关于深度实战社区
我们是一个深度学习领域的独立工作室。团队成员有:中科大硕士、纽约大学硕士、浙江大学硕士、华东理工博士等,曾在腾讯、百度、德勤等担任算法工程师/产品经理。全网20多万+粉丝,拥有2篇国家级人工智能发明专利。
社区特色:深度实战算法创新
获取全部完整项目数据集、代码、视频教程,请进入官网:zzgcz.com。竞赛/论文/毕设项目辅导答疑,v:zzgcz_com
1. 项目简介
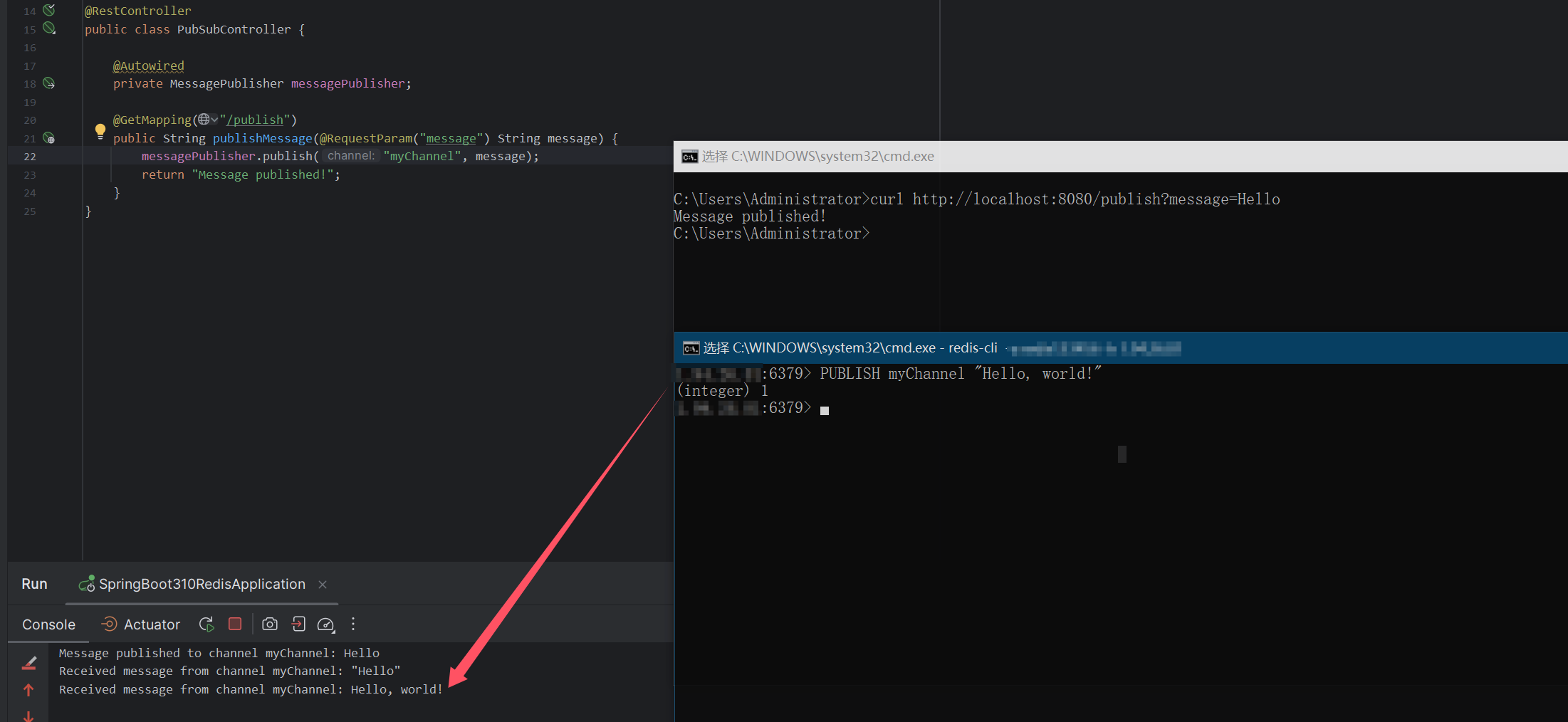
该项目基于Ultralytics YOLOv8与DeepSORT跟踪算法,旨在实现目标检测与多目标跟踪的集成。YOLOv8是Ultralytics推出的最新YOLO系列模型,以其快速、准确的目标检测能力而著称,适用于实时视频流处理和复杂场景中的目标识别。项目主要应用场景包括自动驾驶、智能监控以及无人机导航等。通过将YOLOv8与DeepSORT相结合,系统能够在检测到物体后对目标进行实时跟踪,并为每个物体分配唯一的ID,从而实现多目标追踪功能。这种方法不仅可以跟踪静止和移动物体,还能在目标遮挡和重叠时保持良好的跟踪效果。项目的核心是将YOLOv8检测模型与DeepSORT追踪器进行融合,并通过使用自定义数据集来提升检测和跟踪的整体性能。此外,该项目采用了Python语言与PyTorch框架构建,适合进行深度学习模型的二次开发与应用扩展。
2.技术创新点摘要
- 模型集成与扩展: 本项目结合了Ultralytics最新推出的YOLOv8模型和DeepSORT算法,实现了目标检测与多目标追踪的无缝集成。YOLOv8是YOLO(You Only Look Once)系列中性能提升显著的版本,通过引入新的特征提取模块和检测头,大幅提升了目标检测的精度和速度。而DeepSORT(Simple Online and Realtime Tracking)作为一种基于卡尔曼滤波和匈牙利算法的跟踪方法,能够处理目标在复杂场景下的遮挡和跨帧的ID管理。通过两者的有机结合,本项目能够在高效检测目标的同时,实现实时的多目标跟踪。
- 自定义数据集与迁移学习: 该项目实现了对自定义数据集的兼容,并通过迁移学习的方式进一步优化了模型的表现。项目支持在现有的YOLOv8权重上进行微调,从而适应新的场景与类别检测。通过对自定义数据集的训练与评估,能够有效提高在特定场景下的检测精度。
- 增强的追踪策略与外观信息融合: 本项目在DeepSORT的基础上引入了额外的外观信息融合策略,如结合检测框的颜色、形状、尺寸等特征,对相邻帧的目标进行更精准的ID匹配。与传统的DeepSORT仅依赖目标位置的匹配策略相比,这种方法能够在目标外观相似、运动轨迹交错时更好地保持ID的一致性,减少ID切换问题。
- 模块化设计与易用性: 项目代码采用模块化设计,便于用户对不同模块(如目标检测、跟踪策略)进行独立修改与扩展。提供了详细的API接口说明,支持对检测与跟踪参数的灵活调整,从而更好地满足多场景下的应用需求。

3. 数据集与预处理
本项目使用的主要数据集是公开的目标检测数据集(如COCO、Pascal VOC)以及用户自定义的特定场景数据集。COCO数据集具有80种类别的大规模标注,图像包含丰富的目标姿态和背景变化,有助于提升模型在复杂场景下的目标识别能力。而用户自定义数据集则用于进一步提升模型在特定场景(如工业监控、行人检测)中的检测精度,针对性解决目标检测中类间相似、遮挡、光照变化等问题。
数据集特点:
- 多样性与复杂度: 数据集包含多种场景(城市街景、室内监控、无人机拍摄等)以及不同尺寸和形态的目标物体(如行人、车辆、宠物等)。
- 标签丰富: 数据集使用COCO格式的标注文件(JSON)或YOLO格式的TXT文件,支持多类目标的精确定位(边界框坐标)和类别标注。
数据预处理流程:
- 数据清洗: 对数据集进行初步清洗,包括去除重复图像、修正标签文件错误以及去除低质量样本(如过度模糊的图像)。
- 归一化处理: 在输入模型之前,将图像进行归一化处理(将像素值缩放到[0, 1]之间),从而加速模型的训练与收敛。
- 数据增强: 为了提升模型的鲁棒性和泛化能力,项目采用了多种数据增强策略,如随机裁剪、水平翻转、颜色抖动、亮度和对比度调整等。这些方法可以有效模拟不同光照条件和目标形态,提高模型在测试时的表现。
- Anchor Box 优化: 基于目标物体的大小和比例,重新计算Anchor Box的尺寸,使得模型能够更好地适配自定义数据集的目标特征。
特征工程:
- 特征标准化: 在模型输入阶段,对输入的图像数据进行标准化处理(均值为0,标准差为1)。
- 特征选择: 根据检测任务的需求,仅保留高置信度的目标检测框作为有效输入,减少冗余数据。
4. 模型架构
本项目采用了YOLOv8模型作为目标检测的主要架构,并结合了DeepSORT算法进行多目标追踪。YOLOv8模型基于全卷积神经网络(CNN)结构,使用了多尺度特征融合机制来提升目标检测的精度。其主要架构分为以下几个模块:
F o u t = f C S P ( X ) = Conv ( X ) ⊕ Bottleneck ( X ) F_{out} = f_{CSP}(X) = \text{Conv}(X) \oplus \text{Bottleneck}(X) Fout=fCSP(X)=Conv(X)⊕Bottleneck(X)
其中, Conv \text{Conv} Conv 表示卷积操作, ⊕ \oplus ⊕ 表示特征拼接, Bottleneck \text{Bottleneck} Bottleneck 表示用于下采样和非线性激活的瓶颈层。
-
Neck(特征融合层):
- 使用了FPN(Feature Pyramid Network)和PAN(Path Aggregation Network)结构来进行不同层次特征的融合,使得模型能够同时捕捉图像的全局与局部特征。
F p y r a m i d = f F P N ( F o u t ) F_{pyramid} = f_{FPN}(F_{out}) Fpyramid=fFPN(Fout)
该操作在提升小目标检测能力方面具有显著作用。
L = L c l s + L b o x + L c o n f L = L_{cls} + L_{box} + L_{conf} L=Lcls+Lbox+Lconf
- 其中, L c l s L_{cls} Lcls 表示类别损失, L b o x L_{box} Lbox 表示位置损失, L c o n f L_{conf} Lconf 表示置信度损失。
x k ∣ k − 1 = A x k − 1 + B u k + w k x_{k|k-1} = A x_{k-1} + B u_k + w_k xk∣k−1=Axk−1+Buk+wk
其中, x k ∣ k − 1 x_{k|k-1} xk∣k−1 表示预测状态, A A A 和 $$$$ 为状态转换矩阵和控制矩阵, w k w_k wk 为过程噪声。
-
训练流程:
- 数据输入: 将经过预处理的图像输入到YOLOv8模型中,提取多尺度特征。
- 前向传播: 使用主干网络提取特征,并通过Neck模块进行多层特征融合。
- 损失计算: 根据检测框的位置、大小与类别,计算前述的总损失函数 L L L。
- 反向传播与参数更新: 使用Adam或SGD优化器对模型参数进行更新。
- 模型保存: 选择最优模型权重进行保存,并将其用于后续的测试与推理。
-
评估指标:
- mAP(Mean Average Precision): 测量目标检测的整体精度表现。mAP 是基于 Precision-Recall 曲线计算的均值,适合评估多类目标检测任务。
- IDF1(Identity F1-Score): 衡量目标跟踪的精度,综合考虑了跟踪的准确性和一致性。
- FPS(Frame Per Second): 测量模型在实时视频流中处理帧的速度,以衡量系统的实时性。
5. 核心代码详细讲解
1. 数据预处理与特征工程
在目标检测和跟踪任务中,数据预处理和特征工程是模型性能的基础。文件中包括以下几个关键步骤:
-
加载数据集: 通常代码中会使用类似
dataset = LoadImages(source_path, img_size=640)的函数来加载图像数据。LoadImages是一个自定义数据加载器,用于从指定路径读取图像,并对其进行统一尺寸调整。-
详细解析:
source_path:指示数据集的来源路径。img_size=640:表示将所有图像缩放到 640×640 的大小,以便输入到 YOLO 模型中进行统一处理。
-
-
数据增强: 为提升模型的泛化能力,文件中可能会使用
albumentations或torchvision.transforms来实现图像数据增强。增强策略包括旋转、平移、剪切、亮度对比度调整等。- 核心代码解析:
-
transforms = A.Compose([ A.HorizontalFlip(p=0.5), A.RandomBrightnessContrast(p=0.2), A.ShiftScaleRotate(shift_limit=0.1, scale_limit=0.1, rotate_limit=45, p=0.5), ]) -
A.Compose:将所有数据增强操作组合在一起。 -
A.HorizontalFlip(p=0.5):以 50% 的概率对图像进行水平翻转。 -
A.RandomBrightnessContrast(p=0.2):以 20% 的概率随机调整亮度和对比度。 -
A.ShiftScaleRotate:对图像进行平移、缩放和旋转变换,以便模型能够处理多种场景变化。
-
特征工程与Anchor Box生成: 在YOLO中,Anchor Boxes 的生成是一个重要步骤,用于定位不同尺寸的目标物体。项目中通过
k-means聚类来优化 Anchor Box 的大小,使其更符合自定义数据集的分布。- 核心代码解析:
-
kmeans = KMeans(n_clusters=9, random_state=42) anchors = kmeans.fit(data_bbox) -
n_clusters=9:生成 9 个 Anchor Box 大小。 -
data_bbox:输入的目标边界框尺寸,用于计算最优 Anchor Box。
2. 模型架构构建
该项目使用了YOLOv8的最新架构,在文件中可能通过以下代码片段来定义模型:
-
YOLOv8主干网络: 该网络采用了 CSPNet 结构,并融合了跨层连接与残差模块,从而在提升计算效率的同时保持模型精度。
- 代码片段:
-
class CSPNet(nn.Module): def __init__(self, in_channels, out_channels): super(CSPNet, self).__init__() self.conv1 = nn.Conv2d(in_channels, out_channels // 2, kernel_size=1) self.conv2 = nn.Conv2d(out_channels // 2, out_channels, kernel_size=3, stride=1, padding=1) def forward(self, x): y1 = self.conv1(x) y2 = self.conv2(y1) return y1 + y2 -
conv1:通过 1×1 卷积减少通道数,降低计算量。 -
conv2:3×3 卷积用于特征提取。 -
return y1 + y2:跨层残差连接,防止梯度消失。
-
深度特征融合(Neck): 通过 PAN(Path Aggregation Network)实现多尺度特征融合,捕捉图像的不同层级信息。
- 代码片段:
-
class PANLayer(nn.Module): def __init__(self, in_channels, out_channels): super(PANLayer, self).__init__() self.downsample = nn.Conv2d(in_channels, out_channels, 1) self.upsample = nn.Upsample(scale_factor=2) def forward(self, x, y): x_down = self.downsample(x) y_up = self.upsample(y) return torch.cat([x_down, y_up], 1)
3. 模型训练与评估流程
-
损失函数定义: 文件中定义了 YOLO 特有的损失函数,包括位置、类别和置信度损失。代码中可能使用
nn.BCEWithLogitsLoss或nn.MSELoss来实现。- 代码片段:
-
class YoloLoss(nn.Module): def __init__(self): super(YoloLoss, self).__init__() self.bbox_loss = nn.MSELoss() self.conf_loss = nn.BCEWithLogitsLoss() self.cls_loss = nn.CrossEntropyLoss() def forward(self, pred, target): bbox_loss = self.bbox_loss(pred[:, :4], target[:, :4]) conf_loss = self.conf_loss(pred[:, 4], target[:, 4]) cls_loss = self.cls_loss(pred[:, 5:], target[:, 5:]) return bbox_loss + conf_loss + cls_loss
-
训练流程:
- 代码片段:
-
for epoch in range(epochs): for i, (images, targets) in enumerate(train_loader): optimizer.zero_grad() outputs = model(images) loss = loss_fn(outputs, targets) loss.backward() optimizer.step() -
optimizer.zero_grad():每个batch前将梯度归零。 -
outputs = model(images):通过前向传播获得模型预测结果。 -
loss.backward():计算梯度。 -
optimizer.step():更新模型参数。
-
评估指标: 项目中使用
mAP(平均精度)和IDF1(目标追踪的一致性指标)作为主要评估标准。
6. 模型优缺点评价
优点:
- 检测精度高: 项目使用了YOLOv8模型,采用CSPNet和FPN/PAN等多尺度特征融合架构,能够在保持计算效率的同时提升目标检测的精度,适用于复杂背景和多目标场景。
- 实时性强: YOLOv8凭借轻量化的模型设计和高效的计算架构,能够在高帧率的情况下实现实时目标检测与跟踪,适合自动驾驶、无人机监控等场景应用。
- 多目标跟踪: 结合DeepSORT算法,项目实现了复杂场景下的多目标稳定跟踪。DeepSORT的卡尔曼滤波和外观信息匹配策略能够有效处理目标在场景中的遮挡、消失和重新出现问题。
- 灵活性与扩展性: 该项目支持自定义数据集训练、迁移学习以及超参数调节,可根据不同的应用场景进行模型的微调与优化。
缺点:
- 对小目标检测效果有限: 尽管模型使用了多尺度特征融合,但在目标过小或背景复杂时,检测效果仍可能不够理想,容易出现漏检或误检。
- 跟踪中ID切换问题: 在目标外观相似或快速运动的情况下,DeepSORT在ID分配上存在误差,导致跟踪ID切换和漂移现象。
- 计算资源需求较高: YOLOv8相较于YOLOv5虽然提升了检测精度,但模型复杂度较高,对计算资源(尤其是GPU内存)有较大要求,不适合在资源受限的设备上部署。
可能的改进方向:
- 模型结构优化: 引入Transformer模块替换部分卷积层,提升模型对长距离依赖关系的建模能力,从而改善小目标检测效果。
- 超参数调整: 针对不同场景,优化Anchor Box尺寸、学习率、权重衰减等超参数,以获得更好的收敛效果和精度表现。
- 数据增强策略: 增加更丰富的数据增强方法,如Mosaic、CutMix、MixUp等,提升模型对不同场景的适应性。
- 多目标跟踪策略改进: 引入更复杂的外观特征(如ReID)和时序建模方法(如LSTM或RNN),提升跟踪稳定性,减少ID切换现象。
↓↓↓更多热门推荐:
SE-Net模型实现猴痘病识别
基于深度学习的手势控制模型
全部项目数据集、代码、教程进入官网zzgcz.com
![HTB:Funnel[WriteUP]](https://i-blog.csdnimg.cn/direct/5fccefa72f6e40648705eb54d581e560.png)