背景
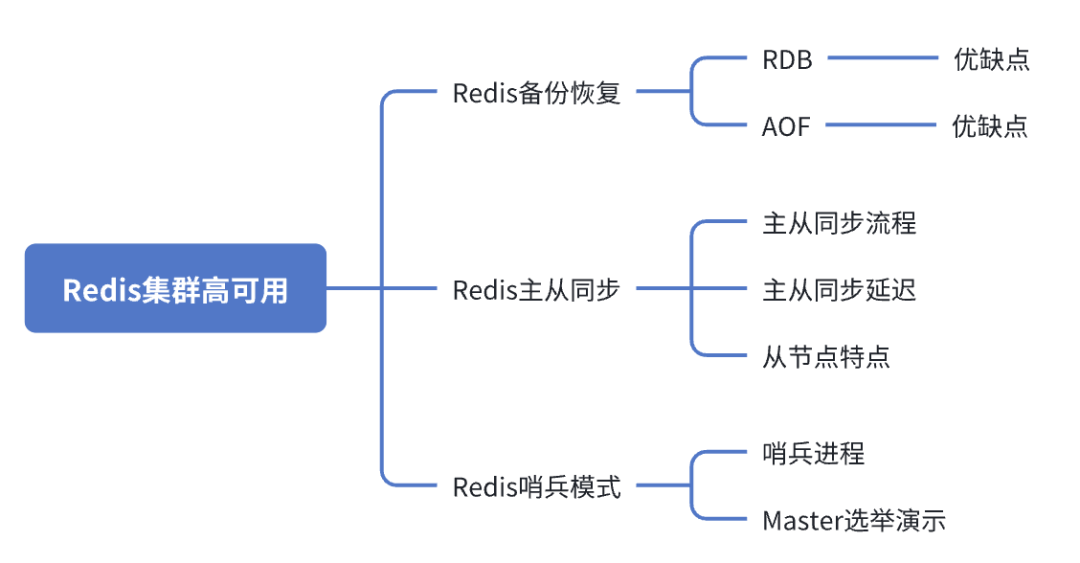
目前实现Redis高可用的模式主要有三种:主从模式、哨兵模式、集群模式。今天我们先来聊一下主从模式。
Redis 提供的主从模式,是通过复制的方式,将主服务器上的Redis的数据同步复制一份到从 Redis 服务器,这种做法很常见,MySQL通过binlog进行的主从复制也是这么做的。
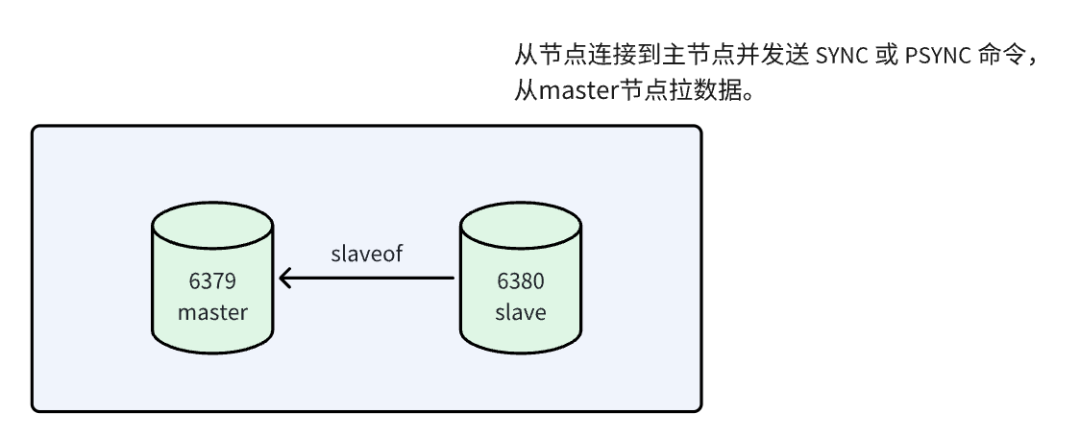
主节点的Redis我们称之为master,从节点的Redis我们称之为slave,主从复制为单向复制,只能由主到从,不能由从到主。
可以有多个从节点,比如1主3从甚至n从,从节点的多少根据实际的业务需求来判断。
搭建Redis主从复制模式
Redis的主从架构中,主节点的数据更新会自动被复制到从节点,确保数据的一致性。主从复制的开启,在从节点配置和发起即可,不需要我们在主节点做任何事情。
可以通过 replicaof(Redis 5.0 之前使用 slaveof)命令形成主库和从库的关系。
主从复制原理
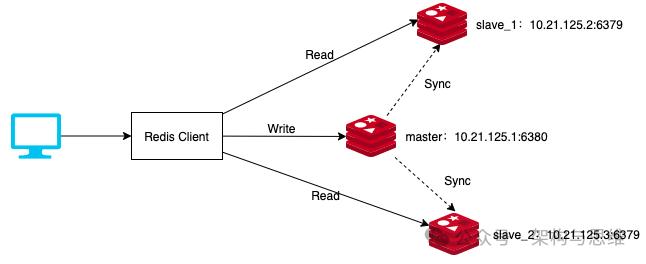
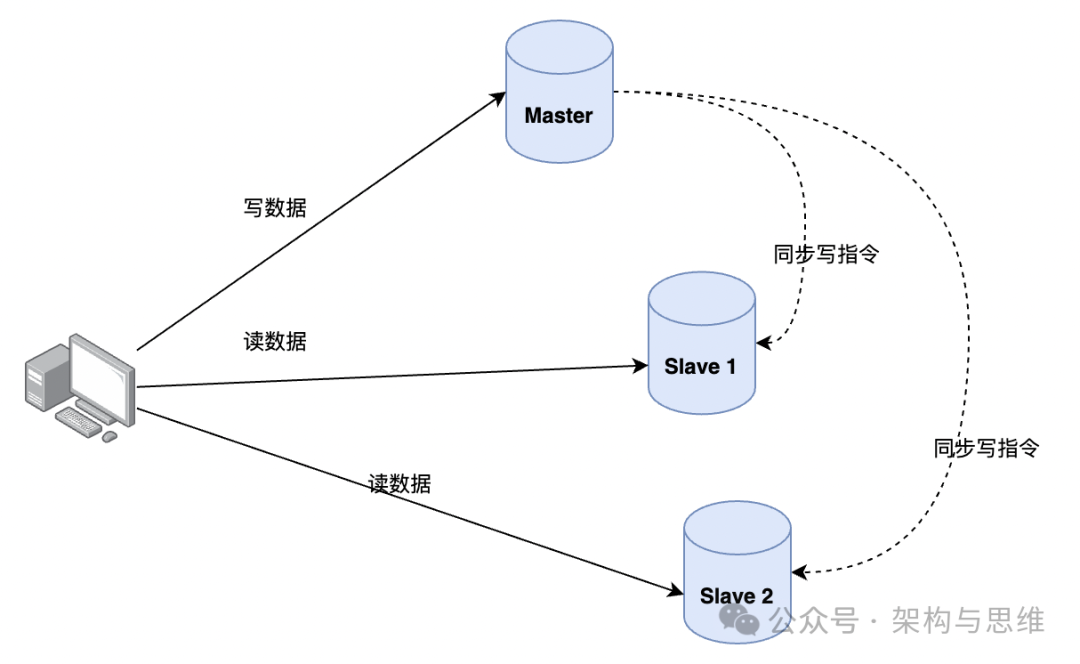
主从库模式开启之后,应用层面采用读写分离,所有数据的写操作只会在主库上进行,而读操作基本会在从库上进行(特殊情况下部分读业务允许走主库)。
主从会保持最终一致性:主库有了数据更新之后,会立即同步给从库,来保证主从库的数据的一致的。
主从架构如何保证数据一致性
为了保证主服务器Redis的数据和从服务器Redis的数据的一致性,也为了分担访问压力,均衡负载,应用层面一般采取读写分离的模式。
读操作:主、从库都可以执行,一般是在从库上读数据,对实时性和准确性有100%高真要求的部分业务,在谨慎评估之后也可以读主库,前提是不能给Master带来高压力和风险
主从同步实践
配置&启动master
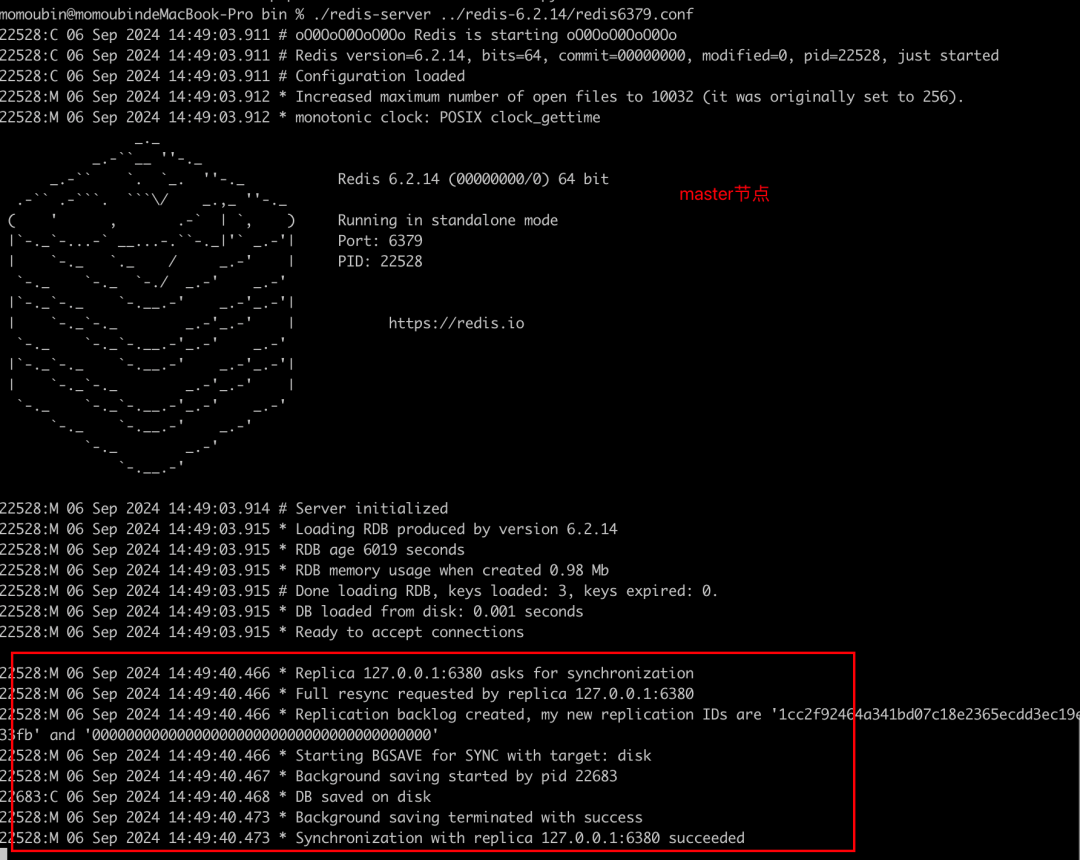
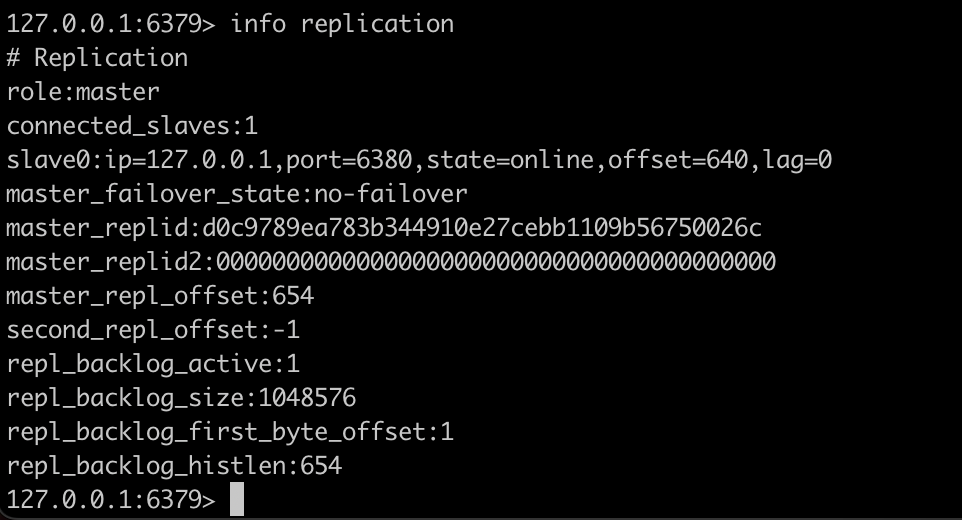
查看主节点信息
配置&启动slave
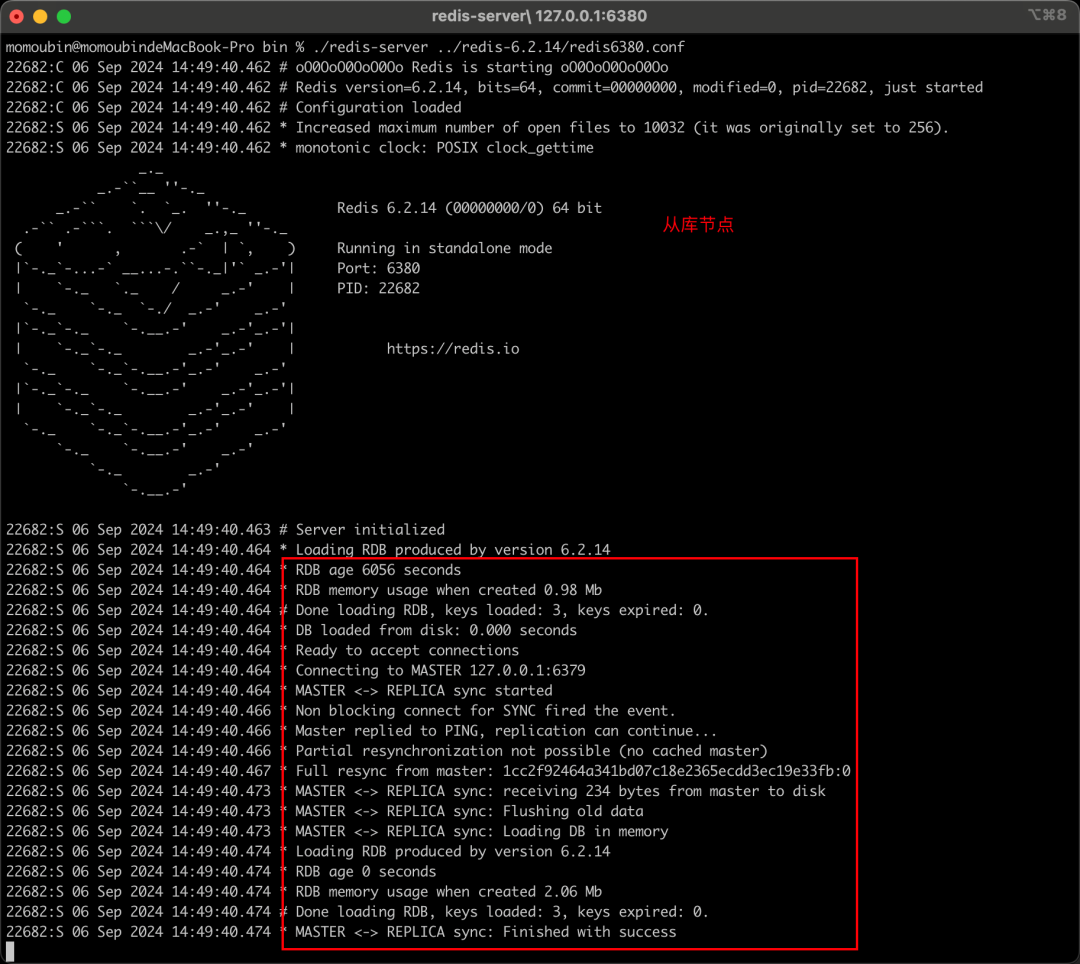
查看从节点信息
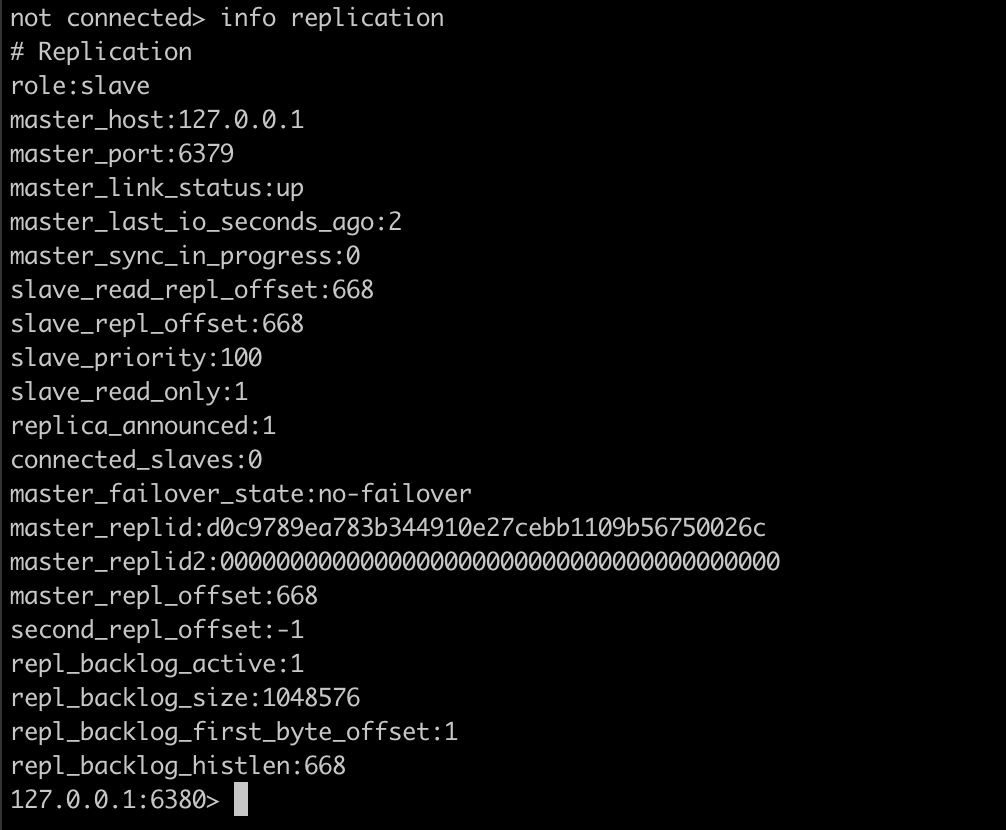
从节点不能写入,只能读出

验证数据同步
redis-cli -h 127.0.0.1 -p 6379 // master
redis-cli -h 127.0.0.1 -p 6380 //slave
结论
默认是走RDB复制模式,PSYNC 命令是Redis中用于从节点与主节点之间数据同步的关键命令。
主从复制的好处:
-
数据冗余,实现数据的热备份
-
故障恢复,避免单点故障带来的服务不可用
-
读写分离,负载均衡。主节点负载读写,从节点负责读,提高服务器并发量
-
高可用基础,是哨兵机制和集群实现的基础
复制原理
Redis 的主从复制机制均采用异步复制,我们也称为乐观复制,这种复制方式意味着不能完全保证主库和从库数据的实时一致性。
Redis的主从复制机制可以根据不同的业务场景可以采用不同的应对方式。下面是一些主要场景及其对应的实现方案:
-
首次配置完成主从库之后的全量复制:在从库第一次连接到主库时,将采用psync复制方式进行全量复制。这意味着从库会从头开始复制主库中的全部数据。主从正常运行期间,准实时同步:在正常运行状态下,从库通过读取主库的缓冲区来进行增量复制。这个过程涉及复制主库上发生的新的数据变更。从库第二次启动(异常或主从网络断开后恢复):Append增量数据 + 准实时同步将通过读取主库的缓冲区进行部分复制。这种方式能够快速同步中断期间发生的数据变更,而不会对主库造成重大影响。
数据同步
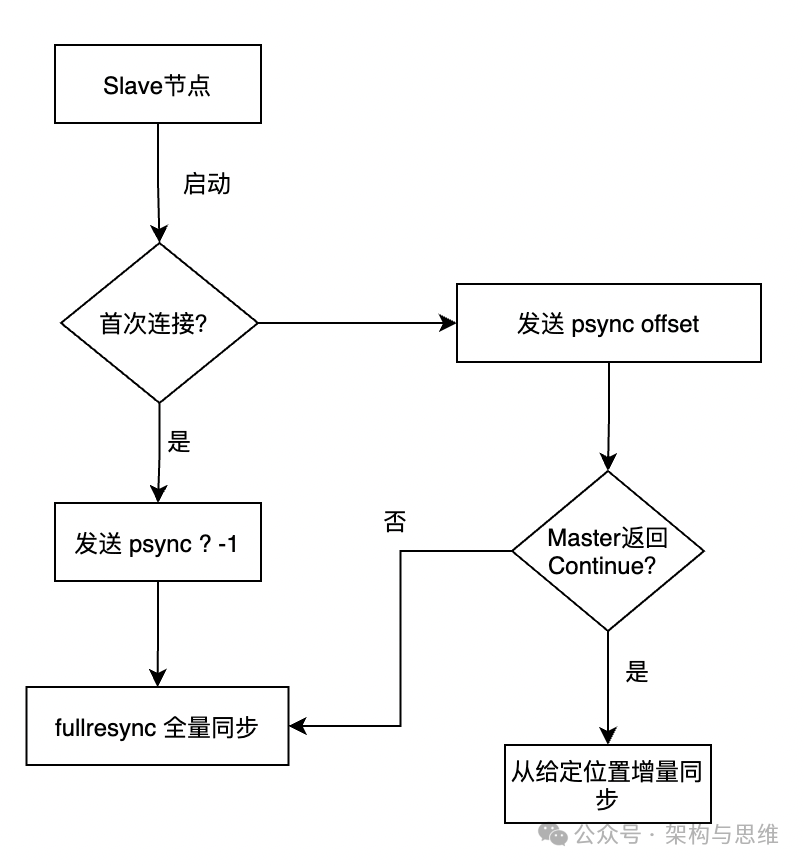
在主从服务器建立连接确认各自身份之后,就开始数据同步,从服务器向主服务器发送PSYNC命令,执行同步操作,并把自己的数据库状态更新至主服务器的数据库状态
Redis的主从同步分为:完整重同步(full resynchronization)和部分重同步(partial resynchronization)
全量同步
有两种情况下是完整重同步,一是slave连接上master第一次复制的时候;二是如果当主从断线,重新连接复制的时候有可能是完整重同步,这个在后面说
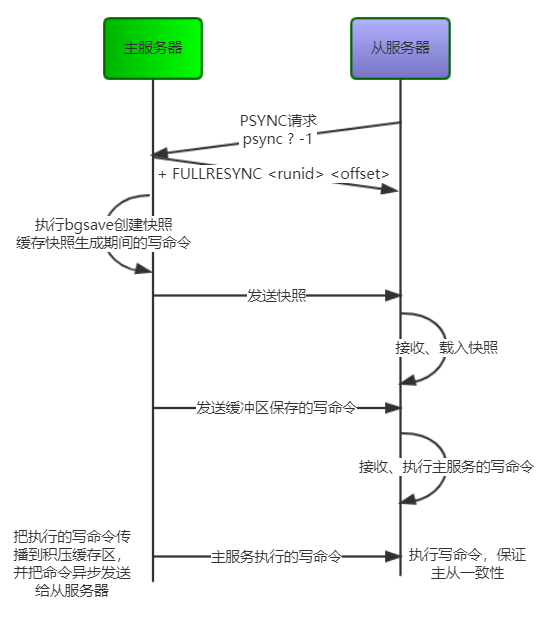
下面是完整重同步的步骤
-
从服务器连接主服务器,发送SYNC命令
-
主服务器接收到SYNC命名后,开始执行
bgsave命令生成RDB文件并使用缓冲区记录此后执行的所有写命令 -
主服务器
basave执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令 -
从服务器收到快照文件后丢弃所有旧数据,载入收到的快照
-
主服务器快照发送完毕后,开始向从服务器发送缓冲区中的写命令
-
从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令
增量同步
部分重同步是用于处理断线后重复制的情况,先介绍几个用于部分重同步的部分
-
runid(replication ID),主服务器运行id,Redis实例在启动时,随机生成一个长度40的唯一字符串来标识当前节点 -
offset,复制偏移量。主服务器和从服务器各自维护一个复制偏移量,记录传输的字节数。当主节点向从节点发送N个字节数据时,主节点的offset增加N,从节点收到主节点传来的N个字节数据时,从节点的offset增加N -
replication backlog buffer,复制积压缓冲区。是一个固定长度的FIFO队列,大小由配置参数repl-backlog-size指定,默认大小1MB。需要注意的是该缓冲区由master维护并且有且只有一个,所有slave共享此缓冲区,其作用在于备份最近主库发送给从库的数据
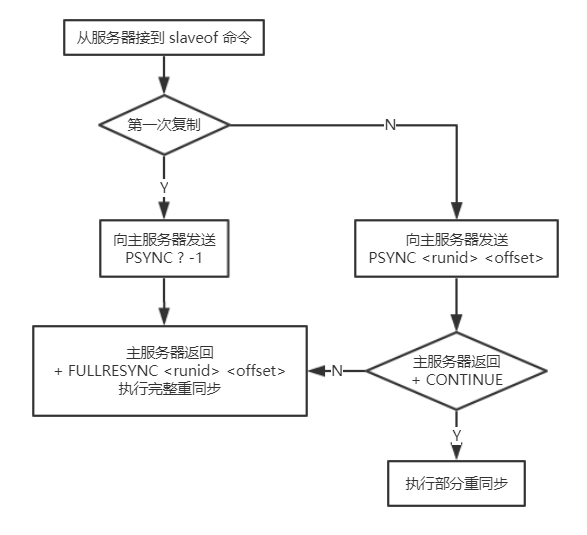
当slave连接到master,会执行PSYNC <runid> <offset>发送记录旧的master的runid(replication ID)和偏移量offset,这样master能够只发送slave所缺的增量部分。但是如果master的复制积压缓存区没有足够的命令记录,或者slave传的runid(replication ID)不对,就会进行完整重同步,即slave会获得一个完整的数据集副本
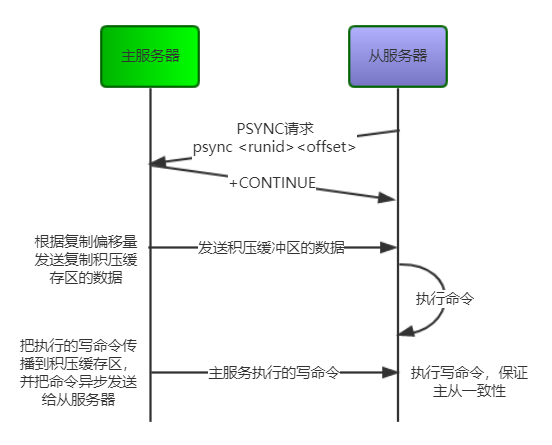
PSYNC命令执行完整重同步和部分重同步的流程图
真实部署架构

总结
-
主从复制的作用一个是为分担读写压力,均衡负载,另一个是为了保证部分实例宕机之后服务的持续可用性,所以Redis演变出主从架构和读写分离。
-
主从复制的步骤包括:建立连接的阶段、数据同步的阶段、基于长连接的命令传播阶段。
-
数据同步可以分为全量复制和部分复制,全量复制一般为第一次全量或者长时间主从连接断开。
-
主从模式是比较低级的可用性优化,要做到故障自动转移,异常预警,高保活,还需要更为复杂的哨兵或者集群模式,这个后面我们继续介绍。
其他文章
Kafka消息堆积问题排查
基于SpringMVC的API灰度方案
理解到位:灾备和只读数据库
SQL治理经验谈:索引覆盖
Mybatis链路分析:JDK动态代理和责任链模式的应用
大模型安装部署、测试、接入SpringCloud应用体系
Mybatis插件-租户ID的注入&拦截应用