文章目录
- hive分析汇总
- 互联网日志分析
- 1.项目需求
- 2.数据说明
- 3.算法思路
- 用户电影推荐
- 1.项目需求
- 2.数据说明
- 3.算法思路
- 4.解题步骤
- 简单数据统计WordCount
- 数据说明
- 疫情数据分析
- 1.项目需求
- 2.数据说明
- step1:创建ods层数据表
- step2:创建dwd层数据表
- step3:创建dwm数据处理分析
- step4:创建dws层
- step5:创建app层
- 其他参考设置:
- 交通事故因素分析
- 1.项目需求
- 2.数据说明
- 3.分析思路
- 网络诈骗
- 1.项目需求
- 2.数据说明
- 3.关联规则
- 人口收入数据分析
- 1.项目需求
- 2.Hive安全配置
- 电商运营数据分析
- 1.项目需求
- 2.数据说明
- 3.分析思路
- 贷款数据分析
- 房屋租赁分析
- 1.项目需求
- 2.数据说明
- 共享单车数据分析
- 1.项目需求
- 题目说明
- 提示
hive分析汇总
互联网日志分析
1.项目需求
随着计算机互联网技术的不断发展,社会经济水平的不断提高,各种通讯设备和移动工具的普及,网络成为人们生活的必需品,以某大型网站为例,每小时就产生10G的数据量,网络数据在飞速增长,在大数据时代背景下,需要对数据隐藏价值进行充分挖掘,加强对数据的分析。
对这些数据进行有效利用需要通过大数据相关方面的技术和工具,收集用户的习惯、风格等方面的数据,对用户进行有效的分析,对每个用户制定不同的平台营销与个性化服务。
2.数据说明
数据地址:主机"hadoop/Hive"节点下/root/internetlogs/journal.log
日志分析数据每行记录有8部分组成:访问者IP、访问名称、访问时间、访问资源、访问状态(HTTP状态码)、本次访问流量、链接访问源、浏览器信息。数据如下所示:
194.237.142.21 - - [18/Sep/2013:06:49:18 +0000] "GET /wp-content/uploads/2013/07/rstudio-git3.png HTTP/1.1" 304 0 "-" "Mozilla/4.0 (compatible;)"
183.49.46.228 - - [18/Sep/2013:06:49:23 +0000] "-" 400 0 "-" "-"
163.177.71.12 - - [18/Sep/2013:06:49:33 +0000] "HEAD / HTTP/1.1" 200 20 "-" "DNSPod-Monitor/1.0"
...
3.算法思路
- 1)页面访问量统计(PV)
网站网页的访问次数,通过统计日志文件的每一行记录,统计每一行日志的访问网站的资源路径为key,相同的资源路径累加,最后即可得到访问网站网页的访问次数。
需要统计的页面如下:
/about
/black-ip-list/
/cassandra-clustor/
/finance-rhive-repurchase/
/hadoop-family-roadmap/
/hadoop-hive-intro/
/hadoop-zookeeper-intro/
/hadoop-mahout-roadmap/
-
2)页面独立IP的访问量统计(IP)
网站的独立IP的统计,是根据日志文件中每一条日志信息中访问资源的ip的个数进行统计的。以资源路径为key,不同的IP值进行累加即可得出结果。
实例说明:1.80.249.223 1表示此IP访问量为1。 -
3)每小时访问网站的次数统计(time)
每小时访问网站的次数统计是以每小时时间为key,每小时时间段内的访问次数进行累加即可得到结果。
实例说明:2013091806 111表示2013年9月18号6点(含)到7点(不含)之间的访问量为111。 -
4)访问网站的浏览器标识统计(browser)
将记录客户浏览器的相关信息作为key,对不同的浏览器进行累加求和。
提示:数据中记录客户浏览器的相关信息(http_ser_agent),user-agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。一些网站常常通过判断UA来给不同的操作系统、不同的浏览器发送不同的页面,因此可能造成某些页面无法在某个浏览器中正常显示,但通过伪装UA可以绕过检测。
标准格式为: 浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识 版本信息(但是不同的浏览器的格式是不同的,大体都包括这些内容)
实例数据:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.65 Safari/537.36
1.本次环境版本为Hadoop2.7.7,对应eclips插件存放于云主机master:/usr/package277/中。
2.本机映射名为hadoop000,云主机Hadoop/Hive的hosts文件中IP需要修改为内网IP,需要修改为实际内网IP(服务器地址有内外网之分),本地eclipse所在主机需要使用外网IP设置映射;
Linux/Mac系统下文件地址:/etc/hosts
Windows系统下文件地址:C:\Windows\System32\drivers\etc\hosts

2.云主机搭建的Hadoop集群,集群之间通过内网通信,本地eclipse开发工具需要使用域名进行访问。
Hadoop配置文件是以内网IP作为机器间通信的IP。在这种情况下,我们能够访问到namenode机器,namenode会给我们数据所在机器的IP地址供我们访问数据传输服务,但是当写数据的时候,NameNode和DataNode是通过内网通信的,返回的是datanode内网的IP,我们无法根据该IP访问datanode服务器。将默认的通过IP访问,改为通过域名方式访问。
// 使用hdfs的fs功能,客户端就会访问core-site.xml配置文件
// 设置客户端访问datanode使用hostname来进行访问
conf.set("dfs.client.use.datanode.hostname", "true");
// 设置core-site.xml中的属性fs.defaultFS和属性值,注意主机名必须和设置的hosts主机名一致
conf.set("fs.defaultFS","hdfs://hadoop000:9000");
考核条件如下 :
- 将本地数据/root/internetlogs/journal.log上传至HDFS文件系统/input/下,注意自行创建目录。
操作环境:Hadoop/Hive
- 编写程序进行页面访问量统计,结果保存至本地/root/internetlogs/pv/目录下part-00000文件中。
操作环境:Hadoop/Hive
参考代码【可完整实现通过】:
package org.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class PV {
public static class PVMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将日志行转换为字符串
String line = value.toString();
// 按照双引号分割行,以提取请求部分
String[] parts = line.split("\"");
if (parts.length > 1) {
// 获取请求行,通常是在第二个部分
String requestLine = parts[1];
// 分割请求行以提取 HTTP 方法和资源路径
String[] requestParts = requestLine.split(" ");
// 检查请求部分长度,确保它包含方法和资源路径
if (requestParts.length > 1) {
String resourcePath = requestParts[1];
// 过滤需要的页面
if (resourcePath.matches("/about|/black-ip-list/|/cassandra-clustor/|/finance-rhive-repurchase/|/hadoop-family-roadmap/|/hadoop-hive-intro/|/hadoop-zookeeper-intro/|/hadoop-mahout-roadmap/")) {
context.write(new Text(resourcePath), new IntWritable(1));
}
} else {
// 如果请求行格式不正确,可以记录或处理错误
System.err.println("无效的请求行: " + requestLine);
}
} else {
// 如果行格式不正确,可以记录或处理错误
System.err.println("无效的日志行: " + line);
}
}
}
public static class PVReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//conf.set("fs.defaultFS", "hdfs://localhost:9000");
Job job = Job.getInstance(conf, "Page Views Count");
job.setJarByClass(PV.class);
job.setMapperClass(PVMapper.class);
job.setReducerClass(PVReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path outpath= new Path("/E:/AUST/wrpv");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outpath)){
fs.delete(outpath);
}
FileInputFormat.addInputPath(job, new Path("/E:/AUST/journal.log"));
FileOutputFormat.setOutputPath(job, outpath);
boolean flag = job.waitForCompletion(true);
if(flag){
System.out.println("success!");
}else{
System.out.println("error!");
}
}
}
以上代码是在本地hadoop环境运行,若要虚拟机环境下运行需多加设置。
- 编写程序进行页面独立IP的访问量统计,结果保存至本地/root/internetlogs/ip/目录下part-00000文件中,例如1.80.249.223 1表示此IP访问量为1
操作环境:Hadoop/Hive
参考代码【可完整实现通过】:
package org.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class IP {
public static class IPMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
// 日志记录的拆分
String[] fields = value.toString().split(" ");
if (fields.length > 0) {
String ipAddress = fields[0];
// 以IP为key,1为value输出
context.write(new Text(ipAddress), new IntWritable(1));
}
}
}
public static class IPReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
// 累加每个IP的访问次数
for (IntWritable val : values) {
sum += val.get();
}
// 输出IP和总访问次数
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "IP Access Count");
job.setJarByClass(IP.class);
job.setMapperClass(IPMapper.class);
job.setReducerClass(IPReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path outpath= new Path("/E:/AUST/wrip");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(outpath)){
fs.delete(outpath);
}
FileInputFormat.addInputPath(job, new Path("/E:/AUST/journal.log"));
FileOutputFormat.setOutputPath(job, outpath);
boolean flag = job.waitForCompletion(true);
if(flag){
System.out.println("success!");
}else{
System.out.println("error!");
}
}
}
- 编写程序进行每小时访问网站的次数统计,结果保存至本地/root/internetlogs/time/目录下part-00000文件中
操作环境:Hadoop/Hive
- 编写程序进行访问网站的浏览器标识统计,结果保存至本地/root/internetlogs/browser/目录下part-00000文件中,具体查看步骤说明
操作环境:Hadoop/Hive
用户电影推荐
1.项目需求
随着互联网的急速发展,网络中的信息量以指数规律迅速扩展和增加,网络上的信息过载和信息迷航问题日益严重,使得人们被动接受不喜欢的事物,为解决这一问题,推荐技术应运而生,推荐系统通过预测用户对信息资源的喜好程度来进 行信息过滤,根据用户具体需求通过协同过滤等技术进行个性化推荐。
基于物品的协同过滤(ItemCF):通过用户对于不同item的评分来预测item之间的相似性,基于item之间的相似性最初推荐;简单来说,就是给用户推荐和他之前喜欢的物品相似的物品。
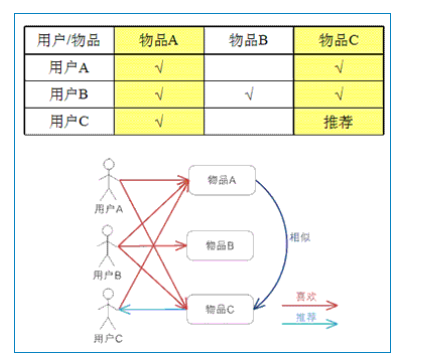
要求通过协同过滤算法itemCF针对用户评价电影的信息,对用户信息进行训练,计算出为每位用户推荐电影的分数,进而进行电影推荐。
(1)计算物品之间的相似度。
(2)根据物品的相似度和用户的历史行为给用户生成推荐列表。
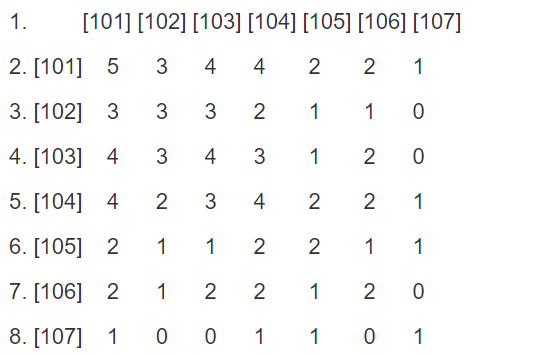
2.数据说明
数据地址:主机"hadoop/Hive"节点下/root/movie/data.csv
推荐系统数据来源于某知名视频网站保存了大量的用户评分数据,共有三列,分别为用户Id,电影Id,评分rate(评分区间0~5分)数据如下:
userId,movieId,rate
1,1,4
1,3,4
1,6,4
1,47,5
1,50,5
1,70,3
1,101,5
1,110,4
...
3.算法思路
- 建立物品的同现矩阵。
2.建立用户对物品的评分矩阵。

3.矩阵计算推荐结果。公式:同现矩阵*评分矩阵=推荐结果
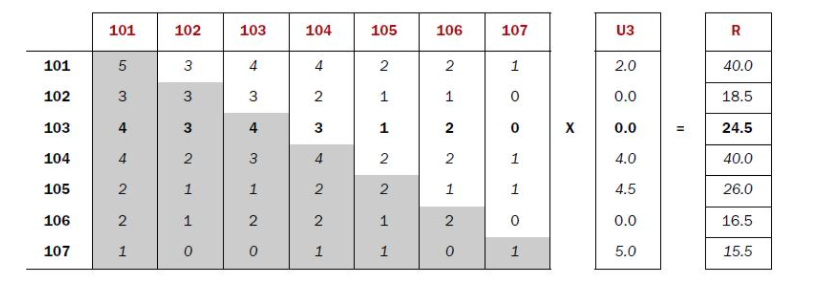
# 推荐结果示例
用户Id 电影Id:推荐分数
1 68872,366.0
4.解题步骤
Step1-- 按用户分组,计算所有物品出现的组合列表,得到用户对物品的评分矩阵
map:获取每一行数据,将userId(用户ID)作为key,movieId + “:” + rate作为value。
reduce:遍历结果集,将每位用户对应的结果按“ “,”+value ”拼接成一行数据输出。
# 样例数据,注意排序方式
用户Id 电影Id:评分...
1 70:3.0,110:4.0,151:5.0,...
Step2–对itemID(电影ID)组合列表进行计数,建立物品的同现矩阵
map:
切分数据(上步骤结果),取出每位用户的movieId并进行循环匹配。
将movieId + “:” + movieId2作为key收集,value记为 1。
reduce:
遍历结果集,按key进行分组,求总和。
电影Id:电影Id 总数
4720:2462 1
Step3–对同现矩阵和评分矩阵进行转换
| 评分矩阵转换 | 同现矩阵转换(step2已完成) |
|---|---|
| 将数据进行切分,获取movieId对应的userId和rate;将movieId作为key,userId+“:”+rate拼接作为value。 | 将movieId:movieId2作为key,总和作为value。 |
| 电影id 用户id:评分1 604:3.0 | 电影id:电影id 总数100044:100044 1 |
Step4–矩阵相乘
map:
判断输入数据集是同现矩阵数据或者评分矩阵数据,同现矩阵需要进行封装;
通过评分矩阵中的itemID遍历对应的同现矩阵itemID2以及总和num,并计算num与评分rate的乘积;
将userID作为key,ItemID2 + “,” + rate * num拼接作为value;
reduce:
遍历结果集;
将遍历结果放入Map集合;
通过遍历集合获取itemID对应的总分score;
收集结果集,将userID作为key,itemID+“,”+score拼接作为value,即按照用户分组,求出对应推荐电影的总分情况。
1.本次环境版本为Hadoop2.7.7,对应eclipse插件存放于云主机master:/usr/package277/中。
2.本机映射名为hadoop000,云主机Hadoop/Hive的hosts文件中IP需要修改为内网IP,需要修改为实际内网IP(服务器地址有内外网之分),本地eclipse所在主机需要使用外网IP设置映射;
Linux/Mac系统下文件地址:/etc/hosts
Windows系统下文件地址:C:\Windows\System32\drivers\etc\hosts
3.云主机搭建的Hadoop集群,集群之间通过内网通信,本地eclipse开发工具需要使用域名进行访问。
Hadoop配置文件是以内网IP作为机器间通信的IP。在这种情况下,我们能够访问到namenode机器,namenode会给我们数据所在机器的IP地址供我们访问数据传输服务,但是当写数据的时候,NameNode和DataNode是通过内网通信的,返回的是datanode内网的IP,我们无法根据该IP访问datanode服务器。将默认的通过IP访问,改为通过域名方式访问。
// 使用hdfs的fs功能,客户端就会访问core-site.xml配置文件
// 设置客户端访问datanode使用hostname来进行访问
conf.set("dfs.client.use.datanode.hostname", "true");
// 设置core-site.xml中的属性fs.defaultFS和属性值,注意主机名必须和设置的hosts主机名一致
conf.set("fs.defaultFS","hdfs://hadoop000:9000");
考核条件如下 :
- 将本地数据/root/movie/data.csv上传至HDFS文件系统/input/下,注意自行创建目录。
操作环境:Hadoop/Hive
- 编写程序实现评分矩阵,计算所有物品出现的组合列表,结果保存至本地/root/movie/output1/目录下part-r-00000文件中
操作环境:Hadoop/Hive
- 编写程序实现同现矩阵,对电影ID循环匹配并进行计数,结果保存至本地/root/movie/output2/目录下part-r-00000文件中
操作环境:Hadoop/Hive
- 编写程序实现对评分矩阵的转换,结果保存至本地/root/movie/output3_1/目录下part-r-00000文件中(0/ 20分)
操作环境:Hadoop/Hive
- 编写程序实现对同现矩阵的转换(即读入output2结果),结果保存至本地/root/movie/output3_2/目录下part-r-00000文件中(0/ 10分)
操作环境:Hadoop/Hive
- 编写程序实现矩阵相乘,得到推荐结果,结果保存至本地/root/movie/output4/目录下part-r-00000文件中(0/ 20分)
操作环境:Hadoop/Hive
简单数据统计WordCount
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版"Hello World",该程序的完整代码可以在Hadoop安装包的"src/examples"目录下找到。
单词计数主要完成功能是:统计一系列文本文件中每个单词出现的次数。
数据说明
数据:sonnet.txt(自动创建)
Shakespeare Sonnet
Shall I compare thee to a summer's day?
Thou art more lovely and more temperate:
Rough winds do shake the darling buds of May,
And summer's lease hath all too short a date:
Sometime too hot the eye of heaven shines,
And often is his gold complexion dimm'd;
And every fair from fair sometime declines,
By chance or nature's changing course untrimm'd
But thy eternal summer shall not fade
Nor lose possession of that fair thou owest;
Nor shall Death brag thou wander'st in his shade,
When in eternal lines to time thou growest:
So long as men can breathe or eyes can see,
So long lives this and this gives life to thee.
考核条件如下 :
1.将数据sonnet.txt上传至HDFS文件系统/input/下,注意自行创建目录。(0/ 10分)
操作环境:Hadoop/Hive/Spark
2.编写程序或使用Hadoop自带的开源jar包对数据进行wordcount操作,结果保存至hdfs:/output/part–r-00000(0/ 10分)
操作环境:Hadoop/Hive/Spark
疫情数据分析
1.项目需求
自2019年底,湖北省武汉市监测发现不明原因肺炎病例,中国第一时间报告疫情,迅速采取行动,开展病因学和流行病学调查,阻断疫情蔓延。
SARS-CoV-2是一种有着高扩散能力的病毒,通过飞沫、直接接触和被感染的物体传播,其潜伏时间为1到14天,并且也由无症状感染者传播。大多数感染者仅表现出轻度至中度的呼吸道症状,或根本不表现任何症状。只有5-10%的感染者显示出完全的严重呼吸综合征,称为冠状病毒病(COVID)-19,能够人传人,进而所引发的全球大流行疫情,是全球自第二次世界大战以来面临的最严峻危机。截至目前,全球已有200多个国家和地区累计报告超过2.1375亿确诊病例,导致超过445万名患者死亡。
在此基础上,大数据技术应用发挥出极大作用。通过城市监测,接触者追踪,疫苗接种等,将我们的疫情信息进行传达。为政府正确决策、精准施策提供了科学依据。强化了政府对疫情物资生产、筹集、投放的科学管控手段。为医疗救治、“群防群控”,防止疫情蔓延采取有效措施提供了科学数据和手段。科学分析预测疫情现状、趋势,适时准确地根据疫情变化把握防疫重点。
本项目为新型冠状病毒(COVID-19)疫情状况的时间序列数据仓库,选手可以通过对疫情历史数据的分析研究,以更好的了解疫情与疫情的发展态势,为抗击疫情之决策提供数据支持。
2.数据说明
数据:/root/covid/covid_area.csv
数据截止到2021年9月全球确诊、感染、治愈、死亡人数,地理信息包含地区、国家、省、市4级信息,时间信息为年与日时分秒,按照每个城市每天更新一次。

step1:创建ods层数据表
ods层是数据原始层,只需将原始数据拉去过来即可,ods层可以采用内部表(EXTERNAL 修饰)保证数据安全性。
数据库:covid_ods
原始数据表:covid_ods.covid
| 字段 | 解释 |
|---|---|
| continerName | 大洲 |
| countryName | 国家 |
| provinceName | 省份 |
| province_confirm | 省份确诊人数 |
| province_suspect | 省份感染人数 |
| province_cured | 省份治愈人数 |
| province_dead | 省份死亡人数 |
| cityName | 城市/地区 |
| city_confirm | 城市确诊人数 |
| city_suspect | 城市感染人数 |
| city_cured | 城市治愈人数 |
| city_dead | 城市死亡人数 |
| updateTime | 数据更新时间 |
数据加工表:covid_ods.covid_time
要求:保留干净数据,去重(去空值、脏数据处理),提取特征数据,只保留每天最后更新的数据;
-
特征数据:包括省份,城市/地区,城市确诊,城市感染,城市治愈,城市死亡,数据更新时间;
-
过滤重复值,数据中有同一天获取的多次疫情信息,根据时间只保留每天最后更新的数据;
-
同时要求国家为中国,省份不为中国,过滤地区空值。
| 字段 | 解释 |
|---|---|
| provinceName | 省份 |
| cityName | 城市/地区 |
| city_confirm | 城市确诊人数 |
| city_suspect | 城市感染人数 |
| city_cured | 城市治愈人数 |
| city_dead | 城市死亡人数 |
| updateTime | 数据更新时间 |
# 重复数据,同一天多次更新的数据,取每天最后更新的数据(按照时间进行条件判断)
亚洲,中国,福建省,1169,15,777,1,莆田,246,0,56,0,2021-09-20 19:14:20
亚洲,中国,福建省,1169,15,777,1,莆田,246,0,56,0,2021-09-20 18:54:20
亚洲,中国,福建省,1169,15,777,1,莆田,246,0,56,0,2021-09-20 09:50:20
# 地区空值数据
亚洲,中国,台湾,40,0,12,1,,,,,,2020-03-02 09:10:02
亚洲,中国,香港,10,0,0,0,,,,,,2020-01-29 19:12:29
step2:创建dwd层数据表
在dwd层采用分区表将数据按照年/月维度进行分区存放,以便在获取某月数据时可快速获取,提高获取效率。在本层将获取想要的字段数据**,**对不规则数据做简单整理。
数据库:covid_dwd
添加昨天时间列表:province
指标:城市累计确诊,城市累计疑似,城市累计治愈,城市累计死亡。
维度:省份,城市,时间(更新时间updateTime,以及时间的前一天yesterday)。
分区:年、月
思路:将数据中的时间切割,获取年月日,并使用date_sub()函数获取昨天更新时间。
| 字段 | 解释 |
|---|---|
| provinceName | 省份 |
| cityName | 城市/地区 |
| city_confirm | 城市确诊人数 |
| city_suspect | 城市感染人数 |
| city_cured | 城市治愈人数 |
| city_dead | 城市死亡人数 |
| updateTime | 数据更新时间 |
| yesterday | 昨天更新时间 |
| yearinfo | 年(分区) |
| monthinfo | 月(分区) |
step3:创建dwm数据处理分析
统计每天各个省份中指标的增长量,因此需要去获取前一天或者后一天的数据,在本层将当天数据和前一天的数据进行汇总,通过join方式将数据合并为一条数据。对四个指标数据进行类型转换,转换为int类型(在dws层将参与运算)。
数据库:covid_dwm
创建当日数据和后一天数据汇总数据表:two_day
| 字段 | 解释 |
|---|---|
| provinceName | 省份 |
| cityName | 城市/地区 |
| city_confirm | 城市确诊人数 |
| city_suspect | 城市感染人数 |
| city_cured | 城市治愈人数 |
| city_dead | 城市死亡人数 |
| updateTime | 更新时间 |
| city_confirm_before | 一天前城市确诊人数 |
| city_suspect_before | 一天前城市感染人数 |
| city_cured_before | 一天前城市治愈人数 |
| city_dead_before | 一天前城市死亡人数 |
| yesterday | 昨天更新时间 |
| yearinfo | 年(分区) |
| monthinfo | 月(分区) |
合并数据注意考虑时间问题。
step4:创建dws层
在dwd层已经拿到前一天的数据,在本层计算各个地区的指标增量,计算方式为:
每日指标增量=前一天指标数据-今日指标数据
数据库:covid_dws
单日指标正常量表:covid_dws.day
| 字段 | 解释 |
|---|---|
| provinceName | 省份 |
| cityName | 城市/地区 |
| new_city_confirm | 日确诊增长人数 |
| new_city_suspect | 日疑似增长人数 |
| new_city_cured | 日治愈增长人数 |
| new_city_dead | 日死亡增长人数 |
| updateTime | 更新时间 |
| yearinfo | 年(分区) |
| monthinfo | 月(分区) |
step5:创建app层
针对疫情数据,在app层再对维度进行上卷,分析维度为各个省份每日的指标增量情况统计。
数据库:covid_app
app层业务表:covid_app.day_app
| 字段 | 解释 |
|---|---|
| provinceName | 省份 |
| new_city_confirm | 日确诊增长人数 |
| new_city_suspect | 日疑似增长人数 |
| new_city_cured | 日治愈增长人数 |
| new_city_dead | 日死亡增长人数 |
| updateTime | 更新时间 |
| yearinfo | 年(分区) |
| monthinfo | 月(分区) |
其他参考设置:
--动态分区配置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=100000;
set hive.exec.max.dynamic.partitions=100000;
set hive.exec.max.created.files=100000;
--hive压缩
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
--写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
--本地模式
set hive.exec.mode.local.auto=true;
set mapreduce.map.memory.mb=1025;
set mapreduce.reduce.memory.mb=1025;
set hive.exec.mode.local.auto.input.files.max=25;
考核条件如下 :
- 进入hive客户端,创建名为covid_ods的数据库用于存储原始数据
操作环境:Hadoop/Hive/Spark
- 数据库covid_ods下创建covid表,导入去除表头后的原始数据/root/covid/covid_area.csv(文件名不变)
操作环境:Hadoop/Hive/Spark
- 数据库covid_ods下创建covid_time表,用于提取有用数据,过滤重复值,只保留每天最后更新的数据,具体参考步骤说明
操作环境:Hadoop/Hive/Spark
- 按照要求向covid_ods.covid_time插入过滤后的数据
操作环境:Hadoop/Hive/Spark
- 创建名为covid_dwd的数据库,此层将数据进行分区,便于数据的快速获取
操作环境:Hadoop/Hive/Spark
-
数据库covid_dwd下创建province表,按照年、月分区,要求根据当天时间获取昨天对应时间列,并插入对应数据,具体要求查看步骤说明
操作环境:Hadoop/Hive/Spark -
创建名为covid_dwm的数据库,用于统计每个省份的各指标增长量。
操作环境:Hadoop/Hive/Spark
- 数据库covid_dwm下创建two_day表,将province中当天数据和前一天的数据进行汇总,通过join方式将数据合并为一条数据,具体查看步骤说明
操作环境:Hadoop/Hive/Spark
- 将表two_day中所有内容保存至云主机/root/covid/two_day.csv
操作环境:Hadoop/Hive/Spark
- 将表two_day中所有内容保存至云主机/root/covid/two_day.csv
操作环境:Hadoop/Hive/Spark
- 数据库covid_dws下创建day表,用于计算地区每日指标增量,具体字段查看步骤说明
操作环境:Hadoop/Hive/Spark
- 将表day中所有内容保存至云主机/root/covid/day.csv
操作环境:Hadoop/Hive/Spark
- 创建名为covid_app的数据库,此层用于各个省份每日的指标增量情况统计
操作环境:Hadoop/Hive/Spark
- 数据库covid_app下创建app层业务表,进行各个省份每日的指标增量情况统计
操作环境:Hadoop/Hive/Spark
- 将表day_app中所有内容保存至云主机/root/covid/day_app.csv
操作环境:Hadoop/Hive/Spark
交通事故因素分析
1.项目需求
基于大数据的交通事故因素分析,从影响交通安全的主要因素出发,分析挖掘道路交通事故的规律和特征,实现交通风险评估,为城市肃清道路交通安全隐患提供一定参考和应用价值。
2.数据说明
数据地址:/root/college/traffic.csv
数据文件中字段对应的含义如下:
| 字段 | 数据类型 | 说明 |
|---|---|---|
| peopletype | string | 人员类型 |
| roadnum | string | 道路编号 |
| carid | int | 车辆id |
| time | date | 事故时间 |
| province | string | 省份 |
| gender | string | 性别 |
| age | int | |
| drivertype | string | 驾驶证类型 |
| belt | string | 安全设置使用(安全带) |
| airbags | string | 气囊 |
| popup | string | 弹出情况 |
| injury | sting | 伤势 |
| operation | string | 操作 |
| sight | string | 视线 |
| check | string | 酒精检测 |
示例数据:
司机,HY368708,10,2015-08-04 12:40:00,江苏,男,未知,不适用,没有弹出,没有受伤,拒绝让步,未知,未测验
司机,HY374018,96,2015-07-31 17:50:00,江苏,男,使用安全带,无部署 ,没有弹出,没有受伤,车距过近,未知,未测验
3.分析思路
1.针对事故中的人员信息进行分析,从年龄、性别、车型、行为操作等不同方面进行分析,试找出不同因素对事故的影响比重。
2.针对地域、路段、时间段、车辆状态等因素着手,试寻找环境等外在因素对事故的影响。
3.针对在安全设备的部署和保护等条件下,对事故中人员伤情信息进行分析,试找出事故安全和安全设备之间的关系。
时间段定义如下:
--early morning: [5:00, 7:59]
--morning: [8:00, 10:59]
--noon: [11:00, 12:59]
--afternoon: [13:00, 17:59]
--evening: [18:00, 21:59]
--night: [22:00, 4:59]
考核条件如下 :
1.在hive数据库下构建数据表traffic,并导入数据traffic.csv
操作环境:Hadoop/Hive/Spark
2.创建中间表driver,只保留人员类型为“司机”的数据,同时过滤年龄为空值的数据,后续均在此中间表基础上进行分析;
操作环境:Hadoop/Hive/Spark
3.统计traffic表中数据量,结果写入本地/root/traffic1/中
操作环境:Hadoop/Hive/Spark
4.统计中间表driver数据量,结果写入本地root/traffic2
操作环境:Hadoop/Hive/Spark
5.计算持有C1证件的驾驶员数量,结果写入本地/root/traffic3/ (二维数组:驾驶证类型 数量)
操作环境:Hadoop/Hive/Spark
6.计算发生交通事故人员中,驾驶人员的平均年龄(向上取整),结果写入本地/root/traffic4/
操作环境:Hadoop/Hive/Spark
7.查询发生交通事故人员中,驾驶人员年龄分布TOP3,结果写入本地/root/traffic5/ (二维数组:年龄 数量)
操作环境:Hadoop/Hive/Spark
8.女性驾驶员因变道不当发生事故的数量,结果写入本地/root/traffic6/
操作环境:Hadoop/Hive/Spark
9.在江苏发生事故的男驾驶员,拒绝血液酒精含量检测(拒绝检测)的人数,结果写入本地/root/traffic7/
操作环境:Hadoop/Hive/Spark
10.在2019年,发生案件最少的四个省份,结果写入本地/root/traffic8/ (二维数组:省份 数量)
操作环境:Hadoop/Hive/Spark
11.找出易发生交通事故的道路编号top5(2019年),结果写入本地/root/traffic9/ (二维数组:道路编号 数量)
操作环境:Hadoop/Hive/Spark
12.查询各时段所发生的案件次数,结果写入本地/root/traffic10/ (二维数组:道路编号 数量)时间段分割见本步骤说明
操作环境:Hadoop/Hive/Spark
13.在正常驾驶C1类型交通情况下,分析安全气囊弹出情况分布,结果写入本地/root/traffic11/ (二维数组:气囊情况 数量)
操作环境:Hadoop/Hive/Spark
14.35岁及以上的驾驶员,在转向不当条件下,没有受伤的事故数量,结果写入本地/root/traffic12/;
操作环境:Hadoop/Hive/Spark
15.驾驶员未系安全带案例中,导致人员致命伤的案例数量,结果写入本地/root/traffic13/ (二维数组:伤势情况 数量)
操作环境:Hadoop/Hive/Spark
网络诈骗
1.项目需求
电信网络诈骗发展迅猛,危害人民的切身利益,它不仅使个人财产受到威胁,由网络诈骗衍生的“黑色产业”发展之猖獗,同时也已经升级到扰乱社会秩序的层面。一些群众不敢使用网上银行,甚至拒绝一切陌生人的电话、短信,严重制约了我们经济的健康发展。在智能数据终端普及的今天,如何使大数据技术更好地服务于警务战略,更精准地打击电信网络诈骗,是我们急需解决的问题。为此,我们应当站在为国家信息化、革命化保驾护航的高度,利用大数据科学预测预防电信网络诈骗,通过云端的机器学习模型识别网址、电话等信息,升级防控手段,加大打击力度,从根源上打击电信网络诈骗。
基于大数据的预测电信网络诈骗为我们打击犯罪提供了崭新视角,基于大数据技术的电信诈骗预测能够全面筛选电信诈骗海量信息、尤其是地理分布广而散的受害者信息更不能被遗漏。其预测分析的数据基础可以来源于公安、电信、金融各个方面,既有机关企业的宏观数据,亦有各当事人的微观数据,分析各层次和各部分数据间的联系,数据来源的全面可以确保结果的全面。基于大数据的模型与算法预测电信网络诈骗,能够积极促进研发预测警务系统和警务软件,促进公安数据信息系统从查询统计功能向预测功能转变,是实现预测警务在打击跨境电信诈骗犯罪中应用的基础技术建设。
2.数据说明
数据地址:/root/college/fraud.txt
给定数据集字段为案件编号、案件状态、案件副案别、经济损失、损失程度、作案手法、案件来源、发案时间、发案地点、受理单位、受理时间、报案时间、警官、破案时间。
| 字段 | 说明 | 数据类型 |
|---|---|---|
| id | ID | int |
| state | 案件状态 | string |
| class | 案件副类别 | string |
| loss | 经济损失 | int |
| degree | 损失程度 | string |
| mode | 作案手法 | string |
| source | 案件来源 | string |
| uppertime | 发案时间上限 | timestamp |
| lowertime | 发案时间下限 | timestamp |
| place | 发案地点 | string |
| accept_unit | 受理单位 | string |
| accept_time | 受理时间 | timestamp |
| take_time | 报案时间 | timestamp |
| police | 警官 | string |
| break_time | 破案日期 | timestamp |
3.关联规则
定义一个关联规则:A->B
其中A和B表示的是两个互斥事件,A称为前因(antecedent),B称为后果(consequent),上述关联规则表示A会导致B。
一般我们使用三个指标来度量一个关联规则,这三个指标分别是:支持度、置信度和提升度。
Support(支持度):表示同时包含 A 和 B 的事务占所有事务的比例。如果用 P(A) 表示包含 A 的事务的比例,那么 Support = P(A & B)
Confidence(置信度):表示包含 A 的事务中同时包含 B 的事务的比例,即同时包含 A 和 B 的事务占包含 A 的事务的比例。公式表达:Confidence = P(A & B)/ P(A)
Lift(提升度):表示“包含 A 的事务中同时包含 B 的事务的比例”与“包含 B 的事务的比例”的比值。公式表达:Lift = ( P(A & B)/ P(A) ) / P(B) = P(A & B)/ P(A) / P(B)。
考核条件如下 :
1.在hive数据库下构建数据表fraud
操作环境:Hadoop/Hive/Spark
2.统计表数据,结果写入本地/root/fraud00/000000_0中
操作环境:Hadoop/Hive/Spark
3.统计2017年3月份的经济损失总额,将结果写入到本地/root/fraud01/000000_0中。(以报案时间为准)
操作环境:Hadoop/Hive/Spark
4.找出经济损失金额最多的案件副类别,并给出该案件副类别对应的损失总额,将结果写入到本地/root/fraud02/000000_0中。
操作环境:Hadoop/Hive/Spark
5.统计2016年03月份发生案件总数,将结果写入到本地/root/fraud03/000000_0中。(以报案时间为准)
操作环境:Hadoop/Hive/Spark
6.在损失度为“特别巨大”的案件中,找出发生次数最高的案件副类别并统计其发生次数,将结果写入到本地/root/fraud04/000000_0中;
操作环境:Hadoop/Hive/Spark
7.列出诈骗金额最高的3个地区,给出对应的损失金额,将结果写入到本地/root/fraud05/000000_0中;(地区示例格式为:A城A区)
操作环境:Hadoop/Hive/Spark
8.“短信诈骗”的发案时间平均为多久(即发案时间的下限(天)-发案时间的上限(天)),将结果写入到本地/root/fraud06/000000_0中;
操作环境:Hadoop/Hive/Spark
9.“电话诈骗”的受害人平均在发案之后多久才会报案(即报案时间-发案时间上限(天),将结果写入到本地/root/fraud07/000000_0中;
操作环境:Hadoop/Hive/Spark
10.计算所有已破案案件从报案到破案的平均处理时间(天),将结果写入到本地/root/fraud08/000000_0中;
操作环境:Hadoop/Hive/Spark
11.列出2016年春季的经济损失总额,将结果写入到本地/root/fraud09/000000_0中;(春季为1、2、3月;以报案时间为准)
操作环境:Hadoop/Hive/Spark
12.列出案发数最高的地区top10及其对应的案发次数,将结果写入到本地/root/fraud10/000000_0中;
操作环境:Hadoop/Hive/Spark
13.统计所有开学季(9月)经济损失总额,将结果写入到本地/root/fraud11/000000_0中;
操作环境:Hadoop/Hive/Spark
14.在损失金额超过18万的案件中,找出受理案件最多的派出所top5及其对应受理案件数目,将结果写入到本地/root/fraud12/000000_0中;
操作环境:Hadoop/Hive/Spark
15.列出破案数额最高的地区top10及其对应的破获案件数,将结果写入到本地/root/fraud13/000000_0中;(state=‘破案’)
操作环境:Hadoop/Hive/Spark
16.列出2015年破案最多的警官(按姓氏)top5及其对应破案数,将结果写入到本地/root/fraud14/000000_0中;
操作环境:Hadoop/Hive/Spark
17.列出深夜受理案件最多的警官(按姓氏)top10及接案次数,将结果写入到本地/root/fraud15/000000_0中。 (00-07为深夜,08-12为上午,13-19为下午,20-23为晚上)
操作环境:Hadoop/Hive/Spark
18.统计在A城案件中的各案件副类别发生次数,将结果写入到本地/root/fraud16/000000_0中。
操作环境:Hadoop/Hive/Spark
19.列出2019年破获案件总金额最高的警官(姓氏)top10及其破获总金额,将结果写入到本地/root/fraud17/000000_0中。
操作环境:Hadoop/Hive/Spark
20.列出“深夜”时段受理案件最多的派出所及其受理案件数目,将结果写入到本地/root/fraud18/000000_0中; (00-07为深夜,08-12为上午,13-19为下午,20-23为晚上)
操作环境:Hadoop/Hive/Spark
21.列出网络诈骗中案发次数最高的作案手法top5及其对应案发次数,将结果写入到本地/root/fraud19/000000_0中。
操作环境:Hadoop/Hive/Spark
22.请根据Apriori关联规则算法的原理找出与损失程度为‘较大’(后项)的关联度最强的作案手法(前项),计算其支持度,结果写入/root/fraud20/01/000000_0中(保留五位小数);
操作环境:Hadoop/Hive/Spark
23.请根据Apriori关联规则算法的原理找出与损失程度为‘较大’(后项)的关联度最强的作案手法(前项),计算其置信度,结果写入/root/fraud20/02/000000_0中(保留五位小数);
操作环境:Hadoop/Hive/Spark
人口收入数据分析
1.项目需求
本数据为某人口普查公开数据数据库抽取而来,该数据集类变量为年收入是否超过50k$,属性变量包含年龄、工作类型、教育程度等属性,统计对各因素对收入的影响。
数据为:/root/college/person.txt,变量如下:
| 字段 | 类型 | 说明 |
|---|---|---|
| age | double | 年龄 |
| workclass | string | 工作类型 |
| fnlwgt | string | 可代表的人数 |
| edu | string | 教育程度 |
| edu_num | double | 受教育时间 |
| marital_status | string | 婚姻状况 |
| occupation | string | 职业 |
| relationship | string | 关系 |
| race | string | 种族 |
| sex | string | 性别 |
| gain | string | 资本收益 |
| loss | string | 资本损失 |
| hours | double | 每周工作时长 |
| native | string | 原籍 |
| income | string | 收入 |
2.Hive安全配置
为防止大数据集群稳定性,类似非全等join(非inner join)是禁止的,禁用了SemanticException笛卡尔产品。
FAILED: SemanticException Cartesian products are disabled for safety reasons. If you know what you are doing, please sethive.strict.checks.cartesian.product to false and that hive.mapred.mode is not set to ‘strict’ to proceed. Note that if you may get errors or incorrect results if you make a mistake while using some of the unsafe features.
hive> set hive.strict.checks.cartesian.product;
# 首先查看hive.strict.checks.cartesian.product
hive> set hive.strict.checks.cartesian.product=false;
# 设置hive.strict.checks.cartesian.product为false
考核条件如下 :
1.数据/root/college/person.txt上传至hdfs://college/目录下
2.数据库hive下创建person数据表,并导入数据
3.计算较高收入人群占整体数据的比例,结果写入本地/root/person01/000000_0。 其他说明:结果四舍五入,保留两位小数。
4.计算学历为Bachelors的人员在调查中的占比,结果写入本地/root/person02/000000_0。结果四舍五入,保留两位小数。
5.计算青年群体中高收入年龄层排行top3,结果写入本地/root/person03/000000_0。注意:15-34岁为青年。
6.计算男性群体中高收入职业排行top5,结果写入本地/root/person04/000000_0。注意:职业升序排列
7.统计性别对于收入的影响,计算不同性别的占比,结果写入本地/root/person05/000000_0。结果为高收入中性别比例,结果四舍五入,保留两位小数,格式为性别 对应比例(如Male 1.0)。
8.统计教育程度对于收入的影响,结果写入本地/root/person06/000000_0。其他说明:数据条件为高收入,对不同教育程度进行数量累加。
电商运营数据分析
1.项目需求
信息流、物流和资金流三大平台是电子商务的三个最为重要的平台。而电子商务信息系统最核心的能力是大数据能力,包括大数据处理、数据分析和数据挖掘能力。无论是电商平台还是在电商平台上销售产品的卖家,都需要掌握大数据分析的能力。越成熟的电商平台,越需要以通过大数据能力驱动电子商务运营的精细化,更好的提升运营效果,提升业绩。
本次竞赛数据集为某购物平台在“双11”之前和之后的过去6个月内的匿名用户的购物日志以及指示它们是否是重复购买者的标签信息。 由于隐私问题,数据采取的方式有偏差,所以这个数据集的统计结果会偏离平台购物的实际情况,但是这不会影响解决方案的适用性。
2.数据说明
本次比赛阶段,数据集已经提供,文件名称为shopping.csv。
shopping.csv中字段含义如下:
| 数据字段 | 定义 |
|---|---|
| user_id | 购物者的唯一ID |
| age_range | 用户的年龄范围:1 代表[<18]; 2表示[18,24]; 3表示 [25,29]; 4表示 [30,34]; 5表示[35,39]; 6 表示[40,49]; 7表示[50,59];8表示[>=60]。0和NULL为未知。 |
| gender | 用户性别:0为女;1为男;2和空null为不详 |
| merchant_id | 商家的唯一ID |
| label | 值来自{0,1,-1,NULL}。 '1’表示’user_id’是’merchant_id’的重复购买者,'0’表示非重复买家。其他不详 |
| activity_log | {user_id,merchant_id}用户、商家之间的交互记录集。'#'用来分隔两个相邻的交互记录。记录没有以任何特定顺序排序。单个交互记录表示为“item_id:category_id:brand_id:time_stamp:action_type”的操作,字段之间使用‘:’进行分割。示例:17235:1604:4396:0818:0#954723:1604:4396:0818:0 |
activity_log中单个交互记录字段含义如下:
| 数据字段 | 定义 |
|---|---|
| item_id | 交互记录的唯一ID |
| category _id | 商品所属类别的唯一ID |
| brand_id | 品牌的唯一ID |
| time_stamp | 购物发生的时间(格式:mmdd) |
| action_type | 枚举类型{0,1,2,3},其中0表示点击,1表示加入购物车,2表示购买,3表示加入收藏 |
3.分析思路
step1:创建shopping表用于存放原始数据shopping.csv
| user_id(int) | age_range(int) | gender(int) | merchant_id(int) | label(int) | activity_log(varchar) |
|---|---|---|---|---|---|
| 34176 | 6 | 0 | 944 | -1 | 408895:1505:7370:1107:0 |
| 34176 | 6 | 0 | 412 | -1 | 17235:1604:4396:0818:0#954723:1604:4396:0818:0#275437:1604:4396:0818:0#236488:1505:4396:1024:0 |
step2:创建中间表result,要求字段包括user_id,item_id,brand_id,action_type,注意处理map结构的字段,将数组转换成多行。
中间表是数据库中专门存放中间计算结果的数据表。这里注意进行数据的切分。
(1)首先将activity_log中以‘#’分割的数据拆成多行数据
| user_id | age_range | gender | merchant_id | label | activity_log |
|---|---|---|---|---|---|
| 34176 | 6 | 0 | 944 | -1 | 408895:1505:7370:1107:0 |
| 34176 | 6 | 0 | 412 | -1 | 17235:1604:4396:0818:0 |
| 34176 | 6 | 0 | 412 | -1 | 954723:1604:4396:0818:0 |
| 34176 | 6 | 0 | 412 | -1 | 275437:1604:4396:0818:0 |
| 34176 | 6 | 0 | 412 | -1 | 236488:1505:4396:1024:0 |
(2)将拆成行的数据activity_log中以‘:’分割的数据拆分成元素
| user_id | age_range | gender | merchant_id | label | item_id | category _id | brand_id | time_stamp | action_type |
|---|---|---|---|---|---|---|---|---|---|
| 34176 | 6 | 0 | 944 | -1 | 408895 | 1505 | 7370 | 1107 | 0 |
| 34176 | 6 | 0 | 412 | -1 | 17235 | 1604 | 4396 | 818 | 0 |
(3)选取指定字段写入中间表result
| user_id | item_id | brand_id | action_type |
|---|---|---|---|
| 34176 | 408895 | 7370 | 0 |
| 34176 | 17235 | 4396 | 0 |
step3:按照要求进行数据分析
考核条件如下 :
1.在hive数据库下构建数据表shopping,数据类型参考步骤说明。
2.将原始导入到表shopping中,注意过滤第一行字段信息。
3.在hive数据库下创建result中间表,注意数据切分,相关要求参看步骤说明。
4.在hive数据库下创建click表,统计数据中点击次数top10的商品信息,结果写入文件/root/click_top_10/000000_0
5.统计数据中购买次数top10的商品信息,结果写入文件/root/emp_top_10/000000_0
6.统计数据中收藏次数top10的商品信息,结果写入文件/root/collect_top_10/000000_0
7.根据用户浏览(点击)最多的品牌,计算该品牌的的收藏购买转化率,结果写入/root/collect_emption路径下
8.查找最活跃用户,求出该用户对应的点击购买转化率最高的品牌信息,并将结果写入/root/click_emption路径下
贷款数据分析
(0 / 100 分)
首先创建对应数据库,根据数据类型创建表,最后将数据进行导入。
本此数据不进行数据清洗。数据说明如下:
LoanStatus:贷款状态
BorrowerRate:贷款率
ProsperScore:信用得分
Occupation:职业
EmploymentStatus:就业状态
IsBorrowerHomeowner:是否有房
CreditScoreRangeLower:信用评分下限
CreditScoreRangeUppe:信用得分上限
IncomeRange:收入范围
数据类型自行定义。
数据地址:/root/loan/loan.csv
1.赛题补充
5.对信用得分上限及下限进行中间数求值作为职业信用分,对职业进行分组,计算职业信用分top5。结果top5写入/root/college005/000000_0文件。
职业信用分:(CreditScoreRangeLower+CreditScoreRangeUpper)/2
分组说明:按照职业分组。
复合排列:按照职业信用分降序,职业升序;
结果格式:职业 职业信用分
2.数据挖掘
公式参考如下:
前项:A 后项:B
支持度:表示同时包含A和B的事务占所有事务的比例。如果用P(A)表示使用A事务的比例。
公式:Support=P(A&B)
置信度:表示使用包含A的事务中同时包含B事务的比例,即同时包含A和B的事务占包含A事务的比例。
公式:Confidence=P(A&B)/P(A)
题目:请根据Apriori关联规则算法的原理找出与违约最多的(借款状态,后项)之间的关联度最强的职业(前项),并计算出其支持度与置信度。
其他说明
为防止大数据集群稳定性,类似非全等join(非inner join)是禁止的,禁用了SemanticException笛卡尔产品。
FAILED: SemanticException Cartesian products are disabled for safety reasons. If you know what you are doing, please sethive.strict.checks.cartesian.product to false and that hive.mapred.mode is not set to ‘strict’ to proceed. Note that if you may get errors or incorrect results if you make a mistake while using some of the unsafe features.
# 进行数据挖掘笛卡尔积之前,进行如下配置
hive> set hive.strict.checks.cartesian.product;
# 首先查看hive.strict.checks.cartesian.product
hive> set hive.strict.checks.cartesian.product=false;
# 设置hive.strict.checks.cartesian.product为false
考核条件如下 :
1.将数据loan.csv上传到hdfs的/input/目录下
2.创建数据库hive
3.在hive数据库下构建数据表loan
4.将提供的分析数据导入到表loan中,并统计数据至本地/root/college000/000000_0文件中
5.以信用得分ProsperScore为变量,对借款进行计数统计(降序),结果写入本地/root/college001/000000_0文件中。
6.给出借款较多的行业top5,结果写入本地/root/college002/000000_0文件中。
7.分析贷款状态为违约(Defaulted)的贷款人就业信息,将结果top3写入/root/college003/000000_0文件
8.对数据中收入范围进行分组统计(降序),查看贷款人收入情况,结果写入/root/college004/000000_0文件
9.对信用得分上限及下限进行中间数求值作为职业信用分,对职业进行分组,计算职业信用分top5(具体见步骤说明)。结果写入/root/college005/000000_0文件。
10.支持度写到本地/root/college006/000000_0文件中(保留五位小数);
11.置信度写到本地/root/college007/000000_0文件中(保留五位小数)。
房屋租赁分析
1.项目需求
本数据为某中介网站某段时间某地区的防区出租价格,通过对户型、商圈、小区、地址、周围设施、交通配套等信息,对网站上的房源情况进行探索分析,进而了解地区性房租的相关情况。
2.数据说明
数据路径:/root/college/house.csv
| 字段说明 | 字段 | 数据类型 |
|---|---|---|
| 标题 | title | string |
| 户型 | layout | string |
| 区县 | district | string |
| 商圈 | area | string |
| 楼盘 | estate | string |
| 房租 | rent | int |
| 地铁 | station | string |
| 亮点1 | merit1 | string |
| 亮点2 | merit2 | string |
| 亮点3 | merit3 | string |
示例数据:
标题,户型,区县,商圈,小区,房租,地铁,亮点1,亮点2,亮点3
绿地 精装套二 随时看房 实图拍摄 临千盛 欧尚 优博 穿巷子,整租|2室2厅|84㎡|朝南,武侯,簇桥,绿地圣路易名邸,2400,家电齐全,
警官公寓 合租 次卧103平米2室1厅1卫限女生,合租次卧|2户合租|103㎡,高新区,中和镇,警官公寓,860,交通便利,合租女生,
高新区大源嘉祥瑞庭南城 35平米1室1厅1卫,整租|1室1厅|35㎡|朝南北,高新区,大源,嘉祥瑞庭南城,2300,采光好,
国光一环大厦1室1厅1卫,整租|1室1厅|60㎡|朝南,成华,建设路伊藤,国光一环大厦,1300,红星桥站,随时入住,
考核条件如下 :
1.在hive数据库下构建数据表house,并导入数据house.csv
2.计算房屋出租量前十的楼盘排名,结果写入本地/college2020/01/000000_0 (二维数组:楼盘 数量,不计入空值)
3.计算房屋出租量前十的商圈排名,结果写入本地/college2020/02/000000_0 (二维数组:商圈 数量,不计入空值)
4.整理双流区整租三室一厅不同楼盘价格,结果写入本地/college2020/03/000000_0 (二维数组:楼盘 价格,为均价降序)
5.现想在中坝站万家湾附近进行合租,试给出户型及房租信息进行参考,结果写入本地/college2020/04/000000_0 (二维数组:户型 价格降序)
6.现想在保利星座进行租房,预算为1000-1500,试给出参考户型信息,结果写入本地/college2020/05/000000_0 (二维数组:户型 价格降序)
7.试列出不同商圈整租1室1厅的价格TOP3,结果写入本地/college2020/06/000000_0 (二维数组:商圈 价格,均值降序)
8.试列出高新区不同户型的整租价格清单,结果写入本地/college2020/07/000000_0 (二维数组示例:3室2厅 4000,均值向下取整降序)
9.合并房屋出租亮点(特点),给出常用亮点TOP5,结果写入本地/college2020/08/000000_0 (二维数组:亮点 数量,不计入空值,降序)
共享单车数据分析
1.项目需求
现有数据为某年某段时间某地区的共享单车数据集,可以适用于大数据分析和挖掘。通过对共享单车的骑行规律,用户群体,单日活月用户等数据的分析,给出运营思路和方法上的建议,对共享单车的发展有一个整体的把握。基于对数据的分析,可以进行活动推广、会员特定优惠,也可进行专线共享大巴等活动策划。
目前有数据文件/root/college/bike.csv,字段解释:
| 字段中文释义 | 字段英文释义 |
|---|---|
| 骑行时间(毫秒为单位) | duration (ms) |
| 开始时间 | startdate |
| 结束时间 | enddate |
| 开始地点数 | startnum |
| 开始地点 | startstation |
| 结束地点数 | endnum |
| 结束地点 | dndstation |
| 单车车号 | bikenum |
| 用户类型 | type(Member 会员/ Casual临时会员) |
题目说明
-
数据上传至hdfs文件系统/college/目录下
-
统计本次数据所有单车数量(以单车车号进行计算),结果写入本地/root/bike01/000000_0文件中。
其他说明:以单车车号进行统计计算。 -
计算单车平均用时,结果写入本地/root/bike02/000000_0文件中,以分钟为单位,对数据结果取整数值(四舍五入)。
格式:对于结果中的二维数据,要求使用“\t”作为声明文件分隔符;
其他说明:以分钟为单位,对数据结果取整数值(四舍五入)。 -
统计常年用车紧张的地区站点top10,结果写入本地/root/bike03/000000_0文件中。(以stratstation为准)
格式:对于结果中的二维数据,要求使用“\t”作为声明文件分隔符;
复合排列:先按照用车总辆进行降序排列,再按照开始地区升序排列;
其他说明:数目限制为10。 -
给出共享单车单日租赁排行榜,结果写入本地/root/bike04/000000_0文件中。(以startdate为准,结果格式为2021-09-14)
格式:对于结果中的二维数据,要求使用“\t”作为声明文件分隔符;
复合排列:先按照租赁总量进行降序排列,再按照开始时间升序排列;
其他说明:数据为年月日,以开始时间为数据标准,排行前5。 -
给出建议维修的单车编号(使用次数),结果写入本地/root/bike05/000000_0文件中。
格式:对于结果中的二维数据,要求使用“\t”作为声明文件分隔符;
复合排列:先按照用车总辆进行降序排列,再按照单车编号升序排列;
其他说明:使用磨损较高的单车(使用次数),数目为10。 -
给出可进行会员活动推广的地区,结果写入本地/root/bike06/000000_0文件中。(以stratstation为准)
格式:对于结果中的二维数据,要求使用“\t”作为声明文件分隔符;
复合排列:先按照用车总辆进行降序排列,再按照开始地区升序排列;
其他说明:以非会员用户用车为数据标准,地区数目为10。 -
给出可舍弃的单车站点,结果写入本地/root/bike07/000000_0文件中。(以endstation为准)
格式:对于结果中的二维数据,要求使用“\t”作为声明文件分隔符;
复合排列:先按照用车总辆进行升序排列,再按照结束地区升序排列;
其他说明:以会员目的地为数据标准,地区数目为10。
提示
Hive数据导出到指定路径的文件中,方式如下:
方式一:在bash中直接通过hive -e命令,并用’>‘输出流把执行结果输出到制定文件
方式二:在bash中直接通过hive -f命令,执行文件中一条或者多条sql语句,并用’>'输出流把执行结果输出到制定文件
方式三:在hive中输入hive-sql语句,通过使用’INSERT OVERWRITE (LOCAL) DIRECTORY’结果到本地系统和HDFS文件系统
考核条件如下 :
1.数据/root/college/bike.csv上传至hdfs://college/目录下
2.统计本次数据所有单车数量(以单车车号进行计算,注意去重),结果写入本地/root/bike01/000000_0文件中。
3.计算单车平均用时,结果写入本地/root/bike02/000000_0文件中,以分钟为单位,对数据结果取整数值(四舍五入)。
4.统计常年用车紧张的地区站点top10,结果写入本地/root/bike03/000000_0文件中。(以stratstation为准)
5.给出共享单车单日租赁排行榜,结果写入本地/root/bike04/000000_0文件中。(以startdate为准,结果格式为2021-09-14)
6.给出建议维修的单车编号(使用次数),结果写入本地/root/bike05/000000_0文件中。
7.给出可进行会员活动推广的地区,结果写入本地/root/bike06/000000_0文件中。(以stratstation为准)
8.给出可舍弃的单车站点,结果写入本地/root/bike07/000000_0文件中。(以endstation为准)
注:文中所提资料仅提供第一题互联网日志分析题目分析文本资料,其他资料请按照题目要求自行生成相关符合条件的资料进行分析求解