GPT(Generative Pre-Training):
训练过程分两步:无监督预训练+有监督微调
模型结构是decoder-only的12层transformer
1、预训练过程,窗口为k,根据前k-1个token预测第k个token,训练样本包括7000本书的内容

2、微调过程,使用有标记的样本,样本输入预训练模型,使用最后一层transformer的输出,接linear+softmax层,预测输出

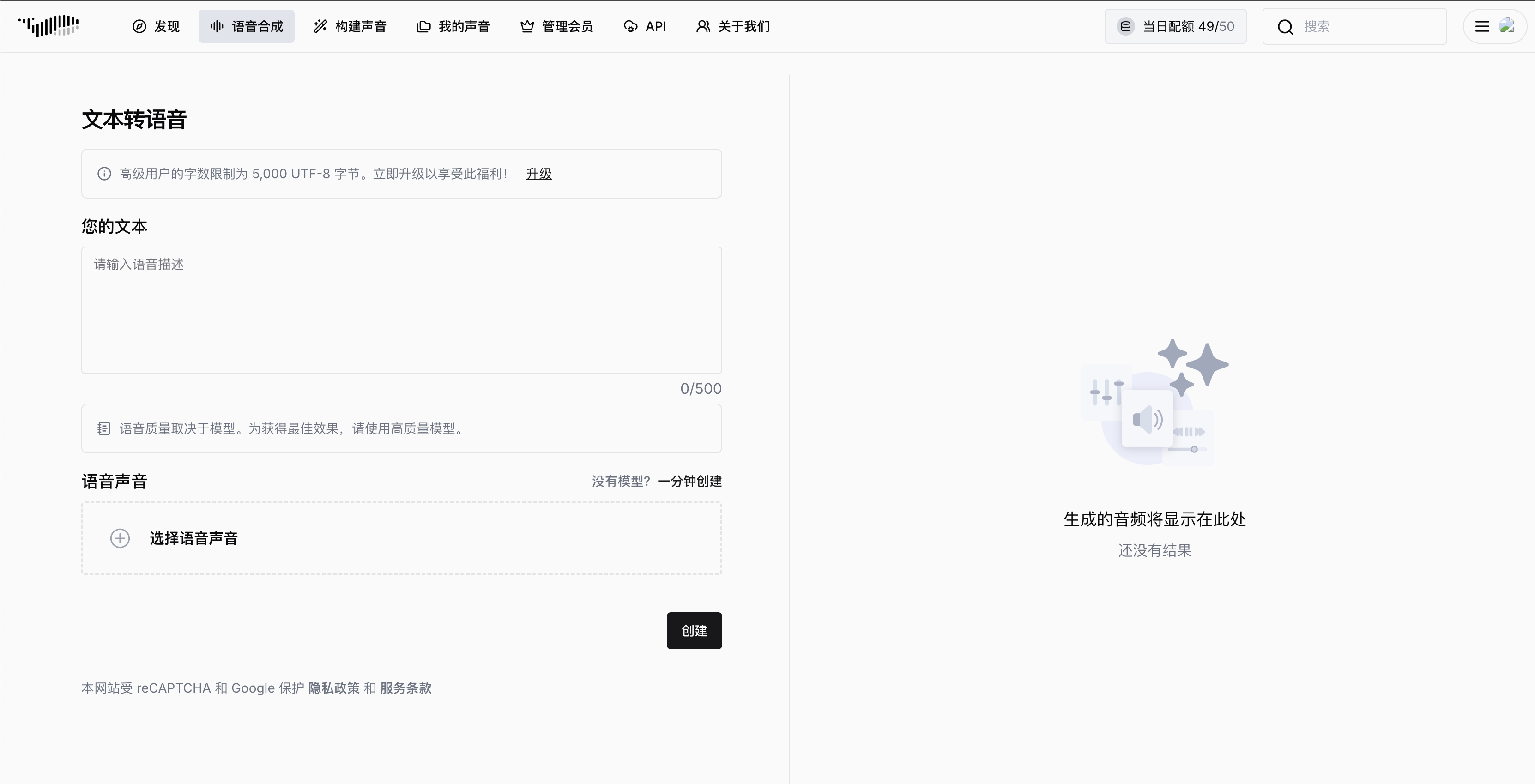
损失函数如下
![]()
使用L1作为辅助优化目标有两点好处,首先能够提高模型的泛化能力,第二是能够加速收敛。
3、不同任务的输入格式适配:将结构化的输入转化为有序序列

GPT系列演化参考文档:简单之美 | GPT 系列模型技术演化之路
GPT-2
与 GPT-1 不同,GPT-2 对每个 Encoder Block 的自注意力层,前后分别都进行了层归一化(Layer Normalization)操作,即在每一层的输入和输出都有一个 Layer Normalization 子层。
在输入自注意力层之前新增 Layer Normalization 层,能够将输入数据的均值和方差分别标准化为 0 和 1,使数据在不同的尺度上保持一致。而且,这种策略能够缓解梯度消失和梯度爆炸的问题。同时,层归一化有助于优化器在更新权重时找到合适的方向,提高模型的训练稳定性和收敛速度。

GPT-3
预训练后,不微调,使用上下文学习(In Context Learning,ICL)
引入稀疏注意力机制

GPT-3 就是使用的普通 Transformer 和 Sparse Transformer 的混合模式。Sparse Transformer 的特点是只关注 Top-k 个贡献最大的特征的状态,它使用稀疏注意力机制替代了 Transformer 的密集注意力。
GPT-3.5/InstructGPT
代码数据训练和人类偏好对齐
基于人类反馈的强化学习算法RLHF
基于GPT-3进行微调,三个阶段的微调方法和过程,可以通过下图给出的步骤来简要说明

分别对应于上面提到的三个模型(SFT 模型、RM 模型、RL 模型),InstructGPT 的训练过程主要包括如下三个步骤:
Step 1: Collect demonstration data, and train a supervised policy.
Step 2: Collect comparison data, and train a reward model.
Step 3: Optimize a policy against the reward model using PPO.
GPT-4
GPT -4是一个多模态大模型
GPT-4 的核心原理是,基于 Decoder-only 的 Transformer 自回归语言模型,即通过给定的文本序列,预测下一个词的概率分布,从而生成新的文本。GPT-4 采用了大规模的无监督预训练和有监督微调的方法,即先在海量的通用文本语料上进行预训练,学习文本的通用特征和规律,然后在特定的下游任务上进行微调,学习任务的特定知识,从而实现对任意文本的生成和理解。
OpenAI在技术报告中强调了GPT-4的安全开发重要性,并应用了干预策略来缓解潜在问题,如幻觉、隐私泄露等。











![[含文档+PPT+源码等]精品大数据项目-基于python爬虫实现的大数据岗位的挖掘与分析](https://img-blog.csdnimg.cn/img_convert/bcd835087bdf6be5c5115e4af597adaa.png)