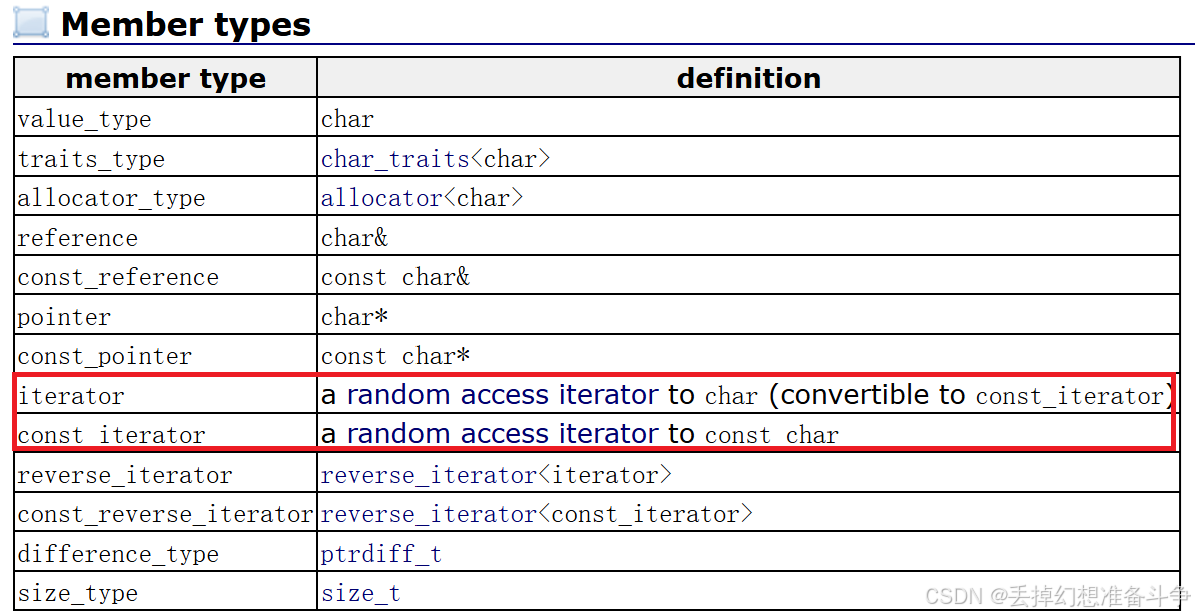
文章目录
- 一、初始HTTP协议
- 二、URL
- 格式
- 网络中怎么通过URL进行定位资源呢?
- 编码和解码
- 三、HTTP的请求格式和响应格式
- HTTP的请求格式
- HTTP的响应格式
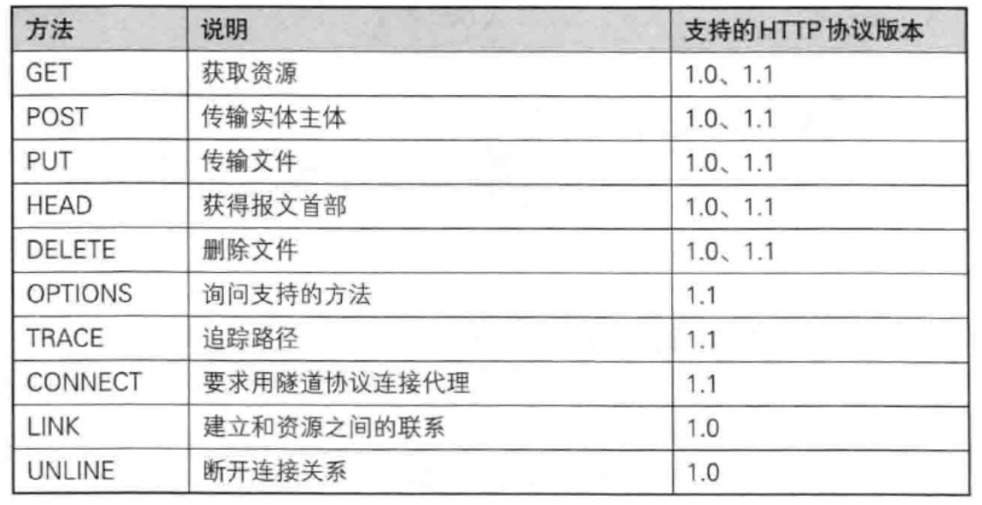
- HTTP的请求方法
- GET方法
- POST方法
- GET Vs Post
- HTTP的封装和分用
- 文件流操作
- 浏览器获得一个完整的网页流程
- HTTP的状态码
- 对3XX状态码的理解
- HTTP常见的Header
- 关于connection报头
一、初始HTTP协议
既然是协议,主要的作用就是为了统一,统一网络中数据的格式,来让所有设备都能够正确的解析,得到正确的数据。
- 超文本传输协议,定义了客户端(浏览器…)与服务器之间如何通信,以及交换和传输超文本(如HTML文档)。
- HTTP是一个无连接,无状态的协议,及每次进行请求都需要建立新的连接,且服务器不会保存客户端的状态信息。
二、URL
- 统一资源定位符。
- 它提供了一种标准化的方式,用于定位网页、图片、视频、文件等各种网络资源。
格式
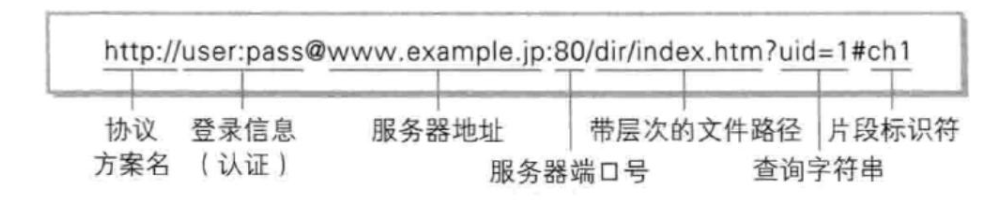

- 超文本:能支持文本、图片、视频和音频等多种媒体类型。
- 资源:HTTP上面获得的图片、视频、音频等。
网络中怎么通过URL进行定位资源呢?
所有的资源都是在服务器端,我们用http协议找到该资源,然后用URL进行标识,然后再通过http协议网络进行返回。
Linux系统中,一切皆文件,资源也是文件。 ===> 我们要找到对应的资源。 ===> 通过文件的路径进行标识。(当前机器上,可以标识文件的唯一性)
编码和解码
在URL中,有一些特殊的字符,如:空格、/、?、%、#等,当URL的内容中含有这些特殊字符的话,如果不进行处理的话,会影响URL的格式,导致解析错误。
所以为了解决这种情况,我们遇到这样的字符需要进行特殊的处理(转义),
转义规则:
将需要转码的字符转为 16 进制, 然后从右到左, 取 4 位(不足 4 位直接处理), 每 2 位做一位, 前面加上%, 编码成%XY 格式。
三、HTTP的请求格式和响应格式
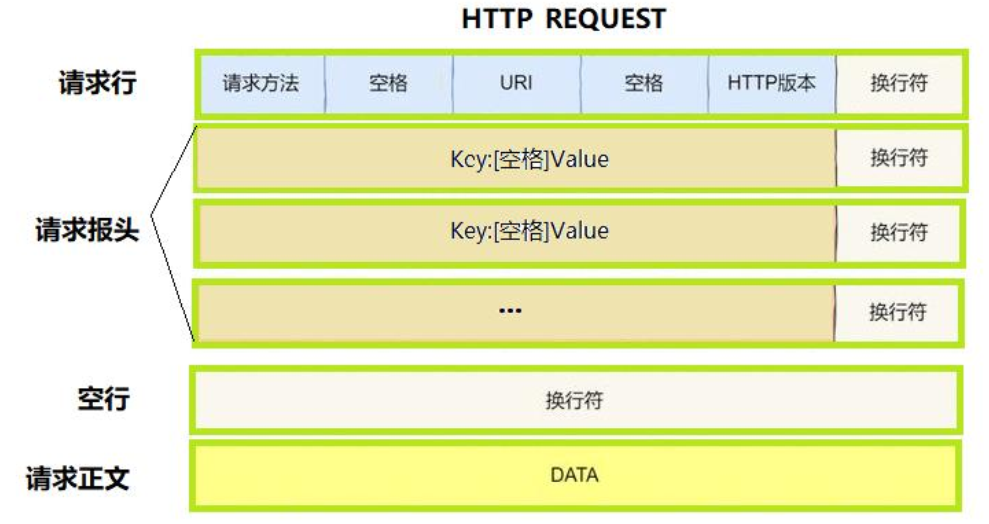
HTTP的请求格式
HTTP的响应格式

HTTP的请求方法
HTTP的请求方法很多,但是最常见的就是GET、POST方法。
GET方法
- 用途:GET方法主要用于请求资源,即向服务器获取指定的数据或资源。
- 参数传递:GET方法的请求参数会附加在URL后面,以键值对的形式呈现,如“?key1=value1&key2=value2”。
- 使用场景:GET方法通常用于搜索、排序、筛选等不涉及数据修改的操作。
POST方法
- 用途:POST方法主要用于向服务器提交数据,请求服务器进行处理,如提交表单或上传文件。
- 参数传递:POST方法的请求参数包含在请求体中,而不是附加在URL后面。
- 使用场景:POST方法通常用于创建新资源、提交表单数据或执行其他涉及数据修改的操作
GET Vs Post
- GET:可以向服务器端发送数据。一般用来获取静态资源,也可以通过url向服务器传递参数。url传参,参数的体量一定不大,正文可以很大。
- POST:可以通过http request的正文来进行参数传递。
- POST方法,比GET方法参数更私密,但是都不安全!为了安全,需要对HTTP的参数部分进行加密(HTTPS)。
- GET,没有请求正文,数据跟url放在一起;POST有请求正文,数据和正文放在一起。
HTTP的封装和分用
- 将报头和有效载荷进行分离(封装):标志是空行\r\n
- 在正文部分一定要有标识内容长度的字段 — 用来对有效载荷进行分离。
url中的第一个‘/’是web根目录,在底层需要在前面进行拼接一个字符串。
但是用户要是访问一个目录,底层不会让其显示出所有的目录,只会显示出首页。所以底层还需要有个一个后缀‘index.html’(需要判断访问的是不是目录)

文件流操作
std::ifstream in(path, std::ios::binary);
if (!in.is_open()) return;
in.seekg(0, in.end); // 移动光标,从文件尾,向后移动0个偏移量
int filesize = in.tellg(); // 告知偏移量
in.seekg(0, in.beg); // 移动光标,从文件头,向后移动0个偏移量
std::string(content);
content.resize(filesize);
in.read((char *)content.c_str(), filesize); // 从流中读取filesizse个字符读取到content
in.close();
浏览器获得一个完整的网页流程
- 发送HTTP请求获取HTML
- 用户在浏览器中输入URL或点击链接。
- 浏览器解析URL,构建HTTP请求,并通过网络发送到服务器。
- 服务器接收请求,处理并返回HTML文档的响应。
- 解析HTML文档
- 浏览器接收HTML文档的响应,并开始解析。
- 解析过程中,浏览器会识别出HTML文档中的标签,如
<img>,<link>,<script>,<iframe>等,这些标签通常包含了对其他资源的引用。- 检测并请求额外资源
- 对于每个识别出的资源引用,浏览器会构建新的HTTP请求来获取这些资源。
- 这些资源可能包括CSS样式表、JavaScript脚本、图片、视频、音频文件等。
- 浏览器会按照HTML文档中的顺序或根据某些策略(如优先级、并行请求数量限制等)来发送这些请求。
- 接收并处理资源
- 服务器接收这些请求,并返回相应的资源。
- 浏览器接收这些资源,并根据需要将其缓存起来。
- 对于CSS和JavaScript资源,浏览器会解析并应用它们,以改变页面的样式或添加交互功能。
- 对于图片和其他媒体资源,浏览器会将其渲染在页面上。
- 渲染页面
- 一旦所有必要的资源都被获取并处理完毕,浏览器就会开始渲染页面。
- 渲染过程包括布局计算、绘制等步骤,最终将页面呈现给用户。
- 后续交互
- 用户可以与页面进行交互,如点击按钮、输入文本等。
- 这些交互可能会触发新的HTTP请求,以获取更多数据或更新页面内容。
HTTP的状态码
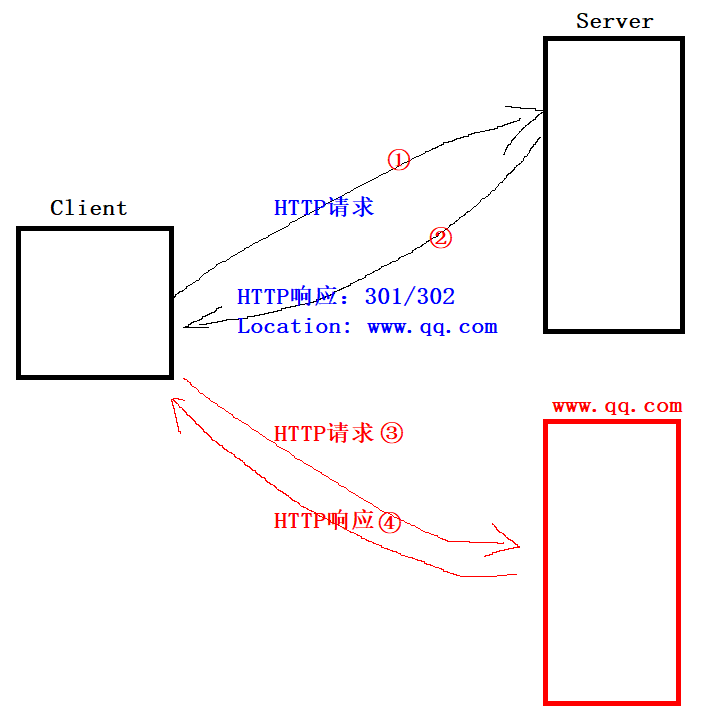
对3XX状态码的理解
- 重定向:客户端访问服务器,服务器给客户端响应一个location地址,客户端转而访问location地址。
- 临时重定向:客户端一直访问服务器,然后服务器给客户端响应。
- 永久重定向:客户端第一次访问服务器,第二次以后,客户端直接访问location。
永久重定向是给搜索引擎看的。
HTTP常见的Header
- Content-Type: 数据类型(text/html 等)
- Content-Length: Body 的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;
- Location: 搭配 3xx 状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
关于connection报头
HTTP 中的 Connection 字段是 HTTP 报文头的一部分,它主要用于控制和管理客户端与服务器之间的连接状态
核心作用
管理持久连接:Connection 字段还用于管理持久连接(也称为长连接)。持久连接允许客户端和服务器在请求/响应完成后不立即关闭 TCP 连接,以便在同一个连接上发送多个请求和接收多个响应。
持久连接(长连接)
HTTP/1.1:在 HTTP/1.1 协议中,默认使用持久连接。当客户端和服务器都不明确指定关闭连接时,连接将保持打开状态,以便后续的请求和响应可以复用同一个连接。
HTTP/1.0:在 HTTP/1.0 协议中,默认连接是非持久的。如果希望在 HTTP/1.0上实现持久连接,需要在请求头中显式设置 Connection: keep-alive。
语法格式
Connection: keep-alive:表示希望保持连接以复用 TCP 连接。
Connection: close:表示请求/响应完成后,应该关闭 TCP 连接。