LLM 在文本生成应用中表现出色,例如具有高理解度和流畅度的聊天和代码完成模型。然而,它们的庞大规模也给推理带来了挑战。基本推理速度很慢,因为 LLM 会逐个生成文本标记,需要对每个下一个标记进行重复调用。随着输入序列的增长,处理时间也会增加。此外,LLM 有数十亿个参数,很难在内存中存储和管理所有这些权重。
为了优化 LLM 推理和服务,有多个框架和软件包,在本博客中,我将使用和比较以下推理引擎:TensorRT-LLM、vLLM、LMDeploy 和 MLC-LLM。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、TensorRT-LLM
TensorRT-LLM 是另一个推理引擎,可加速和优化 NVIDIA GPU 上最新 LLM 的推理性能。 LLM 被编译到 TensorRT Engine 中,然后与 triton 服务器一起部署,以利用推理优化,例如 In-Flight Batching(减少等待时间并允许更高的 GPU 利用率)、分页 KV 缓存、MultiGPU-MultiNode 推理和 FP8 支持。
我们将比较 HF 模型、TensorRT 模型和 TensorRT-INT8 模型(量化)的执行时间、ROUGE 分数、延迟和吞吐量。
你需要为你的 Linux 系统安装 Nvidia-container-toolkit,初始化 Git LFS(以下载 HF 模型),并下载必要的软件包,如下所示:
!curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
!apt-get update
!git clone https://github.com/NVIDIA/TensorRT-LLM/
!apt-get update && apt-get -y install python3.10 python3-pip openmpi-bin libopenmpi-dev
!pip3 install tensorrt_llm -U --pre --extra-index-url https://pypi.nvidia.com
!pip install -r TensorRT-LLM/examples/phi/requirements.txt
!pip install flash_attn pytest
!curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
!apt-get install git-lfs现在检索模型权重:
PHI_PATH="TensorRT-LLM/examples/phi"
!rm -rf $PHI_PATH/7B
!mkdir -p $PHI_PATH/7B && git clone https://huggingface.co/microsoft/Phi-3-small-128k-instruct $PHI_PATH/7B将模型转换为 TensorRT-LLM 检查点格式并从检查点构建 TensorRT-LLM。
!python3 $PHI_PATH/convert_checkpoint.py --model_dir $PHI_PATH/7B/ \
--dtype bfloat16 \
--output_dir $PHI_PATH/7B/trt_ckpt/bf16/1-gpu/
# Build TensorRT-LLM model from checkpoint
!trtllm-build --checkpoint_dir $PHI_PATH/7B/trt_ckpt/bf16/1-gpu/ \
--gemm_plugin bfloat16 \
--output_dir $PHI_PATH/7B/trt_engines/bf16/1-gpu/类似地,现在将 INT8 仅权重量化应用于 HF 模型并将检查点转换为 TensorRT-LLM。
!python3 $PHI_PATH/convert_checkpoint.py --model_dir $PHI_PATH/7B \
--dtype bfloat16 \
--use_weight_only \
--output_dir $PHI_PATH/7B/trt_ckpt/int8_weight_only/1-gpu/
!trtllm-build --checkpoint_dir $PHI_PATH/7B/trt_ckpt/int8_weight_only/1-gpu/ \
--gemm_plugin bfloat16 \
--output_dir $PHI_PATH/7B/trt_engines/int8_weight_only/1-gpu/现在在总结任务上测试基础 phi3 和两个 TensorRT 模型:
%%capture phi_hf_results
# Huggingface
!time python3 $PHI_PATH/../summarize.py --test_hf \
--hf_model_dir $PHI_PATH/7B/ \
--data_type bf16 \
--engine_dir $PHI_PATH/7B/trt_engines/bf16/1-gpu/
%%capture phi_trt_results
# TensorRT-LLM
!time python3 $PHI_PATH/../summarize.py --test_trt_llm \
--hf_model_dir $PHI_PATH/7B/ \
--data_type bf16 \
--engine_dir $PHI_PATH/7B/trt_engines/bf16/1-gpu/
%%capture phi_int8_results
# TensorRT-LLM (INT8)
!time python3 $PHI_PATH/../summarize.py --test_trt_llm \
--hf_model_dir $PHI_PATH/7B/ \
--data_type bf16 \
--engine_dir $PHI_PATH/7B/trt_engines/int8_weight_only/1-gpu/现在,在捕获结果后,你可以解析输出并绘制它以比较所有模型的执行时间、ROUGE 分数、延迟和吞吐量。

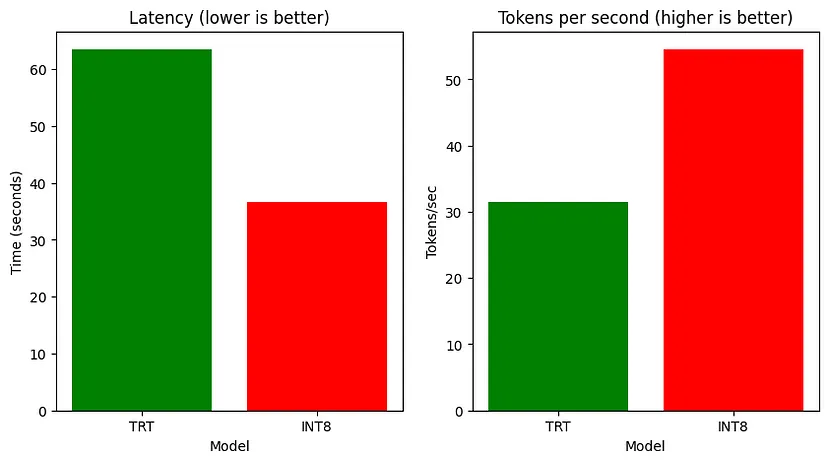
延迟和吞吐量的比较
2、vLLM
vLLM 提供 LLM 推理和服务,具有 SOTA 吞吐量、分页注意、连续批处理、量化(GPTQ、AWQ、FP8)和优化的 CUDA 内核。
让我们评估 microsoft/Phi3-mini-4k-instruct 的吞吐量和延迟。首先设置依赖项并导入库。
!pip install -q vllm
!git clone https://github.com/vllm-project/vllm.git
!pip install -q datasets
!pip install transformers scipy
from vllm import LLM, SamplingParams
from datasets import load_dataset
import time
from tqdm import tqdm
from transformers import AutoTokenizer现在让我们加载模型并在数据集的一小部分上生成其输出。
dataset = load_dataset("akemiH/MedQA-Reason", split="train").select(range(10))
prompts = []
for sample in dataset:
prompts.append(sample)
sampling_params = SamplingParams(max_tokens=524)
llm = LLM(model="microsoft/Phi-3-mini-4k-instruct", trust_remote_code=True)
def generate_with_time(prompt):
start = time.time()
outputs = llm.generate(prompt, sampling_params)
taken = time.time() - start
generated_text = outputs[0].outputs[0].text
return generated_text, taken
generated_text = []
time_taken = 0
for sample in tqdm(prompts):
text, taken = generate_with_time(sample)
time_taken += taken
generated_text.append(text)
# Tokenize the outputs and calculate the throughput
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
token = 1
for sample in generated_text:
tokens = tokenizer(sample)
tok = len(tokens.input_ids)
token += tok
print(token)
print("tok/s", token // time_taken)![]()
我们还通过 ShareGPT 数据集上的 vLLM 对模型的性能进行基准测试
!wget https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
%cd vllm
!python benchmarks/benchmark_throughput.py --backend vllm --dataset ../ShareGPT_V3_unfiltered_cleaned_split.json --model microsoft/Phi-3-mini-4k-instruct --tokenizer microsoft/Phi-3-mini-4k-instruct --num-prompts=1000
3、LMDeploy
此软件包还允许压缩、部署和服务 LLM,同时提供高效推理(持久批处理、块 KV 缓存、动态拆分和融合、张量并行、高性能 CUDA 内核)、有效量化(4 位推理性能比 FP16 高 2.4 倍)、轻松的分发服务器(跨多台机器和卡部署多模型服务)和交互式推理模式(记住对话历史并避免重复处理历史会话)。此外,它还允许分析令牌延迟和吞吐量、请求吞吐量、API 服务器和 triton 推理服务器性能。
安装依赖项并导入包:
!pip install -q lmdeploy
!pip install nest_asyncio
import nest_asyncio
nest_asyncio.apply()!git clone --depth=1 https://github.com/InternLM/lmdeploy
%cd lmdeploy/benchmarkLMdeploy 开发了两个推理引擎 TurboMind 和 PyTorch。
让我们在 microsoft/Phi3-mini-128k-instruct 上分析一下 PyTorch 引擎。
!python3 profile_generation.py microsoft/Phi-3-mini-128k-instruct --backend pytorch它在多轮中对引擎进行分析,并报告每轮的令牌延迟和吞吐量。

Pytorch 引擎配置文件,用于标记延迟和吞吐量
4、MLC-LLM
MLC-LLM 提供高性能部署和推理引擎,称为 MLCEngine。
让我们安装依赖项,包括使用 conda 设置依赖项和创建 conda 环境。然后克隆 git 存储库并进行配置。
conda activate your-environment
python -m pip install --pre -U -f https://mlc.ai/wheels mlc-llm-nightly-cu121 mlc-ai-nightly-cu121
conda env remove -n mlc-chat-venv
conda create -n mlc-chat-venv -c conda-forge \
"cmake>=3.24" \
rust \
git \
python=3.11
conda activate mlc-chat-venv
git clone --recursive https://github.com/mlc-ai/mlc-llm.git && cd mlc-llm/
mkdir -p build && cd build
python ../cmake/gen_cmake_config.py
cmake .. && cmake --build . --parallel $(nproc) && cd ..
set(USE_FLASHINFER ON)
conda activate your-own-env
cd mlc-llm/python
pip install -e .要使用 MLC LLM 运行模型,我们需要将模型权重转换为 MLC 格式。通过 Git LFS 下载 HF 模型,然后转换权重。
mlc_llm convert_weight ./dist/models/Phi-3-small-128k-instruct/ \
--quantization q0f16 \
--model-type "phi3" \
-o ./dist/Phi-3-small-128k-instruct-q0f16-MLC现在将你的 MLC 格式模型加载到 MLC 引擎中:
from mlc_llm import MLCEngine
# Create engine
model = "HF://mlc-ai/Phi-3-mini-128k-instruct-q0f16-MLC"
engine = MLCEngine(model)
# Now let’s calculate throughput
import time
from transformers import AutoTokenizer
start = time.time()
response = engine.chat.completions.create(
messages=[{"role": "user", "content": "What is the Machine Learning?"}],
model=model,
stream=False,
)
taken = time.time() - start
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-128k-instruct")
print("tok/s", 82 // taken)![]()
5、结束语
TensorRT INT8 模型在推理速度方面优于 HF 模型和常规 TensorRT,而常规 TensorRT 模型在总结任务上表现更好,在三个模型中 ROUGE 得分最高。LMDeploy 在 A100 上提供的请求吞吐量比 vLLM 高出 1.8 倍。
原文链接:4个顶级LLM推理引擎 - BimAnt