蘑菇分类检测数据集 21类蘑菇 8800张 带标注 v

蘑菇分类检测数据集 21类蘑菇 8800张 带标注 voc yolo


蘑菇分类检测数据集介绍
数据集名称
蘑菇分类检测数据集 (Mushroom Classification and Detection Dataset)
数据集概述
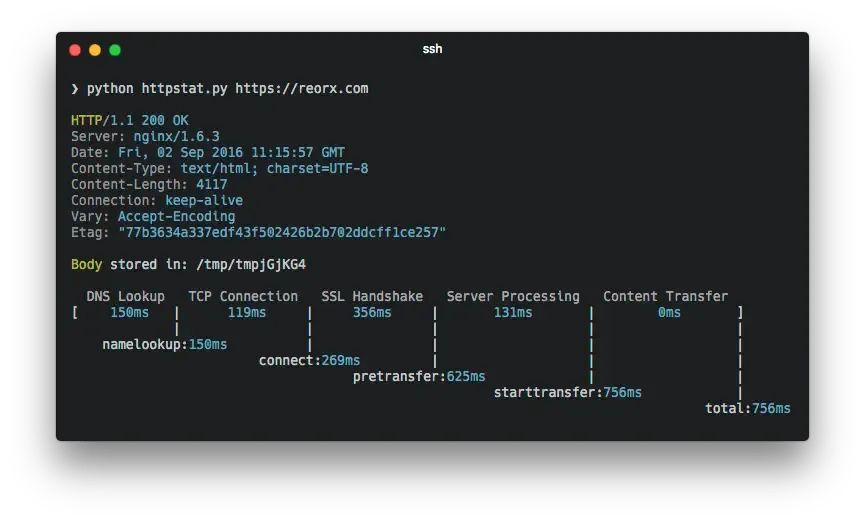
该数据集专为训练和评估基于YOLO系列目标检测模型(包括YOLOv5、YOLOv6、YOLOv7等)而设计,旨在帮助研究人员和开发者创建能够高效识别图像中的多种蘑菇类别的系统。通过使用这个数据集,可以开发出适用于生态研究、食品安全监测、野外探险等多种应用场景的技术解决方案。
数据集规格
- 总图像数量:8,800张
- 训练集:具体划分比例未提供,通常建议按照70%(训练)、20%(验证)、10%(测试)的比例来分配。
- 标注格式:
- VOC格式:每个图像对应一个XML文件,包含边界框坐标及类别信息。
- YOLO格式:每个图像对应一个TXT文件,包含边界框坐标及类别ID。
- 分辨率:图像分辨率可能有所不同,但为了保证一致性,推荐将所有图像调整至统一尺寸,如640x640或1280x1280像素。
- 类别:涵盖21种常见的蘑菇类型,包括但不限于Clitocybe maxima、Lentinus edodes、Agaricus bisporus等。
数据集结构
mushroom_classification_dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
├── labels/
│ ├── train/
│ ├── val/
│ └── test/
└── data.yamlimages/目录下存放的是原始图像文件。labels/目录存放与图像对应的标注文件,每个图像文件都有一个同名的.txt文件存储其YOLO格式的标注信息,以及一个同名的.xml文件存储其VOC格式的标注信息。data.yaml文件包含了关于数据集的基本信息,如路径指向、类别数目及其名称等关键参数。
数据集配置文件 (data.yaml)
# 训练集图像路径
train: path_to_your_train_images
# 验证集图像路径
val: path_to_your_val_images
# 测试集图像路径(如果有的话)
test: path_to_your_test_images
# 类别数量
nc: 21
# 类别名称
names: [
'Clitocybe maxima',
'Lentinus edodes',
'Agaricus bisporus',
'Pleurotus eryngii',
'Copr inus comatus',
'Cantharellus cibarius',
'Boletus',
'Dictyophora indusiata',
'Pleurotus citrinopileatus',
'Hypsizygus marmoreus',
'Pleurotus cystidiosus',
'Flammulina velutiper',
'Agrocybe aegerita',
'Auricularia auricula',
'Armillaria mellea',
'Agaricus blazei Murill',
'Pleurotus ostreatus',
'Morchella esculenta',
'Hericium erinaceus',
'Cordyceps militaris',
'Collybia albuminosa'
]标注统计
- Clitocybe maxima:606张图像,共1,049个实例
- Lentinus edodes:479张图像,共2,690个实例
- Agaricus bisporus:161张图像,共521个实例
- Pleurotus eryngii:423张图像,共704个实例
- Coprinus comatus:519张图像,共1,599个实例
- Cantharellus cibarius:648张图像,共1,317个实例
- Boletus:639张图像,共1,353个实例
- Dictyophora indusiata:535张图像,共1,275个实例
- Pleurotus citrinopileatus:441张图像,共531个实例
- Hypsizygus marmoreus:393张图像,共583个实例
- Pleurotus cystidiosus:429张图像,共711个实例
- Flammulina velutiper:423张图像,共550个实例
- Agrocybe aegerita:179张图像,共197个实例
- Auricularia auricula:242张图像,共408个实例
- Armillaria mellea:200张图像,共290个实例
- Agaricus blazei Murill:137张图像,共307个实例
- Pleurotus ostreatus:433张图像,共549个实例
- Morchella esculenta:433张图像,共1,107个实例
- Hericium erinaceus:454张图像,共1,299个实例
- Cordyceps militaris:600张图像,共1,137个实例
- Collybia albuminosa:493张图像,共2,074个实例
- 总计 (total):8,858张图像,共20,251个实例
标注示例
YOLO格式
对于一张图片中包含一个“Lentinus edodes”情况,相应的.txt文件内容可能是:
1 0.5678 0.3456 0.1234 0.2345这里1代表“Lentinus edodes”这一类别的ID,后续四个数字依次表示物体在图像中的相对位置(中心点x, 中心点y, 宽度w, 高度h),所有值均归一化到[0, 1]范围内。
VOC格式
对于同一张图片,相应的.xml文件内容可能是:
<annotation>
<folder>images</folder>
<filename>000001.jpg</filename>
<size>
<width>640</width>
<height>640</height>
<depth>3</depth>
</size>
<object>
<name>Lentinus edodes</name>
<bndbox>
<xmin>180</xmin>
<ymin>200</ymin>
<xmax>300</xmax>
<ymax>400</ymax>
</bndbox>
</object>
</annotation>这里<name>标签指定了类别名称(Lentinus edodes),<bndbox>标签定义了边界框的坐标。
使用说明
-
准备环境:
- 确保安装了必要的软件库以支持所选版本的YOLO模型。例如,对于YOLOv5,可以使用以下命令安装依赖库:
pip install -r requirements.txt
- 确保安装了必要的软件库以支持所选版本的YOLO模型。例如,对于YOLOv5,可以使用以下命令安装依赖库:
-
数据预处理:
- 将图像和标注文件分别放在
images/和labels/目录下。 - 修改
data.yaml文件中的路径以匹配你的数据集位置。 - 如果需要,可以使用脚本将VOC格式的标注文件转换为YOLO格式,或者反之。
- 将图像和标注文件分别放在
-
修改配置文件:
- 更新
data.yaml以反映正确的数据路径。 - 如果使用YOLOv5或其他特定版本的YOLO,还需要更新相应的模型配置文件(如
models/yolov5s.yaml)。
- 更新
-
开始训练:
- 使用提供的训练脚本启动模型训练过程。例如,对于YOLOv5,可以使用以下命令进行训练:
python train.py --img 640 --batch 16 --epochs 100 --data data.yaml --weights yolov5s.pt
- 使用提供的训练脚本启动模型训练过程。例如,对于YOLOv5,可以使用以下命令进行训练:
-
性能评估:
- 训练完成后,使用验证集或测试集对模型进行评估,检查mAP等指标是否达到预期水平。例如,对于YOLOv5,可以使用以下命令进行评估:
python val.py --data data.yaml --weights runs/train/exp/weights/best.pt --img 640
- 训练完成后,使用验证集或测试集对模型进行评估,检查mAP等指标是否达到预期水平。例如,对于YOLOv5,可以使用以下命令进行评估:
-
部署应用:
- 将训练好的模型应用于实际场景中,实现蘑菇自动检测功能。例如,可以使用以下命令进行推理:
python detect.py --source path_to_your_test_images --weights runs/train/exp/weights/best.pt --conf 0.4
- 将训练好的模型应用于实际场景中,实现蘑菇自动检测功能。例如,可以使用以下命令进行推理:
注意事项
- 数据增强:可以通过调整数据增强策略来进一步提高模型性能,例如随机裁剪、旋转、亮度对比度调整等。
- 超参数调整:根据实际情况调整学习率、批大小等超参数,以获得最佳训练效果。
- 硬件要求:建议使用GPU进行训练,以加快训练速度。如果没有足够的计算资源,可以考虑使用云服务提供商的GPU实例。
- 平衡数据:注意数据集中各类别之间的不平衡问题,可以通过过采样、欠采样或使用类别权重等方式来解决。
- 复杂背景:蘑菇可能出现在各种复杂的自然环境中,因此在训练时需要注意模型对这些特性的适应性。
- 细粒度分类:由于蘑菇种类较多且外观相似,模型需要具备较强的区分能力,可以在训练过程中引入更精细的数据增强技术或采用更强的特征提取网络。
通过上述步骤,你可以成功地使用YOLO系列模型进行蘑菇分类检测,并获得高精度的检测结果。该数据集为研究者们提供了一个良好的起点,用于探索如何有效地利用计算机视觉技术解决各种实际问题,特别是在生态研究和食品安全监测领域。
oc yolo