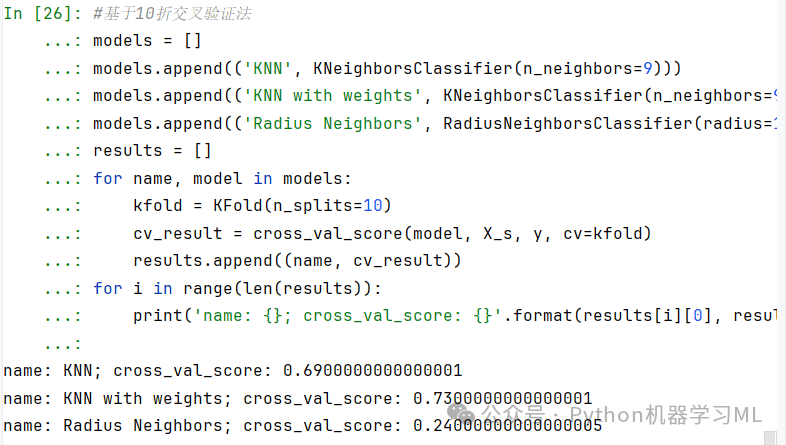
原文标题:Learning Domain Adaptive Object Detection with Probabilistic Teacher
中文标题:基于概率教师学习的域自适应目标检测
代码地址: GitHub - hikvision-research/ProbabilisticTeacher: An official implementation of ICML 2022 paper "Learning Domain Adaptive Object Detection with Probabilistic Teacher"."
论文地址: https://arxiv.org/abs/2206.06293

1、摘要
无监督域自适应目标检测的自训练是一项具有挑战性的任务,其性能在很大程度上取决于伪标签框(pseudo boxes)的质量。 尽管取得了令人鼓舞的结果,但之前的工作在很大程度上忽略了自我训练过程中伪标签框的不确定性。 在本文中,作者提出了一个简单而有效的框架,称为概率教师(PT),旨在从逐渐发展的教师中捕捉未标记目标数据的不确定性,并以互利的方式指导学生的学习。 具体来说,作者建议利用不确定性指导的一致性训练来促进分类适应和定位适应,而不是通过精心设计的置信度阈值过滤伪框。此外,作者将锚点自适应与定位自适应并行进行,因为锚点可以看作是一个可学习的参数。与此框架一起,作者还提出了一种新的熵焦点损失(EFL),以进一步促进不确定性引导的自我训练。配备了EFL, PT比以前的所有基线都要好得多,达到了最新的水平。
2、研究背景
在目标检测任务中,卷积神经网络(CNN)在大规模高质量标注数据上表现卓越。然而,当模型部署到未见过的数据上时,比如不同的天气条件、光照变化或图像损坏等,模型性能会显著下降。为了解决这个问题,提出了无监督域自适应目标检测(UDA-OD)方法,目的是将预训练的模型从标记的源域迁移到未标记的目标域。
3、面临的问题
现有的自训练方法在UDA-OD中依赖于高质量的伪标签框(pseudo boxes),但这些方法很大程度上忽略了自训练过程中伪标签框的不确定性。此外,现有的方法依赖于精心设计的置信度阈值来过滤伪标签,这在没有标注的目标数据可用于阈值调整的情况下是不切实际的。
4、提出的办法
文章提出了一种名为“概率教师”(Probabilistic Teacher, PT)的框架,它通过捕获来自逐渐演变的老师模型的未标记目标数据的不确定性,并以互惠的方式指导学生模型的学习。PT框架不依赖于复杂的置信度阈值,而是利用不确定性引导的一致性训练来促进分类适应和定位适应。此外,文章还提出了一种新颖的熵焦点损失(Entropy Focal Loss, EFL),以进一步促进不确定性引导的自训练。
5、解决的问题
PT框架解决了在UDA-OD设置中,没有标注的目标数据可用于阈值调整的问题。它通过不确定性引导的方法,动态地处理自训练过程中的噪声伪标签,而不是简单地过滤掉它们。
6、取得的效果
PT框架在多个源基/无源UDA-OD基准测试中取得了新的最先进结果,并且与以前的基线相比有了显著的改进。特别是在“正常到雾天”的适应任务中,PT框架通过简单的自训练机制就实现了最先进的结果。
7、总结
文章通过提出概率教师(PT)框架和熵焦点损失(EFL),在无监督域自适应目标检测领域取得了突破性进展。PT框架通过不确定性引导的自训练,有效地处理了目标域中未标记数据的适应问题,提高了模型在不同域之间的泛化能力。
8、伪标签框具体生成过程
8.1、预训练阶段(Pretraining)
- 首先,使用标记的源域数据训练目标检测模型(例如 Faster R-CNN),以初始化检测器。
- 训练完成后,将训练得到的模型权重复制给教师模型(teacher model)和学生模型(student model)。
8.2、互学习阶段(Mutual Learning)
- 教师模型预测:使用教师模型对未标记的目标域数据进行预测,生成伪标签框。这些伪标签框包括类别和定位的概率分布。
- 不确定性表示:利用概率模型(如高斯分布)表示每个预测框的类别和位置,从而捕获预测的不确定性。
8.3、不确定性引导的一致性训练(Uncertainty-Guided Consistency Training)
- 类别和定位概率分布:教师模型为每个预测框生成类别概率分布和定位坐标的概率分布(例如,使用高斯分布表示)。
- 概率分布的锐化(Sharpening):对生成的类别和定位概率分布进行锐化处理,以指导学生模型的训练。锐化是通过调整概率分布的熵来实现的,使得模型更加自信。
8.4、熵焦点损失(Entropy Focal Loss, EFL)
- 熵的计算:对于每个预测框,计算其类别和定位的熵,以此作为不确定性的度量。
- 损失函数的设计:EFL利用这些熵信息来加权损失函数,使得模型更加关注那些不确定性较低(即预测更准确)的预测框。
8.5、教师模型的更新
- 指数移动平均(Exponential Moving Average, EMA):**学生模型学到的知识通过EMA的方式传递给教师模型,从而不断更新教师模型的权重。
8.6、锚点适应(Anchor Adaptation)
- 锚点作为可学习的参数:** 在训练过程中,自动调整锚点的形状以适应目标域中框的尺寸分布。
通过上述步骤,PT框架能够动态地生成和优化伪标签框,同时考虑到预测的不确定性,从而在没有标注的目标域上有效地训练目标检测模型。这种方法特别适用于无监督域自适应目标检测任务,其中没有标注的目标数据可用于调整置信度阈值。
9、什么是概率教师
“概率教师”(Probabilistic Teacher, PT)是文章中提出的一种用于无监督域自适应目标检测(UDA-OD)的框架。这个框架的核心思想是利用一个逐渐演化的教师模型来捕获未标记目标数据的不确定性,并通过不确定性引导的一致性训练来指导学生模型的学习。以下是PT框架的关键特点:
1. 双模型结构:PT框架包含两个模型,即教师模型和学生模型。教师模型用于生成未标记目标数据的伪标签,而学生模型则使用这些伪标签进行训练。
2. 不确定性的表示与利用:在PT中,预测的类别和定位信息都表示为概率分布(如高斯分布),从而能够捕获预测的不确定性。这些不确定性信息被用来引导模型的训练,使其更加关注那些预测较为确定的样本。
3. 不确定性引导的一致性训练:PT框架通过比较教师模型和学生模型的预测来训练学生模型,这种比较是基于不确定性的,目的是促进两个模型之间的知识传递。
4. 熵焦点损失(Entropy Focal Loss, EFL):为了进一步促进不确定性引导的自训练,PT设计了一种新的损失函数EFL。这个损失函数使用预测的熵来加权损失,鼓励模型更加关注那些不确定性较低的预测。
5. 无缝扩展到无源域自适应设置:PT框架可以无缝扩展到无需源数据的UDA-OD设置中,这在隐私敏感的应用场景中非常有用。
6. 锚点适应:PT框架还提出了一种锚点适应的方法,自动调整锚点的形状以适应目标域中框的尺寸分布,从而提高检测的准确性。
总的来说,概率教师(PT)通过模拟教师-学生之间的教学过程,利用概率模型来表示预测的不确定性,并设计了新颖的损失函数来提高无监督域自适应目标检测的性能。