Mistral-7B,或将CLIP-ViT-H替换为SigLIP-SO400M,均显著提高了各项基准测试的性能。由于视觉编码器通常在不同的数据集上进行训练并针对各种任务进行优化,一些模型结合了多个编码器的表示,以创建更丰富的视觉嵌入序列,尽管这会牺牲计算效率。
其他架构选择的探讨
- • 视觉编码器是否真的必要?
一些方法如Fuyu,直接将图像补丁输入语言模型,并通过简单的线性投影调整维度。这种架构独立于其他预训练模型,并保留了原始图像的所有信息。然而,这种方法尚未在基准测试中表现出更好的性能。
- • 如何将视觉编码器连接到语言模型?
许多模型使用简单的线性层连接视觉编码器和LLM,但这会导致视觉tokens序列较长,降低训练和推理效率。为解决这一问题,一些模型使用交叉注意力模块来减少视觉tokens的数量。尽管感知重采样器的方法在计算效率上有优势,但一些研究建议更有效地利用图像的二维结构。
- • 图像分割策略:增加视觉tokens数量的技巧
图像分割策略将原始图像分割成多个子图像,每个子图像分别由视觉编码器编码。这种方法在推理过程中具有灵活性,可以根据任务需求调整视觉tokens的数量。然而,这种方法可能会丢失全局上下文,为此可以将缩小比例的原始图像添加到子图像列表中。
多阶段训练数据的实验发现
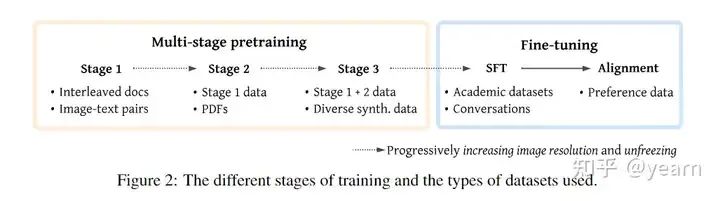
- • 多阶段预训练 多阶段预训练的主要目标是对齐骨干模型并训练模型中新初始化的参数。通过使用大规模数据集,使VLM接触到各种示例,以构建广泛的知识并提高对域外数据的鲁棒性。为了保持LLM的初始性能,一些模型如VILA和LLaVA-NeXT在训练开始时冻结骨干模型,仅关注新初始化的参数(连接器),直到达到令人满意的性能水平。此后,可以逐渐解冻视觉编码器和/或语言模型。如果出现不稳定性,或需要在增加正则化的同时增强模型的表现力,可以在预训练阶段使用LoRA方法。
在大量图像上高效训练时,图像分辨率通常保持较低,并随着训练时间逐步增加。一旦分辨率足够高,包含大图像的数据集(如PDF)可以被纳入训练数据。
- • 图像-文本对
图像-文本对数据集通常通过抓取网页、下载图像并从原始HTML文件中提取相应的alt文本来创建。由于收集这些原始图像-文本对的方便性及其在图像与文本之间建立强对齐方面的有效性,已经创建了许多大规模数据集,如LAION、COYO和DataComp。然而,这些数据集中的alt文本通常是噪声、不合语法或过于简短的,导致训练困难。最近的方法通过使用合成重标注获得了更好的结果,即使用另一个模型对原始数据集中的相同图像重新标注。
- • 交错的图像-文本文档
交错的图像-文本文档训练首次在Flamingo中引入,使用的是专有的M3W数据集。OBELICS是一个开源的交错图像-文本文档数据集,包含141 million个文档和353 million张图像。该数据集是从Common Crawl的HTML文件中过滤构建的。这些文档保持了图像和文本在网站上出现的原始线性顺序,同时去除了垃圾邮件和广告。
- • PDF文档
两个主要的PDF文档数据集是OCR-IDL和PDFA。OCR-IDL包括26M页工业文档,而PDFA的英语过滤版包含18M页来自Common Crawl的文档,提供了比OCR-IDL更大的多样性。这两个数据集通过OCR工具获得对应的文本及其在文档中的位置,可以线性化为完整的文档转录。
- • 微调
类似于LLM的常见方法,微调通常分为两个阶段:监督微调(SFT)和对齐阶段。
- • 监督微调(SFT)
文献中提供了许多高质量的数据集,包含多样的图像并涵盖广泛的任务。这些数据集通常由人工注释,确保了准确的QA对。尽管它们大多相对较小,但结合起来为有效的SFT提供了足够的示例。
- • 对齐阶段
在监督微调之后包括对齐阶段有几个原因。首先是使模型的输出与人类偏好对齐,使其更直观并更善于遵循复杂指令。此外,这一阶段有效地减少了幻觉现象,即模型可能描述图像中实际上不存在的对象或细节。它还通过减少生成有害内容的风险来提高模型的安全性,并可能进一步提高整体模型性能。
例如,RLAIF-V提供了80K对偏好对,用于MiniCPM-V 2.5的训练。VLFeedback提供了380K对比较对,其中从12个VLM中采样的模型响应由GPT-4V进行排名。类似地,SPA-VL通过类似的方法生成了100K对偏好对。在对齐阶段通常应用DPO来处理这些数据集。
当前评估VLM的挑战
开放式和多选题基准测试
早期和最流行的多模态基准测试,如VQAv2、OKVQA、TextVQA和COCO Captioning,主要是开放式的。这些基准测试依赖于每个问题的特定真实答案,因此即使是模型回答中的细微变化也可能导致得分被标记为不正确。这种评估方法倾向于有利于生成答案与基准测试预期格式或写作风格密切对齐的模型。例如,VQAv2通常期望简短的答案,通常只有一到两个词。即使评估提示明确规定了这种格式,像Gemini 1.0 Ultra和GPT-4V这样的模型的得分分别为77.8和77.2,显著低于一些在其微调数据中包含小部分VQAv2的小模型。这种差异突出了在不让基准测试模板影响结果的情况下评估不同模型的挑战。
为了减轻这种偏差,可以进行少量示例评估,尽管这种方法不如在基准测试训练集上训练有效,目前也不用于评估指令模型。然而,这些评估中的模糊程度可以因基准测试而异。例如,TextVQA和DocVQA要求模型直接从图像中读取和提取文本而不重新措辞,从而减少了模糊性。在MathVista中,答案始终是数值的,每个问题都有特定的说明,如答案应为整数或四舍五入至两位小数。
最近提出的LAVE指标通过问LLM评估VLM生成的响应是否正确,给定真实答案和具体问题,从而减少了模板问题。减少模糊性的另一种方法是使用包含选择题的基准测试,模型通过选择相应的字母来选择正确选项。许多最近的基准测试采用了这种方法,如MMMU、MMStar和MMBench。
预训练阶段模型评估的挑战
VLM在预训练阶段与微调后性能之间存在显著差异。例如,Idefics2-base在预训练期间使用8个上下文示例在TextVQA上得分57.9,在DocVQA上得分低于55。然而,经过微调后,在TextVQA上达到70.4,在DocVQA上以零样本设置达到67.3,而无需使用图像分割策略。一个原因是模型仅在微调阶段开始学习视觉问答的具体任务(超越仅图像描述或文本转录),除非在第三预训练阶段使用大规模合成VQA数据集,这些数据集提供与基准测试中存在的示例更一致的示例。
当在预训练期间省略指令数据时,文档理解等更复杂的任务可能表现不佳,VLM中的开发选择的影响可能仅在微调后变得明显,导致反馈循环延迟。例如,在Idefics2中,作者发现使用128个视觉tokens而不是64个在其架构中进行预训练时没有明显的改进。然而,在使用图像分割策略微调后,使用更多视觉tokens在OCR任务中的好处变得明显。因此,为了在预训练消融期间获得更准确的见解,建议将指令数据纳入数据混合中。
一些基准测试中的污染和过度优化风险
一些基准测试源自现有学术数据集的验证或测试集。例如,用于评估推理和数学能力的领先基准测试MathVista显示出潜在污染的迹象。我们发现至少6.6%的问题包含经常用于监督微调的学术数据集的训练集中的图像,2.2%的问题包含图像和问题是相同或高度相似的。此外,这个基准测试通常包含一些问题,除非模型在训练期间遇到过,否则很难回答。例如,我们发现MathVista中至少6.1%的问题是关于“这两个人在图像中的年龄差是多少?”的变体。类似的问题在KVQA中也很常见。因此,在其微调数据中包含这些问题的模型在MathVista上会有优势。
最终,基准测试应该用来衡量模型性能,而不是作为训练目标。在类似示例上进行微调可以提高分数,但这对模型在真实世界场景中的泛化能力提供了很少的证据。因此,我们鼓励研究人员排除在他们评估的基准测试中使用的图像,从他们的监督微调数据中。
构建Idefics3的架构和训练方法
Idefics3是基于Llama 3.1和SigLIP-SO400M构建的视觉语言模型(VLM)。其架构和训练方法如下:
模型结构选择
视觉编码器和语言模型
-
• 视觉编码器:使用SigLIP-SO400M。
-
• 语言模型:使用Llama 3.1 instruct,替换了Idefics2中的Mistral-7B。
图像编码策略
-
• Idefics2中使用的感知重采样器被更换为像素重排策略,作为一种池化技术,将图像的隐藏状态数量减少了四倍。
-
• 每个图像被编码为364x364像素的169个视觉token。
-
• 在训练和推理过程中,图像被分割成364x364像素的patch矩阵,视觉编码器分别处理每个patch,生成视觉token序列。
-
• 为了保留图像的二维结构,在每行Patch后插入一个文本token ‘\n’,并将原始图像缩小至364x364像素附加到patch序列后面。
-
• 在每个patch前添加表示patch在矩阵中位置的文本token ’
'。
训练过程
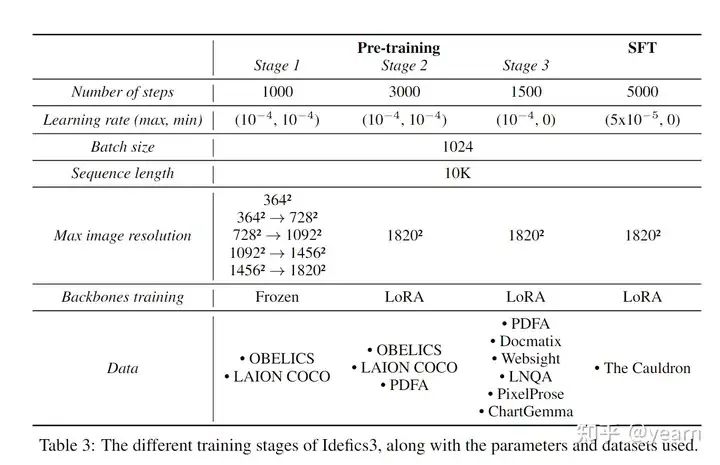
训练包括三个阶段的预训练和一次监督微调:
-
• 第一阶段预训练:冻结模型的骨干部分,以保留其性能,同时学习新初始化的参数,逐步将最大图像分辨率从364²增加到1820²。
-
• 第二阶段预训练:使用DoRA方法高效训练骨干部分,并引入更大的图像。
-
• 第三阶段预训练:专注于使用大型合成数据集进行训练。
-
• 监督微调阶段:应用NEFTune噪声到输入,并仅在答案token上计算损失。前两个预训练阶段学习率保持恒定,最后一个预训练阶段和监督微调阶段学习率线性衰减至零。
整个训练过程,包括重启,共完成于32个H100节点上,耗时5天。
改进机会
-
• 完全解冻骨干部分可能会带来更好的性能,尽管当前使用LoRA方法以提高训练效率。
-
• 在前两个预训练阶段,虽然损失函数未完全收敛,文章为减少计算成本而进入下一个阶段。
-
• 第三阶段预训练中,仅使用了所选数据集的一部分样本,进一步的改进可以通过创建和合并更大的合成数据集。
通过这些方法,Idefics3在多个基准测试中表现显著提升,特别是在文档理解任务上。
模型训练数据选择
数据集准备
训练Idefics3的过程主要利用了Idefics2的训练数据集,同时增加了几个补充数据集以扩展任务范围。
扩展The Cauldron
The Cauldron是一个由50个高质量数据集组成的集合,本文在此基础上增加了6个新的数据集,包括:
-
• Cord-v27:用于训练模型输出JSON格式信息
-
• LNQA:用于大规模真实世界的视觉问答
-
• ShareGPT-4o和IIW-400:用于生成详细的描述
-
• Geo170K:涉及几何任务
-
• Docmatix:用于文档理解
增强文档理解能力的Docmatix
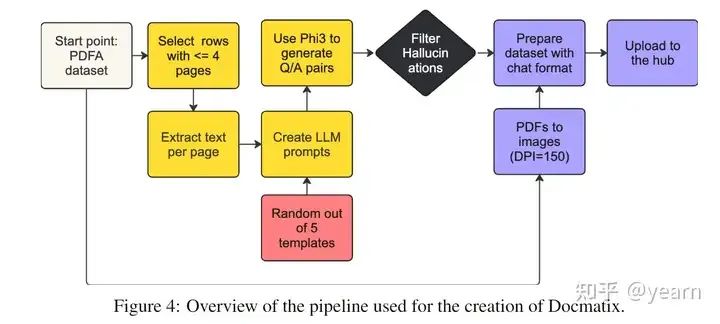
文档理解是VLMs的重要应用领域,现有的开源数据集数量有限。为此,构建了一个大规模的文档理解数据集Docmatix:
-
• 利用现有的OCR工具从PDF文档中提取文本。
-
• 使用Phi-3-small生成问答对。
-
• 通过正则表达式过滤低质量问答对,删除含有"unanswerable"关键词的答案。
最终得到的数据集Docmatix包括2.4M张图片和9.5M个问答对,显著提升了文档理解任务的规模。
通过这些方法,Idefics3在多个基准测试中表现显著提升,特别是在文档理解任务上。
总结
在本文中,详细介绍了构建视觉语言模型(VLMs)的完整教程,强调了架构、数据和训练方法在开发流程中的重要性。通过对当前最先进方法的深入分析,突出了各种设计选择的优缺点,并提出了改进模型的潜在研究方向。
接着,本文详细阐述了构建Idefics3-8B的实际步骤,这是一种在文档理解任务中表现显著提升的VLM,特别是通过引入Docmatix数据集实现了这一进步。通过公开发布模型和数据集,作者希望为下一代负责任且开放的VLMs的发展做出贡献。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓








![[C++ 核心编程]笔记 3 引用做函数参数](https://i-blog.csdnimg.cn/direct/2b86836cc50341a1acf3385b1d346c56.png#pic_center)