目录标题
- Jupyter Notebook
- 安装
- 启动
- Pandas快速入门
- 查看数据
- 验证数据
- 建立索引
- 数据选取
- ⚠️注意:
- 排序
- 分组聚合
- 数据转换
- 增加列
- 绘图
- 'line' 或 ''**(默认):绘制折线图。
- 'bar':绘制条形图。
- 'barh':绘制水平条形图。
- 'hist':绘制直方图。
- 'box':绘制箱形图(Boxplot)。
- 'kde' 或 'density':绘制核密度估计图(Kernel Density Estimate)。
- 'area':绘制面积图。面积图下方区域将被填充。
- 'pie':绘制饼图。饼图通常用于显示部分与整体之间的关系。
- 'scatter':绘制散点图。散点图用于显示两个变量之间的关系。
- 'hexbin':绘制六边形分箱图(Hexbin plot)。
- 写出数据
Jupyter Notebook
Jupyter(https://jupyter.org)项目是一个非营利性开源项目,于2014年由IPython项目中诞生,它能支持所有编程语言的交互式数据科学和科学计算。它的特点是能够在网页上直接执行编写的代码,同时支持动态交互,在做数据可视化时尤其方便

安装
# 安装Jupyter Notebook,使用清华大学下载源加快下载速度
pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装 Jupyter Lab 的命令如下
pip install jupyterlab
启动
jupyter notebook
这样就会在浏览器中打开一个网页
Pandas快速入门
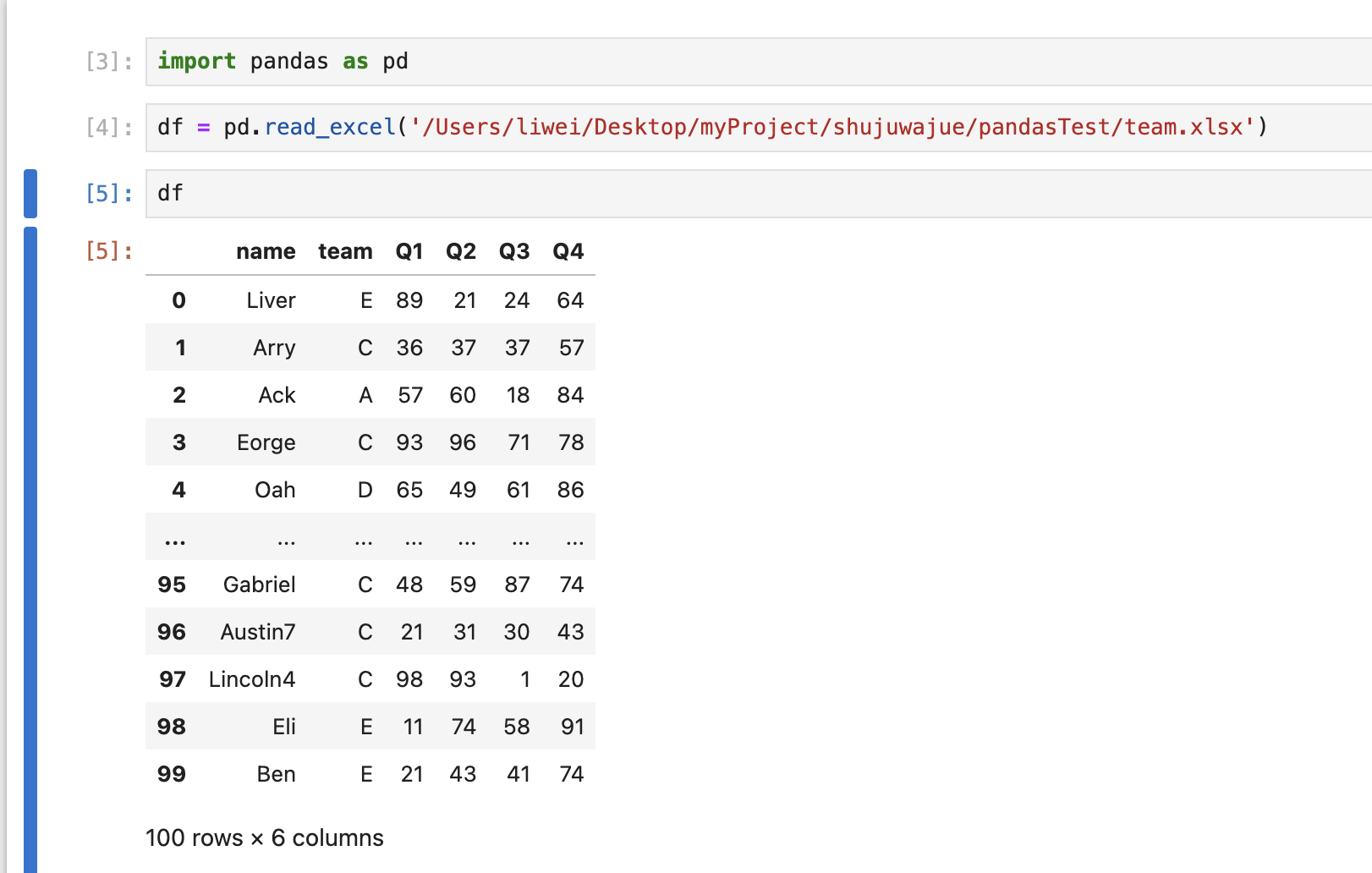
import pandas as pd # 引入Pandas库,按惯例起别名pd
# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
df
查看数据
import pandas as pd # 引入Pandas库,按惯例起别名pd
# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
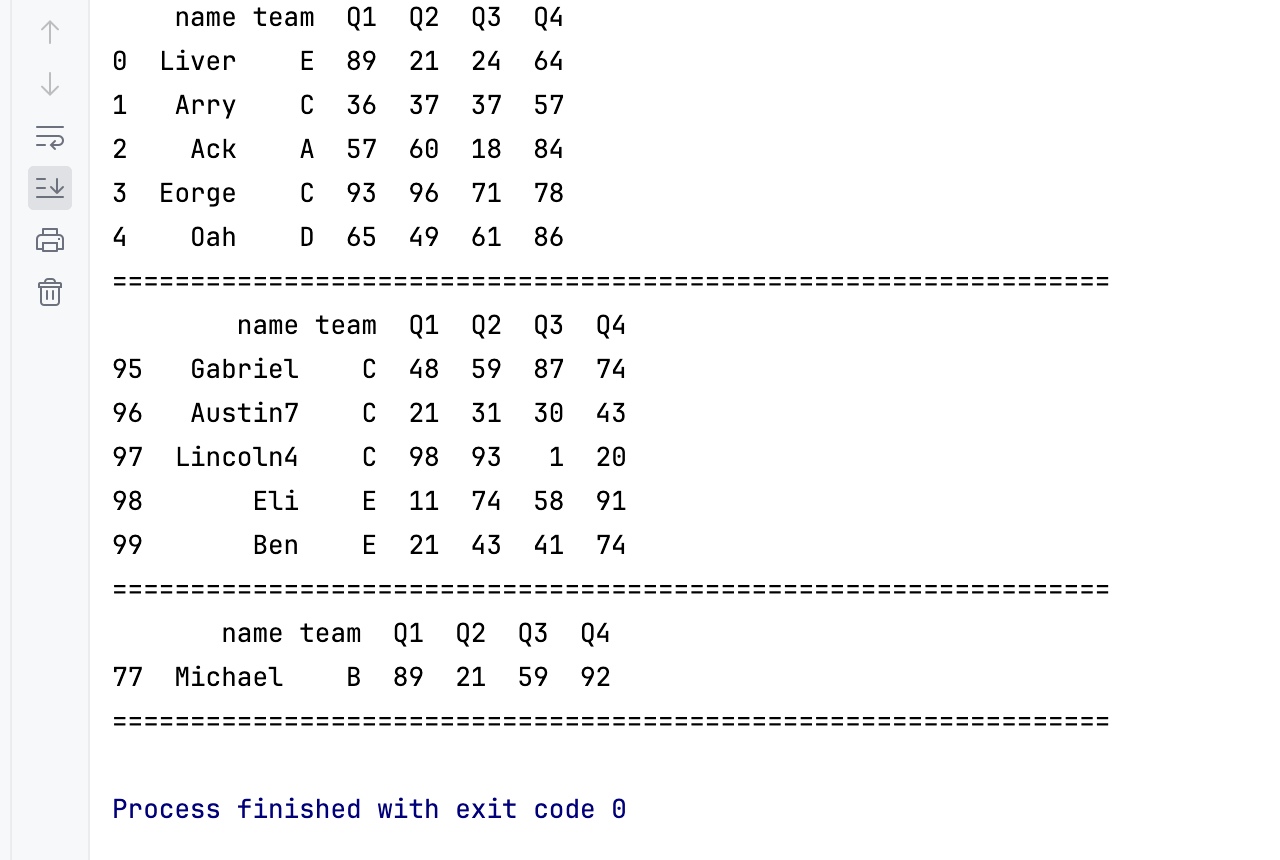
print(df.head()) # 打印前5行数据
print('================================================================')
print(df.tail()) # 打印后5行数据
print('================================================================')
print(df.sample()) # sample
print('================================================================')
验证数据
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : lw
@Description :
"""
import pandas as pd # 引入Pandas库,按惯例起别名pd
# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
print('查看数据类型')
print(df.dtypes) # 查看数据类型
print('================================')
print('查看数据信息')
print(df.info) # 查看数据信息
print('================================')
print('查看数据统计信息')
print(df.describe()) # 查看数据统计信息 df.describe()会计算出各数字字段的总数(count)、平均数 (mean)、标准差(std)、最小值(min)、四分位数和最大值(max
print('================================')
print('查看数据索引')
print(df.axes)
print('================================')
print('查看数据列名')
print(df.columns)
查看数据类型
name object
team object
Q1 int64
Q2 int64
Q3 int64
Q4 int64
dtype: object
================================
查看数据信息
<bound method DataFrame.info of name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
1 Arry C 36 37 37 57
2 Ack A 57 60 18 84
3 Eorge C 93 96 71 78
4 Oah D 65 49 61 86
… … … … … … …
95 Gabriel C 48 59 87 74
96 Austin7 C 21 31 30 43
97 Lincoln4 C 98 93 1 20
98 Eli E 11 74 58 91
99 Ben E 21 43 41 74
[100 rows x 6 columns]>
================================
查看数据统计信息
Q1 Q2 Q3 Q4
count 100.000000 100.000000 100.000000 100.000000
mean 49.200000 52.550000 52.670000 52.780000
std 29.962603 29.845181 26.543677 27.818524
min 1.000000 1.000000 1.000000 2.000000
25% 19.500000 26.750000 29.500000 29.500000
50% 51.500000 49.500000 55.000000 53.000000
75% 74.250000 77.750000 76.250000 75.250000
max 98.000000 99.000000 99.000000 99.000000
================================
查看数据索引
[RangeIndex(start=0, stop=100, step=1), Index([‘name’, ‘team’, ‘Q1’, ‘Q2’, ‘Q3’, ‘Q4’], dtype=‘object’)]
================================
查看数据列名
Index([‘name’, ‘team’, ‘Q1’, ‘Q2’, ‘Q3’, ‘Q4’], dtype=‘object’)
Process finished with exit code 0
建立索引
以上数据真正业务意义上的索引是name列,所以我们需要使它成为索引:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pandas as pd # 引入Pandas库,按惯例起别名pd
# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
print('\n 原始表格 \n')
print(df)
print('\n 姓名为索引 \n')
df.index = df['name']
print(df)
原始表格
name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
1 Arry C 36 37 37 57
2 Ack A 57 60 18 84
3 Eorge C 93 96 71 78
4 Oah D 65 49 61 86
… … … … … … …
95 Gabriel C 48 59 87 74
96 Austin7 C 21 31 30 43
97 Lincoln4 C 98 93 1 20
98 Eli E 11 74 58 91
99 Ben E 21 43 41 74
[100 rows x 6 columns]
姓名为索引
name team Q1 Q2 Q3 Q4
name
Liver Liver E 89 21 24 64
Arry Arry C 36 37 37 57
Ack Ack A 57 60 18 84
Eorge Eorge C 93 96 71 78
Oah Oah D 65 49 61 86
… … … … … … …
Gabriel Gabriel C 48 59 87 74
Austin7 Austin7 C 21 31 30 43
Lincoln4 Lincoln4 C 98 93 1 20
Eli Eli E 11 74 58 91
Ben Ben E 21 43 41 74
[100 rows x 6 columns]
Process finished with exit code 0
数据选取
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
import pandas as pd # 引入Pandas库,按惯例起别名pd
# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
# 查看指定列
print('查看 name列')
print(df['name'])
print('================================')
print('查看 name和Q1列')
print(df[['name','Q1']])
print('================================')
# 用指定索引选取
df[df.index == 'Liver'] # 指定姓名
# 用自然索引选择,类似列表的切片
print('查看前三行')
print(df[0:3]) # 取前三行
print('================================')
print('每两个取一个')
print(df[0:10:2]) # 在前10个中每两个取一个
print('================================')
print('查看前10行')
print(df.iloc[:10,:]) # 前10个
查看 name列
0 Liver
1 Arry
2 Ack
3 Eorge
4 Oah
...
95 Gabriel
96 Austin7
97 Lincoln4
98 Eli
99 Ben
Name: name, Length: 100, dtype: object
================================
查看 name和Q1列
name Q1
0 Liver 89
1 Arry 36
2 Ack 57
3 Eorge 93
4 Oah 65
.. ... ..
95 Gabriel 48
96 Austin7 21
97 Lincoln4 98
98 Eli 11
99 Ben 21
[100 rows x 2 columns]
================================
查看前三行
name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
1 Arry C 36 37 37 57
2 Ack A 57 60 18 84
================================
每两个取一个
name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
2 Ack A 57 60 18 84
4 Oah D 65 49 61 86
6 Acob B 61 95 94 8
8 Reddie D 64 93 57 72
================================
查看前10行
name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
1 Arry C 36 37 37 57
2 Ack A 57 60 18 84
3 Eorge C 93 96 71 78
4 Oah D 65 49 61 86
5 Harlie C 24 13 87 43
6 Acob B 61 95 94 8
7 Lfie A 9 10 99 37
8 Reddie D 64 93 57 72
9 Oscar A 77 9 26 67
Process finished with exit code 0
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei68
@Description :
"""
import pandas as pd # 引入Pandas库,按惯例起别名pd
# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
print('条件选择')
print(df[df['Q1'] > 80]) # 选择Q1列中大于80的行
print(df[df['Q1'] > 80]['name']) # 选择Q1列中大于80的行 name列
print(df[df['Q1'] > 80][['name','Q1']]) # 选择Q1列中大于80的行 name和Q1列
⚠️注意:
选择一列和切片一样的使用方式,多列的时候要使用二维数组切片形式
排序
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei68
@Description :
"""
import pandas as pd # 引入Pandas库,按惯例起别名pd
# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
df = df.sort_values(by = 'Q1') # 按照Q1列进行排序
print(df)
df = df.sort_values(by = 'Q1',ascending=False) # 降序排序
print(df)
df = df.sort_values(by = ['name','Q2'],ascending=[True,False]) # 先按照name升序,再按照Q2降序
print(df)
name team Q1 Q2 Q3 Q4
37 Sebastian C 1 14 68 48
39 Harley B 2 99 12 13
85 Liam B 2 80 24 25
58 Lewis B 4 34 77 28
82 Finn E 4 1 55 32
.. ... ... .. .. .. ..
3 Eorge C 93 96 71 78
88 Aaron A 96 75 55 8
38 Elijah B 97 89 15 46
19 Max E 97 75 41 3
97 Lincoln4 C 98 93 1 20
[100 rows x 6 columns]
name team Q1 Q2 Q3 Q4
97 Lincoln4 C 98 93 1 20
19 Max E 97 75 41 3
38 Elijah B 97 89 15 46
88 Aaron A 96 75 55 8
3 Eorge C 93 96 71 78
.. ... ... .. .. .. ..
82 Finn E 4 1 55 32
58 Lewis B 4 34 77 28
85 Liam B 2 80 24 25
39 Harley B 2 99 12 13
37 Sebastian C 1 14 68 48
[100 rows x 6 columns]
name team Q1 Q2 Q3 Q4
88 Aaron A 96 75 55 8
2 Ack A 57 60 18 84
6 Acob B 61 95 94 8
33 Adam C 90 32 47 39
94 Aiden D 20 31 62 68
.. ... ... .. .. .. ..
40 Toby A 52 27 17 68
46 Tommy C 29 44 28 76
79 Tyler A 75 16 44 63
18 William C 80 68 3 26
55 Zachary E 12 71 85 93
[100 rows x 6 columns]
Process finished with exit code 0
分组聚合
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : li
@Description :
"""
import pandas as pd # 引入Pandas库,按惯例起别名pd
# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
print(df.groupby('team').sum('Q1'))
print(df.groupby('team').mean('Q1'))
print(df.groupby(['team','name']).mean())
# 不同列不同的计算方法
df1 = df.groupby('team').agg({'Q1': sum, # 总和
'Q2': 'count', # 总数
'Q3':'mean', # 平均
'Q4': max}) # 最大值
print(df1)
数据转换
import pandas as pd
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
df1 = df.groupby('team').agg({'Q1': sum, # 总和
'Q2': 'count', # 总数
'Q3':'mean', # 平均
'Q4': max}) # 最大值
print(df1)
print(df1.T)
df.T 转置
转置前
Q1 Q2 Q3 Q4
team
A 1066 17 51.470588 97
B 975 22 54.636364 99
C 1056 22 48.545455 98
D 860 19 65.315789 99
E 963 20 44.050000 98
转置后
team A B C D E
Q1 1066.000000 975.000000 1056.000000 860.000000 963.00
Q2 17.000000 22.000000 22.000000 19.000000 20.00
Q3 51.470588 54.636364 48.545455 65.315789 44.05
Q4 97.000000 99.000000 98.000000 99.000000 98.00
增加列
直接切片增加索引的方式
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei
@Description :
"""
import pandas as pd
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
df['one'] = 1 # 增加一个固定值的列
df['total'] = df.Q1 + df.Q2 + df.Q3 + df.Q4 # 增加总成绩列
# # 将计算得来的结果赋值给新列
df['total2'] = df.loc[:,'Q1':'Q4'].apply(lambda x:sum(x), axis=1)
df['avg'] = df.total/4 # 增加平均成绩列
print(df)
绘图
Pandas利用plot()调用Matplotlib快速绘制出数据可视化图形。注意,第一次使用plot()时可能需要执行两次才能显示图形。 可以使用plot()快速绘制折线图。
在Python中,使用pandas库的DataFrame对象的plot()方法可以很容易地绘制图表。默认情况下,df.plot()会将图表显示在Jupyter Notebook中,但不会自动保存为文件。如果你想保存图表,可以使用matplotlib.pyplot.savefig()函数。
以下是一个简单的例子
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei
@Description :
"""
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
df['one'] = 1 # 增加一个固定值的列
df['total'] = df.Q1 + df.Q2 + df.Q3 + df.Q4 # 增加总成绩列
# # 将计算得来的结果赋值给新列
df['total2'] = df.loc[:,'Q1':'Q4'].apply(lambda x:sum(x), axis=1)
df['avg'] = df.total/4 # 增加平均成绩列
df.plot()
plt.plot()
plt.savefig('team.png')
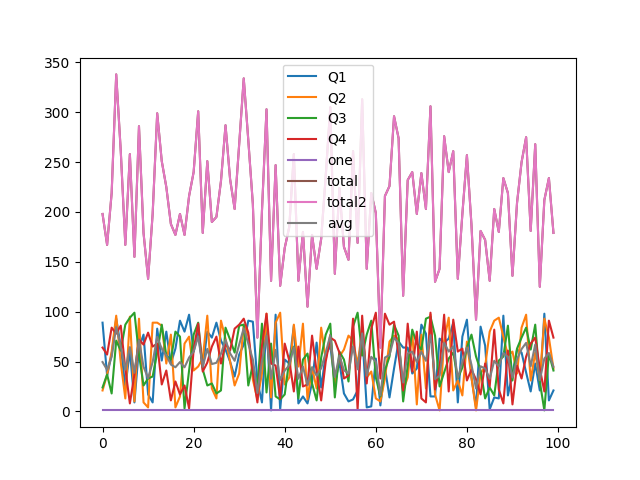
在pandas中,df.plot()是一个非常方便的函数,用于基于DataFrame或Series的数据快速生成图表。kind参数是df.plot()方法中一个非常重要的参数,它指定了要绘制的图表类型。kind参数可以接收多种不同的字符串值,以生成不同类型的图表。以下是一些常见的kind参数值及其对应的图表类型:
‘line’ 或 ‘’**(默认):绘制折线图。
如果DataFrame有多列,则每列都会被绘制为一条线。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei
@Description :
"""
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
file_path_out = 'team_out.xlsx'
# groupby 分组,sum求和,reset_index重置索引
# 注意 此处如果不重置索引,df中将会没有groupBy的字段
df1 = df.groupby('team').sum('Q1').reset_index()
with pd.ExcelWriter(file_path_out) as writer:
df1.to_excel(writer, sheet_name='结果', index=False)
print(df1)
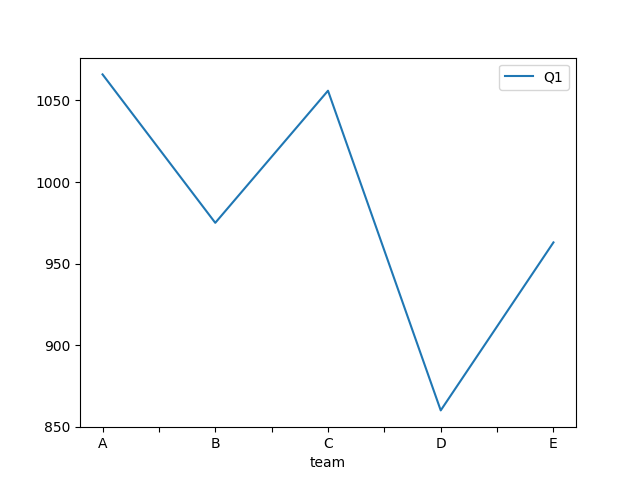
df1.plot(x = 'team',y = 'Q1' ,kind = 'line')
plt.plot()
plt.savefig('team.png')
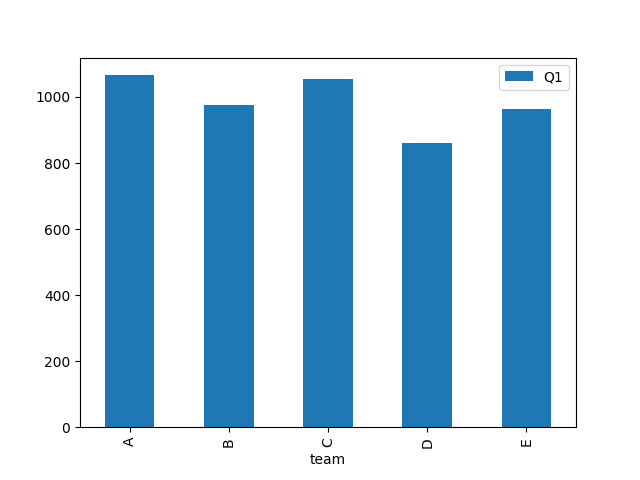
‘bar’:绘制条形图。
如果DataFrame有多列,则每列都会被绘制为独立的条形图组。
df1.plot(x = 'team',y = 'Q1' ,kind = 'bar')
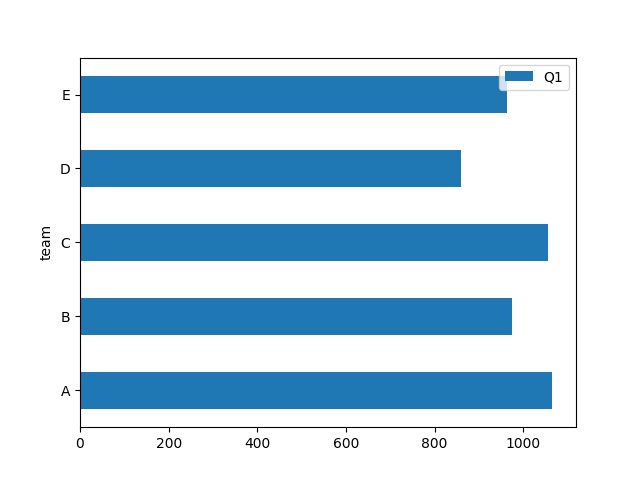
‘barh’:绘制水平条形图。
与条形图类似,但条是水平的。
df1.plot(x = 'team',y = 'Q1' ,kind = 'barh')
‘hist’:绘制直方图。
这通常用于Series,但也可以用于DataFrame的每列,为每列绘制直方图。
df1.plot(x = 'team',y = 'Q1' ,kind = 'hist')
‘box’:绘制箱形图(Boxplot)。
箱形图用于显示数据分布的四分位数,并可能显示异常值。

‘kde’ 或 ‘density’:绘制核密度估计图(Kernel Density Estimate)。
这是一种用于估计单变量概率密度函数的非参数方法。

‘area’:绘制面积图。面积图下方区域将被填充。
如果DataFrame有多列,则堆叠这些区域(除非指定stacked=False)。

‘pie’:绘制饼图。饼图通常用于显示部分与整体之间的关系。
注意,饼图通常用于单个Series,因为DataFrame的每一行都会被解释为饼图的一部分。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei
@Description :
"""
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
file_path_out = 'team_out.xlsx'
# groupby 分组,sum求和,reset_index重置索引
# 注意 此处如果不重置索引,df中将会没有groupBy的字段
# 各组人数对比
df.groupby('team').count().Q1.plot.pie()
plt.savefig('team_pie.png')
‘scatter’:绘制散点图。散点图用于显示两个变量之间的关系。
如果DataFrame有多列,则默认使用前两列作为x和y轴。

‘hexbin’:绘制六边形分箱图(Hexbin plot)。
这是一种用于表示两个变量之间关系的二维直方图。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei
@Description :
"""
import numpy as np
import matplotlib.pyplot as plt
# 生成一些随机数据
np.random.seed(19680801)
x = np.random.randn(10000)
y = np.random.randn(10000)
# 绘制Hexbin plot
plt.hexbin(x, y, gridsize=50, cmap='viridis')
# 添加颜色条
cb = plt.colorbar(label='counts in bin')
# 设置图表标题和坐标轴标签
plt.title("Hexbin of 10,000 points")
plt.xlabel("X")
plt.ylabel("Y")
# 显示图表
plt.show()
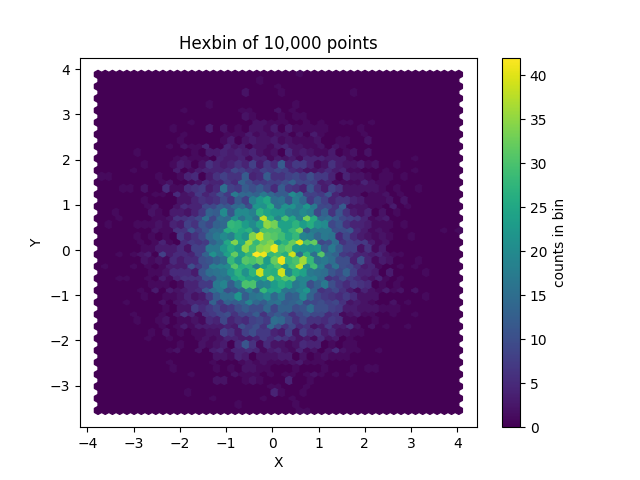
写出数据
with pd.ExcelWriter(file_path_out) as writer:
df1.to_excel(writer, sheet_name='结果', index=False)







![HTB:Explosion[WriteUP]](https://i-blog.csdnimg.cn/direct/e8f2494a71764f08962f4c2461c40a8f.png)