ModelWhale 带来了新一轮的版本更新,期待为大家带来更优质的使用体验。
本次更新中,ModelWhale 主要进行了以下功能迭代:
-
数据管理:新增 mw_python_sdk 支持通过查看、下载、制作、更新数据集
-
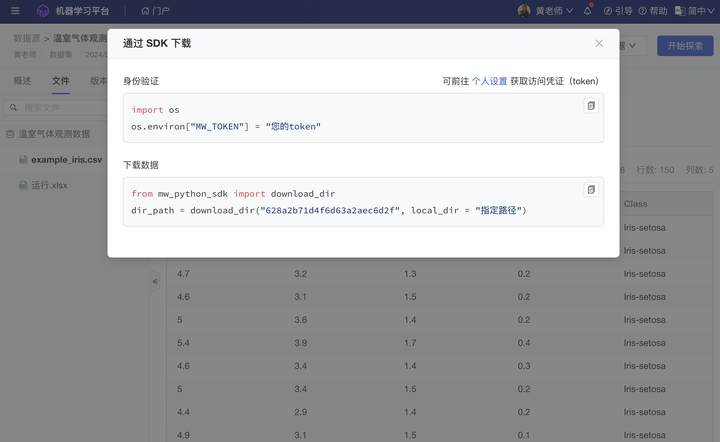
文本标注:新增“关系抽取”标注,满足知识图谱构建、助力 GraphRAG 实践
-
模型服务应用
(1)服务监控:新增记录 TPM 和 RPM 监控指标、调用记录回溯
(2)服务应用:新增 外部文件输入
(3)服务调试:新增 网络环境配置
-
团队协作:新增 我的团队,适用于科研项目组管理、研究小组协同
-
算力管理
(1)新增 由管理员配置“成员可申请的算力”
(2)新增 支持管理员监控服务“最小副本数”
-
智能助手:新增 智谱平台接入,支持在 ModelWhale 使用 智谱 AMiner、AIWorkFlow
-
*仅 ModelWhale 私有化
(1)新增 模型 Repo(新模块):使用 git 命令将外部模型接入平台
(2)视频标注结果:新增 支持转换为 COCO、human3.6m、PoseTrack18 等满足若干开源模型训练的数据规范
(3)待标注数据接入(文本标注):新增 支持解析 json 格式语料
(4)待标注数据接入:新增 从外部 API 数据连接制作平台“标注数据集”
01 数据管理:
新增 mw_python_sdk 支持通过查看、下载、制作、更新数据集
ModelWhale 支持接入企业内多源数据要素,在平台完成数据分析流程中的数据治理(包括元数据管理)、权限分发使用。
-
在本地或第三方平台进行数据分析时,你可以使用 SDK 操作 ModelWhale 平台内你的数据集,包括:查看、下载(无需再手动逐个下载数据集文件)。
-
完成数据产品的开发后,你可以使用 SDK 将成果制作为平台数据集,汇总到 ModelWhale 平台进行统一管理。你也可以将其更新至某个平台数据集。
一些代码示例如下:
(1)查看数据集
pip install mw-python-sdk==0.0.31
from mw_python_sdk import get_dataset
# 读取该数据集 id 下的文件
get_dataset(dataset._id).files响应结果:
[DatasetFile(_id=None, key='dataset/59ad0f2e21100106622a1f0c/1724665346723_1/simple_image.png', size=None, sub_path='')](2)下载数据集
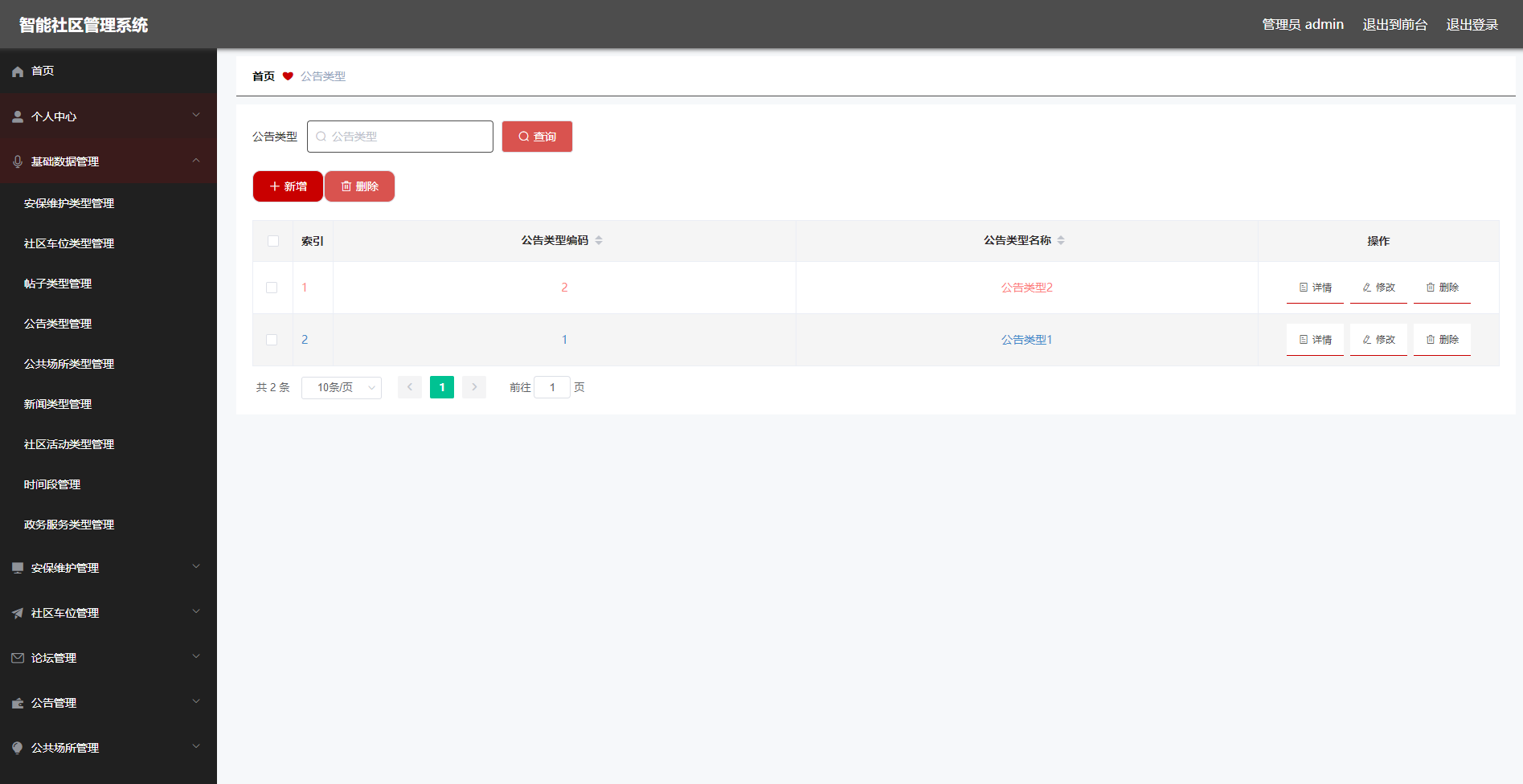
平台数据集详情页,也提供通过 SDK 下载的提示指引。
#import os
#os.environ["MW_TOKEN"]="设置你的token"
#os.environ["HEYWHALE_HOST"]="访问地址,默认可以不设置"
pip install mw-python-sdk==0.0.31
from mw_python_sdk import download_file
dataset_id_tmp = dataset_id
download_file(dataset_id_tmp, "simple_image.png")
(3)制作数据集
pip install mw-python-sdk==0.0.31
from mw_python_sdk import create_dataset
dataset = create_dataset("a_simple_dataset", "dataset_to_upload/", "", "mw is cool")(4)更新数据集
pip install mw-python-sdk==0.0.31
from mw_python_sdk import upload_file
# 上传一个 README.md 文件
upload_file("README.md", "README.md", dataset_id_tmp)02 文本标注:
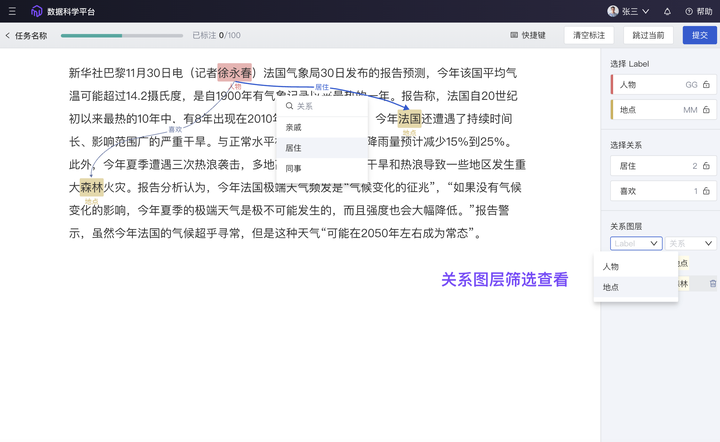
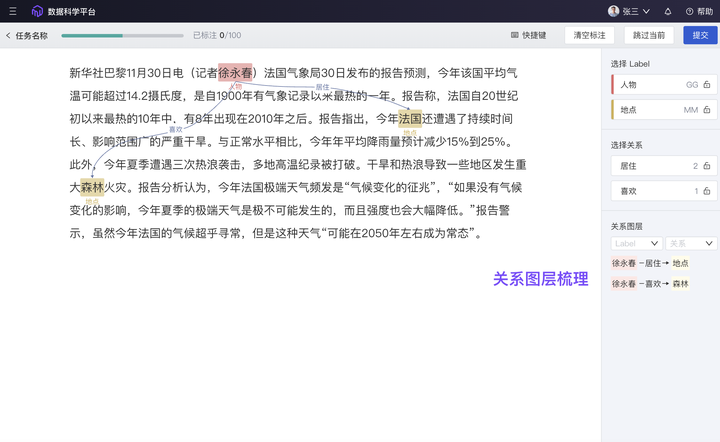
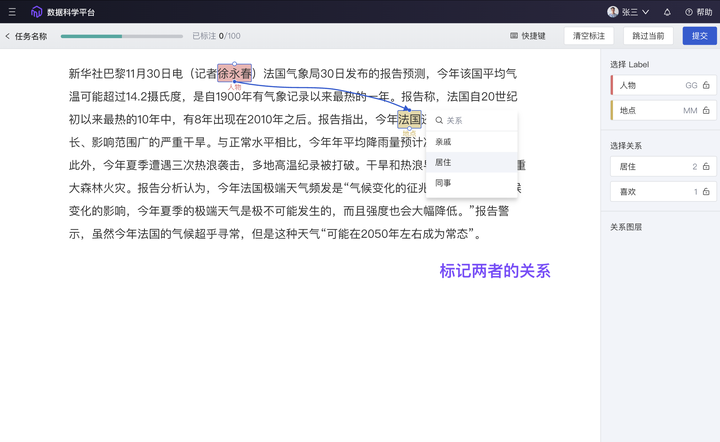
新增“关系抽取”标注,满足知识图谱构建、助力 GraphRAG 实践
GraphRAG(知识图谱 + RAG)是继 RAG 之后进一步提升大模型回答精准度和正确性的重要方式:平台提供三元组标注能力,用户或组织可以通过对错综复杂的文档的数据进行有效的加工、处理、整合,将冗杂信息转化为简单、清晰的“实体-关系-实体”三元组,提取大量高质量知识及知识间关联关系,从而提升大模型在搜索阶段的效果和效率。
ModelWhale 标注工具,新增“关系抽取”的文本标注类型:支持构建满足知识图谱的“实体 - 关系 - 实体”三元组,提取高质量知识及知识间关联关系,从而提升大模型在搜索阶段的效果和效率。具体操作可参考用户手册:
数据标注:
https://www.heywhale.com/docs/org_admin/workbench/annotation.html
03 模型服务应用
ModelWhale 平台的【模型服务】功能支持将算法文件封装为 serverless 服务(Restful API)。
(1)开源大模型的部署:你可以遵循大模型提供方的指引,在 ModelWhale 平台构建依赖的运行环境后,使用平台算力进行模型服务发布。发布时,请选择为“自定义服务”类型、并勾选“生成式大模型”标签。
(2)小工具的封装(比如数据库查询、图像数据分析、统计数据预测等):你可以将代码简单调整后,将其发布为“REST 服务”。代码示例可参考用户手册:
模型服务:
https://www.heywhale.com/docs/org_admin/workbench/model.html
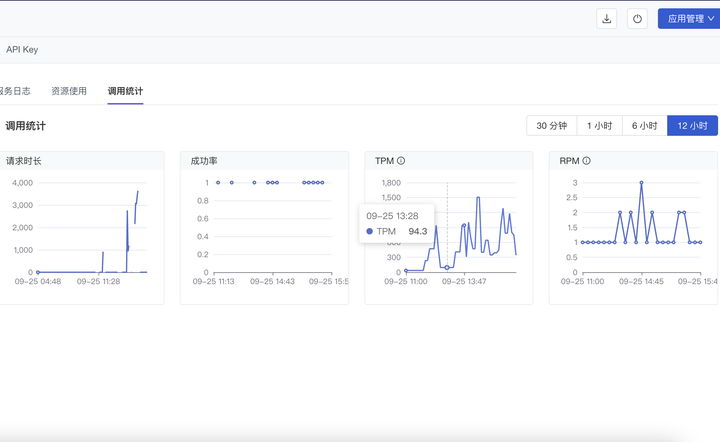
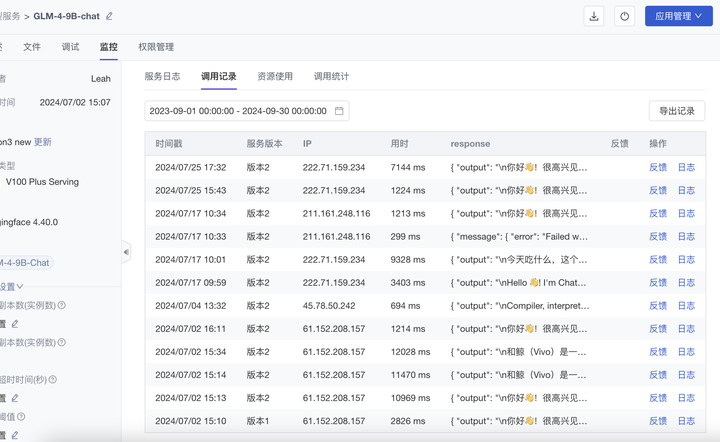
(1)服务监控:新增记录 TPM 和 RPM 监控指标、调用记录回溯
ModelWhale 平台提供完备的服务监控基础设施,帮助模型开发者跟踪服务表现、评估服务性能。本期新增功能如下:
-
新增记录 TPM(Tokens Per Minute,每分钟输入+输出的 tokens 数量):可用于衡量模型的推理速度、评估模型在生成文本或处理输入时的效率。注:仅“生成式大模型”支持记录 TPM。
-
新增记录 RPM(Requests Per Minute,每分钟可以处理的请求数量):可用于衡量 API 或服务的吞吐量、评估模型在并发用户请求下的性能。
-
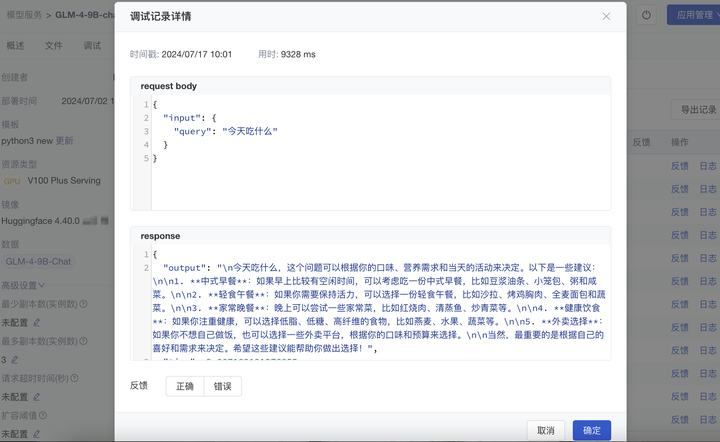
新增 生成式大模型的调用记录:记录每次请求的输入、输出、请求时间等。
-
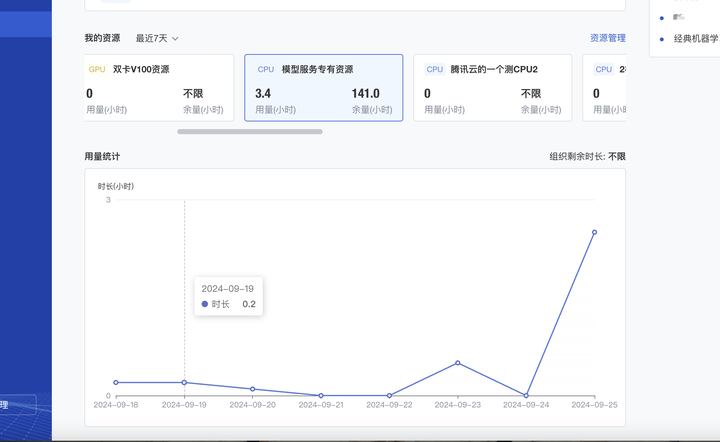
服务资源用量,支持在服务详情页监控,也支持在工作台(最近)查看统计用量。
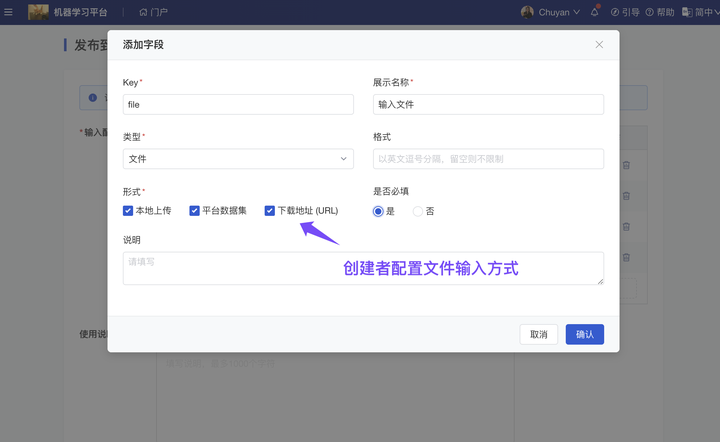
(2)服务应用:新增 外部文件输入
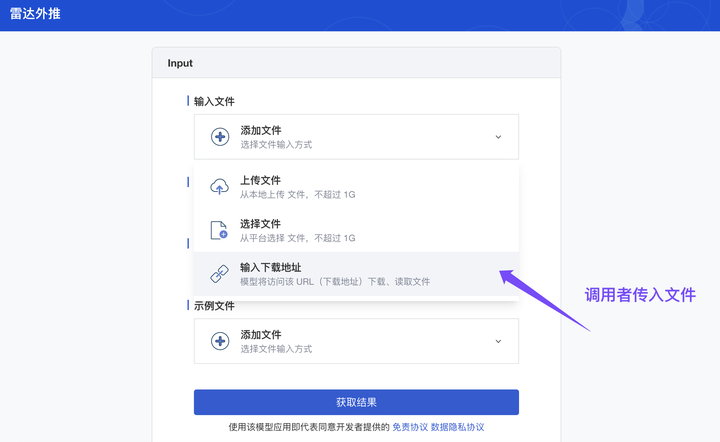
ModelWhale 模型服务 API 支持接入第三方平台(GUI 平台、Agent 编排平台)作为模型或 API 工具使用。你也可以在 ModelWhale 平台将其发布为网页应用(一个 Web 链接),然后将其分享给其他人使用。
模型应用除已支持选择“平台数据集”作为文件输入外,现也支持输入“外部文件”:使用服务时,支持传入“文件下载链接”作为服务推断输入。
(3)服务调试:新增 网络环境配置
不同网络环境下的服务表现不同,“断网”和“不断网”的表现尤其不一致。现创建服务时已新增“网络配置”,供你选择应用场景适用的网络环境:你可以选择组织默认网络环境,也可以选择特定评估任务、比赛任务的网络环境。

04 团队协作:
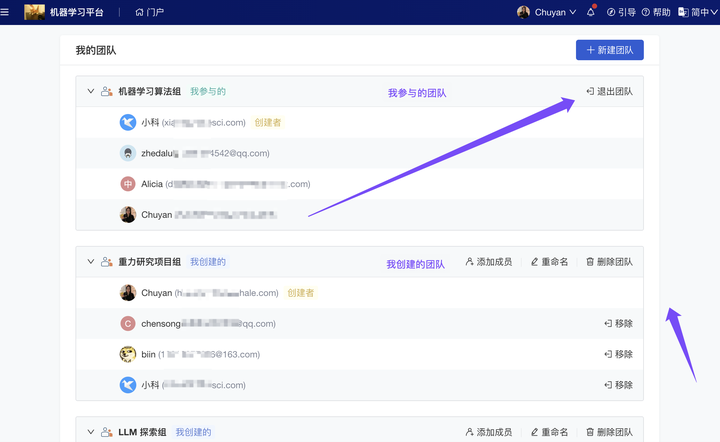
新增 我的团队,适用于科研项目组管理、研究小组协同
一个大科研机构内往往存在多个科研团队,人员管理、内容分享和沉淀也以这些“团队”为单位进行、由团队管理员管理自己的“小组织”。ModelWhale 数据科学协同平台支持承载上述团队管理场景:现除了支持由组织管理员在平台层面进行统一管理外,已支持由组织成员自由搭建自己的团队(比如:**科研小组、**研究小组),闭环实现自己的团队管理、团队内容分发。无需再由组织管理员操作这些小团队的创建、人员管理。

05 算力管理
ModelWhale 支持接入多种算力资源,包括 CPU、GPU、GPU 集群、HPC 集群。这些资源接入平台后,可由管理员按平台内分发单位(可用时长 或 资源代币)进行算力的向下分发。
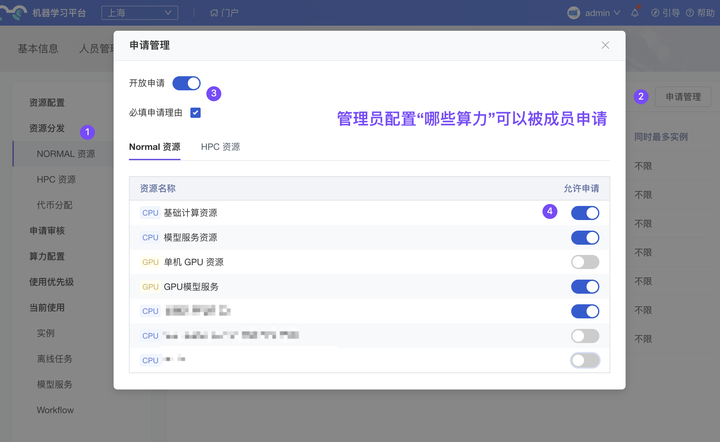
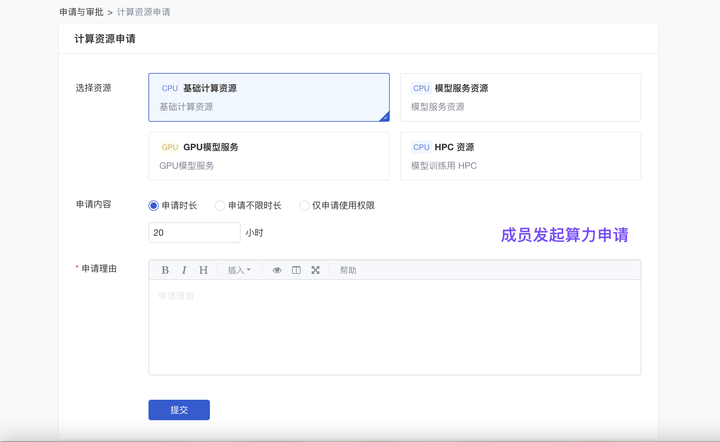
(1)新增 由管理员配置“成员可申请的算力”
如组织成员没有某算力的使用权限、算力可用时长不足,可在线上发起申请、由管理员审批后二次下发。现已支持由管理员配置“哪些算力”可以被成员申请,实现更严格的管理。注:如管理员不希望成员自由申请资源,可关闭【资源申请】功能。
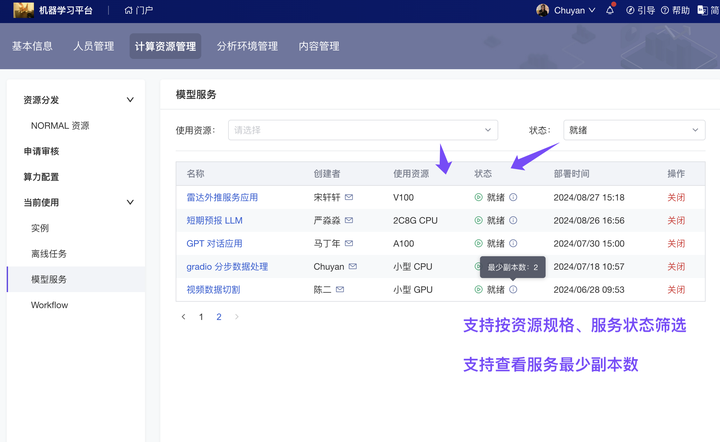
(2)新增 支持管理员监控服务“最小副本数”
管理员查看组织服务时,现已支持查看其“最小副本数”、创建者联系方式、筛选服务状态和使用资源等操作。如管理员觉得不符合预期,可以联系成员了解详情、也可以手动停止服务运行。
06 智能助手:
新增 智谱平台接入,支持在 ModelWhale 使用 智谱 AMiner、AIWorkFlow
ModelWhale 已和智谱达成合作,你可以在 ModelWhale 平台内使用智谱 AMiner、AIWorkFlow。以教学场景为例,你可以使用 ModelWhale 作为主平台承载虚拟实验室的课程管理(第一课堂),使用智谱作为外部学习工具(第二课堂)。
07 *仅 ModelWhale 私有化支持
(1)新增 模型 Repo(新模块):使用 git 命令将外部模型接入平台
ModelWhale 平台支持对算力、数据、模型进行统一管理和分发使用。平台原先已提供“模型库”对象存储基础设施进行模型存储,满足小模型的接入和管理场景。在大模型的浪潮下,现新增“模型 Repo”模块,支持用户使用 git 命令将外部模型接入平台,解决原先大模型难以接入的问题(比如:“模型过大”、“模型上传速度慢”、“网页上传不稳定”、“使用模型时加载速度慢”)。接入模型后,用户依然可以使用 git 对大模型本身进行版本管理,无需改变原有工作习惯。
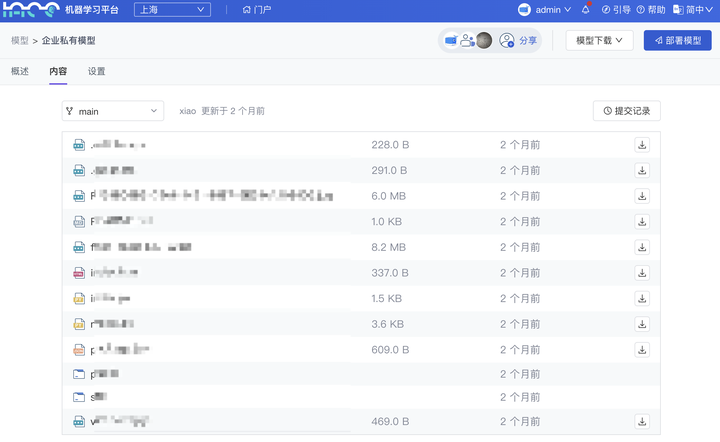
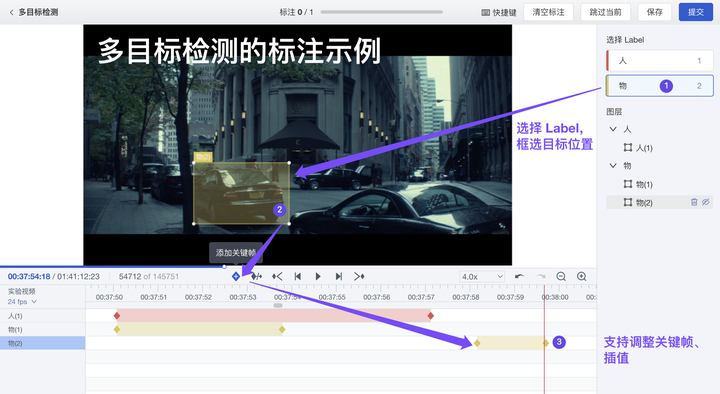
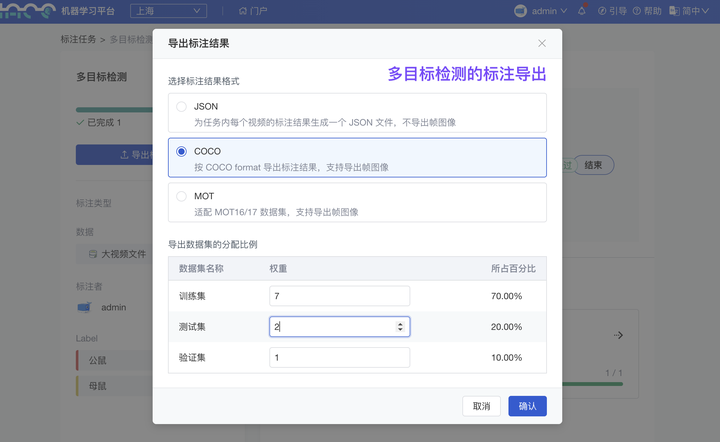
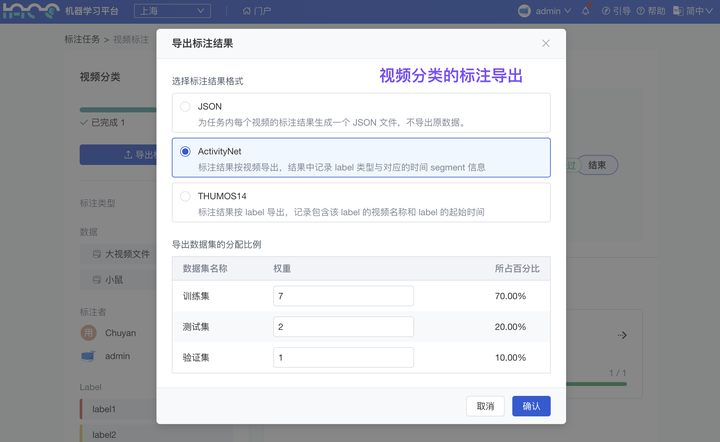
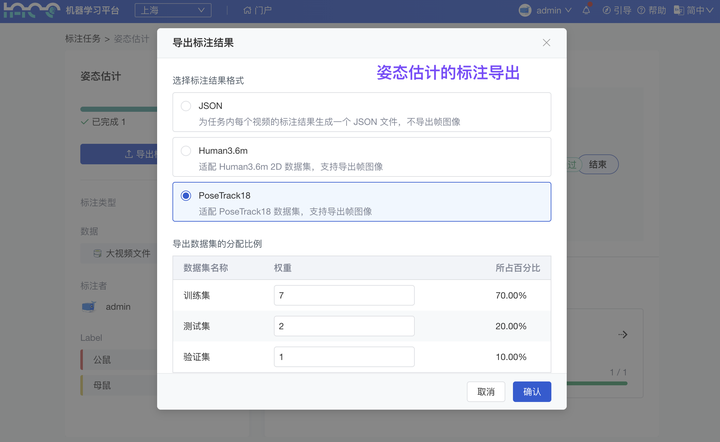
(2)视频标注结果:新增 支持转换为 COCO、human3.6m、PoseTrack18 等满足若干开源模型训练的数据规范
应用场景不同的模型所需的训练数据格式不同,比如:
-
(视频分类)时序动作定位,使用:ActivityNet、THUMOS14
-
(目标检测)多目标追踪,使用:COCO、MOT16/17
-
(姿态估计)姿态追踪,使用:COCO、PoseTrack18
-
(姿态估计)行为检测,使用:human3.6m
平台视频标注支持“视频分类”、“目标检测”、“姿态估计”的标注类型,标注后的数据结果现已均支持上述数据格式的转换。导出时,你还可以分配结果导出的数据集(“训练集”、“测试集”、“验证集”)的比例,更快完成模型输入数据的制作、切分。
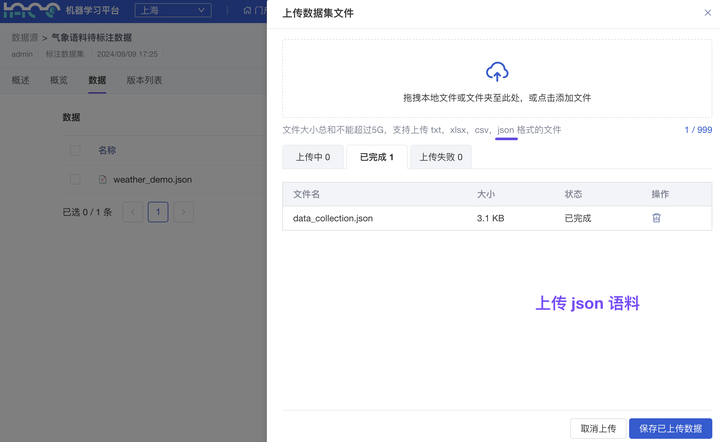
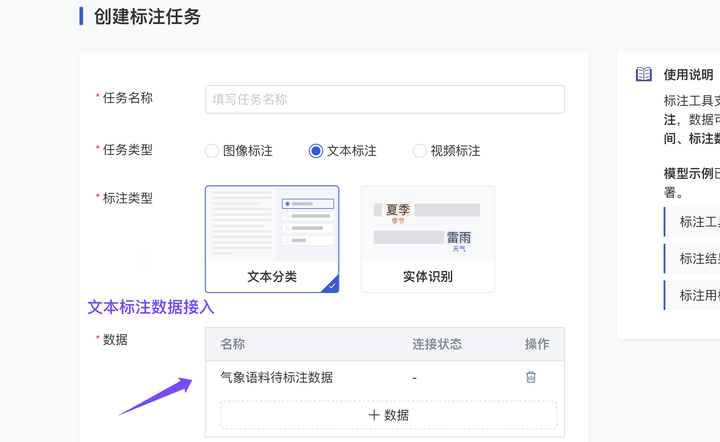
(3)待标注数据接入(文本标注):新增 支持解析 json 格式语料
较严格的语料规范中,每篇语料除主体内容外还会包含很多属性描述信息。这种情况下,语料往往采用 json 格式存储。ModelWhale 文本标注数据集,现已支持用户上传 json 格式的文件。平台将在你上传后自动完成语料的解析,以便你在 ModelWhale 平台继续进行语料标注处理。
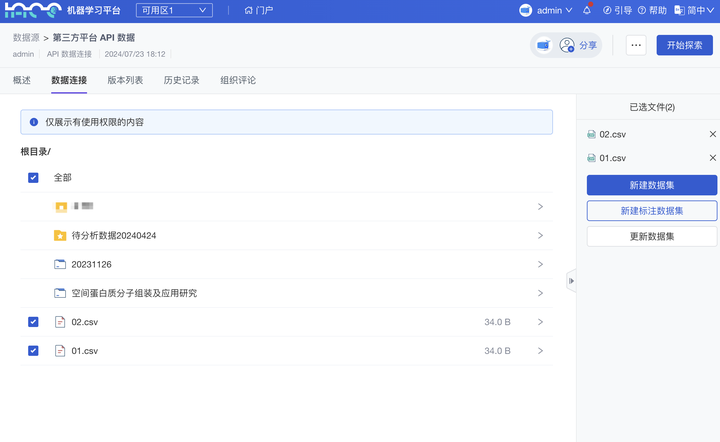
(4)下载数据集待标注数据接入:新增 从外部 API 数据连接制作平台“标注数据集”
ModelWhale 支持接入存储在第三方平台的数据:使用由第三方提供的规范 API 后,可以在 ModelWhale 平台进行数据读取,也可以制作为 ModelWhale 内的数据集、标注数据集(本期新增)进行统一数据管理。
注,如何通过 API 接入第三方平台数据,详见用户手册(该 API 需要第三方平台提供):
数据接入和管理:
https://www.heywhale.com/docs/org_admin/workbench/data.html
08 其他迭代优化
(1)组织成员在平台绑定邮箱后,支持通过“邮件”获取平台内的消息通知,包括:离线任务的运行状态(成功/失败)、内容权限申请通知。
(2)添加协作者时,支持通过邮箱、手机号搜索查询组织成员。
(3)“数据”页新增支持按“元数据”信息筛选。
(4)门户内容均支持配置封面图片,实现更生动的内容展示。注:你可以调用门户接口,将内容展示在企业原有的门户平台。接口信息可咨询你的客户成功经理。
以上,就是本期 ModelWhale 版本更新的全部内容。
点击此处进入 Modelwhale 官网,免费试用 ModelWhale 专业版(个人研究)或团队版(组织协同),获赠 CPU、GPU 算力!(建议使用 pc 端体验试用)
若对 ModelWhale 有任何建议、疑问,或有试用续期需求,欢迎点击这里联系我们,产品顾问 MoMo 很高兴为你服务、与你交流(咨询备注“产品咨询”)。