关于MoE推荐博客:
- https://huggingface.co/blog/zh/moe
- https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/06_distributed_training/moe_cn.html
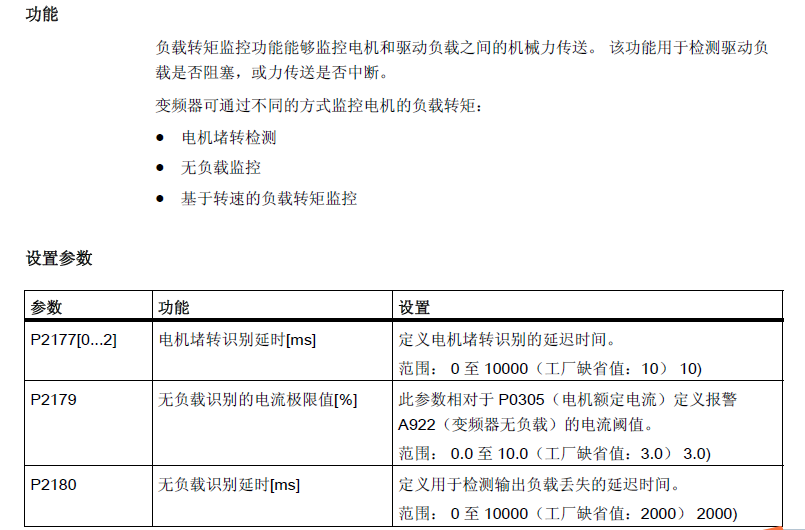
1 概述
这个文档是关于Mixture of Experts (MoE) 的介绍和实现,主要内容如下:
- 背景与动机:
- 上一节课讨论了大规模语言模型(如GPT-3和GPT-4)随着规模的增大,在训练和推理上的一些优劣点。大模型具有更强的容量和更快的收敛速度,但在推理时成本较高。
- 本次课的目标是通过Mixture of Experts (MoE) 模型来减少推理成本,使模型在推理时只激活少量的权重,从而提高效率。
- Mixture of Experts 的定义:
- MoE层包含多个专家(M个专家),通过一个称为"top-k routing"的机制进行专家选择。输入经过一个线性函数的路由器(Router),计算出一个分布,然后用softmax选择前k个最大的值对应的专家进行计算。
- 最后输出是多个专家的加权和,只使用被选择的少数几个专家进行前向计算。
- MoE在Transformer中的使用:
- MoE层可以替换Transformer中的MLP层,典型配置是16个专家,每次通过top-2路由选择激活两个专家。通过这种方法,可以减少模型的活跃参数,提高计算效率。
- 有效参数与总参数:
- 文档区分了总参数(模型所有参数的总数)和有效参数(每个token在推理时实际激活的参数),并指出MoE模型的有效参数仅为总参数的1/11,但性能要比普通的Dense模型高效5倍以上。
- MoE的实际实现与挑战:
- 训练时,针对每个token只计算激活的专家,以避免不必要的计算开销。
- 为了提高训练效率,MoE采用了并行专家模式(Expert Parallel),即每个专家的权重存储在不同的GPU节点上,训练时各节点并行处理激活的专家。
- 负载平衡损失:
- 为了确保模型在训练时的路由和专家分配是均匀的,MoE引入了负载平衡损失(Load-Balancing Loss),以鼓励模型中的专家被均匀使用,避免某些专家过载或闲置。
通过这些内容,文档重点讲解了如何利用MoE架构来提升大规模语言模型的推理效率,同时在实践中通过并行处理和负载平衡损失来应对训练中的挑战。
2 Mixture of Experts (MoE) 详细介绍

1. 背景与动机:
当我们训练大规模模型(如GPT-3或GPT-4)时,模型的规模越大,性能越强。虽然大模型在训练中可以带来更好的表现,但它们在推理(inference)时计算量非常大,导致成本很高。
Mixture of Experts (MoE) 提供了一种解决方案:我们可以通过选择性激活模型中的一部分来应对推理中的计算瓶颈。
2. 什么是Mixture of Experts (MoE):
MoE是一种特殊的神经网络架构,包含多个“专家”(Experts)。每个专家本质上是一个单独的子模型。MoE的关键在于,模型的每次推理只会使用部分的专家,而不是让所有专家都参与计算。这样可以大幅减少推理时的计算成本。
3. MoE的核心思想:
- 稀疏激活(Sparsified Inference):
MoE的主要目的是实现稀疏激活。这意味着在推理时,模型会挑选出少量的专家来处理输入数据,而不是使用所有专家。这大大减少了需要计算的参数数量,从而提高了推理效率。
- 路由器(Router):
当有输入数据(如一个句子)时,模型首先使用一个叫做“路由器”的模块来决定哪些专家最适合处理这部分输入。路由器会根据输入计算出每个专家的相关性,并挑选出top-k(最相关的k个)专家。
4. Mixture of Experts 的实现步骤:
MoE层的具体计算过程可以概括为以下几步:
- 输入处理:
-
假设输入为 x x x,输入的维度为 R d R^d Rd。
-
路由器会计算一个向量 r r r,表示每个专家的权重,这个权重向量的维度是 R M R^M RM,其中 M M M表示专家的数量。
-
通过softmax函数将这些权重归一化,得到一个概率分布向量 s s s,表示每个专家对输入的响应概率。
-
专家选择(Top-k routing):
- 根据 s s s,选择出响应概率最大的k个专家(即top-k专家)。
- 对于选择出的每个专家,会对其权重进一步归一化,以确保选择的专家对输入的贡献比例合适。
-
专家处理:
- 选出的专家会根据输入 x x x 进行计算,每个专家的计算过程通常是一个简单的多层感知机(MLP)。
- 专家们分别处理输入后,将结果加权求和,得到最终输出。
5. 在Transformer中的使用:
MoE可以轻松集成到Transformer模型中,具体方法是用MoE层替代原本的MLP层。传统Transformer的MLP层是固定的神经网络,而使用MoE后,这个MLP层由多个专家组成,并且每次只会选择部分专家来参与计算。
- 传统MLP层:
例如,一个普通的Transformer中,MLP层的计算过程是 d → 4 d → d d \to 4d \to d d→4d→d,即输入经过两层线性变换后输出。
- MoE层替换:
在MoE中,MLP层被多个专家取代(例如M=16个专家),每个专家的结构和普通MLP相同。通过路由机制,模型只会激活其中的2个专家(top-2 routing)。
6. 参数效率:
MoE模型引入了两个概念来描述参数的使用情况:
- 总参数(Total Parameters):
指整个模型中所有专家的参数量,以及模型其他层(如embedding层、attention层)的参数总和。
- 有效参数(Effective Parameters):
在一次推理中,实际激活并使用的参数数量。因为每次只激活少数几个专家,实际使用的参数远小于总参数。MoE的一个重要特性是,模型的有效参数只是总参数的一小部分,但可以实现与全模型相当的性能。
例如,假设模型有32个专家,每次只激活2个专家,那么有效参数大约是总参数的1/11。这意味着虽然模型总参数非常大,但每次推理时只需计算少量的参数,从而大幅提高效率。
7. MoE的训练挑战:
在训练MoE模型时,一个主要挑战是不同的输入(如不同的句子或token)会激活不同的专家。我们希望每个输入只计算被激活的专家,而不是计算所有专家的输出。为了解决这个问题,MoE模型采用了一些高效的技术,如专家并行(Expert Parallel),即每个专家的权重分布在不同的GPU节点上,这样可以并行地进行前向和反向传播计算。
8. 负载平衡与优化:
在训练MoE时,另一个重要的问题是负载平衡。理想情况下,所有专家都应当被均匀使用,以避免某些专家过载或闲置。为此,MoE模型在训练时引入了负载平衡损失(Load Balancing Loss),其目标是让路由器在选择专家时尽可能均匀分布输入给不同的专家。
负载平衡损失的公式为:
Load-Balancing Loss = ∑ i = 1 M f i ⋅ p i \text{Load-Balancing Loss} = \sum_{i=1}^{M} f_i \cdot p_i Load-Balancing Loss=i=1∑Mfi⋅pi
其中:
- f i f_i fi 表示使用第i个专家的token的比例。
- p i p_i pi 表示在路由器中分配给专家i的概率总和。
通过优化这个损失,可以让不同的专家在训练过程中均匀分担任务。
9. MoE的优点:
- 节省推理成本: 每次推理只需要计算部分专家,节省了大量计算资源。
- 可扩展性强: 可以通过增加专家的数量来进一步提升模型的容量,而不会显著增加推理的计算量。
- 高效的参数利用: 使用较少的有效参数实现了高性能,使得大模型在推理时变得更加高效。
总结:
Mixture of Experts (MoE) 是一种可以有效减少推理成本的神经网络架构。通过引入多个专家,并在每次推理时只选择少数专家进行计算,MoE能够在不降低模型性能的前提下,显著提高推理效率。在Transformer等模型中,MoE已被广泛应用,特别适合于需要大规模计算的场景。