目录
- Linux工具的使用-02
- 1.如何让普通用户使用sudo
- 1.1为什么无法使用sudo
- 1.2解决步骤
- 1.3验证
- 2.编译器gcc/g++的使用
- 2.1预处理
- 2.2编译
- 2.3汇编
- 2.4链接
- 2.5函数库
- 2.5.1静态库与动态库
- 2.5.1.1动态链接
- 2.5.1.2静态链接
- 2.6gcc的默认链接方式
- 2.7gcc的静态链接
- 2.8g++的使用
- 2.8.1g++的静态链接
- 3.Linux自动化构建工具-make/Makefile
- 3.1makefile的语法及使用
- 3.1.1.PHONY
- 拓展:`gcc`是怎么知道该可执行文件是最新的编译版本呢?
- 3.2make和makefile的工作原理
- 3.2.1makefile的推导关系
- 3.2.2make的工作原理
- 3.3Linux的小程序—进度条
- 3.3.1缓冲区的存在
- 3.3.1倒计时
- 3.3.2进度条
Linux工具的使用-02
前言:
学习了vim之后,后面的操作都要以普通用户的身份进行。因此,sudo的使用必不可少,但是刚被创建出来的普通用户是无法使用sudo的,因此要进行一些设置
1.如何让普通用户使用sudo
1.1为什么无法使用sudo
当我们useradd一个普通用户之后,这个普通用户是无法执行sudo的。
出现下图所示就说明该用户无法执行sudo

根据提示,WZF这一用户并不在sudoers这个文件中,因此没有使用sudo的权利
这里的这个
sudoers文件位于/etc/sudoers因此,如果想要
WZF这个用户能够使用sudo,需要将其添加到sudoers文件中。但是这里的
/etc/sudoers文件是位于root下的一个文件。因此要对他进行修改需要以root的权限去执行这也很合理,root权限赋予普通用户可以sudo的权利。这里就类似一个白名单。在
/etc/sudoers这个白名单的用户就可以使用sudo
1.2解决步骤
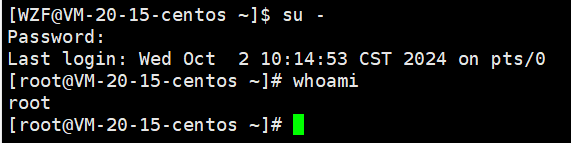
要以root身份在/etc/sudoers文件中添加用户,首先要是root才行。
输入下面这个指令之后,输入密码就可以登录了
su -
然后以vim的方式打开/etc/sudoers文件

打开之后找到下图这个玩意【大概位于100行左右】
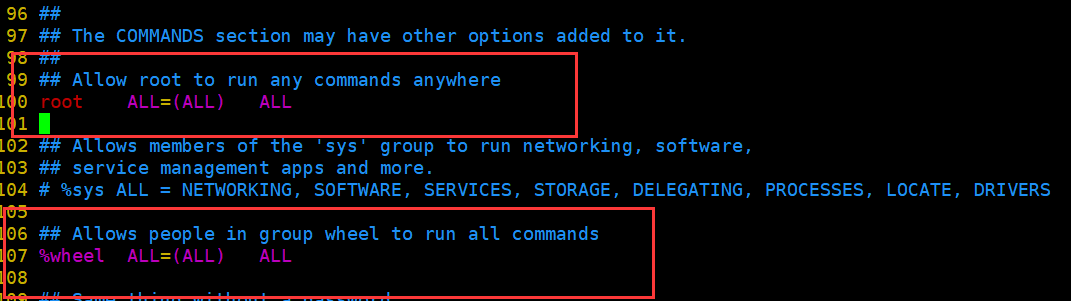
在这两个地方添加都可以,这里我在上面那里添加
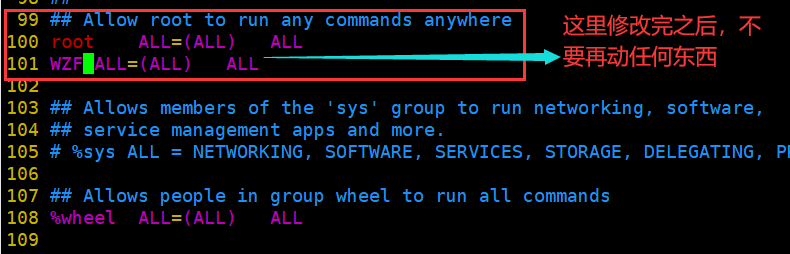
这里我是直接yy100行的内容,然后p一下,在i进入编辑模式,在修改成WZF。
这里修改的方式有很多,我只是把自己如何修改的说一下
在输入wq保存并退出时,会遇到一点点的小问题、如下图所示:
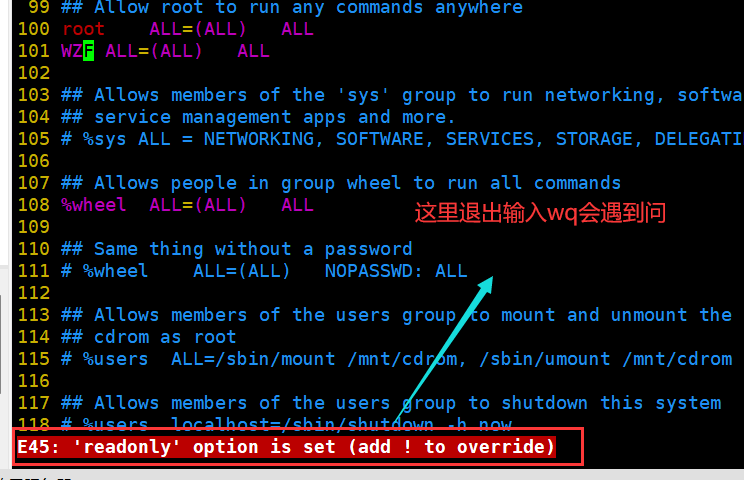
这里不用担心,输入
w!强制写入,在q!强制退出即可
自此WZF就可以使用sudo了
1.3验证
如下图所示即为成功
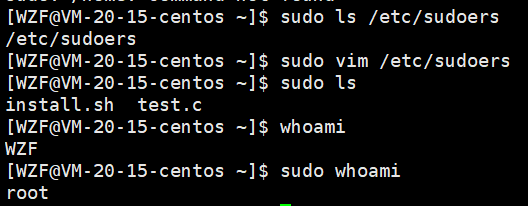
这里最好就是输入
sudo whoami
成功了就会弹出root。非常好验证
这里我们登录到另外一个用户Yaj,进行再一次验证

发生Yaj不能使用sudo
2.编译器gcc/g++的使用
首先得先了解编译器对代码做了什么
注意:
预处理
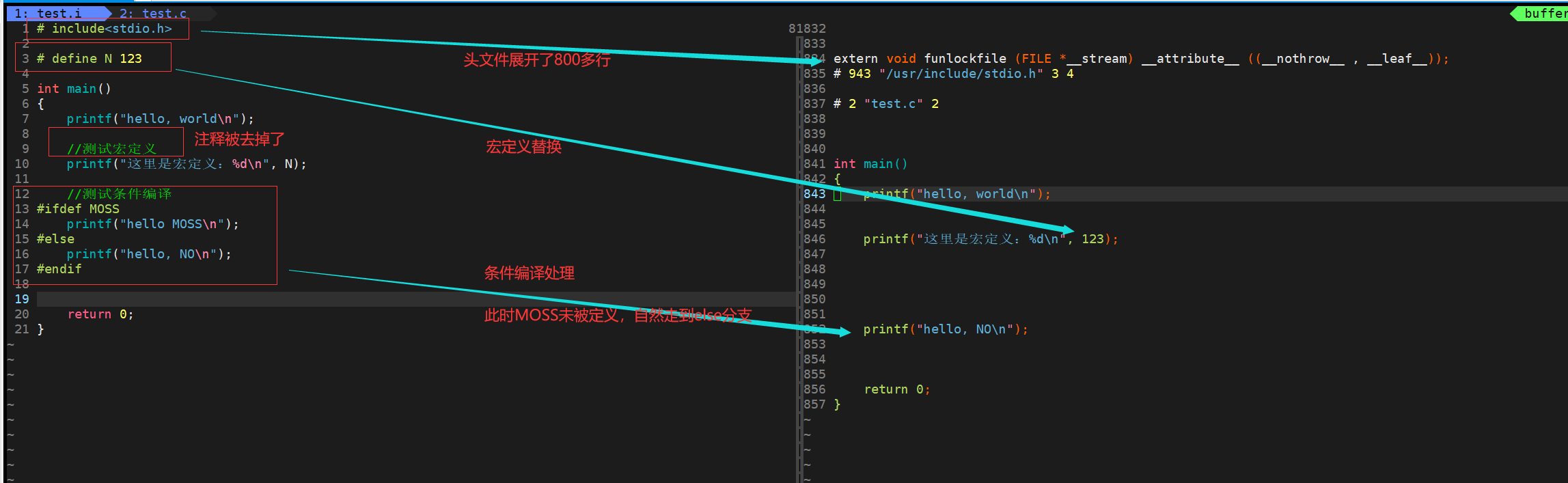
这里会做【头文件展开】【替换宏定义】【去掉注释】【条件编译】
编译(生成汇编)
汇编(生成机器可识别代码)
连接(生成可执行文件或库文件)
gcc的选项:
-E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面
-S 编译到汇编语言不进行汇编和链接
-c 编译到目标代码
-o 文件输出到 文件
-static 此选项对生成的文件采用静态链接
-g 生成调试信息。GNU 调试器可利用该信息。
-shared 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库.
-O0
-O1
-O2
-O3 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
-w 不生成任何警告信息。
-Wall 生成所有警告信息。
2.1预处理
对于一个写在linux下的c/c++语言程序来说,我们需要通过使用gcc/g++编译器来将其转化为可执行代码
如下图所示
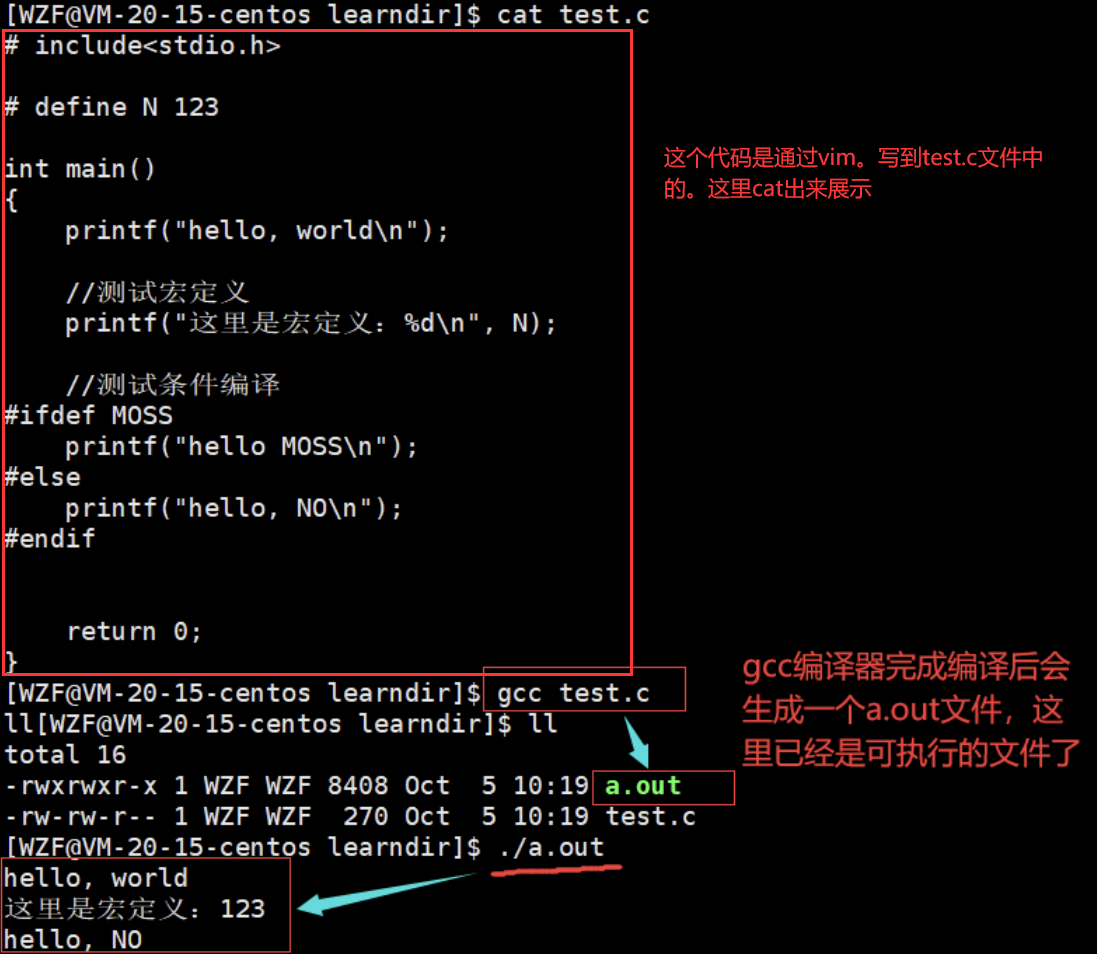
如果想要查看完成预处理阶段的代码就需要添加选项
gcc -E test.c -o test.i
- -E:将预处理阶段后的代码输出到屏幕上
- -o:将预处理后的代码指明到临时文件的名称上
上面这句指令的意思就是:将test.c这个文件开始编译,到预处理阶段就停下来,并且将此时的代码指明放到临时文件test.i上、

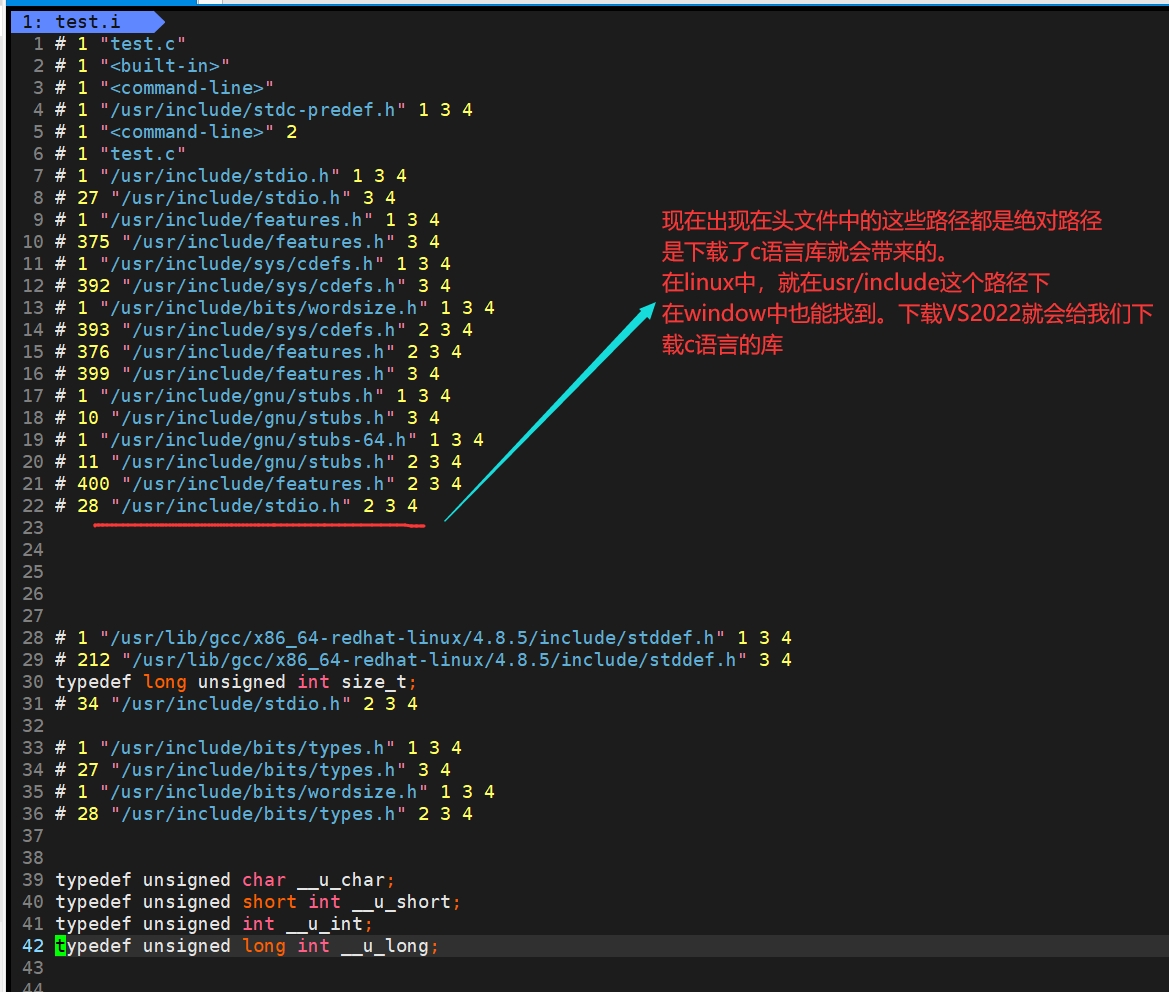
此时的代码由于展开了头文件,非常长,我们通过vim去查看
注意:
头文件展开的意义就是
- 让我们写代码,用到库内的东西
- 支持代码的自动补齐【比如写了一半的库函数就会弹出来对应的库的函数的全称出来】
对比一下原代码和预处理过后的代码:
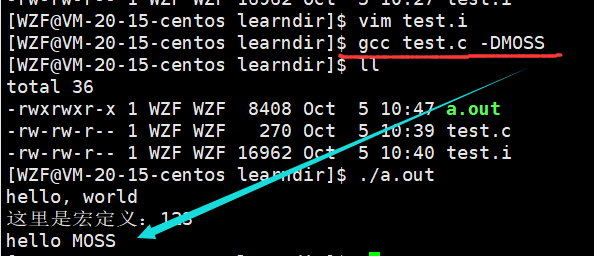
除了从内部添加宏定义。还可以从外部,通过-D选项即可
gcc test.c -DMOSS
这里就是在外部给编译器添加宏定义
2.2编译
在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言
要想看到编译阶段的代码要用到选项-S
gcc -S test.c -o test.s
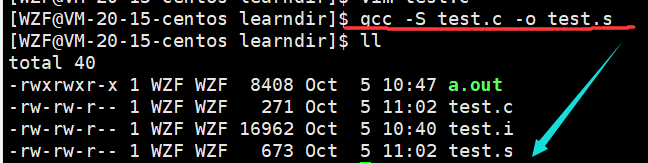
编译阶段就是生成汇编代码
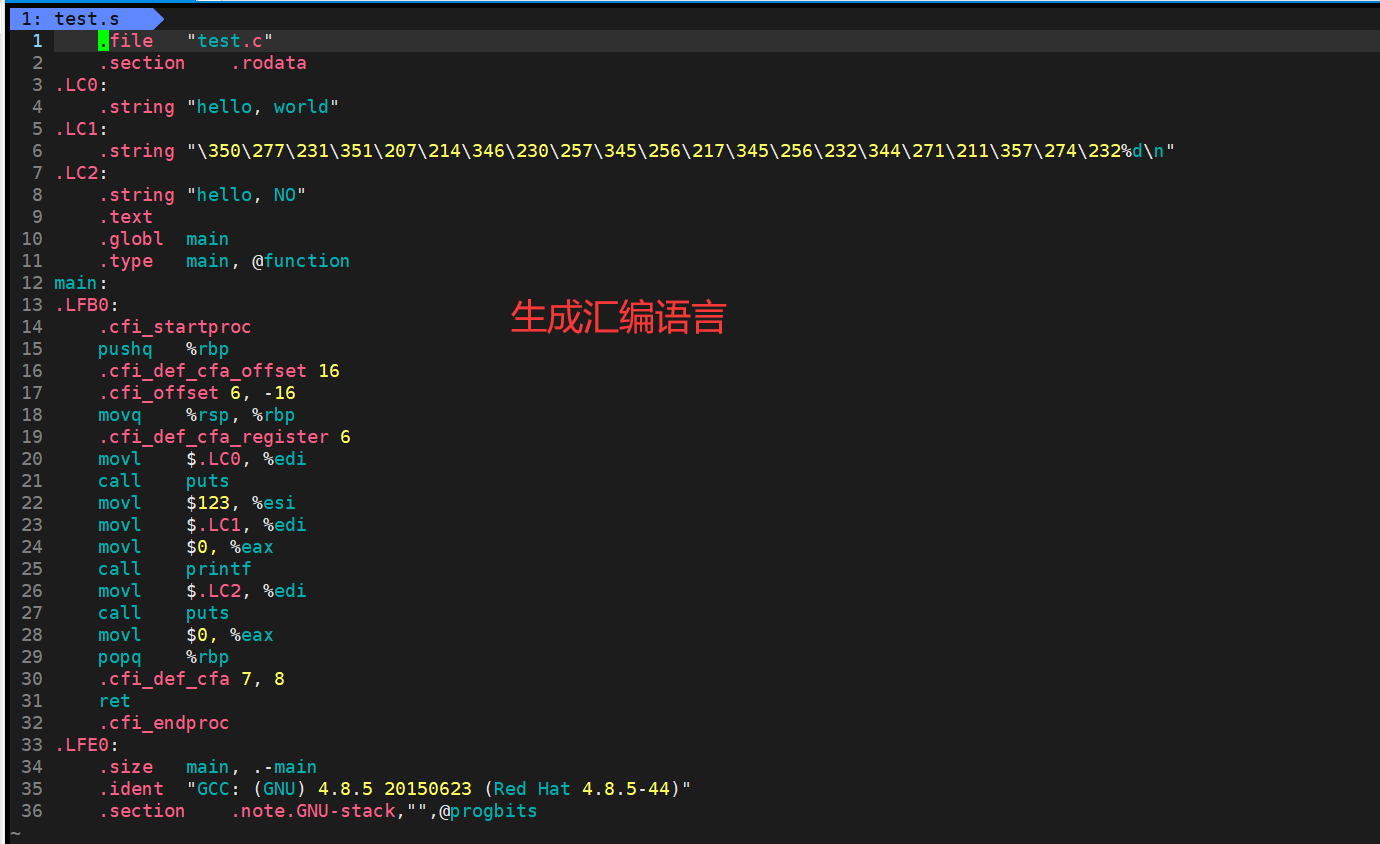
但是汇编语言也是不能被计算机直接执行的,计算机还是看不懂汇编的。
因为汇编语言跟体系结构有很大的关系。AMD和Intel的汇编代码就有所不同
带得把汇编代码转变为二进制代码才行
因此还得经历汇编阶段
2.3汇编
汇编阶段是把编译阶段生成的“.s”文件转成目标文件
要查看汇编阶段的代码我们得用选项-c
gcc -c test.c -o test.o
经过汇编阶段生成的文件,叫做可重定向二进制目标文件,此时计算机就能看懂了
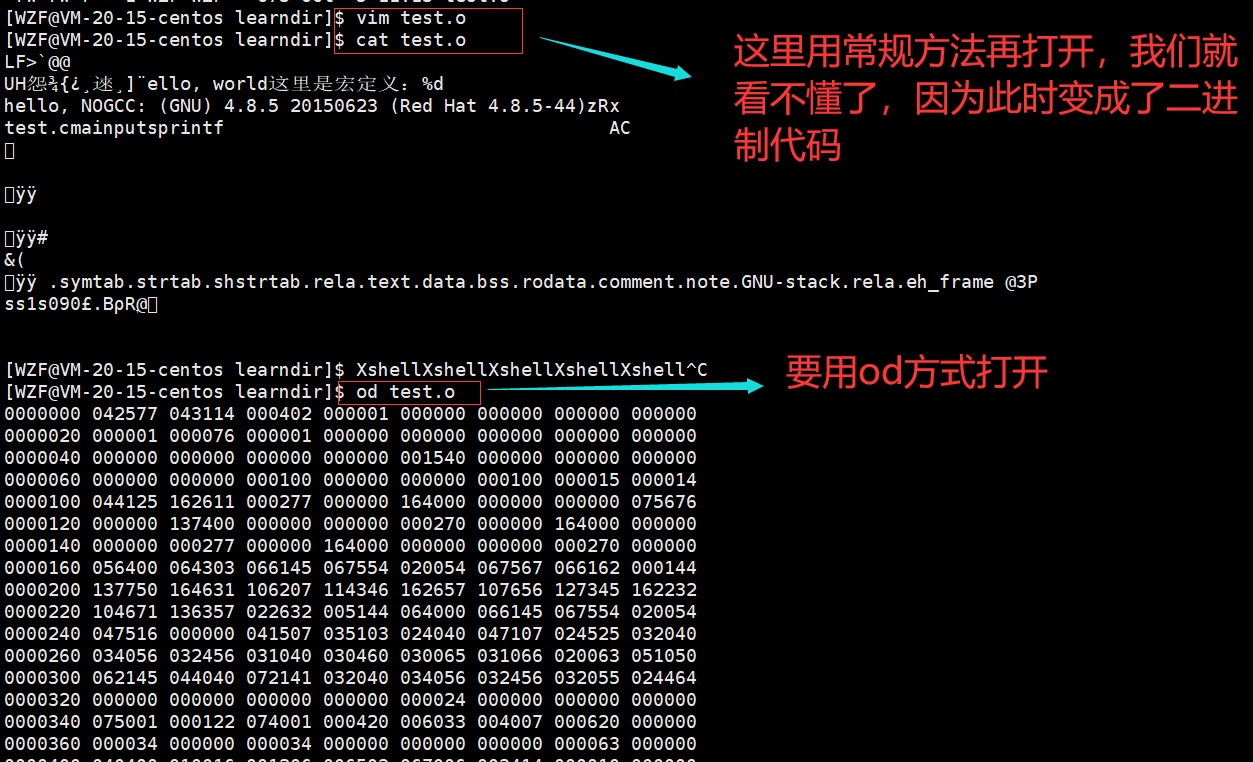
但是此时的二进制目标文件,也不是可执行代码。
原因:
尽管此时的代码经过了预处理,编译,汇编,三个阶段的处理。但是仅仅只是在处理我写的代码,其中我调用的库函数,如
printf。这个函数不是我写的,因此还需要再经过链接的处理——将我写的代码,和库内的代码链接才能生成可执行文件
2.4链接
最后一步链接,可以不带选项,它会自动连接并生成可执行文件
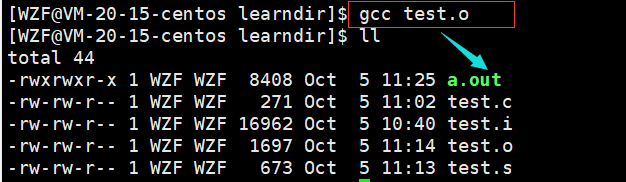
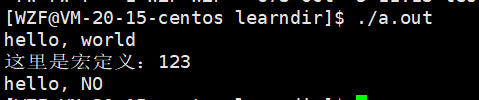
如果不想要生成的可执行文件叫做a.out,可以加-o选项,指明放到那个文件中
gcc test.o -o mytest
这里就变成了链接并生成一个叫做mytest的可执行文件
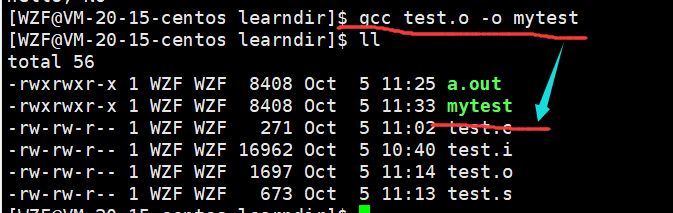
2.5函数库
前面在链接的时候,提到了链接是将个人写的代码和库中的代码链接,这里的库就是指的函数库
C程序中,并没有定义“printf”的函数实现,且在预编译中包含的“stdio.h”中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实“printf”函数的呢?
最后的答案是:
系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径“/usr/lib”下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函数“printf”了,而这也就是链接的作用
2.5.1静态库与动态库
链接是将个人写的代码与库函数的代码进行链接,但是这个链接的过程是什么样的呢?是怎么链接起来的,这就要知道静态库和动态库
函数库分为静态库和动态库
自然这个链接就有两种方式——静态链接和动态链接
2.5.1.1动态链接
动态链接链接的是动态库,个人写的代码如果调用了动态函数库内的函数,那么就需要通过链接器告知动态库的位置,然后进行库函数跳转,调用完库函数内部的函数后,回到个人写的代码继续执行
例如:
我们写了一段c语言代码,代码中调用了**c标准库(动态库)**中的函数,那么在执行到调用库函数那句代码的时候,就会通过链接器得知c标准库的位置,然后进行库函数跳转,在库函数内部找到库函数完成调用,随即回到个人写的c代码中继续执行。直至代码全部执行完毕
如图所示:
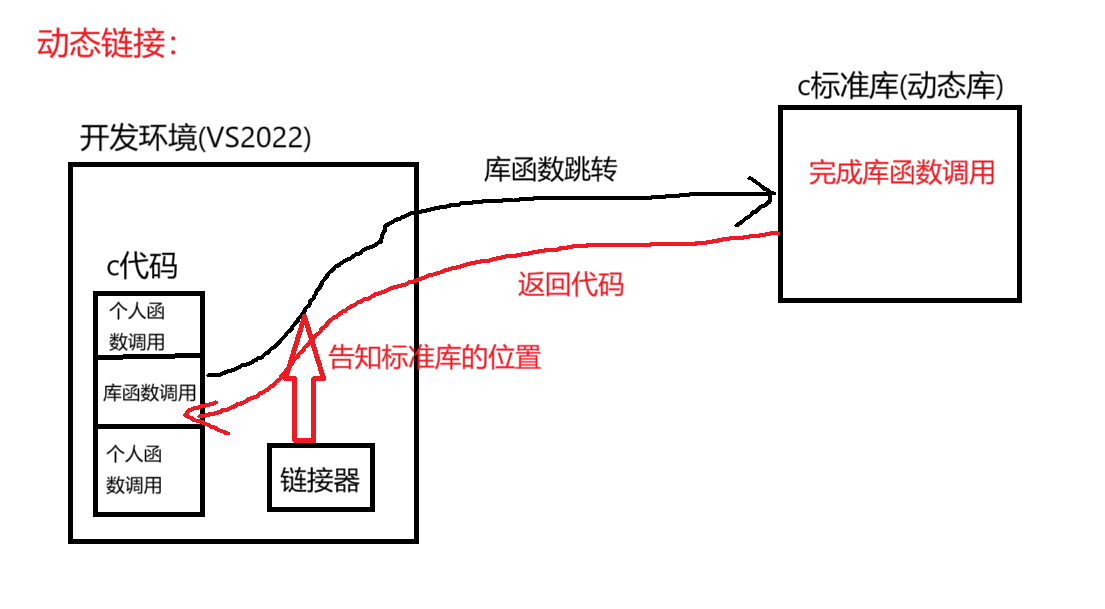
动态链接的优点:
- 生成的可执行文件会很小,因为调用的库函数是去动态库中调用的
- 节省系统的开销,无论是内存还是磁盘的开销都会变小
2.5.1.2静态链接
静态链接:直接静态标准库搬到程序中,也就是加入到可执行文件中,这样调用库函数就无需去标准库中找,直接在代码中就能找到库函数去调用,从而完成静态链接
如下图所示:
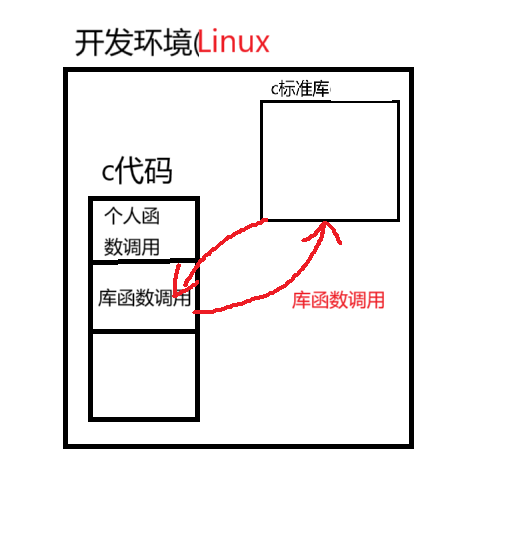
静态链接的优点:
动态库的升级和变化与自己无关,因为已经加载一份到代码中了
静态链接的缺点:
生成的可执行文件太大了,因为会把库函数全部加载到程序中。这样就会导致数据冗余,比如10个c语言代码都调用了库函数,就要在10个可执行文件中加载10个库函数
2.6gcc的默认链接方式
要想验证gcc下的默认链接方式需要用到file指令

如果要看动态链接是链接了哪个库,需要用到指令ldd

其实gcc在动态链接时链接的都是libc.so.6也就是c标准库(动态库)
注意:
linux下库的命名规则如下:
因此
libc.so.6就是c标准库(动态库)

这里我们可以在Linux中来查看这个库

我们发现libc.so.6只是一个链接文件,真正的c标准库是libc-2.17.so,它的大小非常大。
2.7gcc的静态链接
如果一定要静态链接的话,要指明用静态链接来链接。也就是指令-static
但是要使用静态链接,就需要链接静态库(也就是.a结尾的静态库),但是静态库在系统库中默认不一定有,因此还需要安装静态库

如上图所示,链接无法完成,因为找不到c静态库(.a结尾的静态库),然后我们去查看ls一下,发现真的没有,这个时候要安装静态库
输入:
sudo yum install -y glibc-static
安装静态库。
安装完成之后,就可以进行静态连接了,如下图所示:
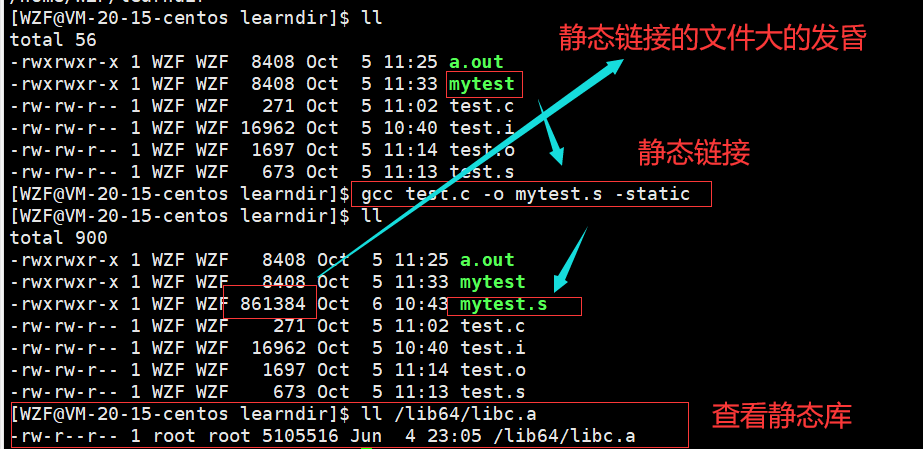
通过file来查看,可以直接看到是通过静态链接的方式生成的可执行文件mytest.s

2.8g++的使用
g++和gcc的使用都是一样的,只是g++用来编译c++程序而已
下面就不对编译的4个阶段进行分析了,直接对静态和动态链接分析一下
下面写了一个c++程序:
对其进行编译,并查看可执行文件mytest采取什么链接方式
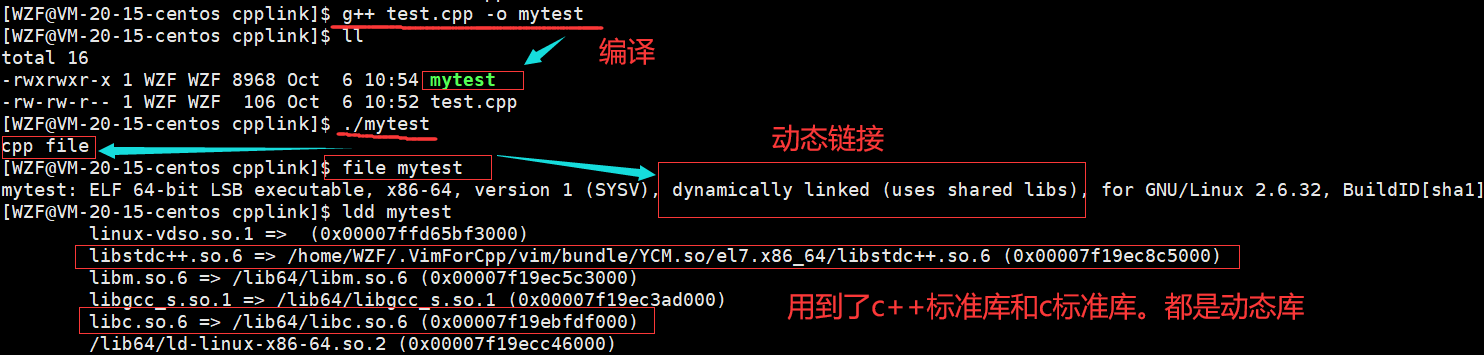
如上图所示,g++默认还是使用动态链接
c++的标准库(动态库)也可以查看,是系统自带的默认库

2.8.1g++的静态链接
和gcc一样,如果要使用静态链接,也是要通过-static特别声明
但是Linux标准库中,同样默认不安装c++的静态标准库(.a结尾的静态库)

如上图所示,静态链接发生错误,找不到c++的静态标准库
因此我们得自己安装:
sudo yum install -y libstdc++-static
安装完成之后,就可以使用静态链接了。

3.Linux自动化构建工具-make/Makefile
一些需要知道的点
- 要搞清楚make是一个指令,而Makefile是一个文件。两个搭配使用,完成项目自动化构建
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作
- makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率
- makefile和Makefile都是可以的
3.1makefile的语法及使用
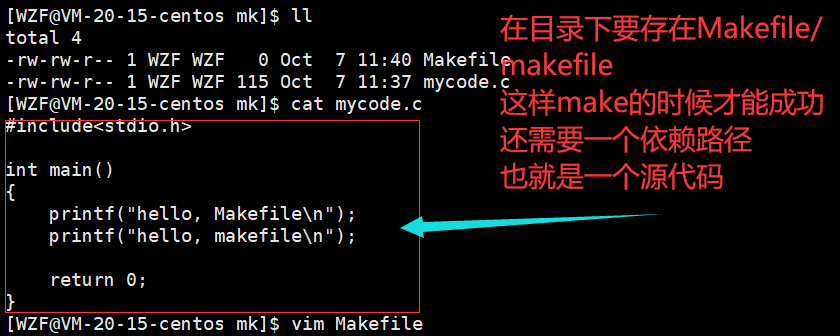
下面是m/Makefile和make的使用案例:
首先需要创建一个m/Makefile文件,然后还有一个程序文件
然后去修改m/Makefile文件,在其中添加依赖路径和依赖方法
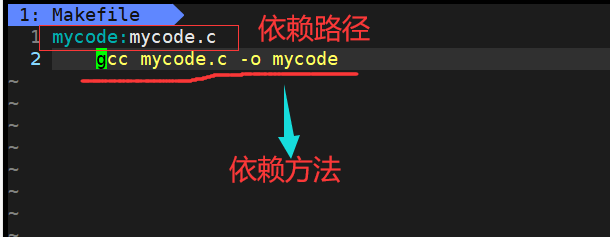
然后make之后,就会自动编译,生成可执行文件mycode
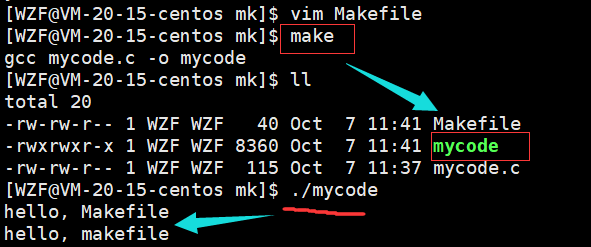
这里有个视频可以看看操作过程,因为图片可能不是很好表示makefile的使用过程
https://live.csdn.net/v/428175
这个视频凑合凑合看吧,质量不高
3.1.1.PHONY
.PHONY:被改关键字修饰的对象是一个伪目标【该目标总是被执行的】
什么意思呢?来看个实例:
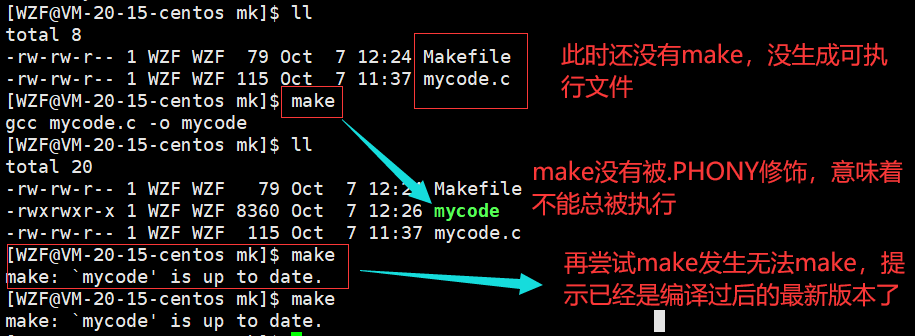
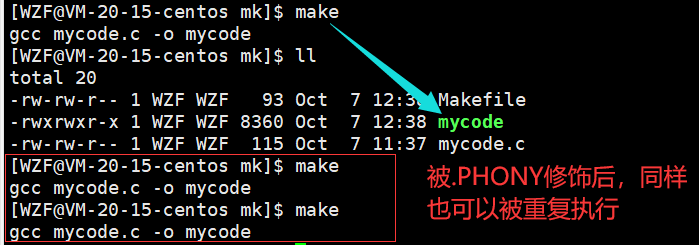
这样是合理的,因为一个文件如果没有变动的话,就不需要再重新编译了。因为编译也是需要耗费时间和资源的,如果一个工程很大,重复的编译就会浪费大量的时间
这里的make就无法总是被执行。
那怎么样才是总是被执行呢?看下面这个图:
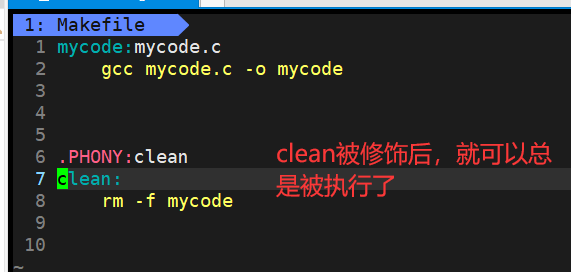
这里的clean是没有依赖路径的
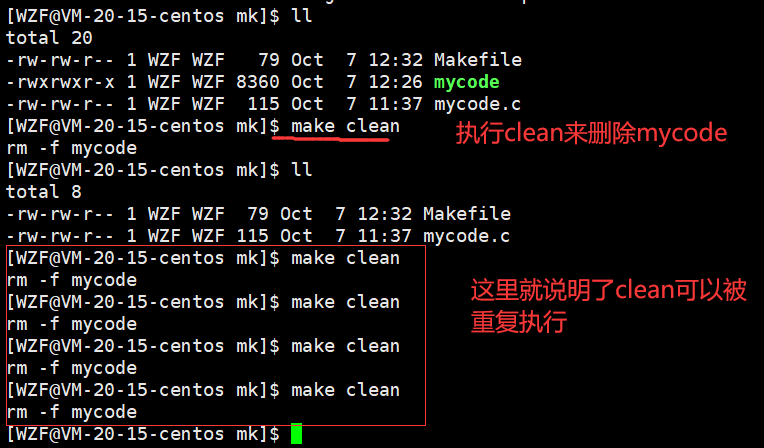
这里还可以做一个实验,就是将mycode也用.PHONY修饰
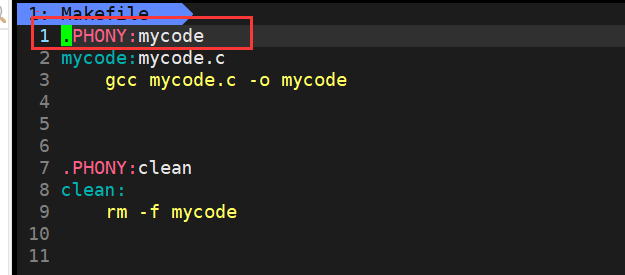
那么mycode也可以总是被执行了
拓展:gcc是怎么知道该可执行文件是最新的编译版本呢?
拓展:
gcc是怎么知道该可执行文件是最新的编译版本呢?
就像上面上图所示。
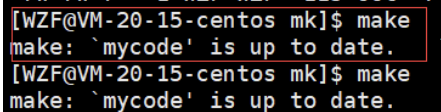
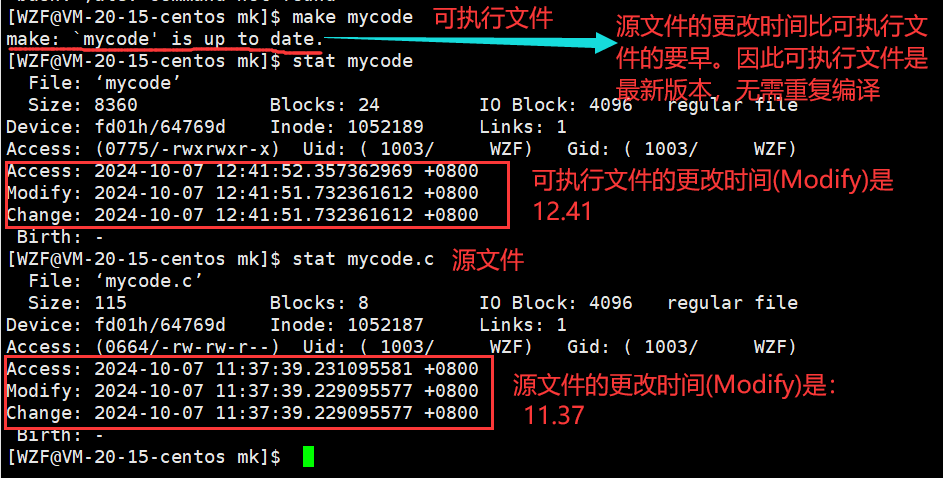
gcc知道mycode可执行文件是最新版本,没有变动的,无需重复编译.其实这跟文件属性有关系,也就是文件的修改时间
经过上图其实总结一句话就是:
gcc会比较可执行文件和源文件之间的Modify时间谁更早
- 如果源文件的时间早,那可执行文件就无需再编译
- 如果可执行文件执行早,就说明源文件进行了修改,那就编译
因此.PHONY就是不要根据时间规则来判断是否执行指令了。
3.2make和makefile的工作原理
3.2.1makefile的推导关系
为了弄清楚makefile的推导关系,我将编译的每个步骤都让makefile帮我编译
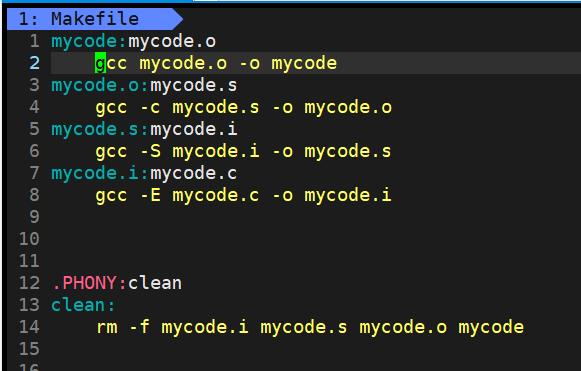
此时的依赖关系是mycode依赖于mycode.o,mycode.o依赖于mycode.s,mycode.s依赖于mycode.i,mycode.i依赖于mycode.c
因此make的时候,makefile文件会先从上到下扫描,扫描到
mycode,**判断mycode是否存在/或者是依赖路径的mycode.o文件的修改时间比自己晚,那么就会想去执行依赖方法来生成mycode,**但是如果找不到依赖路径,也就是发现依赖路径mycode.o不存在,就会顺着依赖关系继续找到mycode.s,发现也不存在,就会继续顺着依赖关系向下找,直到找到mycode.i,其依赖路径mycode.c存在,存在就执行依赖方法,然后依次向上执行依赖方法
最后make的结果如下图所示:
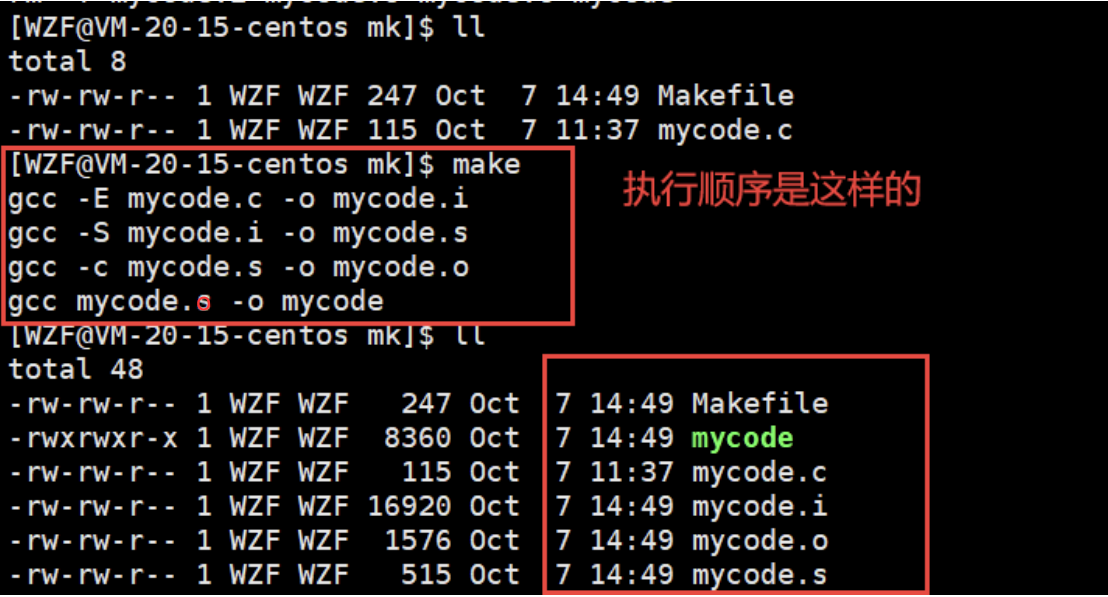
实际在使用makefile的过程中, 不要这样做,这是把简单问题复杂化,就弄一个编译的gcc指令就可以了。这里只是为了方便理解makefile的推导关系而已
3.2.2make的工作原理
当输入make的时候
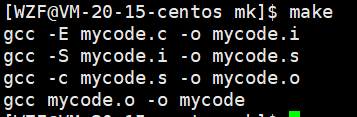
- 首先会在当前目录下寻找Makefile或者makefile文件,找到了就会进入文件当中
- 找到了之后,就会寻找从上到下扫描,直至扫描到第一个目标文件
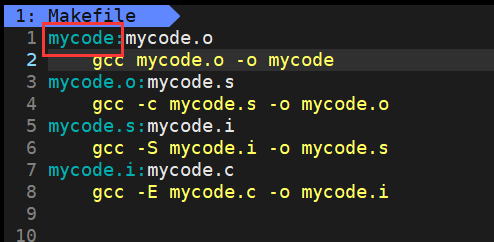
-
在上面例子找,找到的第一个目标文件就是
mycode。然后它就会把生成mycode这个可执行文件作为一个最终的目标 -
找到了目标文件之后,首先会判断目标文件
mycode是否存在,如果不存在那么就会尝试根据依赖路径mycode.o来执行依赖方法从而生成可执行目标文件mycode。 -
如果目标文件
mycode存在,那么就会判断其依赖路径的文件的修改时间与目标文件mycode的修改时间谁大,如果是依赖路径mycode.o的时间更晚,那么也会尝试执行依赖方法来重新生成目标文件mycode -
但是如果检测到依赖路径文件
mycode.o不存在的话,那么就会寻找mycode.o的依赖路径mycode.s,尝试执行依赖方法来生成mycode.o,依次类推,直至能够生成最终目标文件mycode。 -
在上述例子中就会一直找到
mycode.i的依赖路径mycode.c文件,然后生成mycode.i然后再依次执行依赖方法,直至生成mycode -
在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错,而对于所定义的命令的错误,或是编译不成功,make根本不理。
-
make只管文件的依赖性,即,如果在我找了依赖关系之后,冒号后面的文件还是不在,那么就会停止工作
这就是整个make的依赖性,make会一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件
3.3Linux的小程序—进度条
3.3.1缓冲区的存在
在写小程序之前,得需要知道缓冲区的存在。这里只先知道它的影响和存在
缓冲区的影响:
看下面两个代码执行后的区别
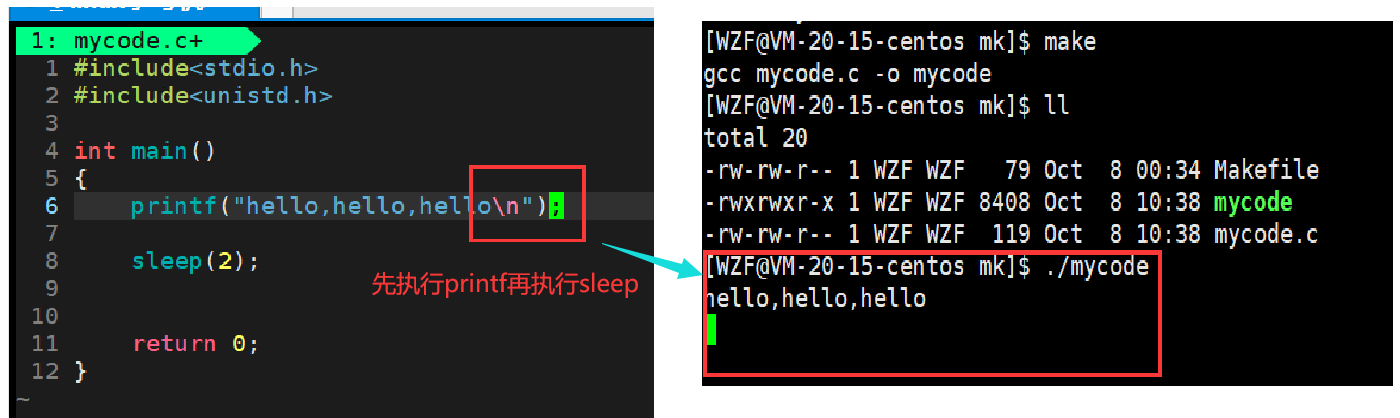
上面这个是有换行符\n,下面这个没有
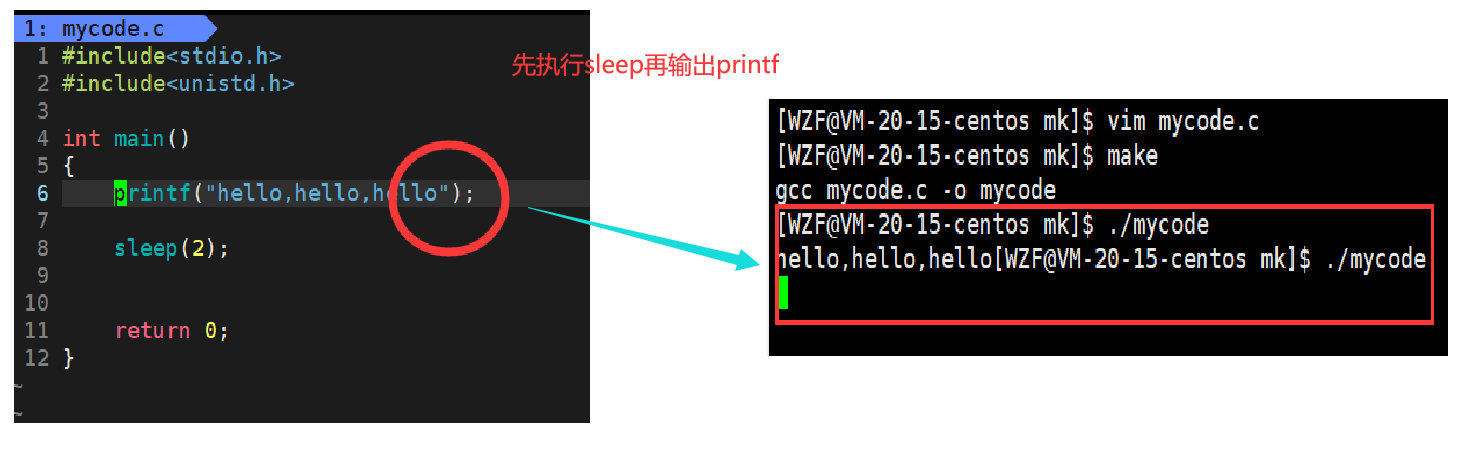
这里的代码之所以最终先执行sleep是因为缓冲区的存在。
这里的代码都是顺序结构的,所以不存在先执行sleep的情况,printf之所以不输出,一定是执行了之后,没有显示出来而已,它先输出到了缓冲区,执行完sleep才输出到了标准输出流上
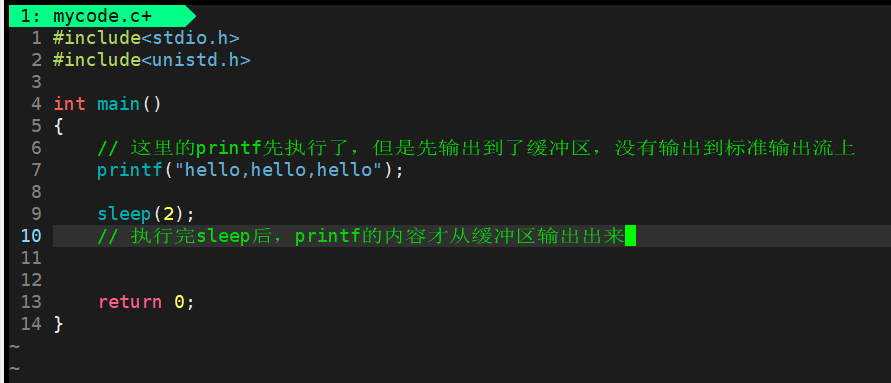
只需要让其printf的内容,先从缓冲区刷新出来,就可以先显示再sleep了、
这里调用一个fflush就行了
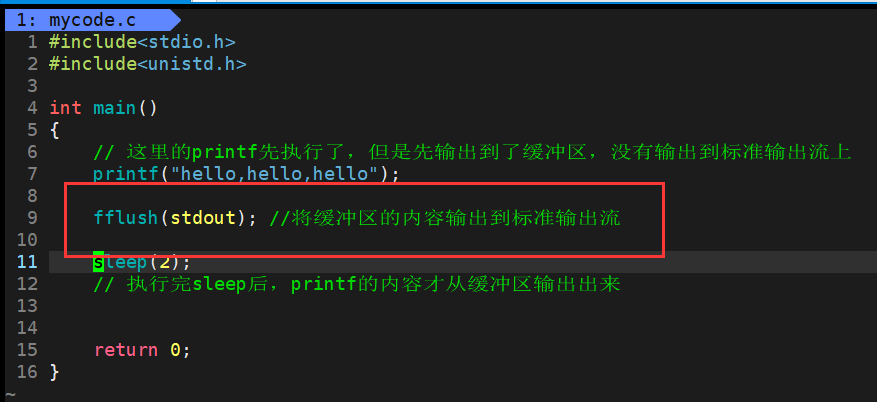
重新make之后,再执行结果如下图所示:

这里还有一个疑问:
有换行符\n的情况为什么就可以直接输出再sleep呢?难道\n也起到将缓冲区内容输出到标准输出流的作用?
因为\n叫做行缓冲,它会将内容直接从缓冲区刷新到标准输出流上
3.3.1倒计时
回车和换行的区别:
回车\r:回到当前光标行的最开始
换行\n:直接光标正下方的下一行
现在键盘的回车建Enter,其实就是回车+换行:光标移动到下一行的最开始处
语言冲的\n符,也就回车+换行
知道了这些知识就可以小练一手,先vim time.c弄个倒计时一样的简单小程序来、
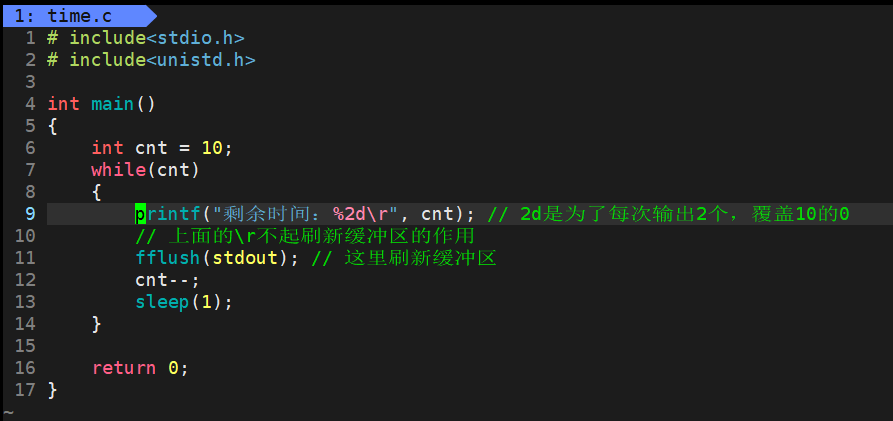
执行结果自然就是倒计时一样的。这里不贴动图,自行脑补了只能
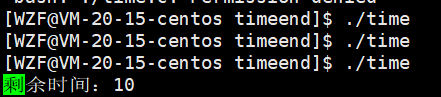
知道了倒计时怎么弄得,搞进度条就能更好的理解了
3.3.2进度条
这里的进度条小程序我们采取多文件来实现
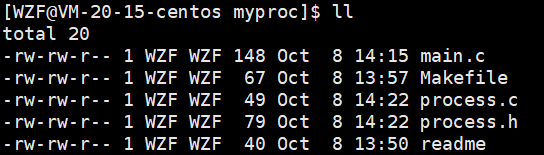
一个头文件,两个源文件。
结构是下图所示:
多文件的Makefile内的依赖关系的配置需要注意一下:
- 头文件不需要写在依赖关系那边,因为头文件在同一个目录下,编译器会自己找到
- -o选项后面跟的第一个就是生成的可执行文件的名字
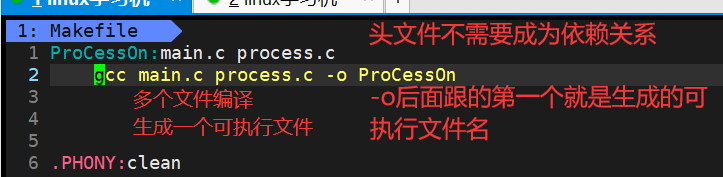
也可以这样写
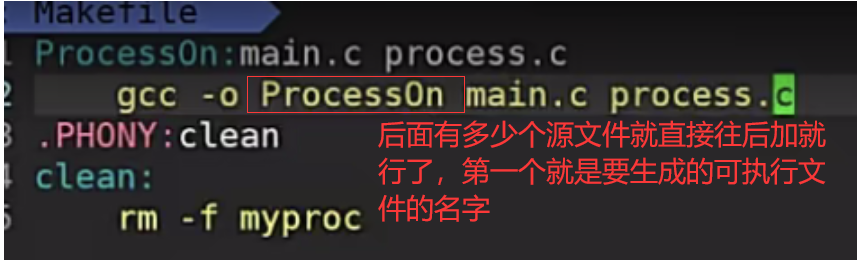
先验证是否能够成功运行
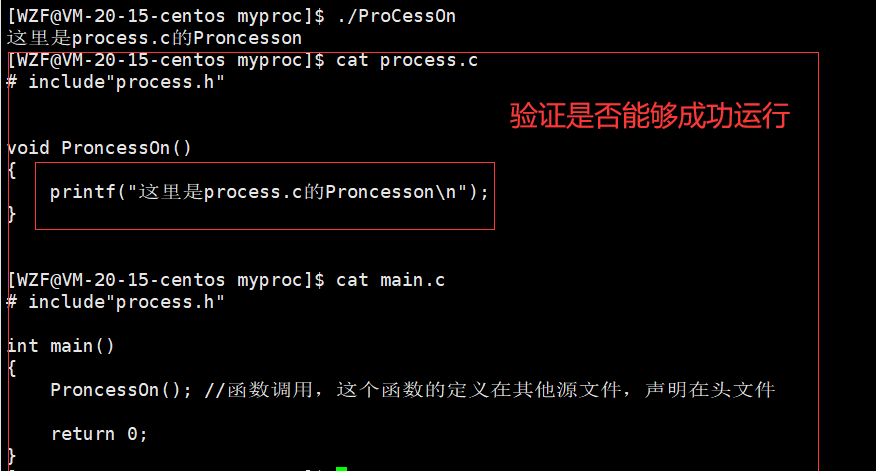
上图是两个源文件的内容
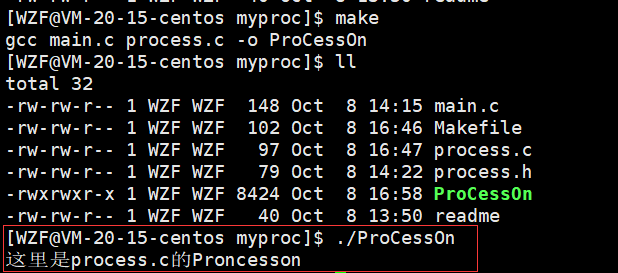
验证通过了之后就可以正式开始写代码了。
可以向下图所示一样,通过vs指令对两个文件进行编辑
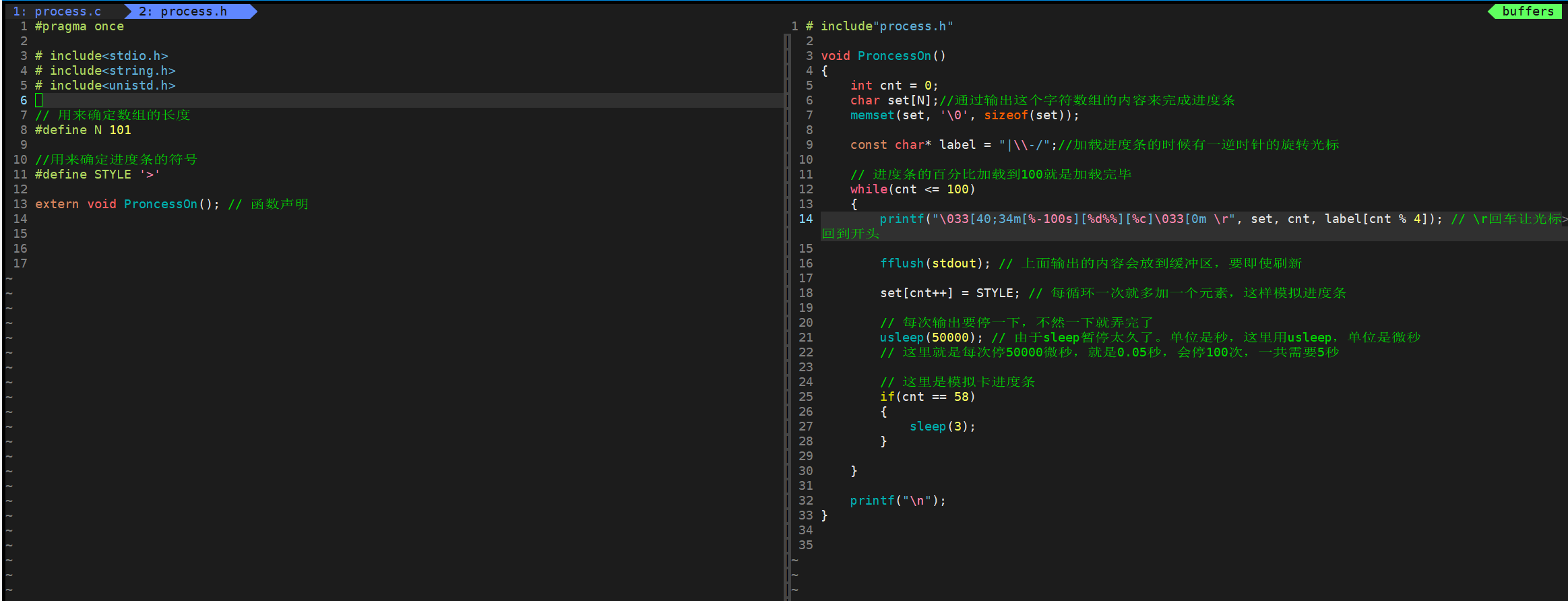
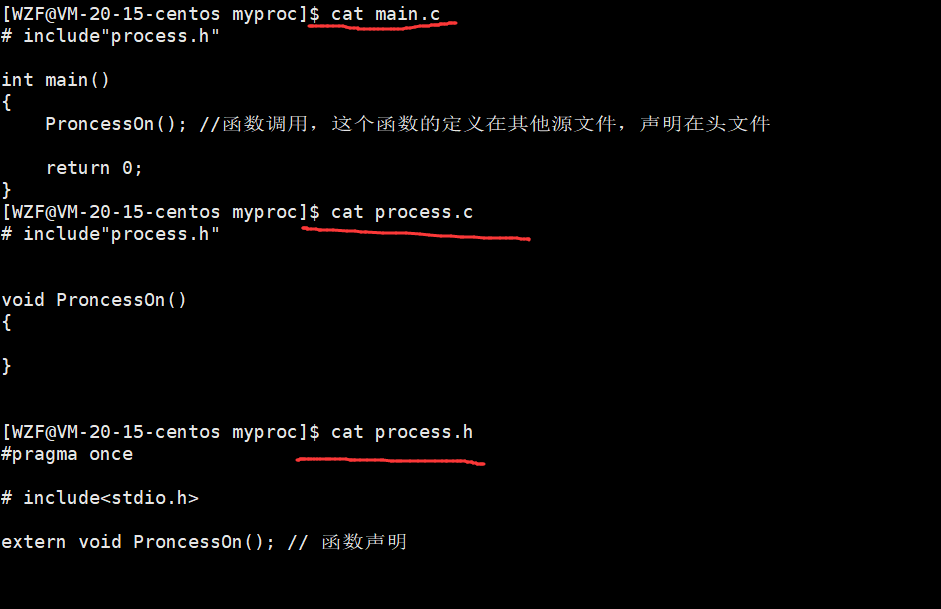
process.c的代码:
# include"process.h"
void ProncessOn()
{
int cnt = 0;
char set[N];//通过输出这个字符数组的内容来完成进度条
memset(set, '\0', sizeof(set));
const char* label = "|\\-/";//加载进度条的时候有一逆时针的旋转光标
// 进度条的百分比加载到100就是加载完毕
while(cnt <= 100)
{
printf("\033[40;34m[%-100s][%d%%][%c]\033[0m \r", set, cnt, label[cnt % 4]); // \r回车让光标回到开头
fflush(stdout); // 上面输出的内容会放到缓冲区,要即使刷新
set[cnt++] = STYLE; // 每循环一次就多加一个元素,这样模拟进度条
// 每次输出要停一下,不然一下就弄完了
usleep(50000); // 由于sleep暂停太久了。单位是秒,这里用usleep,单位是微秒
// 这里就是每次停50000微秒,就是0.05秒,会停100次,一共需要5秒
// 这里是模拟卡进度条
if(cnt == 58)
{
sleep(3);
}
}
printf("\n");
}
关于下面代码的一些解释:
printf("\033[40;34m[%-100s][%d%%][%c]\033[0m \r", set, cnt, label[cnt % 4]);
- [%d%%] 后面有两个%%是因为%是特殊符号需要2个表示显示%本体
- \033[40;34m \033[0m是c语言的颜色代码的格式
这里可以参考这篇博客
- [%-100s] 的-100是预留100个长度并且是左对齐的
- [cnt % 4]是因为label这个数组有效元素是4个元素。为了达到旋转光标的效果,这里只能取 0、1、2、3,这样只需要让cnt % 4 就可以做到
- \r是回车,让光标回到该行的开头
process.h的代码:
#pragma once
# include<stdio.h>
# include<string.h>
# include<unistd.h>
// 用来确定数组的长度
#define N 101
//用来确定进度条的符号
#define STYLE '>'
extern void ProncessOn(); // 函数声明
main.c的代码:
# include"process.h"
int main()
{
ProncessOn(); //函数调用,这个函数的定义在其他源文件,声明在头文件
return 0;
}
make编译之后执行的效果如下: