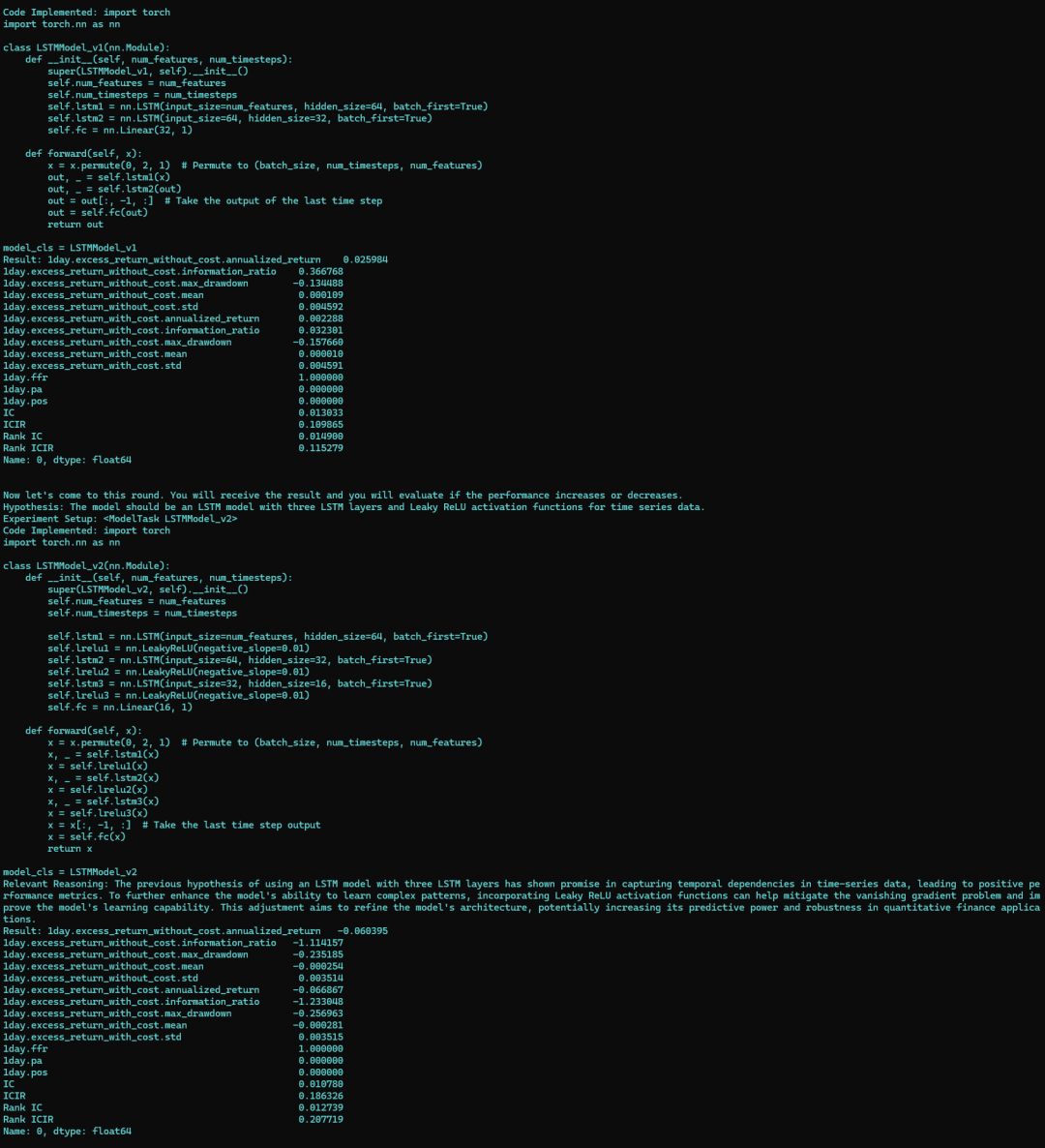
在这篇文章中,我将详细介绍 PostgreSQL 中的公用表表达式(CTE)和窗口函数,帮助你理解如何使用它们进行复杂的数据分析。我将通过具体的示例来演示这些概念的实际应用,并在每个示例中提供详细的解释和注释。
1. 公用表表达式(CTE)
1.1 什么是 CTE?
公用表表达式(Common Table Expression,CTE)是一种在 SQL 查询中定义临时结果集的方式,可以在主查询中多次引用。
CTE 可以提高查询的可读性和结构性,尤其是在处理复杂的查询时。
使用 CTE,可以避免使用嵌套查询,从而使 SQL 代码更清晰。
1.2 CTE 的基本语法
CTE 的基本语法如下:
WITH cte_name AS (
SELECT columns
FROM table
WHERE conditions
)
SELECT *
FROM cte_name;
WITH关键字用于定义 CTE。cte_name是 CTE 的名称,可以在后续查询中使用。- CTE 内部的
SELECT查询定义了临时结果集。
1.3 示例:使用 CTE 进行复杂查询
假设有一个名为 sales 的表,记录了销售数据,结构如下:
CREATE TABLE sales (
id SERIAL PRIMARY KEY, -- 唯一标识每一条销售记录
product_name VARCHAR(100), -- 产品名称
sale_date DATE, -- 销售日期
amount DECIMAL, -- 销售金额
quantity INT -- 销售数量
);
插入一些示例数据:
INSERT INTO sales (product_name, sale_date, amount, quantity) VALUES
('Product A', '2023-01-01', 100.00, 1),
('Product B', '2023-01-02', 200.00, 2),
('Product A', '2023-01-03', 150.00, 1),
('Product C', '2023-01-04', 300.00, 3),
('Product B', '2023-01-05', 250.00, 1);
示例 1:计算每个产品的总销售额
想要计算每个产品的总销售额,可以使用 CTE 来先计算每个产品的销售额,然后再进行汇总。
WITH sales_summary AS (
SELECT
product_name, -- 选择产品名称
SUM(amount) AS total_sales -- 计算每个产品的总销售额
FROM
sales
GROUP BY
product_name -- 按产品名称分组
)
SELECT
product_name,
total_sales
FROM
sales_summary -- 从 CTE 中查询结果
ORDER BY
total_sales DESC; -- 按总销售额降序排列
注释:
- 在 CTE
sales_summary中,使用SUM(amount)来计算每个产品的总销售额,并使用GROUP BY子句按product_name进行分组。 - 主查询从 CTE 中获取结果,并根据
total_sales降序排列,以便查看销售额最高的产品。
1.4 CTE 的递归查询
CTE 还支持递归查询,适用于层级结构的数据(如组织结构、分类等)。
示例 2:递归 CTE 示例
假设有一个员工表 employees,结构如下:
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY, -- 员工唯一标识
employee_name VARCHAR(100), -- 员工姓名
manager_id INT -- 上级员工的 ID
);
插入一些示例数据:
INSERT INTO employees (employee_name, manager_id) VALUES
('Alice', NULL), -- Alice 是顶层管理者,没有上级
('Bob', 1), -- Bob 是 Alice 的下属
('Charlie', 1), -- Charlie 也是 Alice 的下属
('David', 2), -- David 是 Bob 的下属
('Eve', 2); -- Eve 也是 Bob 的下属
想要查询所有员工及其上级,可以使用递归 CTE:
WITH RECURSIVE employee_hierarchy AS (
SELECT
employee_id, -- 选择员工 ID
employee_name, -- 选择员工姓名
manager_id, -- 选择上级员工 ID
0 AS level -- 级别,顶层管理者的级别为 0
FROM
employees
WHERE
manager_id IS NULL -- 从顶层管理者开始
UNION ALL
SELECT
e.employee_id, -- 选择下属员工 ID
e.employee_name, -- 选择下属员工姓名
e.manager_id, -- 选择下属的上级员工 ID
eh.level + 1 -- 级别加 1
FROM
employees e
JOIN
employee_hierarchy eh ON e.manager_id = eh.employee_id -- 连接下属和上级
)
SELECT
employee_name,
level
FROM
employee_hierarchy
ORDER BY
level, employee_name; -- 按级别和姓名排序
注释:
- 递归 CTE
employee_hierarchy的第一部分选择顶层管理者(没有上级的员工),并初始化级别为 0。 - 第二部分通过
JOIN连接员工表和 CTE,以查找每个员工的下属,并将级别加 1。 - 最后,查询 CTE,返回员工姓名及其层级,并按层级和姓名排序。
2. 窗口函数
2.1 什么是窗口函数?
窗口函数是一种在结果集的每一行上执行计算的函数,它允许我们在不分组的情况下进行聚合计算。
窗口函数通常用于计算排名、移动平均、累计和等。
与普通的聚合函数不同,窗口函数不会减少结果集的行数。
2.2 窗口函数的基本语法
窗口函数的基本语法如下:
SELECT columns,
window_function() OVER (PARTITION BY column ORDER BY column)
FROM table;
window_function()是要使用的窗口函数,如SUM(),RANK(),ROW_NUMBER()等。OVER子句定义了窗口的分区和排序方式。PARTITION BY用于将结果集分成不同的组(类似于 GROUP BY),而ORDER BY用于在每个组内排序。
2.3 示例:使用窗口函数进行数据分析
示例 3:计算每个产品的销售排名
可以使用窗口函数来计算每个产品的销售排名。
SELECT
product_name,
SUM(amount) AS total_sales, -- 计算每个产品的总销售额
RANK() OVER (ORDER BY SUM(amount) DESC) AS sales_rank -- 计算销售排名
FROM
sales
GROUP BY
product_name
ORDER BY
sales_rank; -- 按销售排名排序
注释:
- 在这个查询中,
SUM(amount)计算每个产品的总销售额,并使用RANK()函数为每个产品分配一个排名,排名基于总销售额的降序。 - 最后,结果按销售排名排序。
示例 4:计算累计销售额
还可以使用窗口函数计算累计销售额。
SELECT
sale_date,
product_name,
amount,
SUM(amount) OVER (ORDER BY sale_date) AS cumulative_sales -- 计算累计销售额
FROM
sales
ORDER BY
sale_date; -- 按销售日期排序
注释:
- 在这个查询中,
SUM(amount) OVER (ORDER BY sale_date)计算截至每个销售日期的累计销售额。 - 结果按销售日期排序,显示每个日期的销售额和累计销售额。
3. 综合示例:结合 CTE 和窗口函数
现在结合 CTE 和窗口函数进行一个更复杂的分析,计算每个产品的总销售额、排名以及累计销售额。
WITH sales_summary AS (
SELECT
product_name,
SUM(amount) AS total_sales -- 计算每个产品的总销售额
FROM
sales
GROUP BY
product_name -- 按产品名称分组
)
SELECT
product_name,
total_sales,
RANK() OVER (ORDER BY total_sales DESC) AS sales_rank, -- 计算销售排名
SUM(total_sales) OVER (ORDER BY total_sales DESC) AS cumulative_sales -- 计算累计销售额
FROM
sales_summary
ORDER BY
sales_rank; -- 按销售排名排序
注释:
- 在这个综合示例中,首先使用 CTE
sales_summary计算每个产品的总销售额。 - 然后在主查询中,使用窗口函数
RANK()计算销售排名,并使用SUM(total_sales) OVER (ORDER BY total_sales DESC)计算累计销售额。 - 最后,结果按销售排名排序,展示每个产品的总销售额、排名和累计销售额。
4. 总结
本文详细介绍了 PostgreSQL 中的公用表表达式(CTE)和窗口函数。通过具体的示例,实操展示了如何使用这些功能进行复杂的数据分析。
希望这篇文章能帮助你掌握 CTE 和窗口函数,可以帮助你编写更清晰、灵活的 SQL 查询,进行深入的数据分析。