此次yolov10+deepsort不论是准确率还是稳定性,再次超越了之前的yolo+deepsort系列。
yolov10介绍——实时端到端物体检测
YOLOv10 是清华大学研究人员在 UltralyticsPython 清华大学的研究人员在 YOLOv10软件包的基础上,引入了一种新的实时目标检测方法,解决了YOLO 以前版本在后处理和模型架构方面的不足。通过消除非最大抑制(NMS)和优化各种模型组件,YOLOv10 在显著降低计算开销的同时实现了最先进的性能。大量实验证明,YOLOv10 在多个模型尺度上实现了卓越的精度-延迟权衡。

概述
实时物体检测旨在以较低的延迟准确预测图像中的物体类别和位置。YOLO 系列在性能和效率之间取得了平衡,因此一直处于这项研究的前沿。然而,对 NMS 的依赖和架构上的低效阻碍了最佳性能的实现。YOLOv10 通过为无 NMS 训练引入一致的双重分配和以效率-准确性为导向的整体模型设计策略,解决了这些问题。
YOLOv10 的结构建立在以前YOLO 模型的基础上,同时引入了几项关键创新。模型架构由以下部分组成:
- 主干网YOLOv10 中的主干网负责特征提取,它使用了增强版的 CSPNet(跨阶段部分网络),以改善梯度流并减少计算冗余。
- 颈部颈部设计用于汇聚不同尺度的特征,并将其传递到头部。它包括 PAN(路径聚合网络)层,可实现有效的多尺度特征融合。
- 一对多头:在训练过程中为每个对象生成多个预测,以提供丰富的监督信号并提高学习准确性。
- 一对一磁头:在推理过程中为每个对象生成一个最佳预测,无需 NMS,从而减少延迟并提高效率。
主要功能
- 无 NMS 训练:利用一致的双重分配来消除对 NMS 的需求,从而减少推理延迟。
- 整体模型设计:从效率和准确性的角度全面优化各种组件,包括轻量级分类头、空间通道去耦向下采样和等级引导块设计。
- 增强的模型功能:纳入大核卷积和部分自注意模块,在不增加大量计算成本的情况下提高性能。
型号
YOLOv10 有多种型号,可满足不同的应用需求:
- YOLOv10-N:用于资源极其有限环境的纳米版本。
- YOLOv10-S:兼顾速度和精度的小型版本。
- YOLOv10-M:通用中型版本。
- YOLOv10-B:平衡型,宽度增加,精度更高。
- YOLOv10-L:大型版本,精度更高,但计算资源增加。
- YOLOv10-X:超大型版本可实现最高精度和性能。
性能
在准确性和效率方面,YOLOv10 优于YOLO 以前的版本和其他最先进的模型。例如,在 COCO 数据集上,YOLOv10-S 的速度是RT-DETR-R18 的 1.8 倍,而 YOLOv10-B 与 YOLOv9-C 相比,在性能相同的情况下,延迟减少了 46%,参数减少了 25%。
| 模型 | 输入尺寸 | APval | FLOP (G) | 延迟(毫秒) |
|---|---|---|---|---|
| YOLOv10-N | 640 | 38.5 | 6.7 | 1.84 |
| YOLOv10-S | 640 | 46.3 | 21.6 | 2.49 |
| YOLOv10-M | 640 | 51.1 | 59.1 | 4.74 |
| YOLOv10-B | 640 | 52.5 | 92.0 | 5.74 |
| YOLOv10-L | 640 | 53.2 | 120.3 | 7.28 |
| YOLOv10-X | 640 | 54.4 | 160.4 | 10.70 |
使用TensorRT FP16 在 T4GPU 上测量的延迟。
方法
一致的双重任务分配,实现无 NMS 培训
YOLOv10 采用双重标签分配,在训练过程中将一对多和一对一策略结合起来,以确保丰富的监督和高效的端到端部署。一致匹配度量使两种策略之间的监督保持一致,从而提高了推理过程中的预测质量。
效率-精度驱动的整体模型设计
提高效率
- 轻量级分类头:通过使用深度可分离卷积,减少分类头的计算开销。
- 空间信道解耦向下采样:将空间缩减与信道调制解耦,最大限度地减少信息损失和计算成本。
- 梯级引导程序块设计:根据固有阶段冗余调整模块设计,确保参数的最佳利用。
精度提升
- 大核卷积扩大感受野,增强特征提取能力。
- 部分自我关注(PSA):纳入自我关注模块,以最小的开销改进全局表征学习。
实验和结果
YOLOv10 在 COCO 等标准基准上进行了广泛测试,显示出卓越的性能和效率。与以前的版本和其他当代探测器相比,YOLOv10 在延迟和准确性方面都有显著提高。
比较
 与其他最先进的探测器相比:
与其他最先进的探测器相比:
- YOLOv10-S / X 比RT-DETR-R18 / R101 快 1.8 倍 / 1.3 倍,精度相似
- 在精度相同的情况下,YOLOv10-B 比 YOLOv9-C 减少了 25% 的参数,延迟时间缩短了 46%
- YOLOv10-L / X 的性能比YOLOv8-L / X 高 0.3 AP / 0.5 AP,参数少 1.8× / 2.3×
以下是 YOLOv10 变体与其他先进机型的详细比较:
| 模型 | 参数 (M) | FLOPs (G) | mAPval 50-95 | 延迟 (毫秒) | 延迟-前向 (毫秒) |
|---|---|---|---|---|---|
| YOLOv6-3.0-N | 4.7 | 11.4 | 37.0 | 2.69 | 1.76 |
| 金色-YOLO-N | 5.6 | 12.1 | 39.6 | 2.92 | 1.82 |
| YOLOv8-N | 3.2 | 8.7 | 37.3 | 6.16 | 1.77 |
| YOLOv10-N | 2.3 | 6.7 | 39.5 | 1.84 | 1.79 |
| YOLOv6-3.0-S | 18.5 | 45.3 | 44.3 | 3.42 | 2.35 |
| 金色-YOLO-S | 21.5 | 46.0 | 45.4 | 3.82 | 2.73 |
| YOLOv8-S | 11.2 | 28.6 | 44.9 | 7.07 | 2.33 |
| YOLOv10-S | 7.2 | 21.6 | 46.8 | 2.49 | 2.39 |
| RT-DETR-R18 | 20.0 | 60.0 | 46.5 | 4.58 | 4.49 |
| YOLOv6-3.0-M | 34.9 | 85.8 | 49.1 | 5.63 | 4.56 |
| 金色-YOLO-M | 41.3 | 87.5 | 49.8 | 6.38 | 5.45 |
| YOLOv8-M | 25.9 | 78.9 | 50.6 | 9.50 | 5.09 |
| YOLOv10-M | 15.4 | 59.1 | 51.3 | 4.74 | 4.63 |
| YOLOv6-3.0-L | 59.6 | 150.7 | 51.8 | 9.02 | 7.90 |
| 金色-YOLO-L | 75.1 | 151.7 | 51.8 | 10.65 | 9.78 |
| YOLOv8-L | 43.7 | 165.2 | 52.9 | 12.39 | 8.06 |
| RT-DETR-R50 | 42.0 | 136.0 | 53.1 | 9.20 | 9.07 |
| YOLOv10-L | 24.4 | 120.3 | 53.4 | 7.28 | 7.21 |
| YOLOv8-X | 68.2 | 257.8 | 53.9 | 16.86 | 12.83 |
| RT-DETR-R101 | 76.0 | 259.0 | 54.3 | 13.71 | 13.58 |
| YOLOv10-X | 29.5 | 160.4 | 54.4 | 10.70 | 10.60 |
strongsort介绍
三个要点
✔️ 改进了MOT任务中的早期深度模型DeepSORT,实现了SOTA!
✔️ 提出了两种计算成本较低的后处理方法AFLink和GSI,以进一步提高准确度!
✔️ AFLink和GSI提高了几个模型的准确性,不仅仅是所提出的方法!
性能指标图
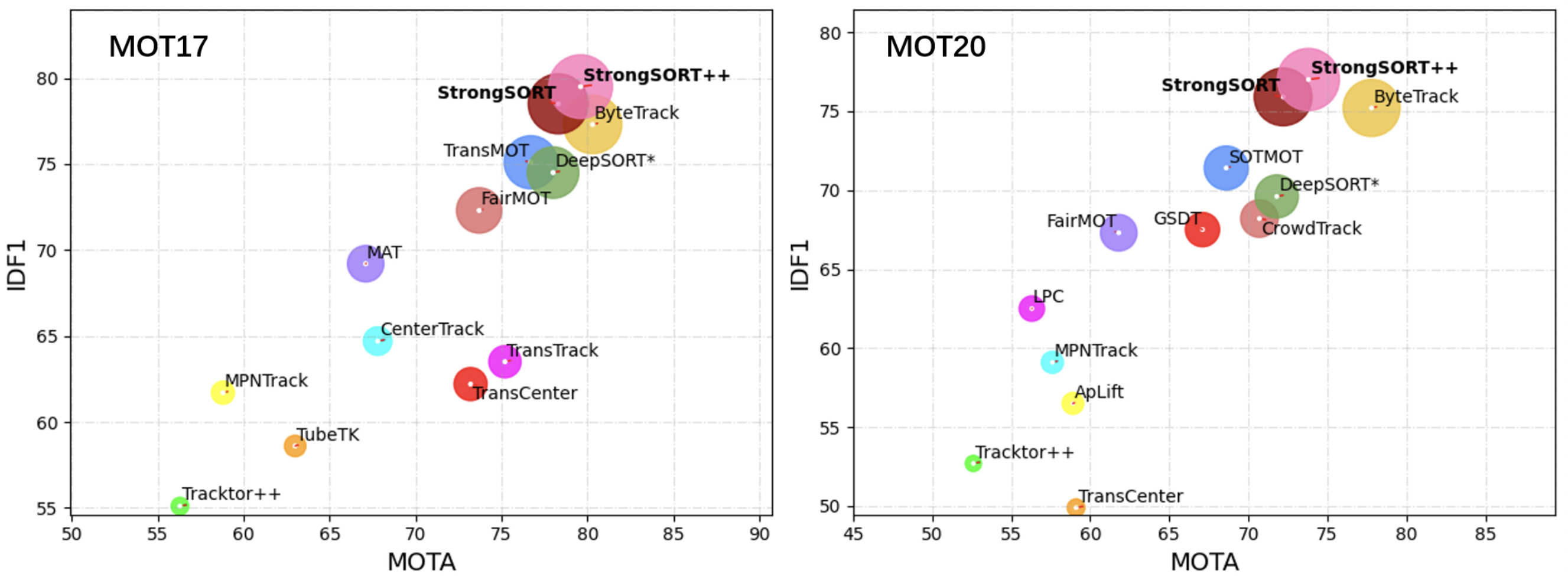
首先,我附上了MOT17和MOT20的准确性比较,这表明了StrongSORT的优越性。现在,VGGNet,一个著名的特征提取器,最近作为RepVGG,一个更强大的版本回归。以类似的标题回归的是StrongSORT:让DeepSORT再次伟大,其中DeepSORT是一个早期的基于深度学习的物体追踪模型,而StrongSORT是对这个早期模型的改进,采用最新的技术实现SOTAStrongSORT是一个通过用最新技术在初始模型上进行改进而实现SOTA的模型。让我们先快速看一下这些改进。
DeepSORT
+BoT:改进的外观特征提取器
+EMA:带有惯性项的特征更新
+NSA:用于非线性运动的卡尔曼滤波器
+MC:包括运动信息的成本矩阵
+ECC:摄像机运动更正
+woC:不采用级联算法
=StrongSORT
+AF链接:仅使用运动信息的全局链接
=StrongSORT+
+GSI内插:通过高斯过程对检测误差进行内插
=StrongSORT++
与其说从根本上改变了结构,不如说是改进了跟踪所需的特征提取、运动信息和成本矩阵的处理。StrongSORT++将AFLink(离线处理)和GSI插值(后处理)应用于改进的StrongSORT,是一个更加精确的模型。我个人认为关键在于此,所以如果你能读到最后,我将很高兴。让我们快速了解一下StrongSORT。
系统定位
本节首先解释了这一方法的系统定位。想了解该方法细节的人可以跳过这一节。深度学习跟踪方法始于DeepSORT。后来,出现了FairMOT和ByteTrack等新方法,并超越了DeepSORT的准确性。在提出新的追踪方法的过程中,出现了两种追踪方法。DeepSORT属于SDE,其检测器是单独准备的。它属于SDE。然而,在本文中,DeepSORT的低准确性并不是因为方法不好,而只是因为它的年龄,其动机是,如果根据此后提出的最新元素技术进行改进,就可以使它变得足够准确。我们有动力去改进它。
改进DeepSORT的原因还有很多。首先,JDE方法的缺点是不容易训练:JDE同时训练检测和跟踪等不同任务的参数,所以模型容易发生冲突,从而限制了准确性。它还需要一个可以同时从检测到跟踪进行训练的数据集,这限制了训练的范围。相比之下,使用SDE,检测和跟踪模型可以被单独优化。最近,诸如ByteTrack这样的模型也被提出来,用于仅基于运动信息的高速跟踪,而没有任何外观信息,但这种模型指出了当目标的运动不简单时无法跟踪的问题。
因此,基于在基于DeepSORT的SDE方法中使用外观特征进行追踪是最佳的动机,提出了StrongSORT。
效果展示
训练与预测


UI设计
将本次的实验使用pyqt打包,方便体验

界面其他功能展示
其他功能演示参考yolov5+deepsort文章
两万字深入浅出yolov5+deepsort实现目标跟踪,含完整代码, yolov,卡尔曼滤波估计,ReID目标重识别,匈牙利匹配KM算法匹配_yolov5 deepsort-CSDN博客
完整代码实现+UI界面
视频,笔记和代码,以及注释都已经上传网盘,放在主页置顶文章



















