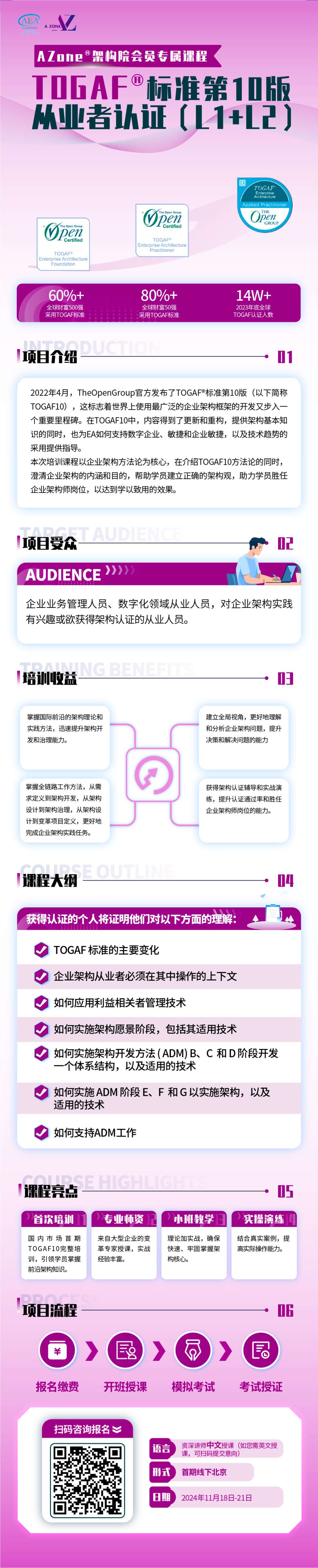
四,MyBatis-Plus 当中的主键策略和分页插件的(详细实操使用)
文章目录
- 四,MyBatis-Plus 当中的主键策略和分页插件的(详细实操使用)
- 1. 主键策略
- 1.1 主键生成策略介绍
- 2. 准备工作:
- 2.1 AUTO 策略
- 2.2 INPUT 策略
- 2.3 ASSIGN_ID 策略
- 2.3.1 雪花算法
- 2.4 NONE 策略
- 2.5 ASSIGN_UUID 策略
- 3. 分页
- 3.1 分页插件
- 3.2 自定义分页插件
- 4. 总结:
- 5. 最后:
1. 主键策略
1.1 主键生成策略介绍
首先大家先要指定什么是主键,主键的作用就是唯一标识,我们可以通过这个唯一标识来定位到这条数据。
当然对于表数据中的主键,我们可以自己设计生成规则,生成主键。但是在更多的场景中,没有特殊要求的话,我们每次自己手动生成的比较麻烦,我们可以借助框架提供好的主键生成策略,来生成主键。这样比较方便快捷。
在MyBatis Plus 中提供了一个注解,是 @TeableId 。

该注解提供了各种的主键生成策略,我们可以通过使用该注解来对于新增的数据指定主键生成策略。那么在以后新增数据的时候,数据就会按照我们指定的主键生成策略来生成对应的主键。
2. 准备工作:
特别说明:
需要导入的相关
jar依赖。如下:

<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.5.3</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.rainbowsea</groupId> <artifactId>mp03</artifactId> <version>0.0.1-SNAPSHOT</version> <name>mp03</name> <description>mp03</description> <url/> <licenses> <license/> </licenses> <developers> <developer/> </developers> <scm> <connection/> <developerConnection/> <tag/> <url/> </scm> <properties> <java.version>8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!-- spring boot web 依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- mysql 驱动依赖--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <!-- lombok 的依赖--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <!-- druid--> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.2.8</version> </dependency> <!-- mybatis-plus 的依赖--> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.4.3</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> </plugins> </build> <repositories> <repository> <id>spring-snapshots</id> <name>Spring Snapshots</name> <url>https://repo.spring.io/snapshot</url> <releases> <enabled>false</enabled> </releases> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>spring-snapshots</id> <name>Spring Snapshots</name> <url>https://repo.spring.io/snapshot</url> <releases> <enabled>false</enabled> </releases> </pluginRepository> </pluginRepositories> </project>对应的 application.yaml 文件的配置的编写:

spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/mybatisplus?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false username: root password: MySQL123 main: banner-mode: off #关闭 spring boot 在命令行当中的图标显示 mybatis-plus: global-config: banner: false # 关闭 mybatis-plus 在命令行当中的图标显示 db-config: table-prefix: rainbowsea_ # 还可以通过统一添加前缀的方式: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 开启 Log 日志信息打印 map-underscore-to-camel-case: true # 开启驼峰,下划线映射规则
编写对应的 DataSource 数据源,这里我们通过配置类的方式,将Spring Boot 的数据库连接池换为 Druid 数据库连接池。如下:

package com.rainbowsea.config;
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
@Configuration // 标注配置类
public class DruidDataSourceConfig {
@Bean
@ConfigurationProperties(value = "spring.datasource")
public DataSource getDataSource() {
DruidDataSource druidDataSource = new DruidDataSource();
return druidDataSource;
}
}
运行测试,看看是否换为了 Druid 数据库连接池。

编写场景启动器:

2.1 AUTO 策略
该策略为跟随数据库表的主键递增策略,前提是数据库表的主键要设置为自增。


实体类添加注解,指定主键生成策略。
运行测试:

import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.rainbowsea.bean.User;
import com.rainbowsea.mapper.UserMapper;
//import com.rainbowsea.mapper.UserMapper2;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
@SpringBootTest
public class PrimaryKeyTest {
@Autowired
//@Resource
private UserMapper userMapper;
@Test
void primary() {
User user = new User();
user.setName("张三");
user.setAge(19);
user.setEmail("mary@rainbowsea.com");
userMapper.insert(user);
}
}

2.2 INPUT 策略
该策略表示,必须由我们手动的插入id,否则无法添加数据
// 该策略表示,必须由我们手动的插入id,否则无法添加数据,前提是:需要去掉数据表的自增策略


import com.baomidou.mybatisplus.annotation.FieldFill;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableLogic;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.annotation.Version;
import com.baomidou.mybatisplus.extension.activerecord.Model;
import com.baomidou.mybatisplus.extension.handlers.FastjsonTypeHandler;
import com.rainbowsea.enums.GenderEnum;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
import java.util.Map;
@Data
@NoArgsConstructor
@AllArgsConstructor
@TableName(autoResultMap = true,value = " rainbowsea_user2")//查询时将json字符串封装为Map集合
public class User extends Model<User> {
@TableId(type = IdType.INPUT) // 该策略表示,必须由我们手动的插入id,否则无法添加数据,前提是:需要去掉数据表的自增策略
private String id;
private String name;
private Integer age;
private String email;
}
这里如果我们省略不写id,会发现,无法插入数据

@Test
void primaryKey(){
User user = new User();
user.setName("Jerry");
user.setAge(38);
user.setEmail("test8@powernode.com");
userMapper.insert(user);
}

但是我们自己指定了id,发现可以添加成功

2.3 ASSIGN_ID 策略
我们来思考一下,像之前这种自动递增的方式,有什么问题?
如果我们将来一张表的数据量很大,我们需要进行分表。
常见的分表策略有两种:水平拆分,垂直拆分
- 水平拆分:水平拆分就是将一个大的表按照数据量进行拆分

- 垂直拆分: 垂直拆分就是将一个大的表按照字段进行拆分

其实我们对于拆分后的数据,有三点需求,就拿水平拆分类说:
之前的表的主键是有序的,拆分后还是有序的。
虽然做了表的拆分,但是每条数据还需要保证主键的唯一性。
主键最好不要直接暴露数据的数量,这样容易被外界知道关键信息。
那就需要有一种算法,能够实现这三个需求,这个算法就是雪花算法。
2.3.1 雪花算法
雪花算法是由一个
64位的二进制组成的,最终就是一个Long类型的数据。主要分为:四部分存储 。
1位的符号位,固定值为 041位的时间戳10位的机器码,包含5位机器 id 和5位服务 id12位的序列号

**使用雪花算法可以实现有序、唯一、且不直接暴露排序的数字。 **

import com.baomidou.mybatisplus.annotation.FieldFill;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableLogic;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.annotation.Version;
import com.baomidou.mybatisplus.extension.activerecord.Model;
import com.baomidou.mybatisplus.extension.handlers.FastjsonTypeHandler;
import com.rainbowsea.enums.GenderEnum;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
import java.util.Map;
@Data
@NoArgsConstructor
@AllArgsConstructor
@TableName(autoResultMap = true,value = " rainbowsea_user2")//查询时将json字符串封装为Map集合
public class User extends Model<User> {
@TableId(type = IdType.ASSIGN_ID) // 雪花算法,就算数据表,没有设置自增策略,也可以成功的自增策略
private String id;
private String name;
private Integer age;
private String email;
}
运行测试:

我们可以在插入后发现一个19位长度的id,该id就是雪花算法生成的id,这是二级制的十进制表示形式
2.4 NONE 策略
NONE策略表示不指定主键生成策略,当我们没有指定主键生成策略或者主键策略为NONE的时候,他跟随的是全局策略,那我们来看一下他的全局策略默认是什么
是在application.yaml 文件当中配置 id-type 属性。全局配置中 id-type是用于配置主键生成策略的,我们可以看一下id-type的默认值


通过查看源码发现,id-type的默认值就是雪花算法。
也就是说,就算我们不采用任何的了主键策略,**在全局配置当中,默认就是采用了雪花算法
ASSIGN_ID策略**

2.5 ASSIGN_UUID 策略
UUID(Universally Unique Identifier)全局唯一标识符,定义为一个字符串主键 (注意:这里是字符串,也就是说,你的数据表的id 的主键,要为字符串类型,才可以使用这个ASSIGN_UUID策略),采用32位数字组成,编码采用 16进制,定义了在时间和空间都完成唯一的系统信息。
UUID的编码规则:
1~8位采用系统时间,在系统时间上精确到毫秒级保证时间上的唯一性。9~16位采用底层的 IP地址,在服务器集群中的唯一性。17~24位采用当前对象的HashCode值,在一个内部对象上的唯一性。25~32位采用调用方法的一个随机数,在一个对象内的毫秒级的唯一性。通过上述以上4中策略可以保证数据的唯一性 。在系统中需要用到随机数的地方都可以考虑采用UUID 算法。
我们想要演示UUID的效果,需要改变一下表的字段类型和实体类的属性类型
将数据库表的字段类型改为 varchar(50)

将实体类的属性类型改为String,并指定主键生成策略为 IdType.ASSIGN_UUID


完成数据的添加。我们会发现,成功添加了一条数据,id为uuid类型

3. 分页
在大部分场景下,如果我们的SQL没有这么复杂,是可以直接通过MybatisPlus提供的方法来实现查询的,在这种情况下,我们可以通过配置分页插件来实现分页效果
分页的本质就是需要设置一个拦截器,通过拦截器拦截了SQL,通过在SQL语句的结尾添加limit关键字,来实现分页的效果

3.1 分页插件
接下来看一下配置的步骤:配置分页插件
- 通过配置类来指定一个具体数据库的分页插件,因为不同的数据库的方言不同,具体生成的分页语句也会不同,这里我们指定数据库为Mysql数据库。

import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.annotation.InterceptorIgnore;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.BlockAttackInnerInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.OptimisticLockerInnerInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.apache.ibatis.plugin.Interceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
/*
通过配置类来指定一个具体数据库的分页插件,因为不同的数据库的方言不同,具
体涩会给你从的分页语句也会不同,这里我们指定数据库为 MySQL数据库
*/
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return mybatisPlusInterceptor;
}
}
实现分页查询效果:

import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.rainbowsea.bean.User;
import com.rainbowsea.mapper.UserMapper;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
@SpringBootTest
public class PageTest {
@Resource
private UserMapper userMapper;
@Test
void selectPage() {
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
// 指定分页对象,分页对象包含分页信息 IPage
IPage<User> userPage = new Page<>(1,3);
//Page<User> userPage = new Page<>(2, 3);
// 执行查询
userMapper.selectPage(userPage, lambdaQueryWrapper);
// 获取分页查询的信息
System.out.println("当前页:" + userPage.getCurrent());
System.out.println("每页显示条数: " + userPage.getSize());
System.out.println("总页数: " + userPage.getPages());
System.out.println("总条数: " + userPage.getTotal());
System.out.println("分页数据: " + userPage.getRecords());
}
}


3.2 自定义分页插件
在某些场景下,我们需要自定义SQL语句来进行查询。接下来我们来演示一下自定义SQL的分页操作
在Mapper接口中提供对应的方法,方法中将IPage对象作为参数传入

package com.rainbowsea.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.rainbowsea.bean.User;
import org.apache.ibatis.annotations.Mapper;
@Mapper // 包路径扫描
public interface UserMapper extends BaseMapper<User> {
IPage<User> selectByName(IPage<User> page, String name);
}
在UserMapper.xml映射配置文件中提供查询语句。

<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.rainbowsea.mapper.UserMapper">
<select id="selectByName" resultType="com.rainbowsea.bean.User">
select * from rainbowsea_user where name = #{name}
</select>
</mapper>
实现分页查询效果:

import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.rainbowsea.bean.User;
import com.rainbowsea.mapper.UserMapper;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
@SpringBootTest
public class PageTest {
@Resource
private UserMapper userMapper;
@Test
void selectPage2() {
IPage<User> userPage = new Page<>(1,3);
userMapper.selectByName(userPage,"Mary");
// 获取分页查询的信息
System.out.println("当前页:" + userPage.getCurrent());
System.out.println("每页显示条数: " + userPage.getSize());
System.out.println("总页数: " + userPage.getPages());
System.out.println("总条数: " + userPage.getTotal());
System.out.println("分页数据: " + userPage.getRecords());
}
}
4. 总结:
- 主键策略:
- AUTO 策略,自动添加主键,前提是:要设置数据表的自增。
- INPUT 策略:该策略表示,必须由我们手动的插入id,否则无法添加数据,前提是:需要去掉数据表的自增策略。
- ASSIGN_ID: 策略,运用了雪花算法,为主键的id 加密的同时自增了。
- NONE策略:默认的策略,该策略默认就是:默认设置(默认就是雪花算法),数据表没有设置自增策略,也可以成功。
- ASSIGU_UUID策略:采用UUID的编码加密主键,同时自增主键,全局唯一标识符,定义为一个字符串主键,注意是字符串,所以数据表的主键要为字符串类型才行,对应的 Java bean 对象当中的属性值,也要为 字符串类型
- 分页的本质就是需要设置一个拦截器,通过拦截器拦截了SQL,通过在SQL语句的结尾添加limit关键字,来实现分页的效果
5. 最后:
“在这个最后的篇章中,我要表达我对每一位读者的感激之情。你们的关注和回复是我创作的动力源泉,我从你们身上吸取了无尽的灵感与勇气。我会将你们的鼓励留在心底,继续在其他的领域奋斗。感谢你们,我们总会在某个时刻再次相遇。”