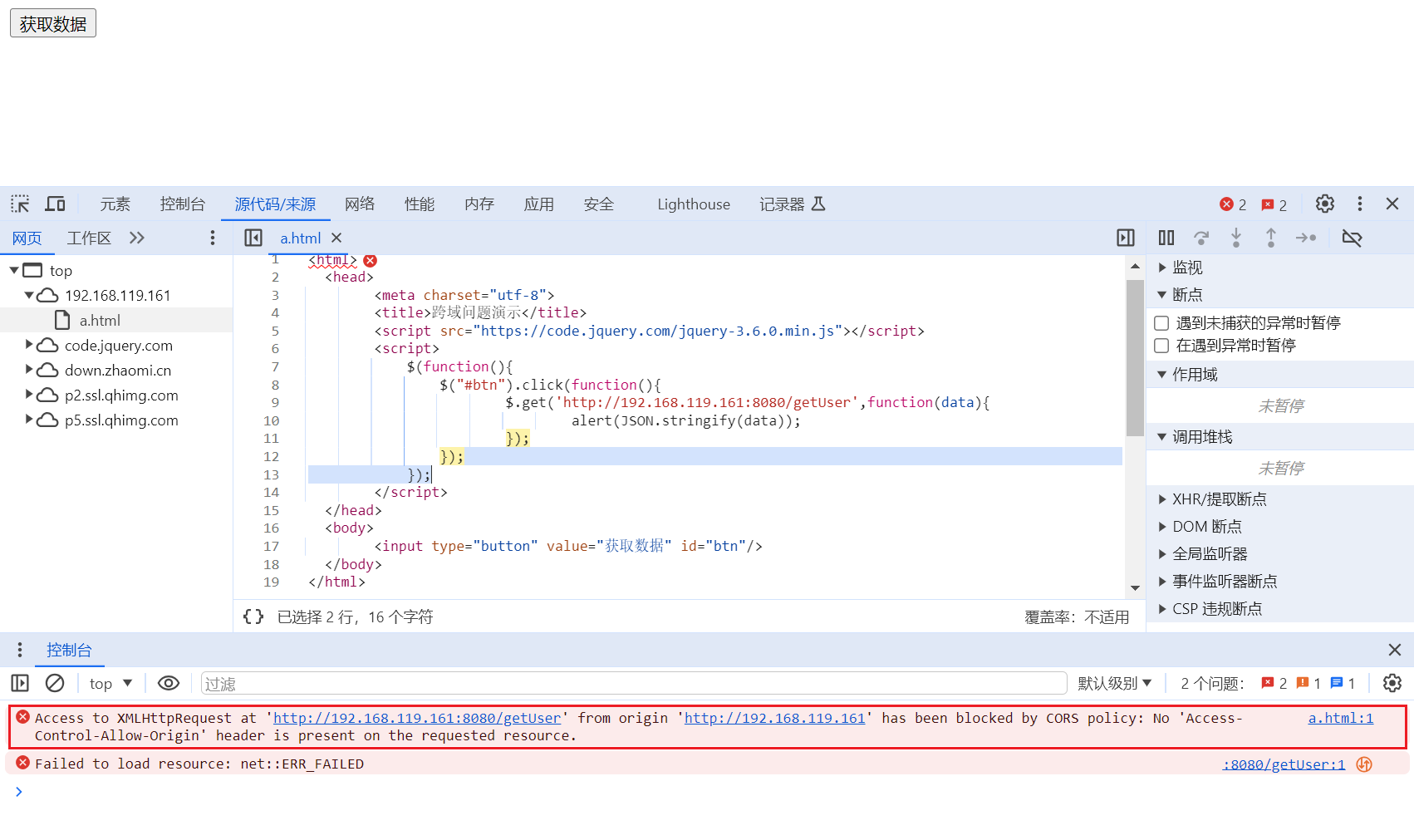
重复值处理:

重复值处理代码:
import pandas as pd
data = pd.DataFrame({
'学号': [1, 2, 3, 4, 5, 6, 7, 7, 8],
'身高': [172,162,175,170,168,160,164,164,160],
'体重': [70,62,75,68,67,58,64,64,53]
})
data.drop_duplicates(['学号'], keep = 'last', inplace=True)
print(data)
# drop_duplicates方法的正确语法是drop_duplicates(subset=None, keep='first', inplace=False),
# 其中keep参数只能是
# 'first'(保留第一次出现的重复行)、
# 'last'(保留最后一次出现的重复行)
# False(删除所有重复行)缺损值删除:

缺损值删除代码:
import pandas as pd
import numpy as np
data = pd.DataFrame({
'学号': [1, 2, 3, 4, 5, 6, 7, 7, 8],
'身高': [172,162,175,170,np.nan,160,164,164,160],
'体重': [70,62,75,68,67,58,64,64,53]
})
data=data.dropna() #只要有空值就删除
data=data.dropna(how='all') #只有当一行中所有值都是缺失值才删除改行,如果至少有一个非缺失值,则改行不会被删除
print(data)
缺损值填充:

缺损值填充代码:
import pandas as pd
import numpy as np
data = pd.DataFrame({
'学号': [1, 2, 3, 4, 5, 6, 7, 7, 8],
'身高': [172,162,175,170,np.nan,160,164,164,160],
'体重': [70,62,75,68,67,58,64,64,53]
})
# data=data.fillna(199) #用199数值填充缺损的数据
# data=data.fillna(method='ffill') #使用缺损值前一行填充缺损值
# data=data.fillna(method='bfill') #使用缺损值后一行填充缺损值
data['身高'].fillna(data['身高'].mean(),inplace=True) #使用身高的均值来填充缺损值
print(data)
异常值填充:

异常值填充代码:
import pandas as pd
data = pd.DataFrame({
'学号': [1, 2, 3, 4, 5, 6, 7, 7, 8],
'身高': [172,162,175,170,1700,160,164,164,160],
'体重': [70,62,75,68,67,58,64,64,53]
})
print("是否存在超出正常身高范围的值:",any(data['身高']>240)) #检查是否存在异常值
renew_value=data['身高'][data['身高']<200].max()
data.loc[data['身高']>200,'身高']=renew_value #用身高最高值填充异常值
print(data)