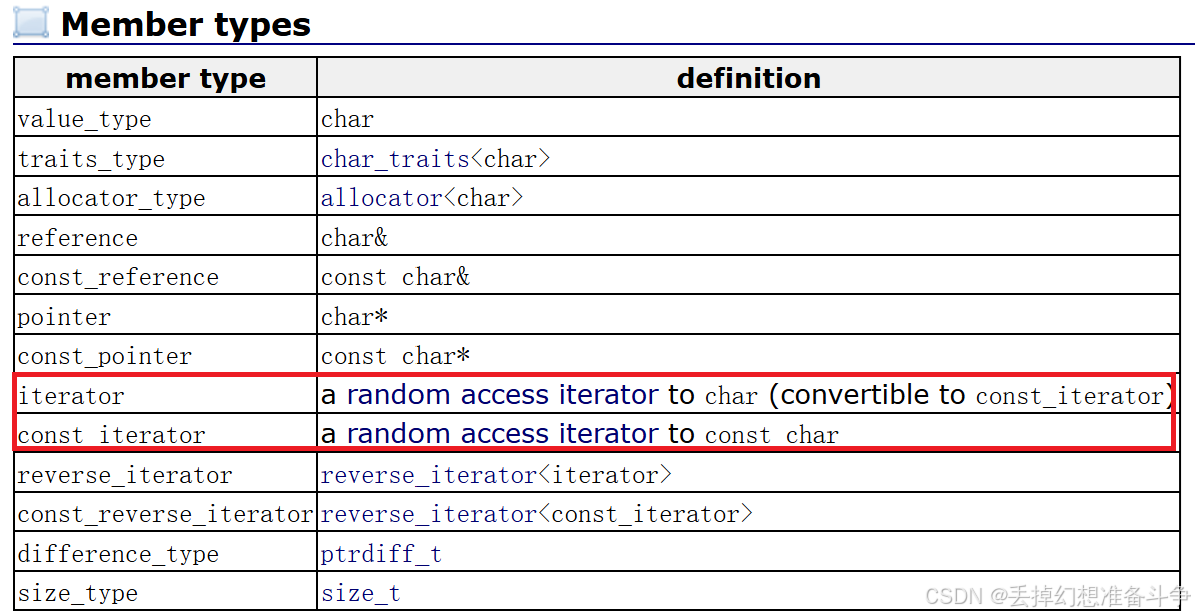
自己刷题缺少分类思想,总是这里刷一道那里刷一道,以后建立几个专辑,然后自己新刷的同类型的题目都会即使更新上。
文章目录
- 690. 员工的重要性
690. 员工的重要性
2024-10-03
题目描述:

我第一次写并没有考虑到dfs,首先使用一个哈希表构建 id 和 对应下属的映射关系。并且将此员工的中重要度加入到下述集合中,这样就不需要单独存储一个 Id 对应的重要度,直接根据map映射关系,根据id获取到对应下属映射,此后从下属映射的List集合的最后一个元素就是此员工对应的重要性。
上述操作完成后,联想到二叉树的层状遍历,直接构建了一个双端队列,队列里面存储员工id,之后循环队列即可完成操作。
详细代码如下:
/*
// Definition for Employee.
class Employee {
public int id;
public int importance;
public List<Integer> subordinates;
};
*/
class Solution {
public int getImportance(List<Employee> employees, int id) {
int ans = 0;
HashMap<Integer, List<Integer>> map = new HashMap<>();
for(Employee employ : employees){
List<Integer> sub = employ.subordinates;
if(sub == null){
sub = new ArrayList<>();
}
sub.add(employ.importance);
map.put(employ.id, sub);
}
Deque<Integer> dq = new ArrayDeque<>();
dq.addLast(id);
while(!dq.isEmpty()){
int size = dq.size();
while(size-- > 0){
int idx = dq.pollFirst();
List<Integer> temp = map.get(idx);
ans += temp.get(temp.size() - 1);
for(int i = 0; i < temp.size() - 1; i++){
dq.addLast(temp.get(i));
}
}
}
return ans;
}
}
这种做法是使用迭代代替递归,参考二叉树的做法,上述也可以改写为递归版本的。这个版本参考了题解(灵茶山艾府)的一个版本,供参考:如果此前做过dfs以及二叉树,直接看下面代码非常易懂了。
class Solution {
public int getImportance(List<Employee> employees, int id) {
Map<Integer, Employee> employeeMap = new HashMap<>(employees.size());
for (Employee e : employees) {
employeeMap.put(e.id, e);
}
return dfs(employeeMap, id);
}
private int dfs(Map<Integer, Employee> employeeMap, int id) {
Employee e = employeeMap.get(id);
int res = e.importance;
for (int subId : e.subordinates) {
res += dfs(employeeMap, subId);
}
return res;
}
}