文章目录
- 技术交流
- 多模态理解
- 一、图像描述
- 1. 基于编码器-解码器的方法
- 2. 基于注意力机制的方法
- 3. 基于生成对抗网络的方法
- 二、视频描述
- 三、视觉问答
- 视觉大模型
- 一、通用图像理解模型
- 二、通用图像生成模型
- 多模态检索
- 一、单模态检索
- 二、多模态检索
- 三、跨模态检索
最近这一两周看到不少互联网公司都已经开始秋招发放Offer。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
- 《大模型面试宝典》(2024版) 正式发布!
- 持续火爆!!!《AIGC 面试宝典》已圈粉无数!
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们
技术交流

多模态理解
多模态理解是指从多个不同模态(如视觉、听觉、语言等)的数据中提取和融合信息,以便更深入地理解和推断数据的含义。这种跨模态的信息整合能力对于构建更加智能、更加贴近人类认知的人工智能系统至关重要。
在计算机视觉(CV)领域,多模态理解可以应用于图像描述和视频描述,使计算机能够生成对图像或视频内容的自然语言描述,从而帮助人们更便捷地获取和理解视觉信息。
在自然语言处理(NLP)领域,多模态理解则体现在与视觉、听觉等模态的交互上,如视觉问答系统,它要求计算机在理解图像内容的同时,还能准确解析自然语言问题,并给出恰当的回答。
接下来分三部分:_图像描述、视频描述、视觉问答,一起来深入了解多模态应用:多模态理解。

多模态理解
一、图像描述
什么是图像描述(Image Captioning)?图像描述任务要求模型能够准确识别图像中的物体、场景以及它们之间的关系,并用自然语言生成一段简洁、流畅且富有信息量的描述。这类似于人类日常生活中的“看图说话”活动,但对于计算机来说,这项任务充满了挑战,因为它需要模型具备高级别的图像理解和语言生成能力。

图像描述
图像描述旨在让计算机能够根据给定的图像自动生成一段描述性文字。这个过程结合了计算机视觉(Computer Vision, CV)技术和自然语言处理(Natural Language Processing, NLP)技术,是深度学习领域中图像与文本跨模态融合的一个重要应用。
-
图像识别:识别出图像中的不同模式、目标或对象。图像识别技术通常包括图像预处理、特征提取、目标检测等步骤。
-
自然语言处理:要求模型能够理解自然语言的结构、语法和语义,并能够根据图像内容生成与之相符的文本。
-
跨模态融合:将图像信息和文本信息进行有效融合。通过多模态学习来实现,使模型能够同时理解和处理来自不同模态的数据。

图像描述
图像描述的方法有哪些?图像描述的三种主要方法包括基于编码器-解码器、基于注意力机制和基于生成对抗网络。
1. 基于编码器-解码器的方法
受机器翻译领域中编码器-解码器(Encoder-Decoder)模型的启发,图像描述可以通过端到端的学习方法直接实现图像和描述句子之间的映射,将图像描述过程转化成为图像到描述的“翻译”过程。
-
编码器:通常使用卷积神经网络(CNN)来提取图像的特征,将图像转换为高维特征表示。
-
解码器:通常使用循环神经网络(RNN)或其变体(如LSTM、GRU)来读取编码后的图像特征,并生成文本描述。

基于编码器-解码器的图像描述
2. 基于注意力机制的方法
注意力机制并不是将输入序列编码成一个固定向量,而是通过增加一个上下文向量来对每个时间步的输入进行解码,以增强图像区域和单词的相关性,从而获取更多的图像语义细节。

-
关注重点:注意力机制允许模型集中关注图像中的重要区域,并根据不同区域的重要性分配不同的权重。
-
上下文信息融合:基于注意力机制帮助模型更好地选择下一个单词,生成连贯和准确的描述。

基于注意力机制的图像描述
3. 基于生成对抗网络的方法
生成对抗网络(GANs)通过引入竞争机制,实现了生成器和判别器的协同进化,能够生成逼真且多样化的图像。在图像描述任务中,GANs同样可以生成多样化的描述语句。
-
生成网络:生成网络负责生成描述语句,它通常结合CNN和RNN(或LSTM)来实现。在生成单词时,可以加入随机噪声以增加描述的多样性。
-
判别网络:判别网络负责区分生成的描述语句和真实的描述语句。通过生成网络和判别网络的动态博弈学习,模型可以不断优化生成描述的质量。

二、视频描述
什么是视频描述(Video Captioning)?视频描述是指通过机器自动生成视频内容的描述语句的技术,旨在将视频中的视觉和听觉信息转化为易于理解的自然语言文本,从而帮助用户快速了解视频内容。
视频描述同样也是计算机视觉(Computer Vision, CV)和自然语言处理(Natural Language Processing, NLP)任务的结合。

视频描述
什么是视频定位(Video Localization)?视频定位任务指的是在视频内容中准确识别并标记出关键元素或事件的位置和时间点。这要求系统能够分析视频帧,理解视频中的动态变化,并据此确定特定对象、场景或事件在视频中的具体位置和时间范围。
-
目标检测与跟踪:利用计算机视觉技术,如深度学习算法,对视频中的物体、人物等进行实时检测和跟踪,以确定其在视频帧中的位置。
-
时间标注:对于视频中的关键事件或场景变化,系统需要能够识别其发生的时间点或时间段,并进行相应的标注。

视频定位
在视频描述任务中,“定位”和“描述”是紧密相连的两个环节。定位任务为描述任务提供了关键信息的基础,即确定了视频中需要被描述的对象或事件。而描述任务则进一步将这些信息转化为易于理解的自然语言文本,实现了视频内容的语言化表达。两者相互配合,共同构成了视频描述技术的完整框架。

视频描述
三、视觉问答
什么是视觉问答(Visual Question Answering,VQA)?视觉问答系统接收一张图像和一个关于这张图像的自然语言问题作为输入,经过系统处理后,输出一个准确的自然语言答案。这个过程不仅要求系统能够理解图像中的信息,还需要解析自然语言问题,并将两者结合起来生成与图像内容相一致的答案。

视觉问答
视觉问答也是一项结合了计算机视觉(Computer Vision)和自然语言处理(Natural Language Processing)技术的综合性学习任务。

视觉问答
什么是视频问答(Video Question Answering, VideoQA)?视频问答是视觉问答的一个子集,特指针对视频内容进行的问答任务。视频作为一种特殊的视觉内容,不仅包含静态的图像信息,还包含了丰富的时序和动态变化信息。

视频问答
视频问答的任务是根据给定的视频内容和自然语言问题,生成一个或多个准确的自然语言答案。这些问题可以是开放式的,也可以是选择式的,它们涵盖了视频中的对象识别、事件检测、场景理解、时间关系推理等多个方面。视频问答的目标是构建一个能够像人类一样理解视频内容并回答相关问题的智能系统。

视频问答
视觉大模型
视觉大模型(Large Vision models)在图像理解和生成领域展现出了巨大的潜力和价值。CLIP和SAM作为通用图像理解模型的代表,分别通过跨模态匹配和精确分割技术推动了图像理解领域的发展。而Stable Diffusion作为通用图像生成模型的代表,则以其高效、稳定的图像生成能力为图像创作和艺术设计等领域带来了全新的可能性。
接下来分两部分:通用图像理解模型、通用图像生成模型,一起来学习视觉大模型CLIP、SAM和Stable Diffusion。
一、通用图像理解模型
什么是通用图像理解模型?通用图像理解模型是指一类能够处理和理解广泛图像内容,执行多种图像理解任务的计算机视觉模型。如CLIP和SAM,它们分别通过跨模态匹配和精确分割技术,实现了对图像的高效理解和应用。
-
图像分类:将图像划分为预定义的类别之一。例如,识别图像中的物体是猫、狗还是其他动物。
-
目标检测:在图像中定位并识别出多个物体及其类别。这通常涉及在图像上绘制边界框来指示物体的位置。
-
图像分割:将图像分割成不同的区域或对象,通常是在像素级别上进行。这可以是语义分割(区分不同类别的对象)或实例分割(区分同一类别的不同实例)。
什么是CLIP(Contrastive Language-Image Pre-training)?CLIP(对比语言-图像预训练)是一种基于对比学习的多模态模型,通过大规模的图像-文本对数据集进行预训练,学习图像和文本之间的匹配关系。
CLIP模型将图像和文本编码到同一向量空间中,使得相似的图像和文本在空间中距离更近,从而实现了跨模态的语义理解和检索。
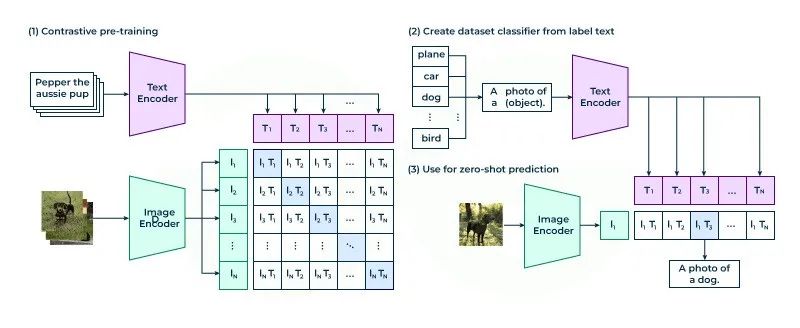
CLIP
图像-文本对数据集驱动图像和文本两种模态数据进行跨模态对齐,从而学习图像-文本的映射关系,实现图像-文本多模态融合。-- 架构师带你玩转AI
什么是SAM(Segment Anything Model)?SAM(分割一切模型)是一个由Meta AI(Facebook AI Research)发布的图像分割模型,旨在通过用户提示(如点击、画框、掩码、文本等)从图像中分割出特定的对象。

SAM
该模型具有零样本泛化的能力,即能够分割图像上的视觉对象,即使这些对象没有在训练集中出现过。
-
零样本泛化能力:SAM能够处理并分割出图像中未曾在训练集中见过的对象,这种能力在图像分割领域尚属首次。
-
灵活的提示输入:用户可以通过多种形式的提示(点、边界框、文本等)来指导模型进行分割,这使得模型在应用中更加灵活和便捷。
-
高效的模型结构:SAM模型由图像编码器、提示编码器和掩码解码器组成,能够在浏览器中快速(约50毫秒)根据提示预测掩码。
-
大规模多样化的数据集:为了训练SAM模型,Meta AI构建了一个名为SA-1B的大规模图像分割数据集,包含1100万张图片以及10亿个Mask图。

SAM
二、通用图像生成模型
什么是通用图像生成模型?通用图像生成模型是一类基于深度学习技术的生成式模型,它们的主要目的是学习图像数据的分布,并据此生成新的、多样化的图像样本。包括图像生成、图像编辑、图像修复、图像增强等。

通用图像生成模型
什么是Stable Diffusion?Stable Diffusion是一种先进的图像生成模型,属于Diffusion模型的一种。它采用了更加稳定、可控和高效的方法来生成高质量图像。
Stable Diffusion通过文本编码器的文本嵌入、潜空间采样、U-Net网络的逐步去噪生成,以及VAE解码器的图像解码,实现从文本描述到高质量图像的生成。

Stable Diffusion
Stable Diffusion模型结构主要由变分自编码器(VAE)、U-Net神经网络和文本编码器(CLIP Text Encoder)三个核心部分组成,通过潜空间中的信息逐步处理和文本条件引导,实现高质量图像的生成。

Stable Diffusion
-
文本编码器(CLIP Text Encoder):
-
文本编码器是Stable Diffusion模型的重要组成部分,它负责将输入的文本描述转换为数值表示,即文本嵌入(Text Embeddings)。
-
在Stable Diffusion中,文本编码器通常采用的是CLIP模型中的Text Encoder部分。CLIP模型是一个基于对比学习的多模态模型,能够理解和比较文本与图像之间的相似度,使得生成的图像能够与输入的文本描述相匹配。
-
-
变分自编码器(VAE, Variational Autoencoder):
-
VAE在Stable Diffusion中主要用于图像的压缩和恢复。它包含编码器(Encoder)和解码器(Decoder)两个部分。
-
编码器负责将输入的高维图像数据压缩到低维的潜空间(Latent Space)中,生成潜空间特征(Latent Features)。解码器则负责将潜空间特征重新映射回原始的高维图像空间,生成最终的图像输出。
-
-
U-Net网络:
-
U-Net是Stable Diffusion中用于图像生成的核心网络。它接收文本嵌入向量和潜空间特征作为输入,通过逐步去噪(Denoising)的过程生成最终的图像。
-
U-Net网络结构具有对称性,包含编码器和解码器两个部分。编码器部分逐步降低特征图的分辨率并提取高级特征,解码器部分则逐步恢复特征图的分辨率并生成最终的图像。
-

Stable Diffusion
多模态检索
多模态检索是指利用多种数据模态(如文本、图像、视频、音频等)进行信息检索的技术。它旨在通过整合不同形式的数据,提供更全面、精确和丰富的检索结果,以满足用户多样化的查询需求。
接下来分三部分:单模态检索、多模态检索、跨模态检索,一起来深入了解多模态应用:多模态检索。

多模态检索
一、单模态检索
什么是单模态检索(Single-Modal Retrieval)?单模态检索是指仅涉及单一数据模态(如文本、图像、音频或视频等)的检索技术。在这种检索方式中,用户通过特定模态的查询来检索相同模态下的相关信息。

单模态检索
文本检索(Text Retrieval)是单模态检索中最常见且应用最广泛的一种形式。它主要依赖于文本处理技术和信息检索算法,如倒排索引、向量空间模型、布尔模型、概率模型等。
-
分词与索引:将文本分割成词或短语,并构建索引以便于快速检索。
-
查询处理:对用户的查询进行解析和优化,以提高检索效率。
-
相关性排序:根据文本之间的相似度或相关性对检索结果进行排序。

文本检索
图像检索(Image Retrieval)是基于图像内容的检索技术,它通过分析图像的颜色、纹理、形状等特征来检索相似的图像。
-
特征提取:使用卷积神经网络(CNN)等深度学习模型提取图像的视觉特征。
-
特征匹配:计算查询图像与数据库图像之间的特征相似度。
-
检索优化:通过哈希技术、量化方法等优化检索过程,提高检索速度。

图像检索
音频检索(Audio Retrieval)是基于音频内容的检索技术,它通过分析音频信号的频谱、节奏、音色等特征来检索相似的音频片段。
-
音频特征提取:使用音频处理算法提取音频信号的频谱特征和时间特征。
-
特征匹配与检索:计算查询音频与数据库音频之间的特征相似度,并进行检索。

音频检索
二、多模态检索
什么是多模态检索(Multi-Modal Retrieval)?多模态检索是一种涉及多种媒体模态(如文本、图像、音频、视频等)的信息检索方法。与传统的基于单一模态的信息检索不同,多模态检索能够处理并整合来自不同模态的数据,以提供更全面、准确和丰富的检索结果。

多模态检索
多模态检索的关键步骤和过程是什么?多模态检索通过深度学习模型转换数据为向量表示,映射至共同向量空间实现跨模态对齐,进行模态融合提取共同特征,并通过相似度度量排序检索结果。
-
数据转换:在多模态检索中,首先需要将不同类型的输入数据(文本、图像、音频、视频等)转换为相应的向量表示。这些向量表示通常通过深度学习模型(如卷积神经网络CNN、循环神经网络RNN、Transformer等)进行提取,以捕捉数据的特征。
-
共同向量空间:为了在同一空间中进行检索,必须将所有模态的数据映射到同一向量空间中。这一步骤通过多模态对齐技术(Cross-modal alignment)实现,确保不同模态的数据在向量空间中具有可比性。
-
模态融合:在多模态检索中,还需要进行模态融合,即将不同模态的数据进行融合,提取它们的共同特征。这有助于更好地理解用户的查询意图,并返回更准确的检索结果。
-
相似度度量:在向量空间中,通过计算查询向量与候选结果向量之间的相似度,来确定检索结果的排序。常用的相似度度量方法包括余弦相似度、欧氏距离等。

多模态检索
三、跨模态检索
什么是跨模态检索(Cross-Modal Retrieval)?跨模态检索是指在不同类型的数据(如图像、文本、音频、视频等)之间进行查询和检索的过程。这种技术通过特定的方法将不同模态的数据映射到一个共享的特征空间中,使得用户可以通过一种模态的查询来检索到另一种模态的数据。

跨模态检索
跨模态检索的核心流程是什么?跨模态检索视觉通过特征提取与表示学习、跨模态映射、语义对齐及检索与排序等步骤,实现了不同模态数据在共享特征空间中的相互关联与高效检索。
-
特征提取与表示学习:首先,针对不同模态的数据,需要提取各自的特征,并将这些特征转换为统一的向量表示。这一步骤是跨模态检索的基础,它确保了不同模态的数据在向量空间中可以进行比较和计算。
-
跨模态映射:将不同模态的数据映射到共享的特征空间是跨模态检索的核心。这一步骤通常通过深度学习等机器学习技术实现,如使用卷积神经网络(CNN)处理图像数据,使用循环神经网络(RNN)或Transformer处理文本数据等。通过映射,不同模态的数据在特征空间中能够相互关联,从而支持跨模态的查询和检索。
-
语义对齐:在共享的特征空间中,需要实现不同模态数据之间的语义对齐。这意味着虽然数据来自不同的模态,但它们在特征空间中的表示应该能够反映出相同的语义信息。这一步骤对于提高跨模态检索的准确性和效率至关重要。
-
检索与排序:在跨模态检索过程中,用户通过一种模态的查询(如文本)来检索另一种模态的数据(如图像)。系统会根据查询向量与候选结果向量之间的相似度进行排序,并返回最相关的检索结果。相似度的计算通常基于向量空间中的距离度量,如余弦相似度或欧氏距离等。

跨模态检索
nsformer处理文本数据等。通过映射,不同模态的数据在特征空间中能够相互关联,从而支持跨模态的查询和检索。
-
语义对齐:在共享的特征空间中,需要实现不同模态数据之间的语义对齐。这意味着虽然数据来自不同的模态,但它们在特征空间中的表示应该能够反映出相同的语义信息。这一步骤对于提高跨模态检索的准确性和效率至关重要。
-
检索与排序:在跨模态检索过程中,用户通过一种模态的查询(如文本)来检索另一种模态的数据(如图像)。系统会根据查询向量与候选结果向量之间的相似度进行排序,并返回最相关的检索结果。相似度的计算通常基于向量空间中的距离度量,如余弦相似度或欧氏距离等。