数据库管理248期 2024-10-06
- 数据库管理-第248期 23ai:全球分布式数据库-分片数据分布方法(20241006)
- 1 系统管理分片
- 2 用户定义分片
- 2.1 分片空间
- 2.2 在用户定义分片配置中添加分片空间
- 2.3 为用户定义分片创建表空间
- 2.4 用户定义分片创建分片表
- 2.5 用户定义分片的块管理
- 2.6 用户定义分片的复制
- 3 基于目录分片
- 3.1 适用场景
- 3.1.1 系统管理分片数据不均匀
- 3.1.2 将某些键值分组到同一位置或块中
- 3.1.3 实施基于自定义策略的分片
- 3.2 组件及架构
- 3.3 创建表
- 4 复合分片
- 5 分片中使用子分区
- 总结
数据库管理-第248期 23ai:全球分布式数据库-分片数据分布方法(20241006)
作者:胖头鱼的鱼缸(尹海文)
Oracle ACE Pro: Database(Oracle与MySQL)
PostgreSQL ACE Partner
10年数据库行业经验,现主要从事数据库服务工作
拥有OCM 11g/12c/19c、MySQL 8.0 OCP、Exadata、CDP等认证
墨天轮MVP、年度墨力之星,ITPUB认证专家、专家百人团成员,OCM讲师,PolarDB开源社区技术顾问,HaloDB外聘技术顾问,OceanBase观察团成员,青学会MOP技术社区(青年数据库学习互助会)技术顾问
圈内拥有“总监”、“保安”、“国产数据库最大敌人”等称号,非著名社恐(社交恐怖分子)
公众号:胖头鱼的鱼缸;CSDN:胖头鱼的鱼缸(尹海文);墨天轮:胖头鱼的鱼缸;ITPUB:yhw1809。
除授权转载并标明出处外,均为“非法”抄袭

Oracle全球分布式数据库支持多种分片表数据分布方式。
1 系统管理分片
System-managed sharding,系统管理分片,不需要用户指定数据到分片的映射。数据通过一致哈希进行分区,自动分布在分片之间。分区算法在分片之间均匀随机地分布数据。系统管理分片中使用的分布旨在消除热点,并在分片之间提供统一的性能。当向分片数据库添加分片或从分片数据库中删除分片时,Oracle全局分布式数据库会自动保持块的平衡分布。
一致性哈希是一种常用在可扩展分布式系统中的分区策略。它不同于传统的哈希分区。使用传统散列,桶(bucket)的数量计算为HF(key)%N,其中HF是散列函数,N是桶的数量。如果N是常数,这种方法可以很好地工作,但当N发生变化时,需要重新整理所有数据。更高级的算法,如线性散列,不需要重新散列整个表来添加哈希桶,但它们对桶的数量施加了限制,例如桶的数量只能是2的幂,以及桶可以拆分的顺序。
Oracle全局分布式数据库中使用的一致性哈希的实现通过将哈希函数的可能值范围(例如从0到232)划分为一组N个相邻区间,并将每个区间分配给一个块来避免这些限制,如下图所示。在这个例子中,分片数据库包含1024个块,每个块被分配222个哈希值。因此,按一致哈希进行分区本质上就是按哈希值的范围进行分区。
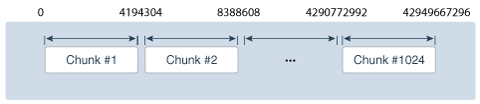
假设所有分片具有相同的计算能力,则分片数据库中的每个分片都分配了相等数量的块。例如,如果在包含16个分片的分片数据库中创建1024个块,则每个分片将包含64个块。
在重新分片的情况下,当分片被添加到分片数据库或从分片数据库中删除时,一些块会在分片之间重新定位,以保持分片上块的均匀分布。在此过程中,块的内容不会改变;不需要重组数据。
当一个块被分割时,它的哈希值范围被分为两个范围,但其他块不需要做任何操作。任何块都可以在任何时候独立分割。
分片数据库中涉及将连接请求定向到分片的所有组件都维护一个路由表,该路由表包含每个分片托管的块列表以及与每个块关联的哈希值范围。为了确定将特定数据库请求路由到何处,路由算法将哈希函数应用于分片键的提供值,并将计算出的哈希值映射到适当的块,然后映射到包含该块的分片。
在创建分片目录时,可以指定具有系统管理分片的分片数据库中的块数。如果未指定,则使用默认值,即每个分片120个块。一旦部署了分片数据库,就只能通过拆分块来更改块的数量。
在创建由一致哈希分区的分片表之前,必须创建一组表空间(每个块一个表空间)来存储表分区。表空间是通过处理SQL语句CREATE TABLESPACE SET自动创建的。
表空间组中的所有表空间都具有相同的物理属性,并且只能使用OMF管理。在最简单的形式中,CREATE TABLESPACE SET语句只有一个参数,即表空间组的名称,例如:
CREATE TABLESPACE SET ts1;
在这种情况下,表空间组中的每个表空间都包含一个具有默认属性的OMF文件。为了自定义表空间属性,将USING TEMPLATE子句(如下例所示)添加到语句中。USING TEMPLATE子句指定应用于集合中每个表空间的属性:
CREATE TABLESPACE SET ts1
USING TEMPLATE
(
DATAFILE SIZE 10M
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 256K
SEGMENT SPACE MANAGEMENT AUTO
ONLINE
)
;
创建表空间组后,可以使用存储在属于该组的表空间中的分区创建由一致哈希分区的表。CREATE TABLE语句可能如下所示:
CREATE SHARDED TABLE customers
( cust_id NUMBER NOT NULL
, name VARCHAR2(50)
, address VARCHAR2(250)
, location_id VARCHAR2(20)
, class VARCHAR2(3)
, signup DATE
, CONSTRAINT cust_pk PRIMARY KEY(cust_id)
)
PARTITION BY CONSISTENT HASH (cust_id)
PARTITIONS AUTO
TABLESPACE SET ts1
;
在此语句中,PARTITIONS AUTO表示分区数量自动设置为表空间组ts1中的表空间数量(等于块的数量),每个分区将存储在单独的表空间中。
表空间组中的每个表空间都属于一个不同的块。换句话说,一个块只能包含给定表空间组中的一个表空间。但是,同一表空间组可用于属于同一表族的多个表。在这种情况下,表空间组中的每个表空间将存储多个分区,每个分区来自每个表。
或者,表族中的每个表都可以存储在单独的表空间集中。在这种情况下,一个块包含多个表空间,每个表空间组中有一个表空间。每个表空间存储一个分区。
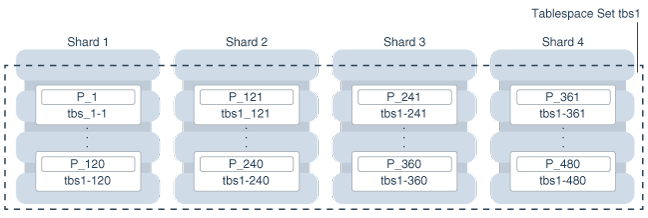
下图说明了具有单个分片表的用例中分区、表空间和分片之间的关系。在这种情况下,每个块包含一个表空间,每个表空间存储一个分区。
2 用户定义分片
User-defined sharding,用户定义分片,允许明确指定数据到每个分片的映射。当由于性能、监管或其他原因,某些数据需要存储在特定的分片上,并且管理员需要完全控制分片之间的数据移动时,就会使用它。
用户定义分片的另一个优点是,在分片计划内或计划外停机的情况下,用户确切地知道哪些数据不可用。用户定义分片的缺点是数据库管理员需要监控和维护分片之间数据和工作负载的平衡分布。
2.1 分片空间
shardspace,分片空间,是一组分片,用于存储与键值范围(range)或列表(list)相对应的数据。在用户定义的分片中,分片空间由一个分片或一组完全复制的分片组成。为简单起见,假设每个分片空间都由一个分片组成。
2.2 在用户定义分片配置中添加分片空间
在将分片及其CDB添加到用户定义的分片配置之前,必须创建并填充分片空间。例如,您可以使用以下GDSCTL命令:
ADD SHARDSPACE -SHARDSPACE east
ADD SHARDSPACE -SHARDSPACE central
ADD SHARDSPACE -SHARDSPACE west
ADD CDB -CONNECT cdb1
ADD CDB -CONNECT cdb2
ADD CDB -CONNECT cdb3
ADD SHARD –CONNECT shard-1 -CDB cdb1 –SHARDSPACE west;
ADD SHARD –CONNECT shard-2 -CDB cdb2 –SHARDSPACE central;
ADD SHARD –CONNECT shard-3 -CDB cdb3 –SHARDSPACE east;
2.3 为用户定义分片创建表空间
用户定义的分片无需设置表空间组。每个表空间都必须单独创建,并明确地与分片空间相关联。
以下语句可用于为上述示例中的每个共享空间创建表空间:
CREATE TABLESPACE tbs1 IN SHARDSPACE west;
CREATE TABLESPACE tbs2 IN SHARDSPACE central;
CREATE TABLESPACE tbs3 IN SHARDSPACE east;
2.4 用户定义分片创建分片表
使用用户定义的分片,可以按范围或列表对分片表进行分区。分片表的CREATE TABLE语法与常规表的语法没有太大区别,除了要求每个分区都应存储在单独的表空间中。
例如:
CREATE SHARDED TABLE accounts
( id NUMBER
, account_number NUMBER
, customer_id NUMBER
, branch_id NUMBER
, state VARCHAR(2) NOT NULL
, status VARCHAR2(1)
)
PARTITION BY LIST (state)
( PARTITION p_west VALUES ('OR', 'WA') TABLESPACE ts1
, PARTITION p_central VALUES ('SD', 'WI') TABLESPACE ts2
, PARTITION p_east VALUES ('NY', 'VM', 'NJ') TABLESPACE ts3
)
;
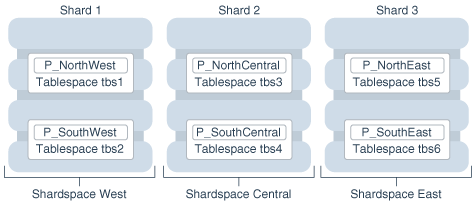
下图显示了前面示例中accounts表的分区到表空间以及表空间到分片的映射:
2.5 用户定义分片的块管理
与系统管理的分片一样,为用户定义的分片创建的表空间被分配给块。但是,当将分片添加到分片数据库中时,不会自动启动块迁移。您必须为每个需要迁移的块在GDSCTL中执行MOVE CHUNK命令。
块的总数由分片表中指定的分区数量定义。给定分片空间的块数是指分配给它的分区数。分片表上的ALTER TABLE ADD、DROP、SPLIT和MERGE PARTITION命令可以增加或减少块数。
GDSCTL中使用SPLIT CHUNK命令用于为系统管理的分片拆分哈希范围中间的块,但用户定义的分片不支持该命令。您必须使用ALTER TABLE SPLIT PARTITION语句来分割块。
2.6 用户定义分片的复制
用户定义分片数据库,支持两种复制方案:
- Oracle Data Guard
- Oracle Active Data Guard
用户定义分片不支持使用Raft复制方法。
3 基于目录分片
Directory-based sharding,基于目录分片,允许在运行时动态地将键值与分片显式关联,这使可以对键值到分片的映射进行细粒度控制
与此相比,系统管理的分片可能会导致数据分布不均,特别是当存在相对大量的不同键值(数万到数十万),但通常不足以实现基于哈希的分配以实现统一的数据分布时。此外,将其与常规的用户定义分片进行比较,后者最适合在schema创建时指定的少量静态键值。
3.1 适用场景
以下用例说明了在分片数据库中使用基于目录的数据分发方法何时是有利的:
3.1.1 系统管理分片数据不均匀
当系统分片因为不同键值的数量不够大导致数据分布不均时,基于目录的分片可能更合适。
一个典型的用例是一个B2B应用程序,它管理着数以万计的商业客户账户的数据。
一个例子是经销商应用程序,它为许多经销商托管和管理数据。经销商的数量在数万家,这不足以通过哈希实现数据的均匀分布。更重要的是,不同经销商的数据量可能大不相同:一些经销商是大型企业,而另一些经销商则小得多,因此我们不希望像系统内分片那样对待它们。可能还需要根据特定应用的标准为不同的经销商指定不同的资源/地点。
3.1.2 将某些键值分组到同一位置或块中
当您需要将某些键值组合到同一位置或块中以实现相关性时,基于目录的分片非常有用,并且在需要时可以有效地将该组移动到一起。
一个例子是社交网络应用程序,将经常在同一分片上交换消息的客户分组在一起,可以最大限度地减少跨分片流量。当数据在分片之间移动时,在重新分片过程中必须保留分组。另一方面,如果组的一个成员开始与另一个组的成员进行更多的通信,他们的数据必须移动到适当的组,对应用程序的影响最小。
3.1.3 实施基于自定义策略的分片
基于目录的分片可用于实现基于策略的自定义分片,如轮转、随机、最少数据等。
3.2 组件及架构
基于目录分片的关键组件:
- 键值到分区和分片的映射存储在目录表中。
- 当创建按目录分片的表时,目录表会在分片目录和分片中自动创建。
- 分片控制器(GSM)和客户端连接池缓存目录以用于路由目的。缓存中的键值是加密的。
- 当在启用自动分配规则的情况下,将行插入到分片表或从分片表中删除以进行插入时,目录会自动更新。删除操作不会自动删除目录中的映射。
- 分片表包含一个带有分区信息的虚拟列,用于分区修剪。
下图显示了基于目录的分片的关键组件:目录表(directory table)存放在分片目录上,并复制到所有分片。分片表根据目录表中的键/分区映射分布在不同的分片上。

键插入和更新操作在分片目录上执行,并在提交时同步复制到分片。
客户端池以与其他分片方法相同的方式从每个分片获取块/分片映射的密钥。他们还订阅FAN事件,通知他们新的密钥映射或删除。
基于目录的分片是对用户定义分片方法的增强。
3.3 创建表
基于目录的分片表是使用CREATE SHAREDD TABLE语句中的PARTITION BY Directory创建的:
CREATE SHARDED TABLE customers
( id NUMBER NOT NULL
, name VARCHAR2(30)
, address VARCHAR2(30)
, status VARCHAR2(1)
,
CONSTRAINT cust_pk PRIMARY KEY(id)
)
PARTITION BY DIRECTORY (id)
( PARTITION p1 TABLESPACE tbs1,
PARTITION p2 TABLESPACE tbs2,
PARTITION p3 TABLESPACE tbs3…);
- 这里需要注意的是,和用户定义分片不同,基于目录的分片中,分片表创建时不需要指定分区的键值
- 目录表是在根表创建过程中自动创建的。目录表的定义是:
<shard_user_schema><root_table>$SDIR
4 复合分片
Composite Sharding,复合分片,允许由一致哈希分区的表中的不同数据子集创建多个分片空间。分片空间是一组分片,用于存储与键值范围或列表相对应的数据。
系统管理的分片使用一致哈希进行分区,在分片之间随机分配数据。与使用按范围或列表分区的用户定义分片相比,这提供了更好的负载平衡。然而,系统管理的分片并不能让用户对分片的数据分配有任何控制权。
当对主键进行一致哈希分片时,通常需要区分分片数据库中的数据子集,以便将它们存储在不同的地理位置,为它们分配不同的硬件资源,或以不同的方式配置高可用性和灾难恢复。通常,这种区分是基于另一个(非主要)列的值来完成的,例如客户位置或服务类别。
复合分片是用户定义分片和系统管理分片的组合,在需要时,可以提供这两种方法的优点。使用复合分片,数据首先在多个分片空间中按列表或范围进行分区,然后在每个分片空间的多个分块中按一致的哈希进行进一步分区。这两个级别的分片使得在每个分片空间中自动保持数据在分片之间的平衡分布成为可能,同时也可以在分片空间之间对数据进行分区。
例如,假设您想将托管在较快服务器上的三个分片分配给“黄金”客户,将托管在较慢机器上的四个分片分片分配给与“白银”客户。在每组分片中,客户必须通过客户ID上的一致哈希进行分区。
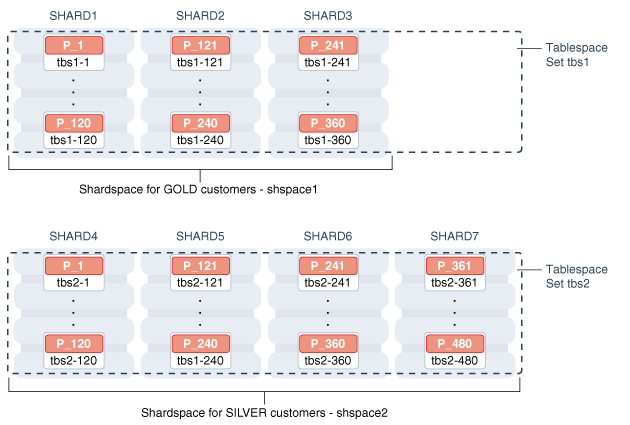
下面命令可以用来创建创建此配置。请注意,此配置需要创建两个分片空间:
create SHARDCATALOG -sharding composite -database
cat_host:1521/cat_pdb.domain -user gsmcatuser/gsmcatuser_pwd
-region dc1
add gsm -gsm gsm1 -listener 1540 -catalog cat_host:1521/cat_pdb.domain
-region dc1 -pwd gsmcatuser_pwd
gdsctl start gsm
add shardspace -shardspace shspace1 -chunks 60
add shardspace -shardspace shspace2 -chunks 120
ADD SHARDGROUP -shardgroup gold -shardspace shspace1 -region dc1 -deploy_as
primary
ADD SHARDGROUP -shardgroup silver -shardspace shspace2 -region dc1 -deploy_as
primary
add CDB -connect cdb1_host:1521/cdb1.domain -pwd gsmrootuser_pwd
add CDB -connect cdb2_host:1521/cdb2.domain -pwd gsmrootuser_pwd
add CDB -connect cdb3_host:1521/cdb3.domain -pwd gsmrootuser_pwd
add CDB -connect cdb4_host:1521/cdb4.domain -pwd gsmrootuser_pwd
add CDB -connect cdb5_host:1521/cdb5.domain -pwd gsmrootuser_pwd
add CDB -connect cdb6_host:1521/cdb6.domain -pwd gsmrootuser_pwd
add CDB -connect cdb7_host:1521/cdb7.domain -pwd gsmrootuser_pwd
add shard -cdb cdb1 -shardgroup gold -connect
cdb1_host:1521/sh1_pdb.domain -pwd gsmuser_pwd
add shard -cdb cdb2 -shardgroup gold -connect
cdb2_host:1521/sh2_pdb.domain -pwd gsmuser_pwd
add shard -cdb cdb3 -shardgroup gold -connect
cdb3_host:1521/sh3_pdb.domain -pwd gsmuser_pwd
add shard -cdb cdb4 -shardgroup silver -connect
cdb4_host:1521/sh4_pdb.domain -pwd gsmuser_pwd
add shard -cdb cdb5 -shardgroup silver -connect
cdb5_host:1521/sh5_pdb.domain -pwd gsmuser_pwd
add shard -cdb cdb6 -shardgroup silver -connect
cdb6_host:1521/sh6_pdb.domain -pwd gsmuser_pwd
add shard -cdb cdb7 -shardgroup silver -connect
cdb7_host:1521/sh7_pdb.domain -pwd gsmuser_pwd
deploy
与其他分片方法一样,使用复合分片时,表空间用于指定分区到分片的映射。要将分片表中的数据子集放入不同的分片空间,必须在每个分片空间中创建一个单独的表空间组,如下例所示:
CREATE TABLESPACE SET tbs1 IN SHARDSPACE shspace1;
CREATE TABLESPACE SET tbs2 IN SHARDSPACE shspace2;
为了在不同的表空间中存储用户定义的数据子集,Oracle全球分布式数据库提供了将分区分组到集合中的语法,并将每组分区与表空间组相关联。对分区集的支持可以被认为是更高级别分区的逻辑等价物,它是在一致哈希分区的基础上实现的。
以下示例中的语句根据服务类将分片表划分为两个分区集:金和银。每个分区集都存储在单独的表空间中。然后,每个分区集中的数据通过客户ID上的一致哈希进行进一步分区:
CREATE SHARDED TABLE customers
( cust_id NUMBER NOT NULL
, name VARCHAR2(50)
, address VARCHAR2(250)
, location_id VARCHAR2(20)
, class VARCHAR2(3)
, signup_date DATE
, CONSTRAINT cust_pk PRIMARY KEY(cust_id, class)
)
PARTITIONSET BY LIST (class)
PARTITION BY CONSISTENT HASH (cust_id)
PARTITIONS AUTO
(PARTITIONSET gold VALUES (‘gld’) TABLESPACE SET tbs1,
PARTITIONSET silver VALUES (‘slv’) TABLESPACE SET tbs2)
;
注意:分片方法在GDSCTL CREATE SHARDCATALOG命令中指定,以后无法更改。
5 分片中使用子分区
由于Oracle全球分布式数据库基于表分区,因此Oracle数据库提供的所有子分区方法也都支持分片。
子分区将每个分区拆分为更小的部分,这可能有利于分片内的高效并行处理,特别是在按范围或列表分片的情况下,每个分片的分区数量可能很小。
从可管理性的角度来看,子分区可以通过将子分区放入单独的表空间并在存储层之间移动来支持分层存储方法。可以在存储层之间迁移子分区,而不会牺牲分片的可扩展性和可用性优势,以及在主键上执行分区修剪和分区连接的能力。
以下示例显示了通过一致哈希结合按范围进行子分区的系统管理分片:
CREATE SHARDED TABLE customers
( cust_id NUMBER NOT NULL
, name VARCHAR2(50)
, address VARCHAR2(250)
, location_id VARCHAR2(20)
, class VARCHAR2(3)
, signup_date DATE
, CONSTRAINT cust_pk PRIMARY KEY(cust_id, signup_date)
)
TABLESPACE SET ts1
PARTITION BY CONSISTENT HASH (cust_id)
SUBPARTITION BY RANGE (signup_date)
SUBPARTITION TEMPLATE
( SUBPARTITION per1 VALUES LESS THAN (TO_DATE('01/01/2000','DD/MM/YYYY')),
SUBPARTITION per2 VALUES LESS THAN (TO_DATE('01/01/2010','DD/MM/YYYY')),
SUBPARTITION per3 VALUES LESS THAN (TO_DATE('01/01/2020','DD/MM/YYYY')),
SUBPARTITION future VALUES LESS THAN (MAXVALUE)
)
PARTITIONS AUTO
;
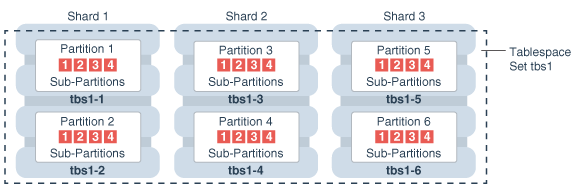
在这个例子中,每个子分区都存储在父分区的表空间中。由于子分区是按日期完成的,因此将子分区存储在单独的表空间中更有意义,以提供存档旧数据或将其移动到只读存储的能力。下面是对应的语法:
CREATE SHARDED TABLE customers
( cust_id NUMBER NOT NULL
, name VARCHAR2(50)
, address VARCHAR2(250)
, location_id VARCHAR2(20)
, class VARCHAR2(3)
, signup_date DATE NOT NULL
, CONSTRAINT cust_pk PRIMARY KEY(cust_id, signup_date)
)
PARTITION BY CONSISTENT HASH (cust_id)
SUBPARTITION BY RANGE(signup_date)
SUBPARTITION TEMPLATE
( SUBPARTITION per1 VALUES LESS THAN (TO_DATE('01/01/2000','DD/MM/YYYY'))
TABLESPACE SET ts1,
SUBPARTITION per2 VALUES LESS THAN (TO_DATE('01/01/2010','DD/MM/YYYY'))
TABLESPACE SET ts2,
SUBPARTITION per3 VALUES LESS THAN (TO_DATE('01/01/2020','DD/MM/YYYY'))
TABLESPACE SET ts3,
SUBPARTITION future VALUES LESS THAN (MAXVALUE)
TABLESPACE SET ts4
)
PARTITIONS AUTO
;
请注意,对于非分片的数据库,当在子分区模板中指定表空间时,这意味着每个分区的子分区N都存储在同一个表空间中。这在分片的情况下是不同的,因为属于不同分区的子分区必须存储在单独的表空间中,以便在重新分片时可以移动它们。
子分区也可以与复合分片一起使用。在这种情况下,表中的数据分为三个级别:分区集、分区和子分区。下面显示了三个数据组织级别的示例。
不支持为每个分区集指定子分区模板,以确保分区集中子分区的数量和边界的一致性。如果需要为每个分区集的子分区指定表空间,可以使用subpartitions STORE IN子句。
CREATE SHARDED TABLE customers
( cust_id NUMBER NOT NULL
, name VARCHAR2(50)
, address VARCHAR2(250)
, location_id VARCHAR2(20)
, class VARCHAR2(3) NOT NULL
, signup_date DATE NOT NULL
, CONSTRAINT cust_pk PRIMARY KEY(cust_id, class, signup_date)
)
PARTITIONSET BY LIST (class)
PARTITION BY CONSISTENT HASH (cust_id)
SUBPARTITION BY RANGE (signup_date)
SUBPARTITION TEMPLATE /* applies to both SHARDSPACEs */
( SUBPARTITION per1 VALUES LESS THAN (TO_DATE('01/01/2000','DD/MM/YYYY'))
, SUBPARTITION per2 VALUES LESS THAN (TO_DATE('01/01/2010','DD/MM/YYYY'))
, SUBPARTITION per3 VALUES LESS THAN (TO_DATE('01/01/2020','DD/MM/YYYY'))
, SUBPARTITION future VALUES LESS THAN (MAXVALUE)
)
PARTITIONS AUTO
(
PARTITIONSET gold VALUES (‘gld’) TABLESPACE SET tbs1
subpartitions store in(tbs1)
, PARTITIONSET silver VALUES (‘slv’) TABLESPACE SET tbs2
subpartitions store in(tbs2)
)
;
总结
本期对Oracle全球分布式数据库的分片上分布方法进行了简单介绍。
老规矩,知道写了些啥。




![HTB:Funnel[WriteUP]](https://i-blog.csdnimg.cn/direct/5fccefa72f6e40648705eb54d581e560.png)













