文章目录
- 从现实中的例子理解什么是梯度
- 梯度的数学定义
- 梯度的严格的数学定义
- 为什么梯度向量指向函数增长最快的方向?
- 为什么梯度是深度学习优化的最基础概念
- 在python中实现梯度求导的简单案例
- 一元线性回归
- 多元线性回归
- 结合示例深度学习中的梯度求导的一般过程
- 数学原理推导
- 对应到代码中的梯度计算
- 个人公众号
从现实中的例子理解什么是梯度
想象你在一座被浓雾笼罩的山上,想找到山谷的最低点。但由于能见度低,你无法看到全貌,只能感觉到脚下的坡度。这种坡度感告诉你哪个方向是向下的,哪边更陡峭。这个“坡度”就是梯度的直观表现,它指示了函数在当前点变化最快的方向和速率。此时,真想吟诗一首:
雾锁高山觅谷深,
脚踏迷途辨缓峻。
坡度指引下山路,
梯度犹似暗中灯。
梯度的数学定义
梯度的严格的数学定义
在多元微积分中,梯度(Gradient)是标量函数在某一点的方向导数取得最大值的方向。具体来说,对于一个实值的可微函数
f
(
x
1
,
x
2
,
.
.
.
,
x
n
)
f(x_1, x_2, ..., x_n)
f(x1,x2,...,xn),其梯度是由函数对各个变量的偏导数组成的向量:
∇
f
=
(
∂
f
∂
x
1
,
∂
f
∂
x
2
,
.
.
.
,
∂
f
∂
x
n
)
\nabla f = \left( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n} \right)
∇f=(∂x1∂f,∂x2∂f,...,∂xn∂f)
为什么梯度向量指向函数增长最快的方向?
首先,我们需要引入方向导数的概念。方向导数描述了函数在某个特定方向上的变化率。对于单位向量 u \mathbf{u} u,函数 f f f在点 x \mathbf{x} x沿方向 u \mathbf{u} u的方向导数定义为:
D u f ( x ) = ∇ f ( x ) ⋅ u = ∥ ∇ f ( x ) ∥ ⋅ ∥ u ∥ cos θ = ∥ ∇ f ( x ) ∥ cos θ D_{\mathbf{u}} f(\mathbf{x}) = \nabla f(\mathbf{x}) \cdot \mathbf{u} = \| \nabla f(\mathbf{x}) \| \cdot \| \mathbf{u} \| \cos \theta = \| \nabla f(\mathbf{x}) \| \cos \theta Duf(x)=∇f(x)⋅u=∥∇f(x)∥⋅∥u∥cosθ=∥∇f(x)∥cosθ
其中, θ \theta θ是 ∇ f ( x ) \nabla f(\mathbf{x}) ∇f(x)与 u \mathbf{u} u之间的夹角, ∥ ⋅ ∥ \| \cdot \| ∥⋅∥表示向量的模。
从上式可以看出,方向导数 D u f ( x ) D_{\mathbf{u}} f(\mathbf{x}) Duf(x)的值取决于 cos θ \cos \theta cosθ。当 θ = 0 \theta = 0 θ=0时, cos θ \cos \theta cosθ取得最大值1,此时方向导数也达到最大值,即:
D u f ( x ) max = ∥ ∇ f ( x ) ∥ D_{\mathbf{u}} f(\mathbf{x})_{\text{max}} = \| \nabla f(\mathbf{x}) \| Duf(x)max=∥∇f(x)∥
这意味着,函数 f f f在点 x \mathbf{x} x沿着梯度方向 ∇ f ( x ) \nabla f(\mathbf{x}) ∇f(x),具有最大的增长率。
为什么梯度是深度学习优化的最基础概念
梯度在深度学习中扮演着核心角色,几乎贯穿了整个模型训练和优化的过程。要理解梯度为何如此重要,需要从深度学习模型的构建、训练以及优化方法等多个角度来探讨。
1. 深度学习的目标:最小化损失函数
深度学习的核心目标是通过调整模型参数,使得模型在给定数据集上的损失函数达到最小值。损失函数(Loss Function)衡量了模型预测输出与真实标签之间的差距,是一个关于模型参数的多元函数。优化损失函数的过程本质上是一个在高维参数空间中寻找全局或局部最小值的问题。
2. 梯度提供了最陡下降的方向
在高维参数空间中,直接找到损失函数的最小值是极其困难的。然而,梯度为我们提供了一条捷径。梯度向量指示了损失函数在当前参数点处增长最快的方向。根据梯度的性质,沿着梯度的反方向,即是函数下降最快的路径。因此,梯度为我们提供了在参数空间中如何调整参数以最快速地降低损失函数值的指导。
3. 梯度下降法是深度学习的基础优化算法
梯度下降法(Gradient Descent)利用了梯度信息,通过迭代更新模型参数,使得每一步都朝着损失函数减小的方向前进。其基本更新公式为:
θ n e w = θ o l d − η ∇ θ L ( θ o l d ) \theta_{new} = \theta_{old} - \eta \nabla_{\theta} L(\theta_{old}) θnew=θold−η∇θL(θold)
其中, θ \theta θ表示模型参数, η \eta η是学习率, L ( θ ) L(\theta) L(θ)是损失函数, ∇ θ L ( θ ) \nabla_{\theta} L(\theta) ∇θL(θ)是损失函数对参数的梯度。
4. 反向传播算法依赖梯度计算
反向传播(Backpropagation)是训练神经网络的关键算法,用于高效地计算损失函数对每个参数的梯度。通过链式法则,反向传播将输出层的误差逐层传递回前面的网络层,计算出每个参数对损失的影响。这个过程的核心就是梯度的计算和传递,没有梯度,反向传播无法进行。
在python中实现梯度求导的简单案例
一元线性回归
下面示例展示了普通线性一元回归的梯度求导以及反向误差传播,并动态可视化其结果:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
# 生成数据集
np.random.seed(0)
X = np.linspace(0, 10, 50)
y = 2 * X + 1 + np.random.randn(50) * 4 # 增加噪声强度
# 参数初始化
w, b = -10.0, -10.0 # 将初始参数设置为远离最优值
lr = 0.02 # 学习率
epochs = 300 # 训练次数
# 存储参数和损失以便绘图
ws, bs = [], []
losses = []
# 创建图形
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))
scatter = ax1.scatter(X, y, color='blue', label='data scatter')
line, = ax1.plot([], [], 'r-', linewidth=2, label='fitted curve')
text_loss = ax1.text(0.05, 0.85, '', transform=ax1.transAxes, fontsize=12, verticalalignment='top')
ax1.set_xlabel('X')
ax1.set_ylabel('y')
ax1.set_title('simple Linear Regression')
ax1.legend()
ax2.set_xlim(0, epochs)
ax2.set_ylim(0, max((y - y.mean()) ** 2) * 1.2)
loss_line, = ax2.plot([], [], 'b-')
ax2.set_xlabel('epoch')
ax2.set_ylabel('loss')
ax2.set_title('loss curve')
def animate(i):
global w, b
y_pred = w * X + b
loss = ((y_pred - y) ** 2).mean()
# 计算梯度
grad_w = 2 * ((y_pred - y) * X).mean()
grad_b = 2 * (y_pred - y).mean()
# 更新参数
w -= lr * grad_w
b -= lr * grad_b
# 记录参数和损失
ws.append(w)
bs.append(b)
losses.append(loss)
# 更新拟合直线
line.set_data(X, w * X + b)
# 更新损失曲线
loss_line.set_data(range(len(losses)), losses)
# 更新损失文本
text_loss.set_text(f'epoch: {i + 1}\ncurrent loss: {loss:.2f}')
return line, loss_line, text_loss
# 初始化函数
def init():
line.set_data([], [])
loss_line.set_data([], [])
text_loss.set_text('')
return line, loss_line, text_loss
# 创建动画
ani = FuncAnimation(fig, animate, frames=epochs, init_func=init, interval=100, blit=True)
# 保存动画为 GIF 文件
ani.save('linear_regression_animation.gif', writer='pillow', fps=30)
plt.tight_layout()
plt.show()

多元线性回归
import numpy as np
import matplotlib.pyplot as plt
# 1. 生成数据集
np.random.seed(42) # 设置随机种子以保证结果可重复
# 样本数量和特征数量
n_samples = 100
n_features = 5
# 生成随机特征矩阵 X,形状为 (100, 5)
X = np.random.randn(n_samples, n_features)
# 真实的权重和偏置,用于生成目标值 y
true_w = np.array([2, -3, 4, 1, -2])
true_b = 5
# 生成目标值 y,并添加一些噪声
y = X.dot(true_w) + true_b + np.random.randn(n_samples) * 0.5 # 噪声的标准差为 0.5
# 2. 参数初始化
w = np.zeros(n_features) # 初始化权重为零向量
b = 0.0 # 初始化偏置为 0
lr = 0.01 # 学习率
epochs = 300 # 训练轮数
# 存储损失值以便绘图
losses = []
# 3. 训练过程
for epoch in range(epochs):
# 前向传播:计算预测值
y_pred = X.dot(w) + b
# 计算损失(均方误差)
loss = ((y_pred - y) ** 2).mean()
losses.append(loss)
# 计算梯度
grad_w = 2 * X.T.dot(y_pred - y) / n_samples
grad_b = 2 * (y_pred - y).mean()
# 参数更新
w -= lr * grad_w
b -= lr * grad_b
# 可选:每隔一定迭代次数打印一次损失值
if (epoch + 1) % 50 == 0:
print(f"Epoch {epoch + 1}/{epochs}, Loss: {loss:.4f}")
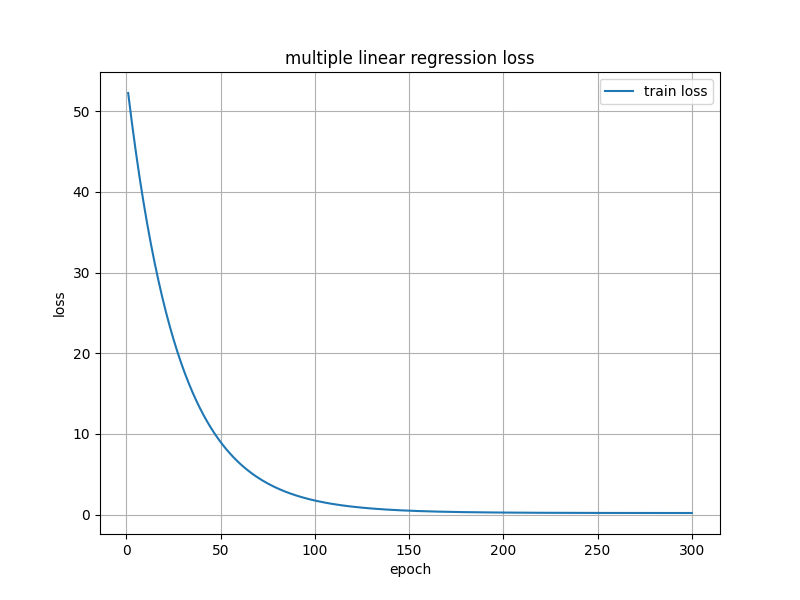
# 4. 绘制损失曲线
plt.figure(figsize=(8, 6))
plt.plot(range(1, epochs + 1), losses, label='train loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('multiple linear regression loss')
plt.legend()
plt.grid(True)
plt.show()
# 5. 打印最终的参数值
print("训练结束后的参数值:")
print(f"w: {w}")
print(f"b: {b}")
# 6. 比较真实参数和模型学习到的参数
print("\n真实的参数值:")
print(f"true_w: {true_w}")
print(f"true_b: {true_b}")
程序输出:
Epoch 50/300, Loss: 9.0096
Epoch 100/300, Loss: 1.7507
Epoch 150/300, Loss: 0.4893
Epoch 200/300, Loss: 0.2570
Epoch 250/300, Loss: 0.2122
Epoch 300/300, Loss: 0.2032
训练结束后的参数值:
w: [ 2.0363504 -2.90204453 3.95529038 1.08716601 -2.00416486]
b: 4.896948074085842
真实的参数值:
true_w: [ 2 -3 4 1 -2]
true_b: 5
以及loss的下降曲线图:
结合示例深度学习中的梯度求导的一般过程
数学原理推导
1. 问题背景
在上面的多元线性回归案例中,我们的目标是找到最优的参数 w \mathbf{w} w和 b b b,使得模型预测值 y ^ \hat{\mathbf{y}} y^与真实值 y \mathbf{y} y之间的均方误差(Mean Squared Error, MSE)最小化。
模型表示:
y ^ = X w + b \hat{\mathbf{y}} = \mathbf{X} \mathbf{w} + b y^=Xw+b
- X \mathbf{X} X:形状为 ( n , m ) (n, m) (n,m)的数据矩阵, n n n为样本数, m m m为特征数。
- w \mathbf{w} w:形状为 ( m , 1 ) (m, 1) (m,1)的权重向量。
- b b b:偏置项,标量。
损失函数(MSE):
L ( w , b ) = 1 n ∑ i = 1 n ( y ^ i − y i ) 2 L(\mathbf{w}, b) = \frac{1}{n} \sum_{i=1}^n (\hat{y}_i - y_i)^2 L(w,b)=n1i=1∑n(y^i−yi)2
2. 计算梯度
我们需要计算损失函数 L L L对参数 w \mathbf{w} w和 b b b的梯度,即 ∇ w L \nabla_{\mathbf{w}} L ∇wL和 ∂ L ∂ b \frac{\partial L}{\partial b} ∂b∂L。
2.1. 对 w \mathbf{w} w的梯度 ∇ w L \nabla_{\mathbf{w}} L ∇wL
步骤1:展开损失函数
L ( w , b ) = 1 n ∑ i = 1 n ( y ^ i − y i ) 2 = 1 n ∑ i = 1 n ( x i ⊤ w + b − y i ) 2 L(\mathbf{w}, b) = \frac{1}{n} \sum_{i=1}^n (\hat{y}_i - y_i)^2 = \frac{1}{n} \sum_{i=1}^n (\mathbf{x}_i^\top \mathbf{w} + b - y_i)^2 L(w,b)=n1i=1∑n(y^i−yi)2=n1i=1∑n(xi⊤w+b−yi)2
其中, x i \mathbf{x}_i xi是第 i i i个样本的特征向量。
步骤2:对 w \mathbf{w} w求偏导
对 w \mathbf{w} w求梯度:
∇ w L = ∂ L ∂ w = ∂ ∂ w ( 1 n ∑ i = 1 n ( x i ⊤ w + b − y i ) 2 ) \nabla_{\mathbf{w}} L = \frac{\partial L}{\partial \mathbf{w}} = \frac{\partial}{\partial \mathbf{w}} \left( \frac{1}{n} \sum_{i=1}^n (\mathbf{x}_i^\top \mathbf{w} + b - y_i)^2 \right) ∇wL=∂w∂L=∂w∂(n1i=1∑n(xi⊤w+b−yi)2)
由于求和和求导可以交换:
∇ w L = 1 n ∑ i = 1 n ∂ ∂ w ( ( x i ⊤ w + b − y i ) 2 ) \nabla_{\mathbf{w}} L = \frac{1}{n} \sum_{i=1}^n \frac{\partial}{\partial \mathbf{w}} \left( (\mathbf{x}_i^\top \mathbf{w} + b - y_i)^2 \right) ∇wL=n1i=1∑n∂w∂((xi⊤w+b−yi)2)
步骤3:计算单个项的偏导
对每个 i i i,应用链式法则:
∂ ∂ w ( ( x i ⊤ w + b − y i ) 2 ) = 2 ( x i ⊤ w + b − y i ) ∂ ∂ w ( x i ⊤ w ) \frac{\partial}{\partial \mathbf{w}} \left( (\mathbf{x}_i^\top \mathbf{w} + b - y_i)^2 \right) = 2 (\mathbf{x}_i^\top \mathbf{w} + b - y_i) \frac{\partial}{\partial \mathbf{w}} (\mathbf{x}_i^\top \mathbf{w}) ∂w∂((xi⊤w+b−yi)2)=2(xi⊤w+b−yi)∂w∂(xi⊤w)
注意到 ∂ ∂ w ( x i ⊤ w ) = x i \frac{\partial}{\partial \mathbf{w}} (\mathbf{x}_i^\top \mathbf{w}) = \mathbf{x}_i ∂w∂(xi⊤w)=xi,因此:
∂ ∂ w ( ( x i ⊤ w + b − y i ) 2 ) = 2 ( x i ⊤ w + b − y i ) x i \frac{\partial}{\partial \mathbf{w}} \left( (\mathbf{x}_i^\top \mathbf{w} + b - y_i)^2 \right) = 2 (\mathbf{x}_i^\top \mathbf{w} + b - y_i) \mathbf{x}_i ∂w∂((xi⊤w+b−yi)2)=2(xi⊤w+b−yi)xi
步骤4:合并梯度表达式
将所有样本的梯度相加:
∇ w L = 2 n ∑ i = 1 n ( y ^ i − y i ) x i \nabla_{\mathbf{w}} L = \frac{2}{n} \sum_{i=1}^n (\hat{y}_i - y_i) \mathbf{x}_i ∇wL=n2i=1∑n(y^i−yi)xi
将上述求和形式转换为矩阵形式。定义误差向量:
e = y ^ − y \mathbf{e} = \hat{\mathbf{y}} - \mathbf{y} e=y^−y
将样本特征矩阵 X \mathbf{X} X的转置 X ⊤ \mathbf{X}^\top X⊤与误差向量相乘:
∇ w L = 2 n X ⊤ ( y ^ − y ) = 2 n X ⊤ e \nabla_{\mathbf{w}} L = \frac{2}{n} \mathbf{X}^\top (\hat{\mathbf{y}} - \mathbf{y}) = \frac{2}{n} \mathbf{X}^\top \mathbf{e} ∇wL=n2X⊤(y^−y)=n2X⊤e
2.2. 对 b b b的梯度 ∂ L ∂ b \frac{\partial L}{\partial b} ∂b∂L
步骤1:对 b b b求偏导
∂ L ∂ b = ∂ ∂ b ( 1 n ∑ i = 1 n ( x i ⊤ w + b − y i ) 2 ) = 1 n ∑ i = 1 n ∂ ∂ b ( ( x i ⊤ w + b − y i ) 2 ) \frac{\partial L}{\partial b} = \frac{\partial}{\partial b} \left( \frac{1}{n} \sum_{i=1}^n (\mathbf{x}_i^\top \mathbf{w} + b - y_i)^2 \right) = \frac{1}{n} \sum_{i=1}^n \frac{\partial}{\partial b} \left( (\mathbf{x}_i^\top \mathbf{w} + b - y_i)^2 \right) ∂b∂L=∂b∂(n1i=1∑n(xi⊤w+b−yi)2)=n1i=1∑n∂b∂((xi⊤w+b−yi)2)
步骤2:计算单个项的偏导
∂ ∂ b ( ( x i ⊤ w + b − y i ) 2 ) = 2 ( x i ⊤ w + b − y i ) ∂ ∂ b ( x i ⊤ w + b − y i ) \frac{\partial}{\partial b} \left( (\mathbf{x}_i^\top \mathbf{w} + b - y_i)^2 \right) = 2 (\mathbf{x}_i^\top \mathbf{w} + b - y_i) \frac{\partial}{\partial b} (\mathbf{x}_i^\top \mathbf{w} + b - y_i) ∂b∂((xi⊤w+b−yi)2)=2(xi⊤w+b−yi)∂b∂(xi⊤w+b−yi)
由于 ∂ ∂ b ( x i ⊤ w + b − y i ) = 1 \frac{\partial}{\partial b} (\mathbf{x}_i^\top \mathbf{w} + b - y_i) = 1 ∂b∂(xi⊤w+b−yi)=1,因此:
∂ ∂ b ( ( x i ⊤ w + b − y i ) 2 ) = 2 ( x i ⊤ w + b − y i ) \frac{\partial}{\partial b} \left( (\mathbf{x}_i^\top \mathbf{w} + b - y_i)^2 \right) = 2 (\mathbf{x}_i^\top \mathbf{w} + b - y_i) ∂b∂((xi⊤w+b−yi)2)=2(xi⊤w+b−yi)
步骤3:合并梯度表达式
∂ L ∂ b = 2 n ∑ i = 1 n ( y ^ i − y i ) = 2 n ∑ i = 1 n e i = 2 ⋅ mean ( y ^ − y ) \frac{\partial L}{\partial b} = \frac{2}{n} \sum_{i=1}^n (\hat{y}_i - y_i) = \frac{2}{n} \sum_{i=1}^n e_i = 2 \cdot \text{mean}(\hat{\mathbf{y}} - \mathbf{y}) ∂b∂L=n2i=1∑n(y^i−yi)=n2i=1∑nei=2⋅mean(y^−y)
对应到代码中的梯度计算
在代码中:
grad_w = 2 * X.T.dot(y_pred - y) / len(y)
grad_b = 2 * (y_pred - y).mean()
X.T.dot(y_pred - y)对应于 X ⊤ ( y ^ − y ) \mathbf{X}^\top (\hat{\mathbf{y}} - \mathbf{y}) X⊤(y^−y)。len(y)是样本数量 n n n。(y_pred - y).mean()对应于误差的平均值 mean ( y ^ − y ) \text{mean}(\hat{\mathbf{y}} - \mathbf{y}) mean(y^−y)。
对比数学推导和代码如下:
-
对于 ∇ w L \nabla_{\mathbf{w}} L ∇wL:
数学上:
∇ w L = 2 n X ⊤ ( y ^ − y ) \nabla_{\mathbf{w}} L = \frac{2}{n} \mathbf{X}^\top (\hat{\mathbf{y}} - \mathbf{y}) ∇wL=n2X⊤(y^−y)
代码中:
grad_w = 2 * X.T.dot(y_pred - y) / len(y)二者完全一致。
-
对于 ∂ L ∂ b \frac{\partial L}{\partial b} ∂b∂L:
数学上:
∂ L ∂ b = 2 ⋅ mean ( y ^ − y ) \frac{\partial L}{\partial b} = 2 \cdot \text{mean}(\hat{\mathbf{y}} - \mathbf{y}) ∂b∂L=2⋅mean(y^−y)
代码中:
grad_b = 2 * (y_pred - y).mean()也完全一致。
个人公众号
看到这里的各位朋友,肯定都是真爱,在下是一个从事环境科学领域的科研牛马,主要研究方向为深度学习环境领域的应用,如果您也同样的在做相关的研究,关注在下的微信公众号:Environmodel',每日分享环境领域的模型研究、机器学习等研究进展,当然也还会有不少实用的编程技巧分享。