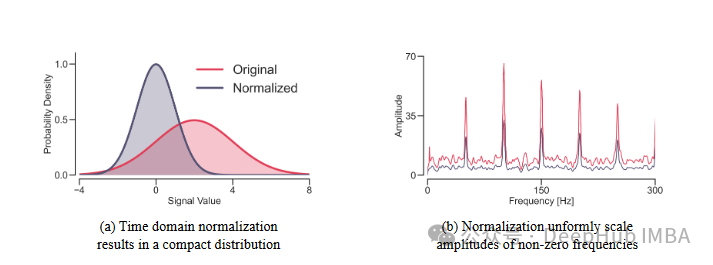
时间序列预测是一个具有挑战性的任务,尤其是在处理非平稳数据时。现有的基于正则化的方法虽然在解决分布偏移问题上取得了一定成功但仍存在局限性。这些方法主要在时间域进行操作,可能无法充分捕捉在频域中更明显的动态模式,从而导致次优的结果。
FredNormer论文的研究目的主要包括:
- 理论分析现有正则化方法如何影响频率分量,并证明它们在处理非零频率时的局限性。
- 提出一种新的频域正则化方法,能够自适应地增强关键频率分量的权重。
- 设计一种即插即用的模块,可以轻松集成到各种预测模型中,而不影响效率。
方法改进
FredNormer的核心思想是从频率角度观察数据集,并自适应地增加关键频率分量的权重。

该方法主要包含两个关键组件:
1、频率稳定性度量
FredNormer首先定义了一个频率稳定性度量,用于量化每个频率分量在训练集中的统计显著性:
S(k) =μ(A(k)) /σ(A(k))
其中,μ(A(k))和σ(A(k))分别表示第k个频率分量幅度的均值和标准差。这个度量具有以下特点:
- 捕捉了每个频率分量在整个训练集中的分布情况
- 无量纲,允许公平比较不同频率分量
- 避免了均匀频率缩放的问题
2、频率稳定性加权层
这一层的主要功能是根据稳定性动态调整频率分量的权重。具体步骤如下:
对输入时间序列数据进行差分和离散傅里叶变换(DFT)
将DFT系数分解为实部和虚部
应用两个线性投影到频率稳定性度量S上:
F'r = Fr ⊙ (S × Wr + Br)
F'i = Fi ⊙ (S × Wi + Bi)
将加权后的频谱通过逆DFT变换回时间域
这种设计允许模型分别处理实部和虚部,从而捕捉更丰富的时间动态。
3、代码实现
我们这里根据论文中的描述实现一个FredNormer的基本版本。这个实现可能不包含所有的优化和细节,但它应该能够展示FredNormer的核心概念。
导入必要的库并定义FredNormer类:
importnumpyasnp
importtorch
importtorch.nnasnn
importtorch.fftasfft
classFredNormer(nn.Module):
def__init__(self, num_channels, seq_length):
super(FredNormer, self).__init__()
self.num_channels=num_channels
self.seq_length=seq_length
self.freq_length=seq_length//2+1
# 定义可学习的权重和偏置
self.W_r=nn.Parameter(torch.randn(self.freq_length, num_channels))
self.B_r=nn.Parameter(torch.zeros(self.freq_length, num_channels))
self.W_i=nn.Parameter(torch.randn(self.freq_length, num_channels))
self.B_i=nn.Parameter(torch.zeros(self.freq_length, num_channels))
defcompute_stability(self, x):
# 计算频率稳定性度量
fft_x=fft.rfft(x, dim=1)
amplitude=torch.abs(fft_x)
mean=torch.mean(amplitude, dim=0)
std=torch.std(amplitude, dim=0)
stability=mean/ (std+1e-5) # 添加小值以避免除零
returnstability
defforward(self, x):
# 应用一阶差分
x_diff=torch.diff(x, dim=1, prepend=x[:, :1])
# 计算FFT
fft_x=fft.rfft(x_diff, dim=1)
# 计算稳定性度量
stability=self.compute_stability(x)
# 分离实部和虚部
real=fft_x.real
imag=fft_x.imag
# 应用频率稳定性加权
real=real* (stability*self.W_r+self.B_r)
imag=imag* (stability*self.W_i+self.B_i)
# 重构复数FFT
fft_weighted=torch.complex(real, imag)
# 应用逆FFT
x_normalized=fft.irfft(fft_weighted, n=self.seq_length, dim=1)
returnx_normalized
# 使用示例
seq_length=96
num_channels=7
batch_size=32
# 创建一个随机输入张量
x=torch.randn(batch_size, seq_length, num_channels)
# 初始化FredNormer
frednormer=FredNormer(num_channels, seq_length)
# 应用FredNormer
x_normalized=frednormer(x)
print(f"Input shape: {x.shape}")
print(f"Output shape: {x_normalized.shape}")
这个实现包含了FredNormer的主要组件:
compute_stability: 计算频率稳定性度量。
forward: 实现了FredNormer的前向传播,包括:
- 应用一阶差分
- 计算FFT
- 计算稳定性度量
- 应用频率稳定性加权
- 应用逆FFT
要将FredNormer集成到完整的预测模型中,可以这样做:
classTimeSeriesModel(nn.Module):
def__init__(self, input_dim, hidden_dim, output_dim, seq_length):
super(TimeSeriesModel, self).__init__()
self.frednormer=FredNormer(input_dim, seq_length)
self.lstm=nn.LSTM(input_dim, hidden_dim, batch_first=True)
self.fc=nn.Linear(hidden_dim, output_dim)
defforward(self, x):
x=self.frednormer(x)
lstm_out, _=self.lstm(x)
returnself.fc(lstm_out[:, -1, :])
# 使用示例
input_dim=7
hidden_dim=64
output_dim=1
seq_length=96
batch_size=32
model=TimeSeriesModel(input_dim, hidden_dim, output_dim, seq_length)
x=torch.randn(batch_size, seq_length, input_dim)
output=model(x)
print(f"Input shape: {x.shape}")
print(f"Output shape: {output.shape}")
我们上面的代码将FredNormer作为预处理步骤集成到一个基于LSTM的时间序列预测模型中。
这个实现是基于论文的描述,可能需要进一步的调整和优化以达到论文中报告的性能。另外在实际应用中可能还需要添加训练循环、损失函数、优化器等组件。
实验设置与结果
研究者使用了7个公共时间序列数据集进行实验,包括Weather、ETT系列(ETTh1, ETTh2, ETTm1, ETTm2)、Electricity和Traffic。这些数据集涵盖了不同的时间粒度和应用场景。
基线模型与骨干网络
FredNormer与两个主要的基线方法进行了比较:
- RevIN: 一种广泛使用的基本正则化模块
- SAN: 当前最先进的正则化方法
实验中使用了三种不同的预测模型作为骨干网络:
- DLinear: 一种基于MLP的轻量级模型
- PatchTST: 一种基于Transformer的模型,使用补丁操作捕捉局部时间模式
- iTransformer: 另一种Transformer模型,强调通道间的注意力机制
实验结果
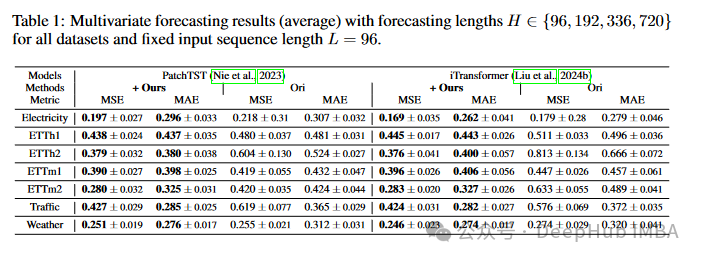
整体性能:
- FredNormer在所有数据集上都显著改善了骨干模型的性能
- 在具有复杂频率特征的数据集(如ETTm2)上,FredNormer将PatchTST和iTransformer的性能分别提高了33.3%和55.3%
与基线方法的比较:
- 在28个设置中,FredNormer取得了18个第一名和6个第二名的结果
- 在ETTh1数据集上,FredNormer将DLinear和iTransformer的MSE值分别降低到0.407和0.445,优于RevIN(0.460和0.463)和SAN(0.421和0.466)
运行时间:
- FredNormer在计算时间上始终优于SAN
- 在28个设置中的16个中,FredNormer实现了60%到70%的速度提升
消融研究
研究者还进行了消融研究,将频率稳定性度量替换为两种替代滤波器:低通滤波器和随机频率选择。结果显示,FredNormer的频率稳定性分数始终实现了最佳准确性,证明了从频谱中提取稳定特征有助于模型学习一致的模式。
可视化分析
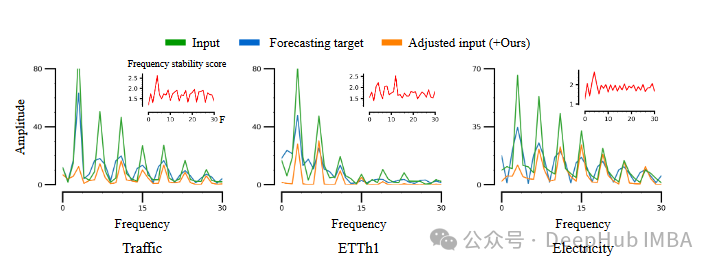
在Traffic、ETTh1和ETTh2数据集上应用FredNormer前后的输入序列可视化
如上图所示,绿线表示输入数据,蓝线表示预测目标,橙线表示FredNormer生成的输入数据,红线表示每个数据集的频率稳定性度量。这个分析展示了:
- FredNormer能够自适应地为不同数据集分配权重
- 该方法能够识别并增强在输入序列和预测目标中都出现显著波动的分量
- 即使某些频率分量的幅度较低,只要它们表现出一致性,FredNormer也会为其分配较高的权重
总结
FredNormer通过在频域中处理非平稳性,为时间序列预测提供了一种新的视角。它不仅在理论上分析了现有方法的局限性,还提出了一种简单而有效的解决方案。实验结果表明,FredNormer在多个数据集和预测模型上都取得了显著的性能提升,同时保持了较低的计算开销。这种方法为处理复杂的非平稳时间序列数据提供了一个强大而灵活的工具。
论文地址:
https://avoid.overfit.cn/post/85db3d9e923c4562a6206f1c9b38d120