【导读】 尽管大模型能力非凡,但干细活的时候还是比不上人类。为了提高LLM的理解和推理能力,Prompt「复读机」诞生了。
众所周知,人类的本质是复读机。
我们遵循复读机的自我修养:敲黑板,划重点,重要的事情说三遍。
but,事实上同样的方法对付AI也有奇效!
有研究证明,在提问的时候故意重复一遍——也就是复制粘贴,即可显著提高LLM的推理能力。

论文地址:https://arxiv.org/pdf/2309.06275
看下面的例子:

作者认为,通常情况下,问题中的重点token(比如这里的tennis balls)无法看到位于它后面的token(上图)。
相比之下,使用重读(re-reading,RE2)的方法,允许「tennis balls」在第二遍中看到自己对应的整个问题(How many tennis balls does he have now?),从而达到双向理解的效果(下图)。

实验表明,在14个数据集上的112个实验中,RE2技术都能带来一致的性能提升,无论是经过指令调整的模型(如ChatGPT),还是未经调整的模型(如Llama)。
实践中,RE2作为独立的技巧,可以与CoT(Let’s think step by step)以及自我一致性方法(self-consistency,SC)一起使用。
下表展示了混合应用多种方法对模型效果的影响。尽管自我一致性聚合了多个答案,但重读机制仍然有助于大多数场景的改进。

接下来,在GSM8K数据集上(使用ChatGPT)进一步研究输入问题复杂性对CoT和RE2提示的推理性能的影响。
这里通过计算真实解释中存在的推理步骤来衡量问题的复杂性,结果如下图所示。
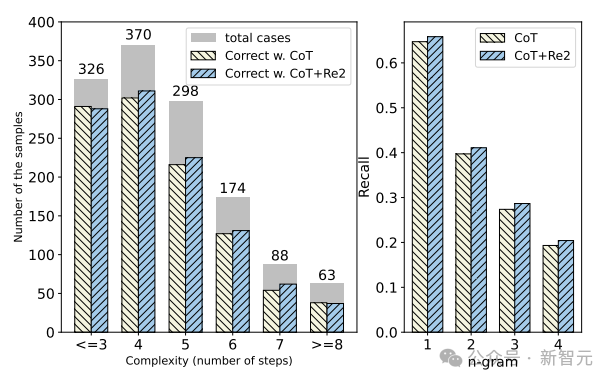
随着问题复杂性的增加,所有提示的表现通常都会下降,但重读的引入提高了LLM应对各种复杂问题的表现。
此外,作者还计算了各代和输入问题之间的覆盖度,证明RE2增加了输出解释中的n-gram (n=1,2,3,4) 召回率。
重要的事情说2遍
现有的推理研究主要集中在设计多样化引导提示,而对输入阶段的理解却很少受到关注。
事实上,理解是解决问题的第一步,至关重要。
当今大多数LLM都采用单向注意力的decoder-only架构 ,在对问题进行编码时,单向注意力限制了token的可见性,这可能会损害对问题的全局理解。

怎么解决这个问题?作者受到人类习惯的启发,尝试让LLM把输入再读一遍。
与引导模型在输出中推理的CoT不同,RE2通过两次处理问题将焦点转移到输入,促进了单向解码器的双向编码,从而增强LLM理解过程。
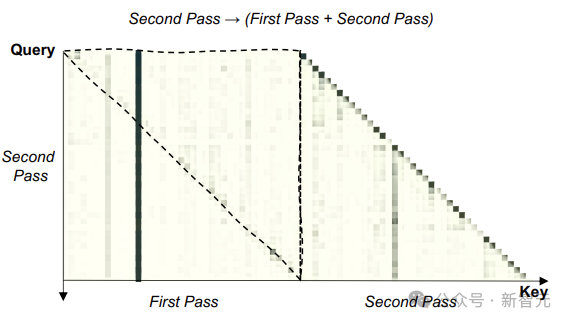
上图为GSM8K数据集上测试的注意力分布图,较暗的单元格表示较高的注意力。
上虚线三角形内的区域表明,第二遍输入中的每个token都明显关注第一遍中的后续token,证明LLM的重读有望实现对问题的双向理解。
从另一个角度考虑,重读使LLM能够为输入编码分配更多的计算资源,类似于水平增加神经网络的深度。因此,拥有RE2的LLM对问题有更深入的理解。
普通推理
利用带有CoT提示的LLM来解决推理任务,可以用公式表述为:
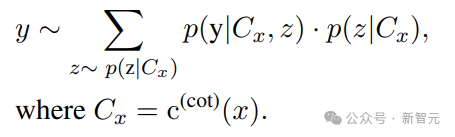
其中,Cx表示提示输入,来自带有CoT提示指令的模板,z表示自然语言中的采样基本原理。
因此, LLM可以将复杂的任务分解为更易于管理的推理步骤,将每个步骤视为整个解决方案链的组成部分。
RE2 推理
受到人类重读策略的启发,将上面的方程改写为:

所以RE2在实际应用中就是下面这种格式:

其中{Input Query}是输入查询的占位符,左侧部分可以包含其他引发思考的提示。
实验
由于RE2的简单性和对输入阶段的重视,它可以与各种LLM和算法无缝集成,包括few-shot、自我一致性、各种引发思考的提示策略等。
为了验证RE2的有效性和通用性,研究人员在14个数据集上进行了112个实验,涵盖算术、常识和符号推理任务。
算术推理
实验考虑以下七个算术推理基准:
数学应用题的GSM8K基准、具有不同结构的数学应用问题的SVAMP数据集、不同数学应用题的ASDiv数据集、代数应用题的AQuA数据集、三到五年级学生的加法和减法数学应用题、多步骤数学问题数据集,以及单次运算的初等数学应用题数据集。
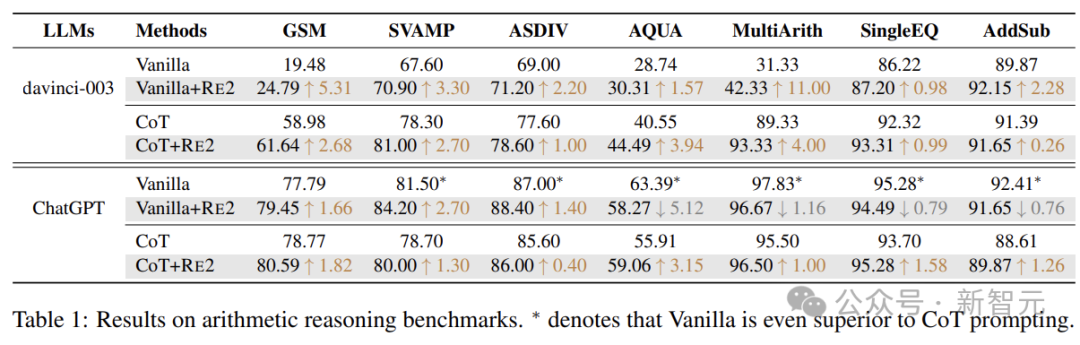
上表为算术推理基准测试结果。*处表示不使用任何技巧,但效果优于CoT提示的情况。
常识和符号推理
对于常识推理,实验采用StrategyQA、ARC和CSQA数据集。
StrategyQA数据集包含需要多步骤推理的问题;
ARC数据集(ARC-t)分为两个集合:挑战集(ARC-c)和简单集(ARC-e),前者包含基于检索和单词共现算法都错误回答的问题;
CSQA数据集由需要各种常识知识的问题组成。
实验评估两个符号推理任务:日期理解和Coinflip。日期理解是 BigBench数据集的子集,Coinflip是一个问题数据集,根据问题中给出的步骤,判断硬币翻转后是否仍然正面朝上。
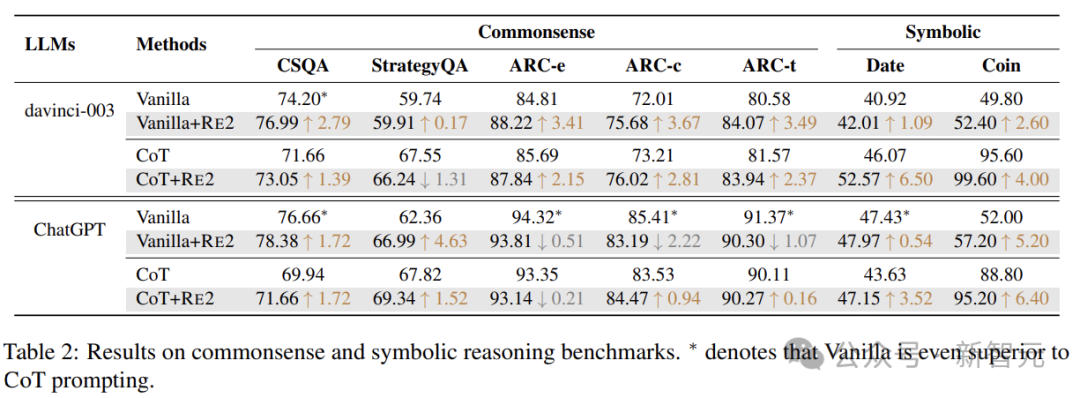
结果表明,除了普通ChatGPT上的某些场景之外,具有简单重读策略的RE2,持续增强了LLM的推理性能。
RE2展示了跨各种LLM的多功能性(Text-Davinci-003、ChatGPT、LLaMA-2-13B和LLaMA-2-70B),涵盖指令微调 (IFT) 和非IFT模型。
作者还对RE2在零样本和少样本的任务设置、思维引发的提示方法以及自洽设置方面进行了探索,突出了其通用性。
Prompting
实验严格评估RE2模型在两种基线提示方法上的性能:Vanilla(不添加特技)和CoT(通过逐步的思维过程来指导模型)。

针对不同的任务,作者在提示中设计了答案格式指令,以规范最终答案的结构,便于精确提取答案。
实验的解码策略使用贪婪解码,温度设置为0,从而产生确定性输出。
最后探索一下问题重读次数对推理性能的影响:
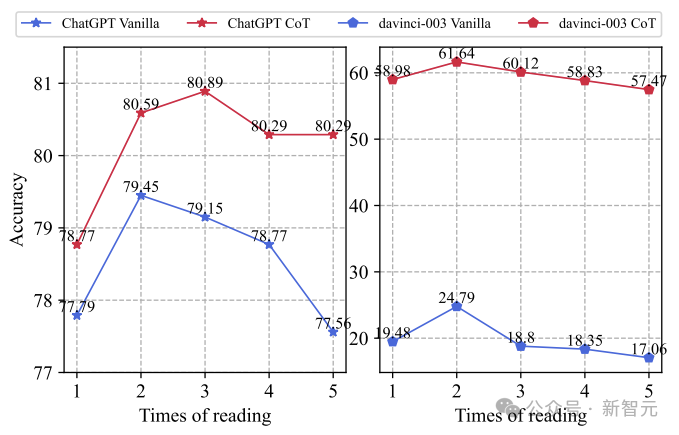
上图展示了两个不同的LLM的表现如何随问题重读次数的变化而变化。我们可以发现重读2次使性能提高,之后随着问题重读次数增加,性能开始下降。
猜测原因有两个:i)过度重复问题可能会起到示范作用,鼓励LLM重复问题而不是生成答案,ii)重复问题会显著增加推理和预训练之间的不一致。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓