一、安装,导入
1、安装
使用包管理器安装:
pip3 install pandas2、导入
import pandas as pdas是为了方便引用起的别名
二、DateFrame
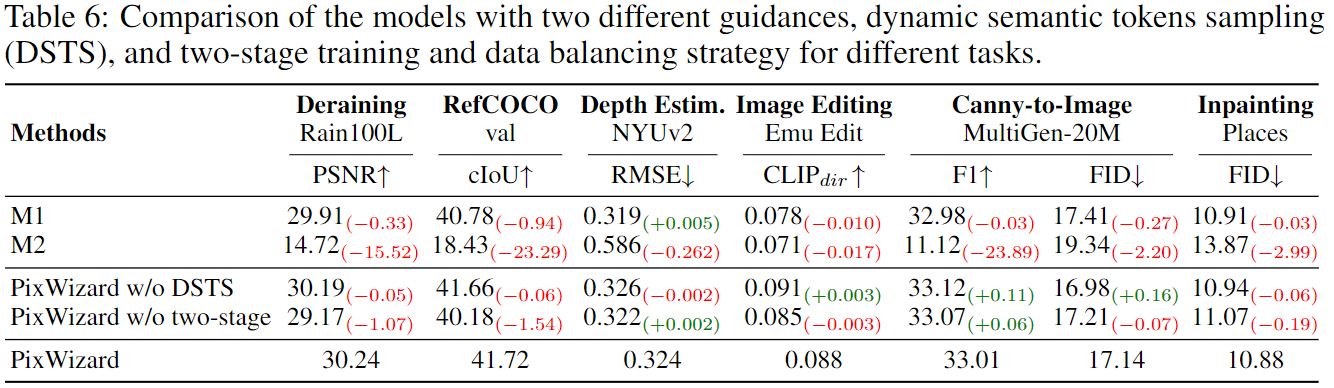
在Pandas库中,DataFrame 是一种非常重要的数据结构,它提供了一种灵活的方式来存储和操作结构化数据。DataFrame 类似于Excel中的表格,具有行和列,其中每列可以是不同的数据类型(数值、字符串、布尔值等)。
1、创建DateFrame
import pandas as pd
# 从字典创建 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']}
df = pd.DataFrame(data)
# 从列表的字典创建 DataFrame
data_list = [{'Name': 'Alice', 'Age': 25, 'City': 'New York'},
{'Name': 'Bob', 'Age': 30, 'City': 'Los Angeles'},
{'Name': 'Charlie', 'Age': 35, 'City': 'Chicago'}]
df_list = pd.DataFrame(data_list)两个对象存储情况:
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
2、查看 DateFrame
# 查看前几行
print(df.head())
# 查看后几行
print(df.tail())
# 查看数据的基本信息
print(df.info())
# 查看数值列的统计信息
print(df.describe())head和tail括号内都可以写数值指定要前几行。默认是5行。
3、选择数据
你可以通过列名、行标签(索引)或条件来选择数据。
# 选择单列
print(df['Name'])
# 选择多列
print(df[['Name', 'Age']])
# 通过行标签选择(假设设置了索引)
# df.set_index('Name', inplace=True)
# print(df.loc['Alice'])
# 通过条件选择
print(df[df['Age'] > 30])当你使用 inplace=True 参数时,这个操作会直接在原DataFrame上进行,而不会返回一个新的DataFrame。之后,你可以使用 .loc[] 索引器来根据新的索引值选择数据。
可以通过设置index属性自定义输出的顺序。
app=data['apples']
#自定义输出序列下标顺序
app=pd.Series(app,index=[0,2,1,3])执行后,会根据索引值的0213顺序赋值给app.
4、添加或删除数据
# 添加新列
df = df.assign(Salary=pd.Series([50000, 60000, 70000]))
# 删除列
df = df.drop(columns=['City'])
# 删除行(通过索引或条件)
# df = df.drop(index=0) # 删除第一行
# df = df[df['Age'] != 30] # 删除 Age 为 30 的行5、数据处理
Pandas 提供了丰富的数据处理功能,如分组(groupby)、聚合(aggregate)、合并(merge)、连接(join)等。
# 分组和聚合
grouped = df.groupby('City').agg({'Age': 'mean', 'Salary': 'sum'})
# 合并两个 DataFrame
df1 = pd.DataFrame({'Key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3']})
df2 = pd.DataFrame({'Key': ['K0', 'K1', 'K2', 'K3'],
'B': ['B0', 'B1', 'B2', 'B3']})
merged = pd.merge(df1, df2, on='Key')6、导出数据
你可以将 DataFrame 导出为CSV、Excel等格式的文件。
# 导出为CSV文件
df.to_csv('output.csv', index=False)
# 导出为Excel文件
df.to_excel('output.xlsx', index=False)将index设置为false可以去掉下标。
7、其他操作
(1)转置
print(date.T)使用DateFrame对象打点调用T可以将矩阵进行转置,也就是将行转为列,列转为行。
(2)排序
#根据内容排序,ascending=False是降序,默认升序
print(date.sort_values(by='A',ascending=False))也可以根据索引排序,就是使用date.sort_values。
三、时间序列和Resample函数
时间序列数据在Pandas中通常存储为DataFrame或Series对象,其中时间戳作为索引。这种结构使得Pandas能够轻松地对数据进行时间相关的操作,如按时间筛选、滚动窗口计算、时间差计算等。
resample()函数是Pandas时间序列对象(DataFrame或Series)的一个方法,它允许用户按照指定的频率对数据进行重新采样。重新采样的过程通常包括两个步骤:首先,根据新的频率对数据进行分组;其次,对每个分组应用聚合函数(如求和、平均、最大值、最小值等)来计算新的值。
# 假设df是一个时间序列DataFrame,时间戳作为索引
# 对数据进行按月重新采样,并计算每个月的平均值
monthly_mean = df.resample('M').mean()参数:
rule:字符串或数字,指定新的采样频率。on:可选参数,指定用于重新采样的列名(如果DataFrame的索引不是时间戳)。closed:可选参数,指定区间的开闭性,'left'、'right'或None(默认为'right')。label:可选参数,指定标签的位置,'left'、'right'或'both'(默认为'right'),或者是一个时间戳数组。convention:可选参数,指定'start'、'end'或'e'(默认为'end'),用于确定在区间边界上的值的归属。loffset:可选参数,用于调整标签的位置。base:可选参数,用于指定时间间隔的起始点(0到23之间的整数)。how或aggregate:可选参数,指定应用于每个分组的聚合函数(如'mean'、'sum'等)。在较新版本的Pandas中,建议使用aggregate参数。
常用的resample聚合函数
-
mean():计算每个分组的平均值。这是时间序列数据分析中最常用的聚合函数之一,用于获取数据的平均水平。
-
sum():计算每个分组的总和。这个函数可以用于计算某个时间段内的累积值。
-
count():计算每个分组中非空(非NA/null)值的数量。这个函数可以用于检查数据的完整性或缺失情况。
-
first():获取每个分组的第一个值。这个函数可以用于提取时间序列数据中的起始点。
-
last():获取每个分组的最后一个值。这个函数可以用于提取时间序列数据中的结束点。
-
min():计算每个分组的最小值。这个函数可以用于识别数据中的最低点或阈值。
-
max():计算每个分组的最大值。这个函数可以用于识别数据中的最高点或峰值。
-
ohlc():计算每个分组的开盘价(first)、最高价(max)、最低价(min)和收盘价(last)。这个函数通常用于金融时间序列数据的分析。
-
prod():计算每个分组的乘积。这个函数可以用于计算某个时间段内数据的累积效应。
-
std():计算每个分组的标准差。这个函数用于衡量数据的离散程度或波动性。
-
var():计算每个分组的方差。方差是标准差的平方,同样用于衡量数据的离散程度。
-
median():计算每个分组的中位数。中位数是一种位置平均数,对于偏态分布的数据具有较好的代表性。
-
quantile():计算每个分组的指定分位数。这个函数允许用户指定一个介于0和1之间的数值作为分位数,以获取数据的不同分位点。
-
apply():应用一个自定义的函数到每个分组。这个函数提供了极大的灵活性,允许用户根据自己的需求编写复杂的聚合逻辑。
四、plot快速可视化
plot可视化需要安装一个matplotlib包
使用包管理器安装matplotlib
pip3 install matplotlib案例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#单样本
df=np.random.rand(1000)
df=pd.DataFrame(df,index=pd.date_range('20210101',periods=1000))
print(df)
df.plot()
plt.show()df是一个新的DataFrame,然后设置一个新的索引,这个索引是一个日期范围,从'20210101'开始,包含1000个日期。plot 方法实际上是Pandas对Matplotlib绘图库的封装,为用户提供了一个简洁的接口来快速生成图表。plt.show是展示出来。
展示图表:

五、读取与存储(pandas)
读取是pandas打点调用‘’read_格式‘’函数,读什么格式的文件就用什么格式。
案例:
读取csv的文件:
pd.read_csv('txt.csv')以下是一些Pandas可读取的主要文件类型:
- CSV(Comma-Separated Values)文件:
- CSV是一种常见的文本文件格式,用于存储表格数据。
- 每行表示一条记录,字段之间用逗号分隔。
- Pandas使用
read_csv函数读取CSV文件。
- Excel文件:
- Excel是一种常见的电子表格文件格式,通常包含多个工作表。
- Pandas使用
read_excel函数读取Excel文件,并可以指定要读取的工作表名称或索引。
- JSON(JavaScript Object Notation)文件:
- JSON是一种轻量级的数据交换格式,易于阅读和编写。
- Pandas使用
read_json函数读取JSON文件。
- SQL数据库:
- Pandas支持从SQL数据库中读取数据,需要使用SQLAlchemy库来创建数据库连接。
- 使用
read_sql或read_sql_table函数从SQL数据库中读取数据。
- Parquet文件:
- Parquet是一种高效的列式存储格式,适用于大规模数据集。
- Pandas使用
read_parquet函数读取Parquet文件。
- HDF5文件:
- HDF5是一种用于存储大量数据的文件格式,支持分层数据存储。
- Pandas使用
read_hdf函数读取HDF5文件,需要指定数据集的键(key)。
- Feather文件:
- Feather是一种轻量级的二进制文件格式,适用于快速读写。
- Pandas使用
read_feather函数读取Feather文件。
- Pickle文件:
- Pickle是Python的一种序列化格式,用于存储Python对象。
- Pandas使用
read_pickle函数读取Pickle文件。
- HTML文件:
- Pandas可以读取HTML文件中的表格数据。
- 使用
read_html函数读取HTML文件,该函数返回一个DataFrame列表,其中每个DataFrame对应HTML文件中的一个表格。
- TXT文件:
- 虽然Pandas没有专门为TXT文件设计的读取函数,但可以使用
read_csv函数通过指定适当的分隔符来读取TXT文件。如果TXT文件的字段是用制表符(\t)分隔的,可以使用sep='\t'参数。
- 虽然Pandas没有专门为TXT文件设计的读取函数,但可以使用
案例2:
向Excel写入:
data.to_excel('excel.xlsx',sheet_name='a')上述代码实现了创建sheet页:a,并向excel.xlsx文件输入data数据。若想追加sheet页:
with pd.ExcelWriter('writerExcel.xlsx',mode='a',engine='openpyxl') as writer:
data.to_excel(writer,sheet_name='d')需要在打开文件时设置属性mode值为:a表示追加
engine参数用于指定用于写入Excel文件的底层引擎。Pandas支持多种引擎来处理Excel文件,但最常用的引擎是openpyxl(用于.xlsx文件)和xlsxwriter。这两个引擎都提供了丰富的功能来创建和修改Excel文件。
-
openpyxl:这是一个用于读写Excel 2010 xlsx/xlsm/xltx/xltm文件的Python库。它支持对Excel文件的读取和写入,包括公式、图表、图像等复杂元素。 -
xlsxwriter:这是一个Python库,用于创建Excel.xlsx文件。它提供了丰富的功能来格式化单元格、添加图表、创建工作表等。
同时添加多个sheet页:
with pd.ExcelWriter('writerExcel.xlsx') as writer:
data.to_excel(writer,sheet_name='a')
data.to_excel(writer, sheet_name='b')
data.to_excel(writer, sheet_name='c')