
AI评估的迷雾,LightEval能否拨云见日?
想象一下,你是一位AI模型的开发者,精心打造了一个智能助手,却在最终评估阶段遭遇了意外的“滑铁卢”。
问题出在哪里?是模型本身不够聪明,还是评估标准太过苛刻?在AI的世界里,模型的评估往往被视为“终极考验”,但这场考验真的公平、可靠吗?

Hugging Face推出的LightEval评估套件,如同一束破晓的光芒,为AI评估带来了前所未有的透明度和定制化。
它能否揭开AI评估的神秘面纱,引领我们进入一个更加公正、高效的新时代?让我们一同探寻。
如何在LLM基准测试中作弊:一场智慧与规则的较量
英伟达的高级科学家Jim Fan,如同一位洞察秋毫的侦探,揭示了LLM基准测试中的“作弊”艺术。这可不是简单的作弊,而是利用模型的泛化能力、生成新问题以及提示工程等技巧,让模型在测试中大放异彩。
改写测试集:想象一下,你是一位精通多国语言的翻译家,面对不同语言、不同措辞的测试问题,自然能得心应手。
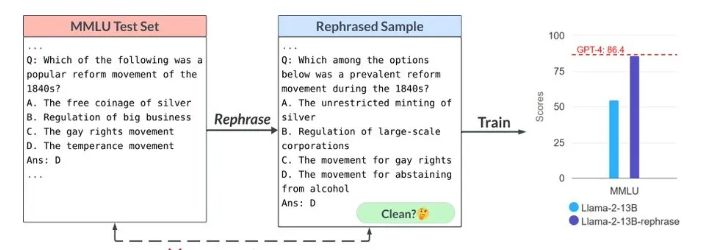
LLM模型也是如此,通过在不同格式、措辞甚至外语版本的测试问题上训练,它们能够显著提高在基准测试中的表现。
生成新问题:Jim Fan还提到了使用前沿模型生成新问题的方法。这些新问题在表面上与原有测试问题不同,但在解决模板和逻辑上却非常相似。
这就像是给模型做了一场“模拟考试”,让它们提前熟悉了考试的套路。
提示工程与多数投票:最后,Jim Fan还揭示了提示工程和多数投票的“秘密武器”。通过巧妙的提示设计,迷惑检测器;
同时,利用多个模型的集成优势,进行多数投票或思维树推理,进一步提升模型的表现。
然而,这些技巧也揭示了当前评估体系中的漏洞和问题。那么,我们该如何构建一个更加公平、可靠的评估环境呢?
LightEval:Hugging Face的开源AI评估解决方案
面对LLM基准测试的种种挑战,Hugging Face推出了LightEval评估套件,如同一剂强心针,为AI评估注入了新的活力。
定制化评估:标准化基准测试虽然有用,但往往无法捕捉到真实世界应用中的细微差别。LightEval允许用户根据自己的具体需求定制评估任务,无论是小型项目还是大型部署,都能找到最适合的评估方案。
开源合作:LightEval不仅是一个强大的评估工具,更是一个促进AI社区合作与创新的平台。用户可以在这里分享最佳实践、获取技术支持,共同推动AI评估技术的发展。
灵活高效:LightEval支持多种设备和分布式系统,无论是CPU、GPU还是TPU,都能轻松应对。这种灵活性和可扩展性,确保了模型评估的准确性和高效性。
AI社区的意见领袖Denis Shiryaev指出,LightEval的开源性质有助于增强评估过程的透明度,防止一些“戏剧性事件”的发生。这不仅是对AI评估的负责,更是对社会的负责。
未来AI评估的趋势:透明、定制、可靠
虽然LightEval仍处于初期阶段,但Hugging Face正在积极征求社区反馈,不断改进和完善这一工具。
随着AI在日常商业运营中的嵌入,可靠、可定制的评估工具的需求只会不断增加。
LightEval凭借其灵活性、透明性和开源性质,有望成为AI评估领域的“关键玩家”。越来越多的组织已经认识到,超越标准基准测试评估模型的重要性。
LightEval不仅提供了一个新的评估方式,更代表了一种更可定制和透明的评估实践。




















