针对“数据8.1”,讲解分类问题的K近邻算法,以V1(转型情况)为响应变量,以V2(存款规模)、V3(EVA)、V4(中间业务收入)、V5(员工人数)为特征变量。
1 变量设置及数据处理
#K近邻算法#载入分析所需要的模块和函数import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.model_selection import KFoldfrom sklearn.model_selection import cross_val_scorefrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import KNeighborsRegressorfrom sklearn.neighbors import KNeighborsClassifier, RadiusNeighborsClassifierfrom sklearn.metrics import mean_squared_errorfrom mlxtend.plotting import plot_decision_regions
data=pd.read_csv(r'数据8.1.csv')X = data.drop(['V1'],axis=1)#设置特征变量,即除V1之外的全部变量y = data['V1']#设置响应变量,即V1X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3, random_state=123)scaler = StandardScaler()scaler.fit(X_train)X_train_s = scaler.transform(X_train)X_test_s = scaler.transform(X_test)
2 构建K近邻分类算法模型
#K近邻算法(K=1)model = KNeighborsClassifier(n_neighbors=1)model.fit(X_train_s, y_train)pred = model.predict(X_test_s)model.score(X_test_s, y_test)#K近邻算法(K=33)model = KNeighborsClassifier(n_neighbors=33)model.fit(X_train_s, y_train)pred = model.predict(X_test_s)model.score(X_test_s, y_test)
3 如何选择最优的K值
scores = []ks = range(1, 33)for k in ks:model = KNeighborsClassifier(n_neighbors=k)model.fit(X_train_s, y_train)score = model.score(X_test_s, y_test)scores.append(score)max(scores)index_max = np.argmax(scores)print(f'最优K值: {ks[index_max]}')#K近邻算法(选取最优K的图形展示)plt.rcParams['font.sans-serif'] = ['SimHei']#本代码的含义是解决图表中中文显示问题。plt.plot(ks, scores, 'o-')#绘制K取值和模型预测准确率的关系图plt.xlabel('K')#设置X轴标签为“K”plt.axvline(ks[index_max], linewidth=1, linestyle='--', color='k')plt.ylabel('预测准确率')plt.title('不同K取值下的预测准确率')plt.tight_layout()
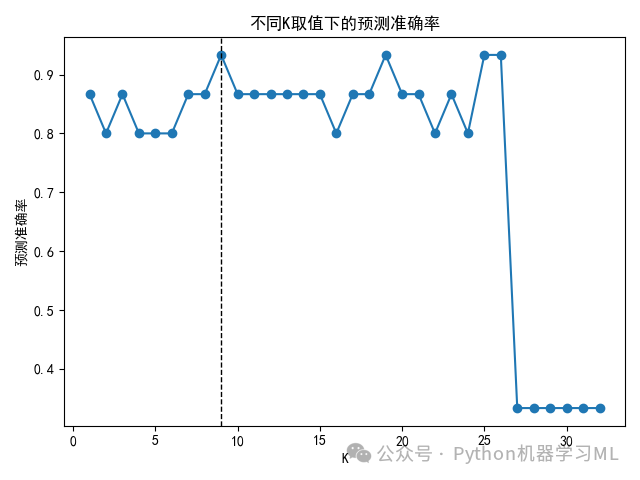
4 最优模型拟合效果图形展示
model = KNeighborsClassifier(n_neighbors=9)#选取前面得到的最优K值9构建K近邻算法模型model.fit(X_train_s, y_train)#基于训练样本进行拟合pred = model.predict(X_test_s)#对响应变量进行预测t = np.arange(len(y_test))#求得响应变量在测试样本中的个数,以便绘制图形。plt.rcParams['font.sans-serif'] = ['SimHei']#本代码的含义是解决图表中中文显示问题。plt.plot(t, y_test, 'r-', linewidth=2, label=u'原值')#绘制响应变量原值曲线。plt.plot(t, pred, 'g-', linewidth=2, label=u'预测值')#绘制响应变量预测曲线。plt.legend(loc='upper right')#将图例放在图的右上方。plt.grid()plt.show()plt.savefig('最优模型拟合效果图形展示.png')
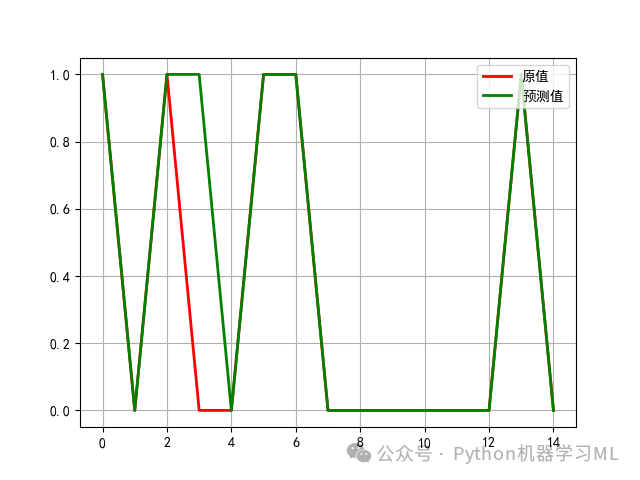
5 绘制K近邻分类算法ROC曲线
scaler = StandardScaler()scaler.fit(X)X_s = scaler.transform(X)plt.rcParams['font.sans-serif'] = ['SimHei']#本代码的含义是解决图表中中文显示问题。from sklearn.metrics import RocCurveDisplay,roc_curve# 计算ROC曲线的值fpr, tpr, thresholds = roc_curve(y, model.predict_proba(X_s)[:, 1])# 使用RocCurveDisplay绘制ROC曲线display = RocCurveDisplay(fpr=fpr, tpr=tpr)display.plot()# 对角线plt.plot([0, 1], [0, 1], color='navy', linestyle='--')# 显示图形plt.show()plt.savefig('K近邻算法ROC曲线.png')
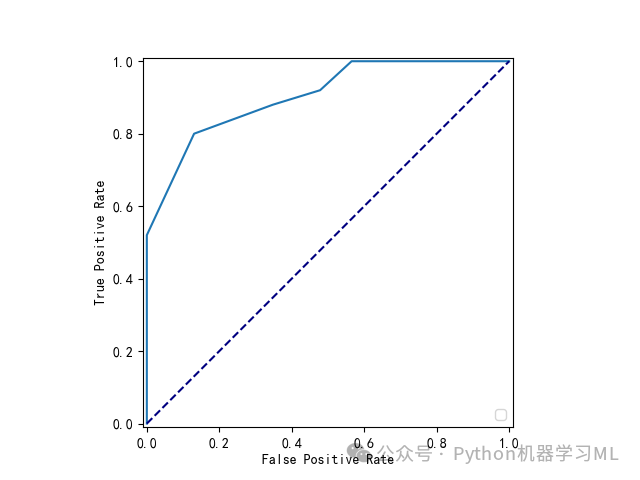
6 运用两个特征变量绘制K近邻算法决策边界图
X2 = X.iloc[:, 0:2]#仅选取V2存款规模、V3EVA作为特征变量model = KNeighborsClassifier(n_neighbors=9)#使用K近邻算法,K=9scaler = StandardScaler()scaler.fit(X2)X2_s = scaler.transform(X2)model.fit(X2_s, y)#使用fit方法进行拟合model.score(X2_s, y)#计算模型预测准确率plt.rcParams['font.sans-serif'] = ['SimHei']#解决图表中中文显示问题plot_decision_regions(np.array(X2_s), np.array(y), model)plt.xlabel('存款规模')#将x轴设置为'存款规模'plt.ylabel('EVA')#将y轴设置为'EVA'plt.title('K近邻算法决策边界')#将标题设置为'K近邻算法决策边界'plt.show()plt.savefig('K近邻算法决策边界.png')
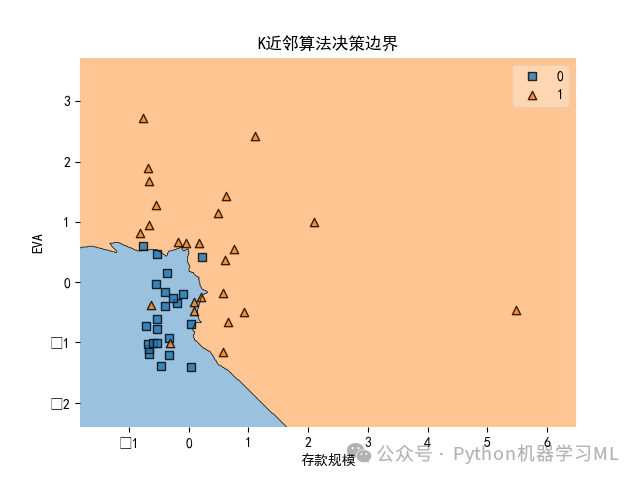
K近邻算法的决策边界是不规则形状,这一边界将所有参与分析的样本分为两个类别,右侧区域为已转型网点区域,左下方区域是未转型网点区域,边界较为清晰,分类效果也比较好,体现在各样本的实际类别与决策边界分类区域基本一致。
7 普通KNN算法、带权重KNN、指定半径KNN三种算法对比
models = []models.append(('KNN', KNeighborsClassifier(n_neighbors=9)))models.append(('KNN with weights', KNeighborsClassifier(n_neighbors=9, weights='distance')))models.append(('Radius Neighbors', RadiusNeighborsClassifier(radius=100)))#基于验证集法results = []for name, model in models:model.fit(X_train_s, y_train)results.append((name, model.score(X_test_s, y_test)))for i in range(len(results)):print('name: {}; score: {}'.format(results[i][0], results[i][1]))

基于10折交叉验证法
models = []models.append(('KNN', KNeighborsClassifier(n_neighbors=9)))models.append(('KNN with weights', KNeighborsClassifier(n_neighbors=9, weights='distance')))models.append(('Radius Neighbors', RadiusNeighborsClassifier(radius=10000)))results = []for name, model in models:kfold = KFold(n_splits=10)cv_result = cross_val_score(model, X_s, y, cv=kfold)results.append((name, cv_result))for i in range(len(results)):print('name: {}; cross_val_score: {}'.format(results[i][0], results[i][1].mean()))
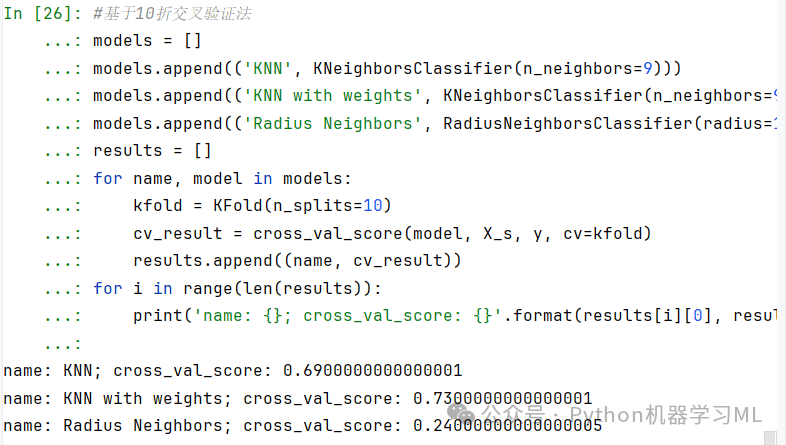
基于10折交叉验证法下带权重KNN算法的预测准确率是最优的,达到了0.73;其次为普通KNN算法,预测准确率达到了0.69;指定半径KNN算法表现非常差,在指定半径为10000时(之所以取这么大,是因为本例中如果把半径设得很小,会导致很多测试样本无法找到近邻值),预测准确率只有0.24。



















