系列文章目录
使用transformers中的pipeline调用huggingface中模型过程中可能遇到的问题和修改建议
[万字解析]从零开始使用transformers微调huggingface格式的中文Bert模型的过程以及可能出现的问题
文章目录
- 系列文章目录
- 前言
- 模型与数据集下载
- 模型下载
- 数据集下载
- 数据加载、划分与保存
- 数据加载
- 数据集可能造成的问题
- 数据集划分
- 数据集保存和加载
- 数据处理
- 编码
- 按文本长度筛选
- 模型训练与评估
- 模型加载
- 加载评价指标
- 定义评价函数
- 定义训练参数
- 定义训练器
- 模型评估与训练
- 模型保存与加载
- 模型预测
前言
在使用huggingface的模型时,很多情况下已有的模型并不能完全满足实际的需求,这种情况下模型微调是常见的解决方式,在本篇文章中将使用transformers针对huggingface格式的中文Bert分类模型为例介绍微调的过程以及解决在微调过程中可能存在的一些问题。
模型与数据集下载
首要步骤是找到合适的模型及数据集,模型和数据集都可以直接在huggingface或者huggingface的镜像上直接搜索
huggingface链接地址:https://huggingface.co
镜像链接地址:https://hf-mirror.com
模型下载
首先在huggingface(或镜像)主页选择Models,然后输入chinese bert可以查询到很多适用于中文的bert模型,在本篇中选择第一个google-bert作为示例。

也可以直接访问https://huggingface.co/google-bert/bert-base-chinese或https://hf-mirror.com/google-bert/bert-base-chinese
点击进入后查看Model card可以查看chinese-bert的介绍,与之前文章中提到的过程相似,需要下载Files and versions中所有的文件。

下载完成后将所有内容放在同一个文件夹中,笔者的路径是'/huggingface_model/google-bert/bert-base-chinese',可做参考。
数据集下载
在本篇中以中文评价数据集为例,同理在主页上选择Datasets然后输入ChnSentiCorp,或者直接访问https://hf-mirror.com/datasets/XiangPan/ChnSentiCorp_htl_8k,随便选一个即可(为了防止出现额外的问题,请尽量与本篇保持一致)。

打开之后可以看到这个数据集是关于酒店的评价,并且数据是不均衡的,数据不均衡的问题在本篇中按下不表,本篇的重点在于跑通整个过程,读者可以自行查看解决数据不均衡的问题。

选择Files and versions下载数据集,在本篇中只需要下载ChnSentiCorp_htl_8k.csv文件即可,笔者下载到的路径为./datas/ChnSentiCorp_htl_8k/ChnSentiCorp_htl_8k.csv可以作为参考。

数据加载、划分与保存
数据加载
本篇中使用datasets中的load_dataset加载数据,在进行下一步操作前可以先观察一下数据。
数据加载代码:
from datasets import load_dataset
dataset = load_dataset('csv', data_files='./datas/ChnSentiCorp_htl_8k/ChnSentiCorp_htl_8k.csv')
print(dataset)
运行结果:
DatasetDict({
train: Dataset({
features: ['label', 'review'],
num_rows: 7765
})
})
从展示效果上可以看到这是一个嵌套两层的字典,根据关键字进一步观察数据。
print(dataset['train']['label'][:2], dataset['train']['review'][:2])
运行结果:
[1, 1] ['距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦.建议用别的路线.房间较为简单.', '商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错!']
由此可见在本数据集中1表示的是好评,0表示的是差评。
数据集可能造成的问题
在本数据集中6376行中的数据为空,如果不加处理直接使用可能会引起报错,一般来讲,拿到数据集后要检查数据集并需要批量的处理掉空数据,在本篇中用到的数据集只有这一条空数据,可以直接在csv文件中删除后保存后重新读取数据即可。
数据集划分
从csv文件的内容来看数据没有打乱,所以首先需要打乱并显示打乱结果。
dataset['train']= dataset['train'].shuffle()
print(dataset['train']['label'][:5])
print(dataset['train']['review'][:5])
运行结果:
[1, 1, 0, 0, 0]
['酒店地理位置还不错,离外滩、步行街都满近的。我住的是单间,不靠马路,以为会比较安静,哪知窗子外面是酒店内部的一个铁制楼梯,夜晚常有人走过,咣当直响,还有边走边唱歌的,受不了。除了前台小姐面无表情,其它都还行。', '定了高级湖景房,前台给了最高的23层。房间非常舒服,而且早餐也很丰盛。只是看出去的白鹭洲公园景色一般。可能住标准客房更实惠些。', '后悔看了评价。上面老兄的要求也够低的。1)隔音太差2)早餐太差3)卫生间太小4)房间装修太差总的来说就是一经济性酒店。', '总台服务员从我来到走,一直没笑过,很酷!宽带慢的让我想起"猫"的时代!中央空调的声音轰隆隆,热闹!要总台安排第2天一早车去机场,满口答应,退房时没人和我落实,我看着酷酷的成都MM,没问,还是自己拉着箱子走到100米外的路口打车!', '很不怎么样的酒店,根本不象三星级。1、大堂:受理很慢,且服务员连你好都不会说;2、房间:我订的是大床房间,电视机很旧,卫生间里洗澡的地方是用玻璃隔起来的,空间很狭小,而且热水放出来的里面全是棕红色的铁锈,洗澡时水温忽冷忽热;比较变态的是,房间里没有预备网线,你得打电话要,而且电源插座很不合理,如果要插笔记本电源,需要把电视柜往前搬至少50厘米,否则你是找不到插孔的;3、订餐:按照《服务指南》,我打了8003,提示无此号码,于是拨打8006查询,告知我打8033,打过去以后又让我打8031,订个餐有这么麻烦吗?好不容易打通了,要了红烧草鱼、清炒土豆丝和紫菜汤,结果巨难吃,还不如外边随便一个小餐馆做的好吃,反而花了70多元,根本不是三星级酒店厨师做的,让人愤慨!紫菜汤的颜色就像是刷锅水!紫菜也是大片大片的!3、服务:打电话要了网线,过了很久,难道绿洲饭店很大吗?要走那么久?!绿洲饭店我已经住过好几次了,这次是最差劲的!!!给各位推荐立达宾馆,性价比很好,服务也特别好,而且做的菜很有家常口味,吃起来很可口!虽然远了一点,但是打车到市中心,也不过7元钱而已。唯一不足的就是没有宽带连接。补充点评2007年8月16日:还有一点最让人无法忍受:隔音太差了!我的房间隔壁住了个醉汉,那个呻吟声和鼾声,简直就像在同一个房间一样,而且看电视的声音和说话的声音都很清晰!']
在打乱的基础上根据数据集的长度按比例划分训练集和测试集。
length = len(dataset['train'])
train_len = int(length * 0.8)
test_len = int(length * 0.2)
train_dataset = dataset['train'].select(range(train_len))
test_dataset = dataset['train'].select(range(train_len, length))
数据集保存和加载
根据划分好的训练数据和测试数据重新构建数据,将训练数据和测试数据使用datasets.DatasetDict构建成新的数据集。
from datasets import DatasetDict
dataset_dict = DatasetDict({
'train': train_dataset,
'test': test_dataset
})
print(dataset_dict)
运行结果:
DatasetDict({
train: Dataset({
features: ['label', 'review'],
num_rows: 6212
})
test: Dataset({
features: ['label', 'review'],
num_rows: 1553
})
})
使用save_to_disk将处理过的数据保存
dataset_dict.save_to_disk('ChnSentiCorp')
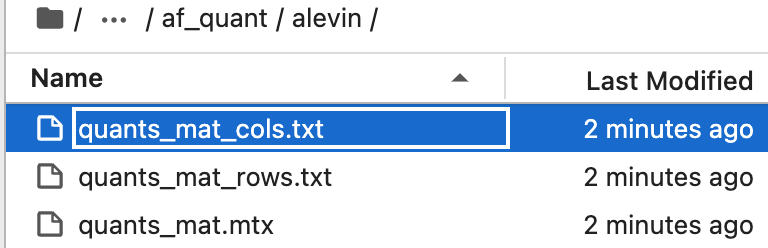
保存好的数据在ChnSentiCorp文件夹中的本地结构如下:

使用load_from_disk可以加载保存好的数据
from datasets import load_from_disk
dataset = load_from_disk('ChnSentiCorp')
print(dataset)
运行结果:
DatasetDict({
train: Dataset({
features: ['label', 'review'],
num_rows: 6212
})
test: Dataset({
features: ['label', 'review'],
num_rows: 1553
})
})
数据处理
在DatasetDict对象中,可以采用map来批量的处理数据,采用filter来批量的筛选数据。
编码
不同模型间的编码方式可以也不同,所以编码的过程需要用到下载好的模型,在transformers中提供了一个自动获取Tokenizer的函数AutoTokenizer。在上文中观察到关键字review是数据中文本部分,所以需要对review字段进行编码。
其中truncation=True指定如果输入的文本长度超过了模型处理的最大长度(这个长度通常在tokenizer初始化时设置),则文本将被截断以适应这个长度。这对于保持批处理的一致性非常重要,因为模型通常要求所有输入具有相同的长度。
在使用map处理数据时最好使用批处理(设置参数batched=True),通过设置batch_size来调整每批的大小,num_proc来设置运行的进程,读者可以根据设备内存适当调整。
def f(data):
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('../huggingface_model/google-bert/bert-base-chinese')
return tokenizer.batch_encode_plus(data['review'], truncation=True)
dataset = dataset.map(f, batched=True, batch_size=1000, num_proc=4, remove_columns=['review'])
print(dataset)
运行结果:
DatasetDict({
train: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 6212
})
test: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 1553
})
})
按文本长度筛选
通常情况下序列长度越长,获取到的信息也就越多,但是随着序列长度的增加,运算代价也在增加,但对于本任务中仅需要部分文本信息就可以得出对于旅店的好评或者差评,并且数据量足够大,所以在此可以选择筛选掉超过一定长度的文本(这相当于直接舍弃了超过整个长度的数据,但是在数据量不足的情况下一般会选择截断或者将一整段话拆成几段)。
def f(data):
return [len(i)<=512 for i in data['input_ids']]
dataset=dataset.filter(f, batched=True, batch_size=1000, num_proc=4)
print(dataset)
运行结果:
DatasetDict({
train: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 6054
})
test: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 1508
})
})
从filter后的效果可以看出整个过程就是按照条件筛选出符合条件的数据,不符合条件的数据会被直接删掉。
模型训练与评估
模型加载
from transformers import AutoModelForSequenceClassification
import torch
model=AutoModelForSequenceClassification.from_pretrained('../huggingface_model/google-bert/bert-base-chinese', num_labels=2)
#统计模型参数量
print(sum([i.nelement() for i in model.parameters()]))
运行结果:
102269186
加载评价指标
如果能够很顺利的访问github,直接使用以下代码会自动下载用于评价精度的accuracy.py,等待下载成功后即可正常运行。
from datasets import load_metric
metric = load_metric('accuracy')
但是如果不能正常访问github或是有在断网情况下使用的应用场景,就会有如下报错。

出现报错后将报错中的链接复制到浏览器

这个文件就是所需的accuracy.py,下载后记录下所在地址,笔者的地址是/metrics/accuracy。然后使用下述代码即可执行。特别注意trust_remote_code=True这一参数的设置,这是因为直接加载一个.py文件会存在安全风险,在直接加载.py文件时将会直接不设防的执行其中的代码,所以一般情况下这一行为将会被阻止。所以需要额外的设置这一参数,需要注意的是,这一参数设置为True时需要确保.py文件足够被信任。
from datasets import load_metric
metric = load_metric('./metrics/accuracy', trust_remote_code=True)
定义评价函数
在评价函数中,eval_pred包含预测结果(概率格式)和实际标签,所以运算过程就是先根据预测结果的概率获取预测的标签,再对比预测标签和实际标签获取的模型的精度。
import numpy as np
from transformers.trainer_utils import EvalPrediction
def compute_metrics(eval_pred):
logits, labels = eval_pred
logits = logits.argmax(axis=1)
return metric.compute(predictions=logits, references=labels)
定义训练参数
参数的定义比较简单,对照的注释很好理解。
from transformers import TrainingArguments
args = TrainingArguments(
output_dir='./output_dir', #定义临时数据保存路径
evaluation_strategy='steps', #定义测试执行的策略,可取值为no、epoch、steps
eval_steps=50, #定义每隔多少个step执行一次测试
save_strategy='steps', #定义模型保存策略,可取值为no、epoch、steps
save_steps=50, #定义每隔多少个step保存一次
num_train_epochs=1, #定义共训练几个轮次
learning_rate=1e-4, #定义学习率
logging_dir='./logs', # 日志文件夹
logging_steps=50,
weight_decay=1e-2, #加入参数权重衰减,防止过拟合
per_device_eval_batch_size=32, #定义测试和训练时的批次大小
per_device_train_batch_size=32,
)
定义训练器
训练器的定义只是把前面设置的参数直接传入,容易出问题的是有可能会因为各种包版本不匹配导致评估过程(trainer.evaluate)和训练过程(trainer.train)出现一些奇怪的报错。
from transformers import Trainer
from transformers.data.data_collator import DataCollatorWithPadding
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('../huggingface_model/google-bert/bert-base-chinese')
trainer = Trainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
compute_metrics=compute_metrics,
data_collator=DataCollatorWithPadding(tokenizer),
)
可能出现的报错为

实际上这个完全是因为版本没有对应上,可以通过更新包来实现
pip install --upgrade accelerate
pip install --upgrade transformers
pip install --upgrade torch torchvision torchaudio
如果仍然没有解决,可以参考笔者包的版本组合。
| 包名 | 版本 |
|---|---|
| accelerate | 0.34.2 |
| torch | 2.3.1+cu121 |
| torchaudio | 2.3.1+cu121 |
| torchvision | 0.18.1+cu121 |
| transformers | 4.45.1 |
模型评估与训练
在训练之前先观察一下如果不进行训练,直接使用模型会有怎样的效果
模型评估:
trainer.evaluate()
运行结果:
{'eval_loss': 0.888075590133667,
'eval_model_preparation_time': 0.0,
'eval_accuracy': 0.3103448275862069,
'eval_runtime': 21.5519,
'eval_samples_per_second': 69.971,
'eval_steps_per_second': 2.227}
从运行结果上来看,精度还没有到50%,比随机分的效果还要差一点。所以训练是有必要的(有些情况下,比如可以找到类似任务的模型的情况下,如果在自己的数据集上能有较好的效果就可以不进行训练而直接使用)
模型训练:
trainer.train()
运行结果:

由于我们设置了每隔50个step保存一次,并且保存路径为./output_dir,所以每次的检查点将保存至这个文件夹中。

训练结束后再进行评估
trainer.evaluate()
运行结果:
{'eval_loss': 0.48144271969795227,
'eval_model_preparation_time': 0.0,
'eval_accuracy': 0.7360742705570292,
'eval_runtime': 153.5957,
'eval_samples_per_second': 9.818,
'eval_steps_per_second': 0.313,
'epoch': 1.0}
可以看到在训练后精度得到了显著提高,虽然仍然不算特别高,但由于我们只训练了一轮,这样的结果已经足够令人满意了,如果想得到更高的精度需要更多的训练轮数。
模型保存与加载
模型的保存直接调用save_model,传入的参数是输出目录
模型保存
trainer.save_model(output_dir='./output_dir/save_model')
模型加载
在加载模型前要注意,需要从原模型文件夹中将词表复制到保存的模型的文件夹中,即把'../huggingface_model/google-bert/bert-base-chinese'目录下的vocab.txt复制到'./output_dir/save_model'
复制后'./output_dir/save_model'路径下应该存在以下四个文件

模型加载:
加载过程和加载原模型一致,尤其要注意的是执行这一步是必须的 model.to('cuda'),因为数据和模型必须在同一个设备上,如果没有GPU可用可以去掉或者改为 model.to('cpu')
model_name = './output_dir/save_model'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
model.to('cuda')
模型预测
model.eval()
for i, data in enumerate(trainer.get_eval_dataloader()):
out = model(**data)
out = out['logits'].argmax(dim=1)
for i in range(8):
print(tokenizer.decode(data['input_ids'][i], skip_special_tokens =True))
print(tokenizer.decode(data['input_ids'][i], skip_special_tokens =False))
print('label=', data['labels'][i].item())
print('predict=', out[i].item())
break
运行结果:















![[QT GUI Tips] Qt creator + PySide6 如何让图像控件的尺寸变化和窗口一致](https://i-blog.csdnimg.cn/direct/dc7c242dc5814743810adb686164e579.png)

