Python脚本全程自动,全部Python内建工具脚本纯净。
(笔记模板由python脚本于2024年10月05日 19:51:06创建,本篇笔记适合喜欢Excel和Python的coder翻阅)
-
Python 官网:https://www.python.org/
-
Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单……
地址:https://lqpybook.readthedocs.io/
自学并不是什么神秘的东西,一个人一辈子自学的时间总是比在学校学习的时间长,没有老师的时候总是比有老师的时候多。
—— 华罗庚
- My CSDN主页、My HOT博、My Python 学习个人备忘录
- 好文力荐、 老齐教室

本文质量分:
本文地址: https://blog.csdn.net/m0_57158496/article/details/142718181
CSDN质量分查询入口:http://www.csdn.net/qc
- ◆ 分享“Excel 表格”关键字博客
- 1、目录、文件
- 2、程序说明
- 3、代码导读
- 4、完整源码(Python)
效果链接: 我关于Excel使用点滴的笔记 https://blog.csdn.net/m0_57158496/article/details/140040251
◆ 分享“Excel 表格”关键字博客
1、目录、文件
输出文件及目录
发文数据样式
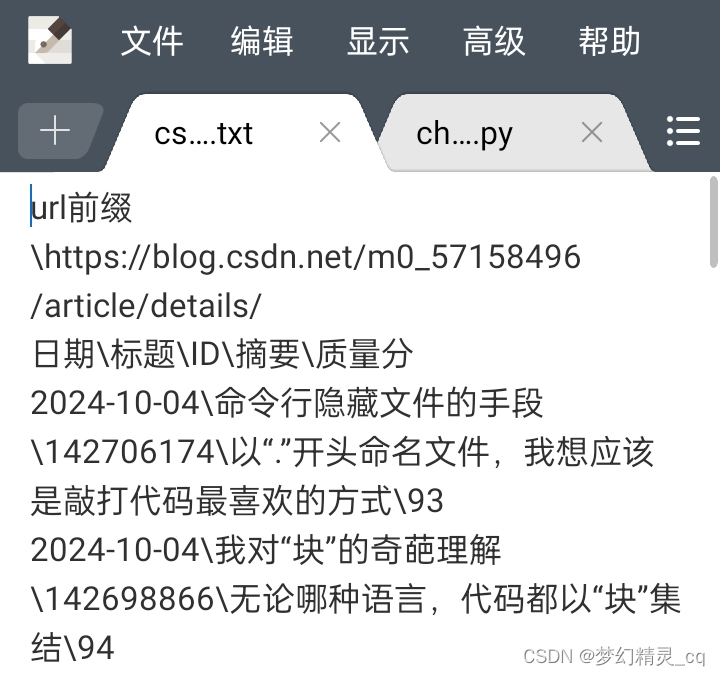
-
发文数据文件
-
head、tail

-
脚本和模板

-
模板文本

-
我的热博
2、程序说明
程序名称: “Excel 表格”关键字的博客笔记自动分享工具
关键字处理说明:
-
关键字筛选: 程序中的关键字是预定义的,并非从博客内容中提取。关键字是"Excel 表格",程序会根据这个关键字筛选出包含该关键字的博客笔记发布数据。
-
收集博文ID: 程序会遍历指定年份的博客笔记发布数据文件(例如
csdn_2021_publishFootprint.txt),查找每行数据中是否包含预定义的关键字。如果包含,则收集该行的博文ID。 -
数据提取: 对于每篇包含关键字的博文,程序会进一步提取其ID,以及其他相关的信息,如标题、摘要、发布日期等。
-
统计与排序: 程序会根据收集到的博文ID,通过网络请求获取每篇博文的阅读量等数据,并对这些数据进行统计和排序,以便生成按阅读量降序排列的列表。
以下是关键字处理部分的代码示例:
def get_key_ids():
''' 获取博文id总列表 '''
#from time import localtime # 确保方法已载入
keys = 'Excel 表格'
text_id = []
for year in range(2021, localtime().tm_year+1): # 循环读取博文笔记id。
with open(f"{my_datapath}csdn_{year}_publishFootprint.txt") as f:
text_id.extend(f.read().split('\n')[2:]) # 去除前两行数据。
ids = [] # 要查找的博文笔记id列表初值
for key in keys.split():
ids.extend([(i.split('\\')[2], i.split('\\')[-2]) for i in text_id if key in i]) # 追加通过关键字找到的id
ids = set(ids) # 集合去重
print(f"\n{f' 已收集到{len(ids)}条博文笔记id ':.^33}\n")
return ids
在这段代码中,keys.split()将预定义的关键字拆分成单词列表,然后程序会检查每行数据是否包含这些关键字中的任何一个。如果包含,就将该行的博文ID和相关数据添加到列表中。这样,最终得到的ids列表就包含了所有包含关键字的博文ID及其相关信息。
3、代码导读
本指南旨在帮助读者理解一个自动化Python脚本的工作原理,该脚本专注于处理CSDN博客中的特定内容,并将其以有序的方式展示出来。
脚本目的:
- 提取CSDN博客中包含“Excel 表格”关键字的博文。
- 根据博文的阅读量进行降序排序。
- 生成一个HTML文件,其中包含了按阅读量排序的博文链接。
脚本概述:
- 模块导入:
time模块:用于生成时间戳和格式化日期时间。urllib.request:用于发送网络请求获取数据。re:用于通过正则表达式解析数据。traceback:用于异常追踪和错误报告。
-
主要功能模块:
a、时间处理:time_stamp():生成唯一的时间戳,用于输出文件的命名。my_strftime():自定义日期时间格式化,提升输出文件的可读性。(可选功能,增加用户体验)
b、程序执行提示:tip_runing():显示程序正在运行的提示信息。
c、数据提取与处理:- 从CSDN博客获取数据,并使用正则表达式提取所需信息。
get_ids():读取并筛选出包含关键字的博文ID列表。
d、排序与输出:read_sort():根据阅读量对博文进行排序。str_url():构建博文的URL超链接,并通过颜色标识不同阅读量区间。write_choice_key():将排序后的博文信息写入HTML文件。
e、主逻辑:main():串联整个程序的执行流程,包括时间戳生成、数据读取、排序和HTML文件写入。- 异常处理:捕获并记录程序运行中可能出现的错误。
f、异常处理:- 使用
try-except结构来管理异常,确保程序的健壮性。
g、程序入口:- 确保脚本直接运行时,
main()函数会被调用。
-
使用说明:
- 确认数据文件路径
my_datapath和URL前缀my_urlroot的正确性。 - 确保网络连接稳定,以便脚本能够正常执行。
- 根据CSDN页面结构的变化,适时更新正则表达式。
- 确认数据文件路径
4、完整源码(Python)
(源码较长,点此跳过源码)
#!/sur/bin/nve python
# coding: utf-8
from time import time
from time import strftime
from time import localtime
import urllib.request
from re import findall
import traceback
my_datapath = '/sdcard/Documents/csdn/' # 数据路径。
my_urlroot = 'https://blog.csdn.net/m0_57158496/article/details/' # 笔记id前缀。
time_stamp = lambda: ''.join([f"{i:0>2}" for i in localtime()[2:6]]) # 时间戳(日时分秒)。
my_strftime = lambda: strftime('%Y年%m月%d日 %H:%M:%S', localtime())
def tip_runing():
''' “程序正在运算……”提示函数 '''
#from time import time # 请在调用脚本开始前加载time.time
k = int(str(time())[-2:])%26
print(' '*40, end='\r')
print(f"{' '*k}{'程序正在运算……'}", end='\r')
def get_key_ids():
''' 获取博文id总列表 '''
#from time import localtime # 确保方法已载入
keys = 'Excel 表格'
text_id = []
for year in range(2021, localtime().tm_year+1): # 循环读取博文笔记id。
with open(f"{my_datapath}csdn_{year}_publishFootprint.txt") as f:
text_id.extend(f.read().split('\n')[2:]) # 去除前两行数据。
ids = [] # 要查找的博文笔记id列表初值
for key in keys.split():
ids.extend([(i.split('\\')[2], i.split('\\')[-2]) for i in text_id if key in i]) # 追加通过关键字找到的id
ids = set(ids) # 集合去重
print(f"\n{f' 已收集到{len(ids)}条博文笔记id ':.^33}\n")
return ids
def get_readed(blog_id: str) -> zip:
''' 获取博文阅读量等数据 '''
with urllib.request.urlopen(f"{my_urlroot}{blog_id}") as reponse:
html_doc = reponse.read().decode('utf-8').split('<li class="tool-item tool-item-bar">')[0] # urlparse模块方法拉取页面超文本,并截取数据文本,加快数据提取速度。
fields = '浏览阅读', '标题', 'ID', '作者', '点赞', '收藏', '评论', '摘要', '首次发布', '最后编辑'
author = findall(r'<span class="profile-name">\s*(.+)\s*</span>', html_doc) # 摘取作者。
author = ''.join(author)
article_title = findall(r'var articleTitle = "(.+)";', html_doc) # 摘取文章标题。
article_title = ''.join(article_title)
abstract = findall(r'var articleDesc = "(.*)";', html_doc) # 提取摘要。
abstract = ''.join(abstract)
for i in ['!', '……', ' '*2]:
abstract = abstract.replace(i, i+'。') # 句末符号不为“。”+“。”,方便以“。”分割数据。
abstract = abstract.split('。')[:2] # 以“。”分割并截取前两个字符串。
abstract = abstract[-1] if abstract[-1] else ''.join(abstract) # 摘取有效摘要字符串。
readed = findall(r'<span class="read-count">阅读量([\d.kw]*)</span>', html_doc) # 提取阅读量。
readed = ''.join(readed)
thumbs_up = findall(r'<span class="read-count" id="blog-digg-num">点赞数\s*([\d.kw]*)\s*</span>', html_doc) # 提取点赞数。
thumbs_up = ''.join(thumbs_up)
collect = findall(r'<span class="count get-collection " data-num="[\d\.wk]*" id="get-collection">\s*([\d\.wk]*)\s*</span>\s*</a>\s*<div class="tool-hover-tip collect">\s*<div class="collect-operate-box">\s*<span class="collect-text" id="is-collection">\s*收藏\s*</span>', html_doc) # 提取收藏数。
collect = ''.join(collect)
readed = readed if readed else '0'
readed = round(float(readed[:-1])*1000, 0) if readed[-1] == 'k' else round(float(readed[:-1])*10000, 0) if readed[-1] == 'w' else round(readed, 0) # 三元操作语句嵌套还原阅读量为整型。
comment = findall(r'<span class="count">\n\s*([\d\.kw]*)\n\s*</span>\n\s*</a>\n\s*<div class="tool-hover-tip"><span class="text space">评论</span></div>', html_doc) # 提取评论。
comment = ''.join(comment)
first_edit_time = ''.join(findall(r'<div class="up-time"><span>于 ([\d\s\-:]+) 首次发布</span></div>', html_doc))
reedit_time = ''.join(findall(r'<span class="time">已于 ([\s\d\-:]+) 修改</span>', html_doc))
datas = readed, article_title, blog_id, author, thumbs_up, collect, comment, abstract, first_edit_time, reedit_time
return zip(fields, datas)
def read_sort():
''' 阅读量排序列表 '''
start = time()
ids = get_key_ids()
readeds = []
print('\n') # 打印空行。
for i in ids:
tip_runing()
article_info = get_readed(i[0])
article_info = {k: v for k,v in article_info if v and v!= '0'} # 剔除零值数据项,生成博文笔记浏览阅读等信息字典。
if not article_info: # 浏览阅读数据为空,跳过本次遍历。
continue
for i in ('\u2003', '"', '??????', '我的HOT博', '&msp' ' ', 'python 3.6.6', 'coding:'): # 遍历删除无意义文章摘要。
if i in article_info.get('摘要', ''):
del article_info['摘要']
break
elif len(article_info.get('摘要', '')) >= len(article_info.get('标题', '')):
if article_info.get('摘要'):
del article_info['摘要'] # 摘要不比标题标题长,删除摘要。
break
if article_info.get('作者'):
del article_info['作者'] # 作者都是我自己,删除。
readeds += [article_info]
readeds.sort(reverse=True, key=lambda x: x.get('浏览阅读', 0)) # 按浏览阅读排降序。
#print('\n\n'.join(map(str, readeds))) # 终端屏幕打印。
S = time() - start
S = f"{S//60:.0f}分{S%60:.1f}秒" if S > 60 else f"{S%60:.1f}秒"
return readeds, f"本次共计收集{len(readeds)}篇博文笔记信息,总阅读量{sum([i.get('浏览阅读', 0) for i in readeds])/10000:.2f}w。数据采集于{my_strftime()},用时{S}。"
def str_url(article_info):
''' 格式化文章阅读量信息 '''
d = article_info
readed = d.get('浏览阅读', 0)
if not readed:
url = f"{myUrlRoot}{d.get('ID', '')}"
print(f"\n{url}")
if readed >= 10000:
color = 'gold'
size = 5
elif 8000 <= readed < 10000:
color = 'purple'
size = 4
elif 6000 <= readed < 8000:
color = 'scarlet'
size = 4
elif 5000 <= readed < 6000:
color = 'red'
size = 3
elif 4000 <= readed < 5000:
color = 'orange'
size = 3
elif 2000 <= readed < 4000:
color = 'green'
size = 3
elif 1000 <= readed < 2000:
color = 'cyan'
size = 3
elif 500 <= readed < 1000:
color = 'blue'
size = 3
elif 100 <= readed < 500:
color = 'black'
size = 2
else:
color = 'gray'
size = 2
readed = f"{readed/10000}w" if readed >= 10000 else f"{readed/1000}k" if 1000 <= readed < 10000 else readed # 格式化千万浏览阅读量数值。
url = f"{my_urlroot}{d.get('ID')}"
thumbs_up = f"点赞:{d.get('点赞')} " if d.get('点赞') else ''
collect = f"收藏:{d.get('收藏')} " if d.get('收藏') else ''
comment = f"评论:{d.get('评论')}" if d.get('评论') else ''
thumbs_ups = f"\n<br>{''.join([thumbs_up, collect, comment])}" if thumbs_up or collect or comment else ''
abstract = f"\n<br>摘要:{d.get('摘要')}。" if d.get('摘要') else ''
edit_time = f"\n<br>(本篇笔记于{d.get('首次发布')}首次发布,最后修改于{d.get('最后编辑')})" if d.get('首次发布') else ''
return f"<a href='{url}' target=_blank>{d.get('标题')}</a>\n<br>地址:<a href='{url}' target=_blank>{url}</a>\n<br>浏览阅读:<font color='{color}' size={size}>{readed}</font>{thumbs_ups}<font color='gray' size=2>{abstract}{edit_time}</font>\n<br> "
def write_choice_key(key_readeds, filename):
''' 写“关键字”博文链接 '''
key_readeds = '\n'.join([f"<li>\n{str_url(i)}\n</li>" for i in key_readeds[0]]) # 排版记录索引数据
key_readeds = f"\n\n  {key_readeds[1]}\n\n<table><ol>\n{key_readeds}\n</ol></table>\n" # 格式化数据索引列表
with open(f'{my_datapath}csdn_blogHead.txt', encoding='utf-8') as f:
head = f.read() # 读取“固定”头部
with open(f'{my_datapath}csdn_myHotBlog.txt', encoding='utf-8') as f:
hot_blog = f.read() # 读取“我的热博”
with open(f'{my_datapath}excel-blog-templet.fstr', encoding='utf-8') as f:
f.readline() # 丢弃注释行
templet = f.read() # 读取“Excel点滴”博文模板
with open(f'{my_datapath}csdn_blogTail.txt', encoding='utf-8') as f:
tail = f.read() # 读取“固定”尾部
templet = templet.format(head=head, excel_blog_list=key_readeds, hot_blog=hot_blog, tail=tail) # 组合模板
with open(filename, 'w') as f:
f.write(templet) # 全文写入
def main():
''' 我的csdn博文被阅读量排序主函数 '''
print(f"\n{f' {my_strftime()} ':~^39}\n")
readeds = read_sort()
print(readeds[1])
filename = f"/sdcard/Documents/csdn/temp/csdn{time_stamp()}choiceKey.txt"
try:
write_choice_key(readeds, filename)
print(f"\n{f' ChoiceKey文本{filename}已保存。 ':~^24}\n")
except Exception as error:
print(f"\n错误类型:\n{error}\n")
traceback.print_exc()
print(f"\n{f' {my_strftime()} ':~^39}\n")
if __name__ == '__main__':
main() # 主程序调用。
上一篇: 命令行隐藏文件的手段(以“.”开头命名文件,我想应该是敲打代码最喜欢的方式)
下一篇:
我的HOT博:
本次共计收集 311 篇博文笔记信息,总阅读量43.82w。数据于2024年03月22日 00:50:22完成采集,用时6分2.71秒。阅读量不小于6.00k的有
7
7
7篇。
-
001
标题:让QQ群昵称色变的神奇代码
(浏览阅读 5.9w )
地址:https://blog.csdn.net/m0_57158496/article/details/122566500
点赞:25 收藏:86 评论:17
摘要:让QQ昵称色变的神奇代码。
首发:2022-01-18 19:15:08
最后编辑:2022-01-20 07:56:47 -
002
标题:Python列表(list)反序(降序)的7种实现方式
(浏览阅读 1.1w )
地址:https://blog.csdn.net/m0_57158496/article/details/128271700
点赞:8 收藏:35 评论:8
摘要:Python列表(list)反序(降序)的实现方式:原址反序,list.reverse()、list.sort();遍历,全数组遍历、1/2数组遍历;新生成列表,resersed()、sorted()、负步长切片[::-1]。
首发:2022-12-11 23:54:15
最后编辑:2023-03-20 18:13:55 -
003
标题:pandas 数据类型之 DataFrame
(浏览阅读 9.7k )
地址:https://blog.csdn.net/m0_57158496/article/details/124525814
点赞:7 收藏:36
摘要:pandas 数据类型之 DataFrame_panda dataframe。
首发:2022-05-01 13:20:17
最后编辑:2022-05-08 08:46:13 -
004
标题:个人信息提取(字符串)
(浏览阅读 8.2k )
地址:https://blog.csdn.net/m0_57158496/article/details/124244618
点赞:2 收藏:15
摘要:个人信息提取(字符串)_个人信息提取python。
首发:2022-04-18 11:07:12
最后编辑:2022-04-20 13:17:54 -
005
标题:Python字符串居中显示
(浏览阅读 7.6k )
地址:https://blog.csdn.net/m0_57158496/article/details/122163023
评论:1 -
006
标题:罗马数字转换器|罗马数字生成器
(浏览阅读 7.5k )
地址:https://blog.csdn.net/m0_57158496/article/details/122592047
摘要:罗马数字转换器|生成器。
首发:2022-01-19 23:26:42
最后编辑:2022-01-21 18:37:46 -
007
标题:回车符、换行符和回车换行符
(浏览阅读 6.0k )
地址:https://blog.csdn.net/m0_57158496/article/details/123109488
点赞:2 收藏:3
摘要:回车符、换行符和回车换行符_命令行回车符。
首发:2022-02-24 13:10:02
最后编辑:2022-02-25 20:07:40
截屏图片

(此文涉及ChatPT,曾被csdn多次下架,前几日又因新发笔记被误杀而落马。躺“未过审”还不如回收站,回收站还不如永久不见。😪值此年底清扫,果断移除。留此截图,以识“曾经”。2023-12-31)

精品文章:
- 好文力荐:齐伟书稿 《python 完全自学教程》 Free连载(已完稿并集结成书,还有PDF版本百度网盘永久分享,点击跳转免费🆓下载。)
- OPP三大特性:封装中的property
- 通过内置对象理解python'
- 正则表达式
- python中“*”的作用
- Python 完全自学手册
- 海象运算符
- Python中的 `!=`与`is not`不同
- 学习编程的正确方法
来源:老齐教室
◆ Python 入门指南【Python 3.6.3】
好文力荐:
- 全栈领域优质创作者——[寒佬](还是国内某高校学生)博文“非技术文—关于英语和如何正确的提问”,“英语”和“会提问”是编程学习的两大利器。
- 【8大编程语言的适用领域】先别着急选语言学编程,先看它们能干嘛
- 靠谱程序员的好习惯
- 大佬帅地的优质好文“函数功能、结束条件、函数等价式”三大要素让您认清递归
CSDN实用技巧博文:
- 8个好用到爆的Python实用技巧
- python忽略警告
- Python代码编写规范
- Python的docstring规范(说明文档的规范写法)