前几个月 Meta HSTU 点燃各大厂商对 LLM4Rec 的热情,一时间,探索推荐领域的 Scaling Law、实现推荐的 ChatGPT 时刻、取代传统推荐模型等一系列话题让人兴奋,然而理想有多丰满,现实就有多骨感,尚未有业界公开真正复刻 HSTU 的辉煌。这里面有很多原因,可能是有太多坑要踩,也有可能是 Meta HSTU 的基线较弱,导致国内已经卷成麻花的推荐领域难以应用 HSTU 产生突破性效果。

然而做起来困难并不代表不去做,总要有真的勇士率先攻克难关迈出一步。字节前几天(2024.9.19 发布 arxiv)公开的工作 ⌜HLLM⌟(分层大语言模型)便是沿着这一方向的进一步探索,论文内也提及了 follow HSTU:


论文题目:
HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling
论文链接:
https://arxiv.org/abs/2409.12740
代码链接:
https://github.com/bytedance/HLLM
这里我针对全文进行一个详细解析,也会有一些疑问,欢迎评论区探讨以及点赞收藏。
1. 背景
传统推荐问题:推荐重要的是建模 user、item feature,主流方法是 ID-based,将 user、item 转为 ID 并创建对应的 embedding table,然而一般都是 embedding 参数很大而模型参数较小,这会导致以下问题:
- 严重依赖 ID feature 在冷启动时表现不好
- 模型较小难以建模复杂且多样的用户兴趣
过往 LLM 探索方向:大致分为三种:
- 利用 LLM 提供一些信息给推荐系统
- 将推荐系统转变为对话驱动的形式
- 修改 LLM 不再只是文本输入/输出,比如直接输入 ID feature 给 LLM
LLM4Rec 挑战:其中一个 issue 是在相同时间 span 情况下,相比 ID-based 方法 LLM 的输入更长,复杂度更高;另一个是相对于传统方法 LLM-based 方法提升并不显著。
三个关键问题:LLM 应用到推荐有三个问题需要评估:
- LLM 预训练权重的真正价值:模型权重蕴含着世界知识,但是如何激活这些知识,只能使用文本输入吗?这也为之后使用 feature 输入埋下伏笔;
- 对推荐任务进行微调是有有必要性?直接使用 pretrain 还是说要进一步微调?
- LLM 是否可以应用在推荐系统中并呈现 scaling law?
由此提出了 Hierarchical Large Language Mode****l(HLLM)架构,训练 Item LLM(用来提取 item feature)和 User LLM (item feature 作为输入,用于预测下一个 item),实验表明在公开数据集上显著超越 ID-based 方法,并呈现了 Scaling Law 特性。在抖音落地,A/B 实验显示在重要指标上增长 0.705%。
2. 方法
2.1 HLLM
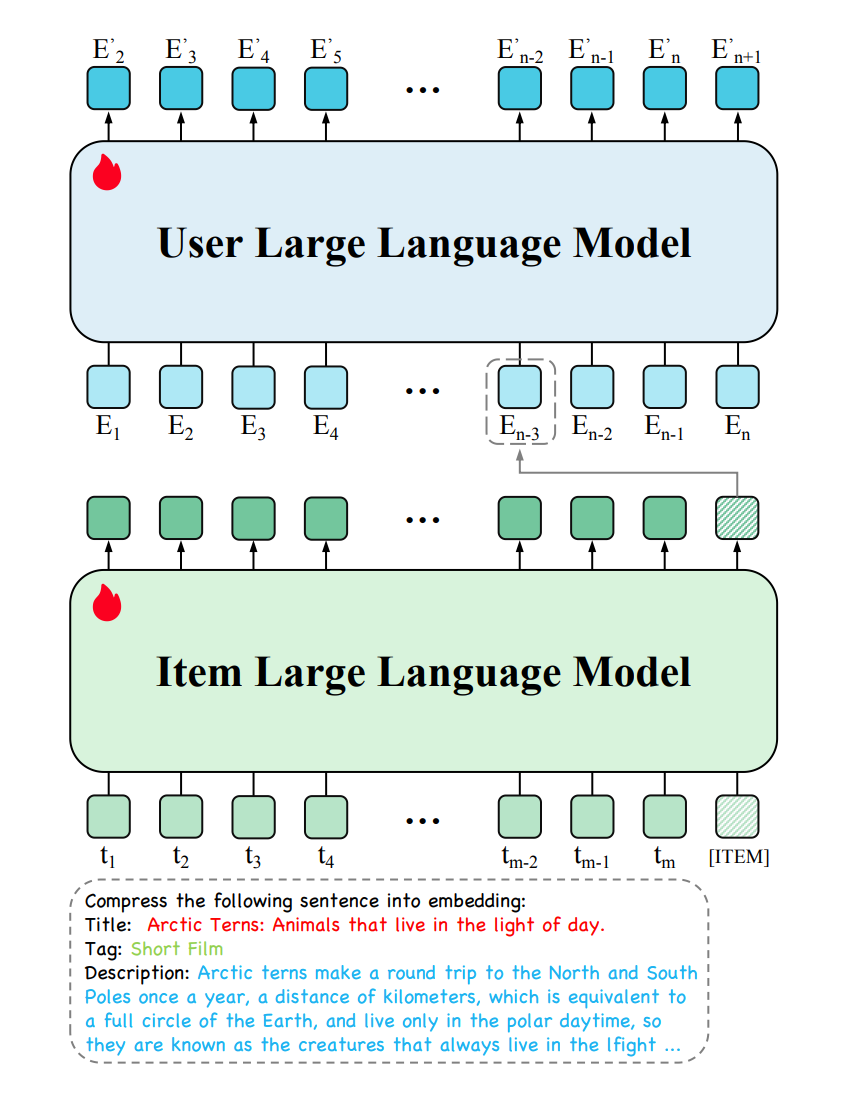
分为 Item LLM 和 User LLM,两者参数并不共享,都是可训练的并通过 next item predict 来进行优化。
可以直接基于已经预训练好的(例如 llama、baichuan)来训练。
Item LLM 使用 item 的描述作为输入,包括 Title、Tag、Description,最后再加上一个特殊 token:[ITEM],特殊 token 对应输出的代表该 item 的 embedding;
User LLM 输入是用户历史交互序列,输入序列中每个 item 就来自于 Item LLM 的输出。由于输入并非文本 token,所以会去除预训练模型的 word embedding;
2.2 优化目标
推荐系统大致分为两类:生成式推****荐与判别式推荐,而 HLLM 同时应用了这两种。
首先针对 Item LLM 的训练虽然论文没提及,但应该就是简单的 next token prediction 的训练,针对输入的每个位置预测下一个 token,损失为交叉熵损失。
其次针对 User LLM 的训练还能用 next token prediction 吗?当然不能!因为去除了 word embedding,词表都没了,还怎么预测 next token。那该怎么做呢?
生成式推荐:
实际会 User LLM 使用 InfoNCE 来作为生成损失,对于某个物品 模型输出的 是正样本,随机抽取的其他物品为负样本,不得不说将对比学习的 InfoNCE 作为预测 next token 的损失设计的很巧妙。
定义的生成式损失函数 如下所示:

这里,公式中的各个符号代表以下含义:
- 是一个相似度函数,带有可学习参数;
- 表示第 个用户的历史交互中由物品 LLM 生成的第 个物品嵌入;
- 表示由用户 LLM 为第 个用户预测的第 个物品嵌入;
- 是负采样的数量, 表示第 个负样本的嵌入;
- 表示批次中的用户总数, 表示用户历史交互的长度;
判别式推荐:
业界主要还是应用判别式推荐模型,HLLM 同样也可。
首先给出问题定义,给定用户的行为序列 和一个目标 item ,模型要预测用户对该 item 感不感兴趣(例如点击、点赞、购买)等。

如上图所示,分为 Early Fusion 和 Late Fusion(实际论文指出真正上线使用的是 Late Fusion)
Early Fusion:将 item 输入给 Item LLM 后得到的 embedding 直接拼到序列后输入给 User LLM,将对应位置的输出做分类。效果好但效率低。
Late Fusion:类似于 Item LLM,使用 User LLM 提取得到用户的 embedding,即 [USER] 拼到序列后输入给 User LLM,将对应位置的输出与 拼到一起做分类。效果差些但效率高。
这两者有点类似单塔和双塔,一个是可以早期进行交叉充分学习但由于候选项过多效率低下,另一个是后期再交叉效率更高。实际在落地使用的是 Late Fusion。
预测是个二分类问题,训练损失函数如下:

其中,y 表示训练样本的标签,x 表示预测的 logit。
经验上,next item prediction 也可以作为判别模型中的辅助损失,用于进一步提升性能。因此,最终的损失函数可以表示为:

其中 用来控制辅助损失的权重。
3. 实验
3.1 公开数据集
数据集使用 PixelRec、Amazon Book,baseline 选用 SASRec 和 HSTU;
离线实验使用生成式推荐(为了与其他方法公平对比),在线 A/B 实验使用判别式推荐(为了与线上系统兼容);
自身模型设置 HLLM-1B、HLLM-7B 两种,HLLM-1B 采用 TinyLlama-1.1B,HLLM-7B 采用 Baichuan2-7B;
HLLM 仅在 PixelRec,Book 训练 5 个 eopch,对比之下其他方法训练 50-200 epoch 不等,其他细节设置详见论文。

简单来说 HLLM 效果比 SASRec 和 HSTU 都要好。
这里有个疑问,目前 HSTU 公开的代码和设置都是忽略了动作这一输入,如若这里实验仅使用 item 并不能真正体现 HSTU 的能力,标星的都是作者自己复现的。
在线 A/B 实验:

【设置】采用 HLLM-1B,应用 判别式推荐 + Late Fusion,
【训练】采用三阶段方法训练:
阶段1:端到端训练 HLLM,包括 Item LLM 和 User LLM,用户行为长度截断为 150 来加速;
阶段2:使用阶段 1 训好的 Item LLM 所有的 item emb 存起来,然后继续只训练 User LLM,输入的 item emb 来自于库内。由于只训练 User LLM,用户行为扩大为 1000;
阶段3:经历前两个阶段大量数据训练后,HLLM 权重不再改变,提取 user feature 和 item feature 喂给线上模型训练。
【推理】在 Serving 阶段,如图所示,item emb 会在其创建时提取,user emb 会进行天级别更新仅仅当用户在前一天发生过交互。基于该方法,线上推理系统推理时间基本不发生变化。
最后做 A/B 实验,重要指标提升 0.705%。
4. 问题
4.1 微调相比直接使用预训练对于推荐目标是否有收益?

**结论1:**对于 Item LLM 和 User LLM,基于预训练微调更好;

**结论2:**预训练使用的 token 越多,效果越好;此外如果预训练后再进行 SFT(在对话场景下),效果会下降,原因可能是因为 SFT 仅仅训练 follow 指令的能力,而对推荐本身无益。

结论3:Item LLM 和 User LLM 都训练会更好。
4.2 HLLM 是否有 Scaling 特性?

针对 Item 和 User LLM 都做了Scaling 实验:
**结论:**对于模型大小具有 scaling 特性;
(模型设置都不是一种结构,LLaMA变成了BERT,这也行?)
4.3 对比 SoTA 方法(HSTU)优势是什么?
论文主要先说了 HLLM 比 HSTU 在相同设置下效果更好,又强调了当增加负样本数量和 batchsize 时,基于 ID 的模型(HSTU)提升相对有限,HSTU-Large R@200 指标 +0.76,而相同设置的 HLLM-1B +2.44。
4.4 训练和 Serving 效率如何?

结论1:相对于 HSTU,HLLM 达到相同性能只需 1/6 至 1/4 的数据,需求更少。其次在实际推理时可以先 cache 所有 item emb;所以 HLLM 可以先训练 item LLM,然后cache item emb,然后再训练 User LLM,上图便展示了在 Pixel8M 的效果。

结论2:itemcache 比原来的性能略微降低,但仍然比 HSTU 好。
值得注意的是,实验所用预训练数据量不到 Pixel8M 的一半,且部分物品未出现在预训练数据中,仍然取得了不错的性能。在工业场景下,用户行为的数据量远大于 item 数量,因此相比 ID-based 模型 cost 一致。工业上实验同时表明,随着预训练数据量的增加,item cache 与 全量微调 之间的 gap 大大缩小。
5. 消融
5.1 Item LLM

结论:Item LLM 采用 Tag + Title + Description + length=256 效果最好。

结论:采用 [ITEM] token 提取 emb 比 mean pooling 方法好。
5.2 UserLLM

结论:输入用户序列长度采用 length=50 相比其他短的会更好。

结论:UserLLM 生成的 LLM emb 比 Item ID emb 更好,LLM emb 加上 ID emb 效果变差,加上 Timestamp emb 效果最好。
5.3 工业场景

结论:工业场景下 Item LLM 和 User LLM 采用 7B 更好,User LLM 输入长度采用 1k 最好。
6. 小结
字节推出的 HLLM 利用大语言模型提取物品特征并建模用户兴趣,有效地将预训练知识集成到推荐系统中,并证明了基于推荐目标的微调至关重要。HLLM 在更大的模型参数下展现了出色的可扩展性。实验表明,HLLM 优于传统的基于 ID 的模型,在学术数据集上取得了很好的结果。在线 A/B 测试进一步验证了 HLLM 的实际效率和适用性,标志着 LLM4Rec 的重大进展。
最后如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码关注免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉如何学习AI大模型?👈
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。