大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。
作为开源AI模型领域的领头羊,Meta的Llama系列模型在持续迭代,不断进化。就在近日的Meta Connect 2024大会上,Meta推出了新版本的Llama模型——Llama 3.2。

省流版摘要
-
Llama 3.2 正式发布:包括小型和中型视觉大模型(11B和90B),以及轻量级的文本模型(1B和3B),适用于边缘设备和移动设备,并提供预训练和指令微调版本。
-
轻量模型表现突出:1B和3B模型支持128K的上下文长度,在设备端的任务(如摘要生成、指令执行、文本改写)中表现卓越,适配高通、联发科硬件,并针对Arm处理器进行了优化。
-
视觉模型超越封闭模型:
Llama 3.2的11B和90B视觉模型可以直接替代对应文本模型,在图像理解任务上超过了Claude 3 Haiku等封闭模型,支持本地微调和部署。 -
Llama Stack 分布方案:首次推出官方的Llama Stack分布,简化了在单节点、本地部署、云端和设备端使用Llama模型的工作流程,支持RAG(检索增强生成)等集成安全的应用。
-
广泛合作伙伴支持:与AWS、Databricks、戴尔科技等合作伙伴协作,为企业客户构建了Llama Stack分布方案。设备端通过PyTorch ExecuTorch实现,单节点通过Ollama支持。
-
坚持开放创新:Llama 继续在开放性、可修改性和成本效益方面引领行业,帮助更多人通过生成式AI实现创意突破。
Llama 3.2模型现已可在llama.com和Hugging Face下载,并支持多家合作平台即时开发。
为什么推出Llama 3.2
Llama 3.2的推出,是对开发者需求的积极响应。Llama 3.1系列模型发布至今已有两个月,其中最引人注目的是405B模型,它是首个开源的前沿级AI模型。然而,Llama 3.1系列尽管性能卓越,但在实际应用中,搭建这些模型往往需要大量的计算资源和专业知识。如何能够在有限的资源条件下,依然享受Llama模型带来的先进功能?Llama 3.2在这样的背景下应运而生。
Llama 3.2的核心目标是让更广泛的开发者,尤其是在边缘设备和移动设备上构建应用的开发者,能够利用轻量且高效的模型进行开发。通过引入1B和3B的轻量级文本模型,以及11B和90B的视觉大模型,Llama 3.2为设备端的应用提供支持。此外,Llama 3.2还进一步优化了对高通、联发科等硬件的支持,并针对Arm处理器进行了精细优化,确保在边缘设备上的性能表现出色。
Llama 3.2核心能力
Llama 3.2系列中的两款大模型——11B和90B,专为图像推理任务而设计,支持多种视觉理解应用场景,如文档级别的图表和图像解析、图像标注以及基于自然语言描述的视觉定位任务。例如,可以通过问题询问上一年度哪个月企业的销售表现最佳,Llama 3.2会根据提供的图表快速推理并给出答案。在另一个场景中,模型还可以通过分析地图,回答某条远足路线何时变得陡峭或特定路径的距离。Llama 3.2模型不仅能够从图像中提取细节,还能理解场景的整体内容,生成适合的图像说明,使得视觉与语言之间的鸿沟得以弥合。
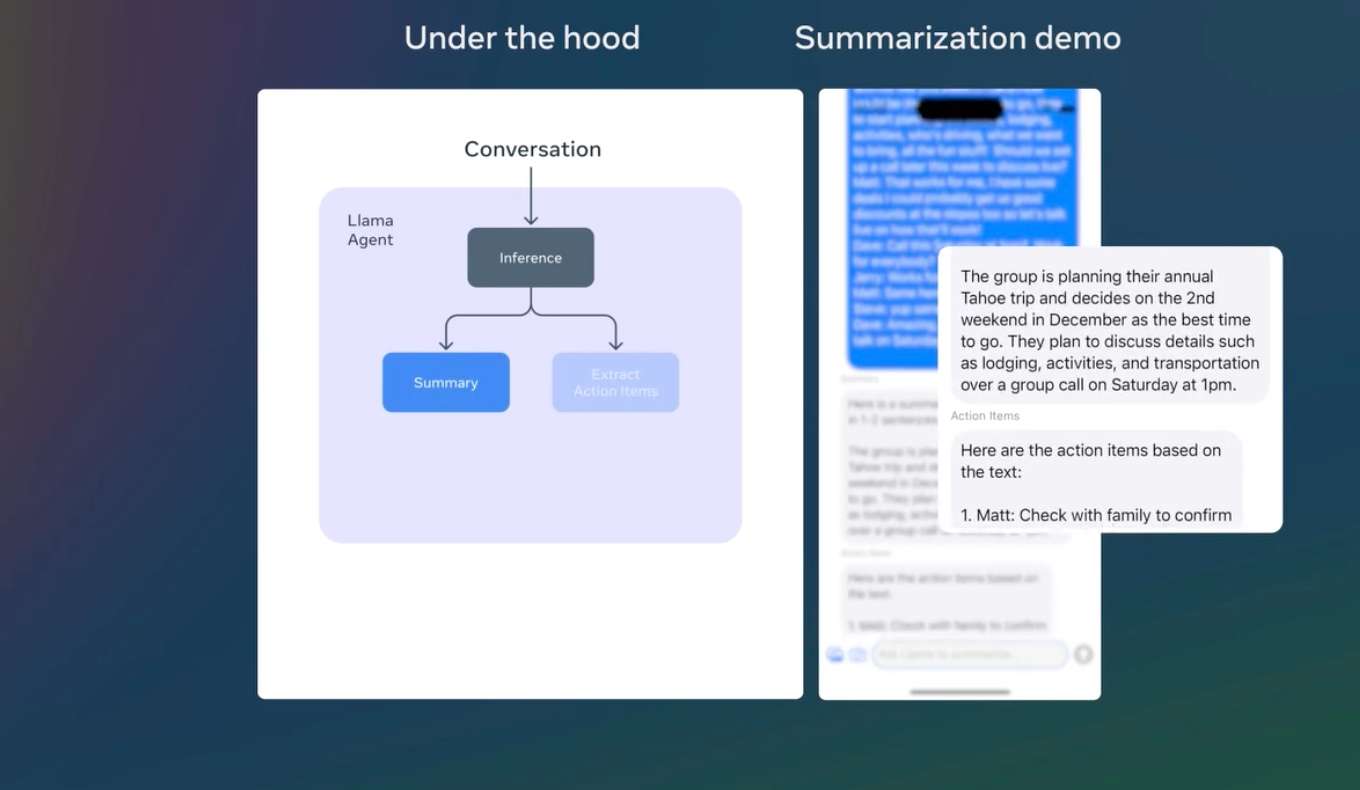
轻量级的1B和3B模型则在多语言文本生成和工具调用能力上表现出色。这些模型能够帮助开发者构建个性化的本地化智能应用,确保数据隐私不离开设备本身。比如,一个这样的应用可以帮助用户总结最近收到的10条消息,提取其中的待办事项,并直接通过工具调用发送会议跟进邀请。
在本地运行这些模型具有两个显著优势。首先,提示词和模型响应的处理速度更快,因为所有操作都在本地进行。其次,本地化运行能够保持数据隐私,避免诸如消息或日历等信息上传至云端,从而确保应用的隐私性更高。由于处理均在本地完成,开发者和用户可以完全掌控哪些查询留在设备上处理,哪些查询可能需要更大的模型在云端完成。
Llama 3.2模型评估
经过评估,Llama 3.2视觉模型在图像识别和多种视觉理解任务上,表现与当前领先的基础模型Claude 3 Haiku和GPT-4o mini相当。尤其是3B模型,在指令执行、摘要生成、提示词改写和工具使用等任务上,超越了Gemma 2 2.6B和Phi 3.5-mini等竞争对手;而1B模型在多项任务中与Gemma系列的表现不相上下。
Llama 3.2模型的性能评估基于超过150个基准数据集,这些数据集涵盖了多种语言和任务类型。对于视觉大语言模型,主要评估了其在图像理解和视觉推理任务中的表现,结果显示Llama 3.2在这些关键任务上具备领先优势。
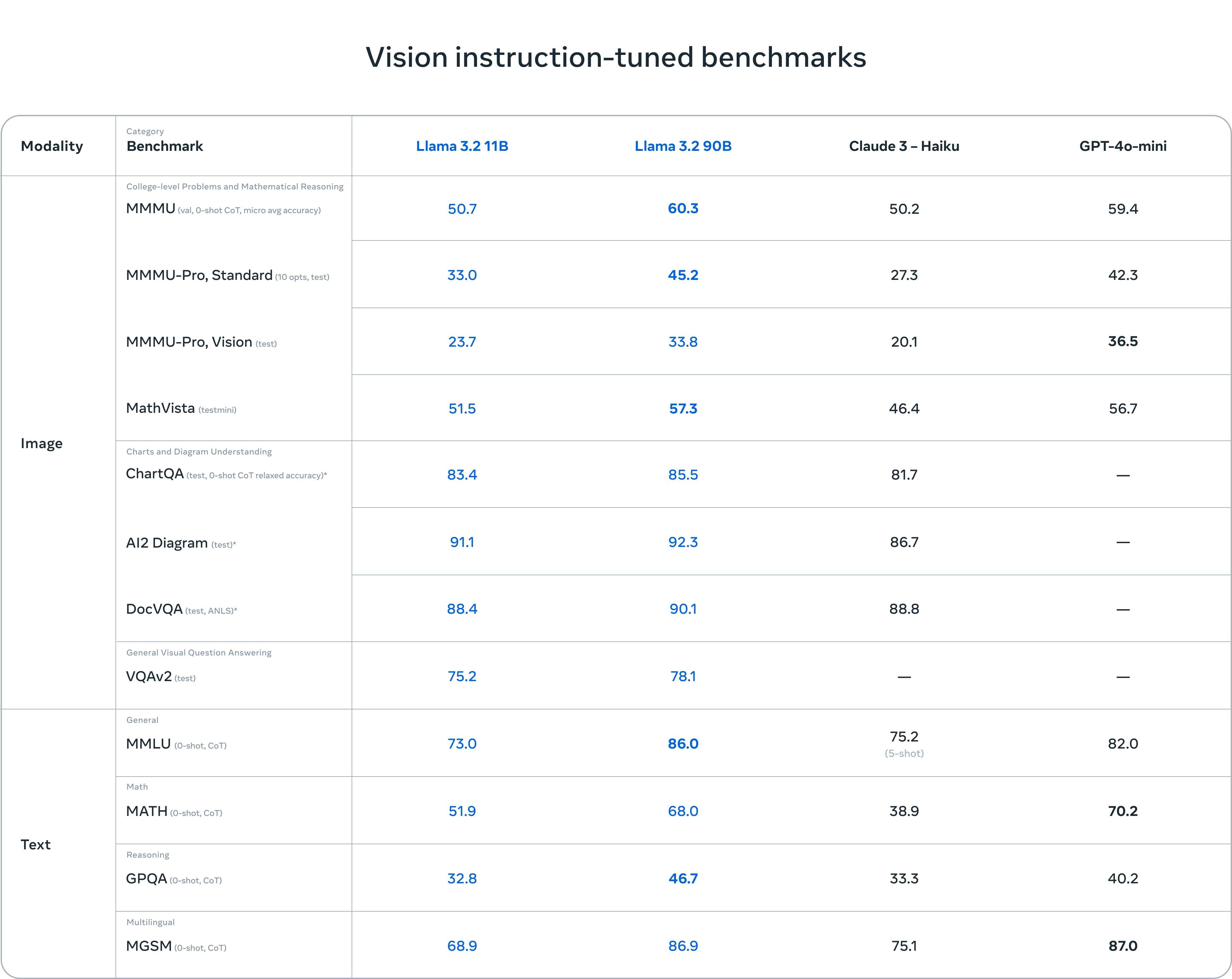
视觉指令微调基准测试
在视觉指令微调基准测试(Vision Instruction-Tuned Benchmarks)中,Llama 3.2的11B和90B模型表现出色,尤其在视觉推理、图表理解和问答任务上,整体表现优于Claude 3 - Haiku,甚至在某些任务上超越了GPT-4o-mini。
-
图像推理任务:
-
在复杂图表理解任务(如
ChartQA和AI2 Diagram)上,Llama 3.2的90B模型得分最高,超越了其他模型。 -
在
DocVQA(文档视觉问答)任务中,Llama 3.2的表现与Claude 3 - Haiku接近,但仍然稍有领先。
-
-
数学与推理任务:
-
Llama 3.2在MATH和MMMU任务上的表现强劲,尤其是90B模型,远远超越了Claude 3 - Haiku。
-
-
文本任务:
-
Llama 3.2在GPQA(推理)和MMLU(通用推理)等文本任务中的表现同样很好,特别是90B模型在多语言推理任务(MGSM)上表现优异。
-
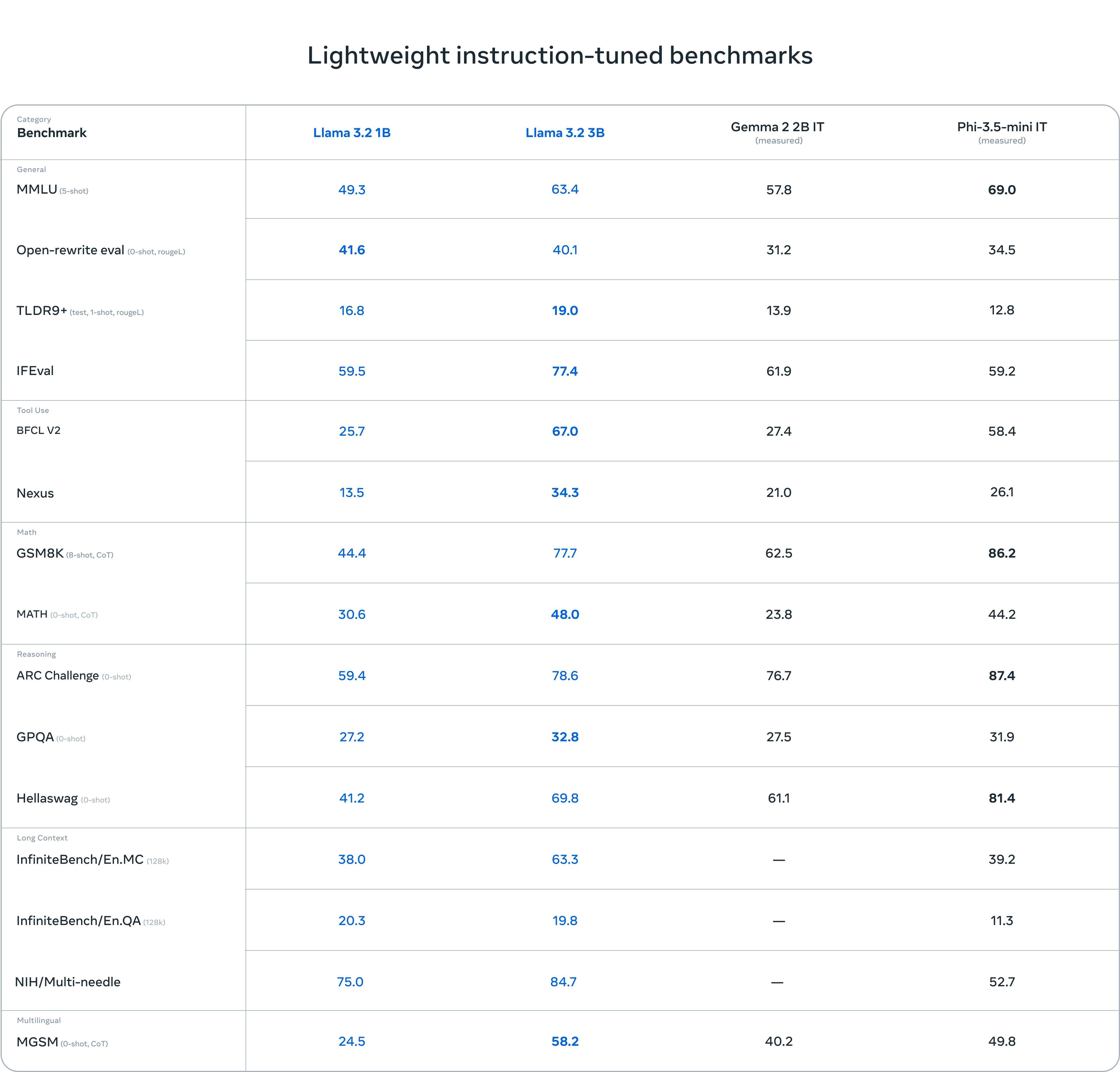
轻量级指令微调基准测试
在轻量级指令微调基准测试(Lightweight Instruction-Tuned Benchmarks)中,Llama 3.2系列的1B和3B模型在多项任务中表现优异,尤其在工具使用、数学推理和多语言推理等方面展现了较强的竞争力。其中,Llama 3.2 3B在BFCL V2工具使用任务中以67.0分领先,在多语言推理任务MGSM中,Llama 3.2 3B取得了58.2分,显示出其在设备端应用中的强大能力。
-
通用任务:
-
在
MMLU(5-shot)任务中,Llama 3.2 3B以63.4分表现出色,超越了Gemma 2 2B IT,但略低于Phi-3.5-mini IT的69.0分。 -
在
Open-rewrite eval任务中,Llama 3.2系列模型整体领先,Llama 3.2 1B和Llama 3.2 3B分别得分41.6和40.1,优于其他对比模型。
-
-
工具使用:
-
Llama 3.2 3B在BFCL V2工具使用任务中表现优异,以67.0分大幅领先于其他模型,显示出其在调用工具任务中的强大能力。
-
-
数学推理:
-
在
GSM8K任务中,Llama 3.2 3B表现优异,获得77.7分,超过了Gemma 2 2B IT的62.5分,但Phi-3.5-mini IT依然以86.2分在该任务上领先。 -
MATH任务中,Llama 3.2 3B取得48.0分,同样远超Gemma 2 2B IT和Phi-3.5-mini IT。
-
-
推理能力:
-
Llama 3.2 3B在ARC Challenge推理任务中取得78.6分,略胜于Gemma 2 2B IT,但仍低于Phi-3.5-mini IT的87.4分。
-
-
多语言任务:
-
在
MGSM(0-shot)任务中,Llama 3.2 3B的58.2分显著超越了其他模型,表明其在多语言推理任务上的卓越表现。
-
视觉模型
Llama 3.2的11B和90B模型是首次支持视觉任务的Llama模型。为支持图像输入,这些模型采用了全新的架构,具备图像推理能力。模型通过引入一组专门训练的适配器权重,将预训练的图像编码器与预训练的语言模型进行集成。这些适配器由一系列交叉注意力层组成,将图像编码器的表示传递给语言模型,确保图像和语言的表示能够很好地对齐。
在训练过程中,首先使用包含大量噪声的图像-文本对数据进行预训练,然后再通过中等规模的高质量、领域内和知识增强的图像-文本对数据进行进一步训练。在适配器训练阶段,仅更新图像编码器的参数,而保留语言模型的参数不变,以确保其原有的文本处理能力不受影响,使得开发者能够将其作为Llama 3.1模型的直接替代方案。
在模型的后期训练中,采用了与文本模型相似的调优方法,结合多轮的监督微调、拒绝采样和直接偏好优化。通过使用生成的数据,结合领域内的图像进行问题和答案的生成,确保微调数据的高质量,并引入安全缓解数据,确保模型在保持有效性的同时具备高安全性。
最终,Llama 3.2的视觉模型能够同时处理图像和文本提示,具备深度理解和推理能力。
轻量级模型
与Llama 3.1一样,Llama 3.2借助强大的教师模型(Teacher Model),成功打造出性能优异的轻量级模型。通过剪枝(Pruning)和知识蒸馏(Knowledge Distillation)两种技术手段,Llama 3.2的1B和3B模型首次实现了在设备端高效运行的能力,成为轻量化Llama模型中的佼佼者。
剪枝技术的应用使得模型体积得以缩减,但依然保留了尽可能多的知识和性能。通过结构化剪枝,对Llama 3.1 8B模型进行精细化调整,系统性地移除部分网络节点,并调整权重和梯度的大小,从而生成一个更小、更高效的模型,同时保持原网络的性能。
知识蒸馏则通过将较大网络的知识传递给较小网络,从而提升小模型的性能。在Llama 3.2的1B和3B模型中,结合了来自Llama 3.1 8B和70B模型的logits,将这些输出作为预训练阶段的目标进行训练,随后在剪枝后通过蒸馏技术恢复模型的性能。
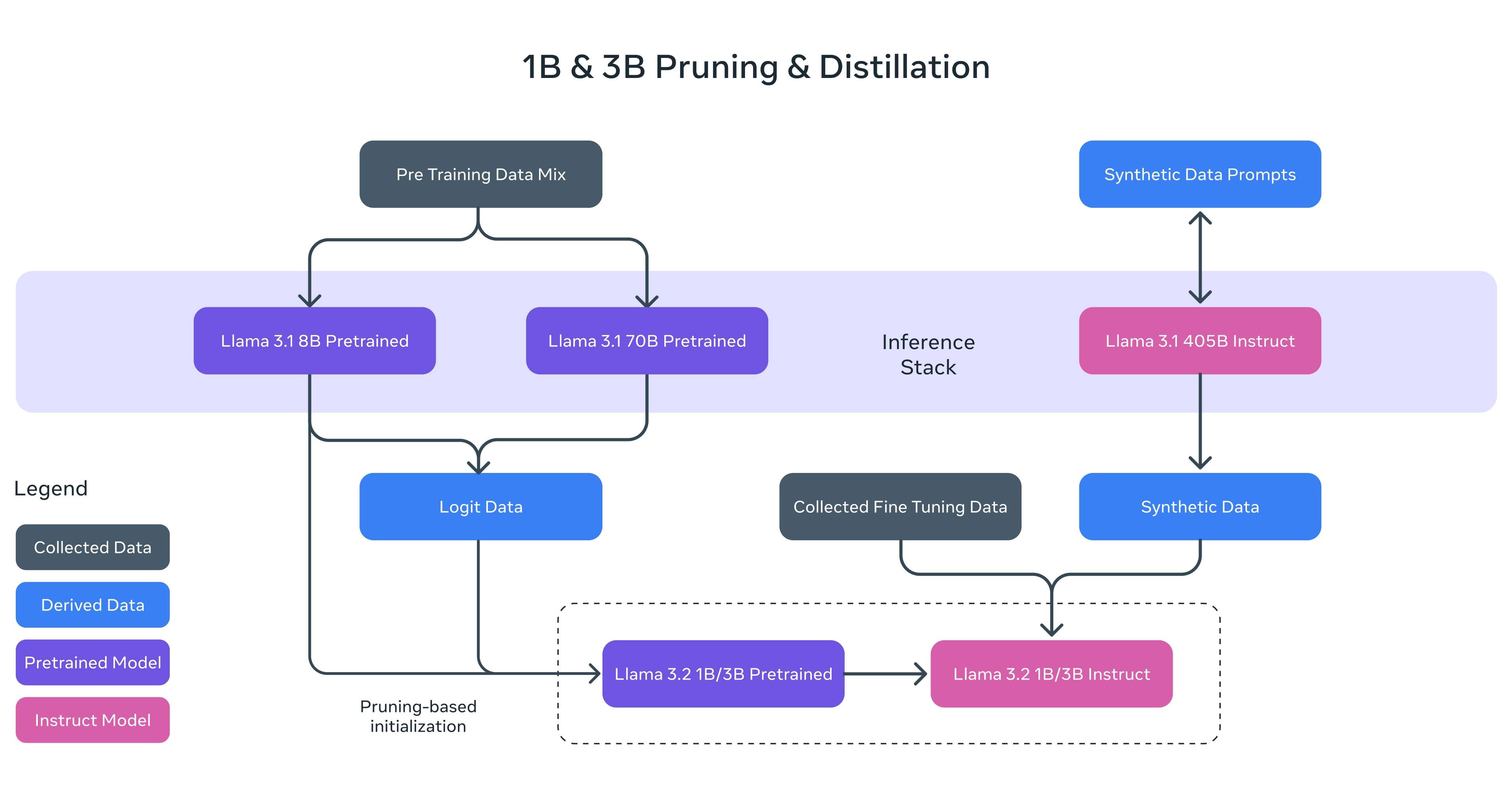
在后期训练中,采用与Llama 3.1类似的流程,通过多轮对预训练模型的对齐,包括监督微调、拒绝采样和直接偏好优化,生成最终的对话模型。此外,支持的上下文长度扩展至128K tokens,同时保证了与预训练模型相同的质量水平。为了确保数据质量,还使用了合成数据生成技术,经过精细处理和过滤,以优化模型在摘要生成、文本改写、指令执行、语言推理和工具使用等多项能力上的表现。
为进一步推动轻量模型在移动设备上的应用,Llama 3.2与高通、联发科以及Arm紧密合作,这三家公司在全球移动设备处理器市场占据重要地位,确保模型能在99%的移动设备上高效运行。发布的模型权重基于BFloat16数值,量化变体也正在积极研发中,未来将进一步提升运行速度。
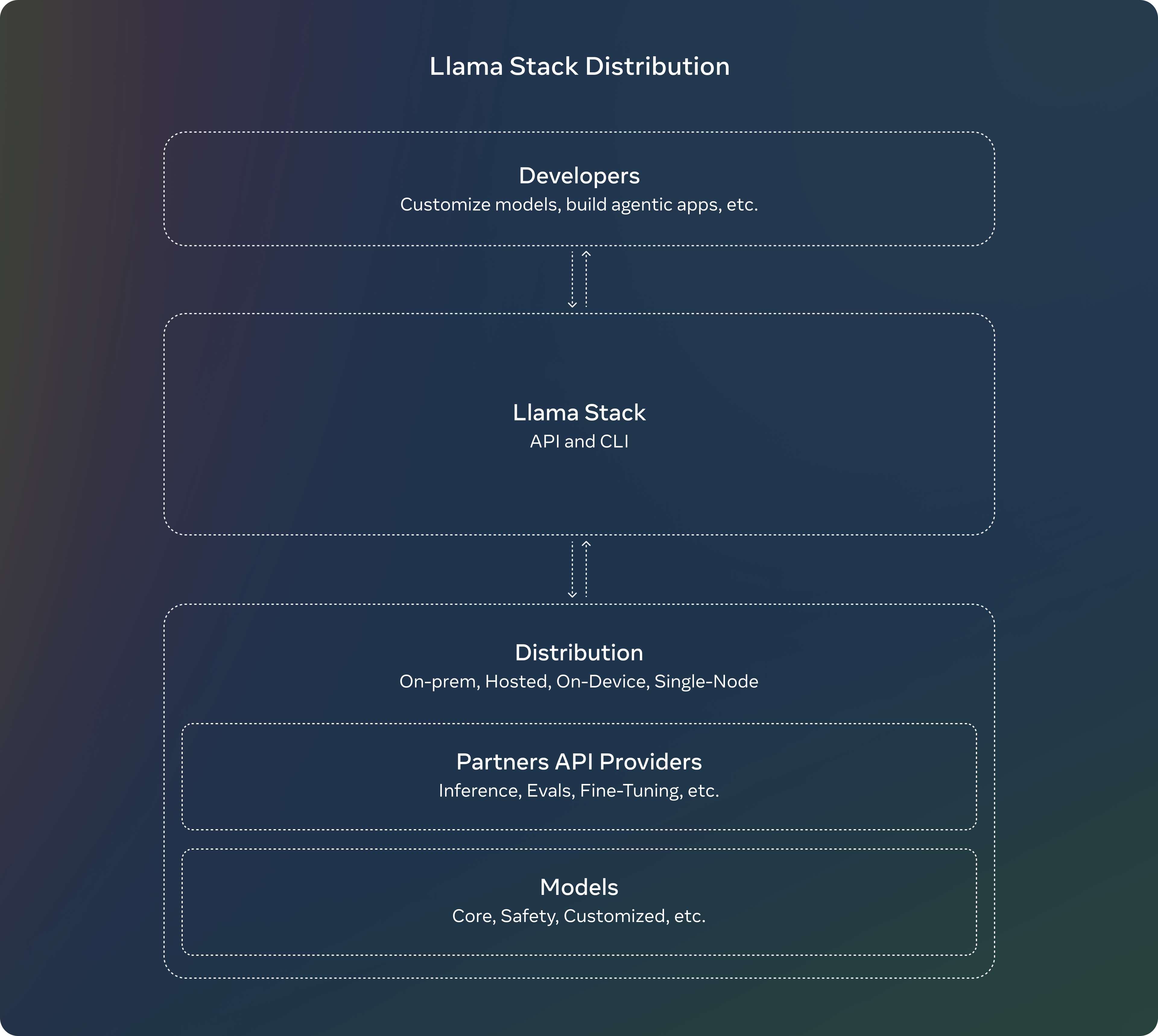
Llama Stack 分布方案
Meta于7月发布了关于Llama Stack API的意见征集,旨在提供一个标准化的接口,支持对Llama模型进行微调、生成合成数据等工具链组件的自定义化。
经过数月,Llama团队将该API从概念化变为实际应用,开发了API的参考实现,涵盖了推理、工具调用和检索增强生成(RAG)等功能。最终推出了Llama Stack分布方案,通过将多个API服务提供商打包为一个单一的端点,简化了开发者在不同环境中使用Llama模型的体验,无论是本地部署、云端还是设备端。
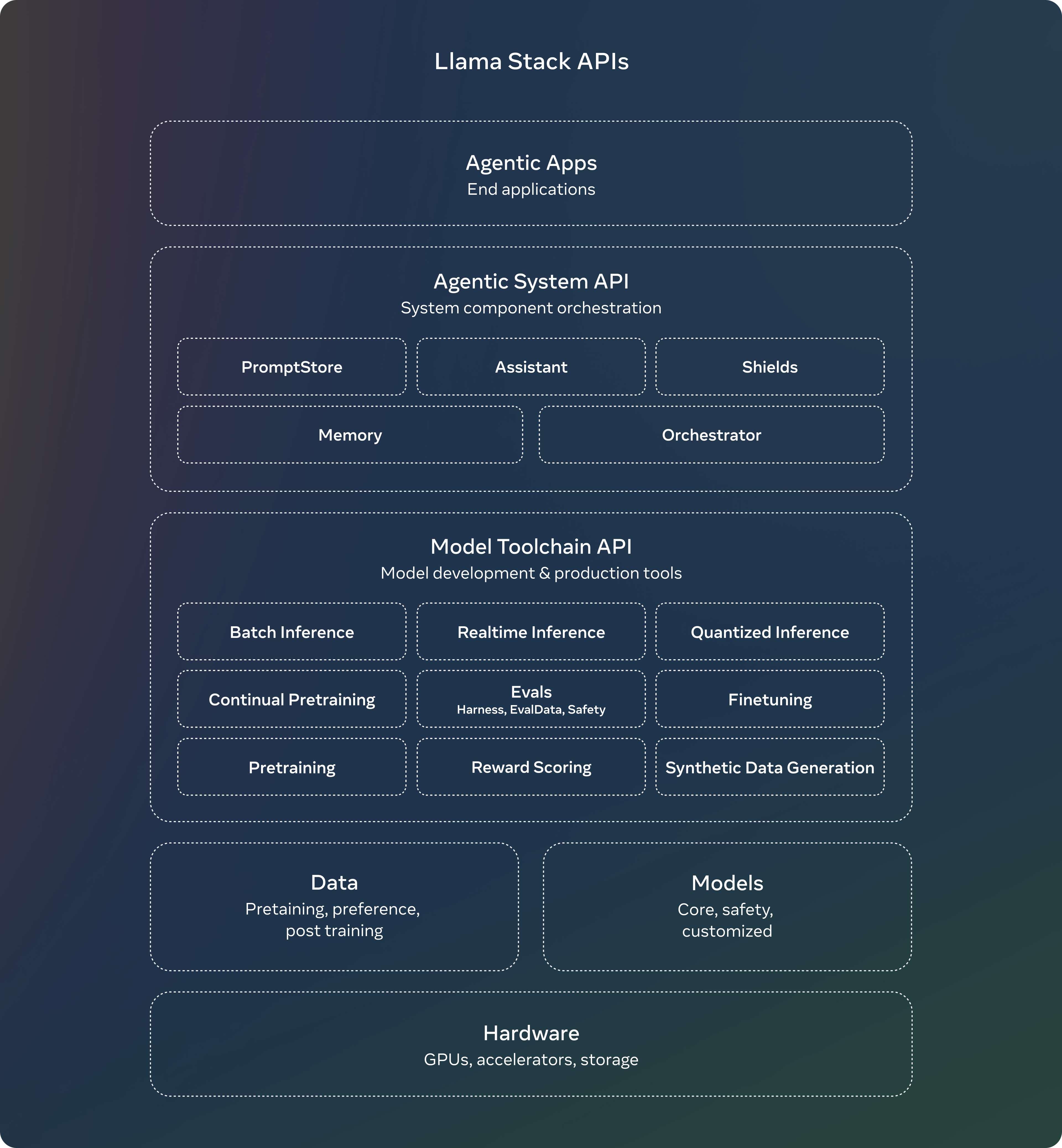
Llama Stack分布方案的完整发布内容包括:
-
Llama CLI:命令行工具,用于构建、配置和运行Llama Stack分布方案
-
多种语言的客户端代码支持,包括Python、Node、Kotlin和Swift
-
适用于Llama Stack分布服务器和代理API服务提供商的Docker容器
- 多种分布方案支持
-
单节点Llama Stack分布(通过Meta内部实现和Ollama)
-
云端分布方案(支持AWS、Databricks、Fireworks和Together)
-
设备端分布方案(通过PyTorch ExecuTorch在iOS上实现)
-
本地部署分布方案(戴尔支持的On-prem)
-
如何使用Llama 3.2
-
Hugging Face:
Llama 3.2的各类模型,包括轻量级的1B和3B文本模型,以及支持图像处理的11B和90B视觉模型,均可在Hugging Face上下载和使用。这是开发者进行模型微调、实验以及集成到不同应用中的一个常见平台。 -
Amazon Bedrock 和 SageMaker:
Llama 3.2模型在Amazon Bedrock和SageMaker上支持云端部署。用户可以通过这些平台进行模型推理,并支持多区域推理端点,方便开发者进行程序化调用。此外,Amazon SageMaker JumpStart还提供了微调和模型部署的能力,使开发者能够定制Llama 3.2模型以满足特定应用需求。 -
Azure AI:
Llama 3.2模型在Microsoft Azure AI平台上也可以使用,提供了无服务器的API部署方案。Azure上不仅支持Llama模型的标准推理,还集成了内容安全功能,帮助开发者在构建AI应用时遵守合规要求。
精选推荐
都读到这里了,点个赞鼓励一下吧,小手一赞,年薪百万!😊👍👍👍。关注我,AI之路不迷路,原创技术文章第一时间推送🤖。