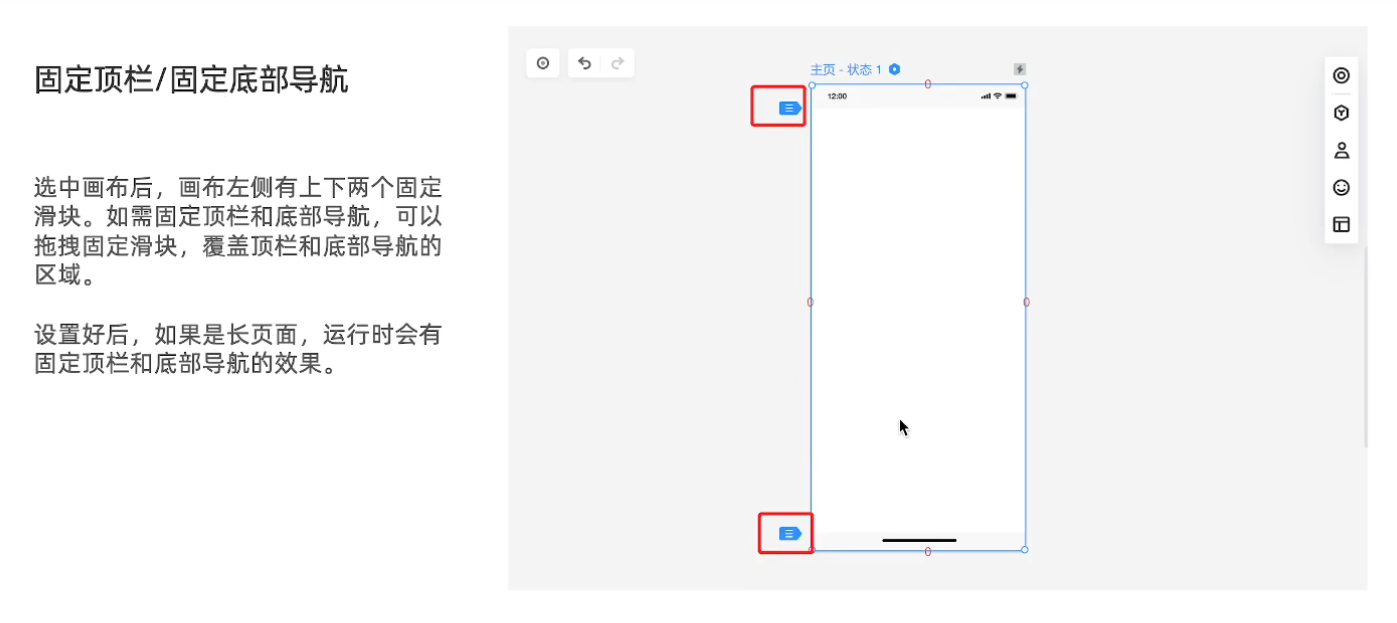
L1-书生大模型全链路开源体系
- 基于反馈的数据生成可以用开源项目标注——label LLM的开源项目
- 大海捞针测试
- 之前需要Rag《分块-量化-匹配-理解》![[Pasted image 20241001144531.png]]
- 复杂问题
- ![[Pasted image 20241001144635.png]]
- 谱系
- ![[Pasted image 20241001144840.png]]
- 全链
- ![[Pasted image 20241001144927.png]]
- ![[Pasted image 20241001145106.png]]
- ![[Pasted image 20241001145138.png]]
1. 全量参数微调(Full Parameter Fine-Tuning)
全量参数微调指的是对预训练模型的所有参数进行调整。这意味着所有的权重都在训练过程中参与更新,以适应新的数据或任务。
- 优点:
- 适应性强:可以针对特定任务进行精细的优化。
- 可以最大化模型的性能提升。
- 缺点:
- 计算开销大:需要大量计算资源,尤其是对于大规模模型,显存占用高。
- 存储需求大:微调后的模型需要重新保存所有参数,这在大模型场景下会带来存储挑战。
2. LoRA 微调(Low-Rank Adaptation of Large Language Models)
LoRA 是一种高效的微调方法,它通过在预训练模型的某些特定层插入 低秩矩阵(Low-Rank Matrices) 来进行微调,而不调整原模型的全部参数。具体来说,它冻结了预训练模型的所有权重,只对低秩矩阵进行训练。这大大减少了需要微调的参数数量。
-
工作原理:
- LoRA 在某些特定层添加了两个小型的可训练的低秩矩阵,用来捕捉模型新的任务相关信息。
- 这些低秩矩阵的参数远少于原始模型的参数,因此训练速度快,占用资源少。
-
优点:
- 节省计算资源:只训练少量参数,大幅减少显存需求和计算开销。
- 高效存储:保存的模型权重很小,适合资源有限的场景。
-
缺点:
- 在某些场景下,LoRA 的性能可能不如全量参数微调,因为它只调整了部分参数。
3. QLoRA(Quantized Low-Rank Adaptation)
QLoRA 是 LoRA 的扩展版本,它结合了量化和低秩微调技术,进一步提高了效率。QLoRA 首先将预训练模型进行 4-bit 量化,以减少显存占用,然后在这个量化后的模型上应用 LoRA 微调。
-
工作原理:
- 首先使用4-bit量化来减少模型的权重表示大小,减少显存占用。
- 然后在量化模型上应用 LoRA 进行低秩矩阵微调,只对低秩矩阵进行训练,原始模型的权重保持不变。
-
优点:
- 极大降低显存占用:通过量化和低秩微调,QLoRA 可以在大幅减少显存需求的同时保持较高的性能。
- 更适合大模型微调:适合资源有限但需要微调大型语言模型的场景。
-
缺点:
- 由于使用了量化,性能可能会有轻微的损失,尤其是在非常精确的任务上。
总结:
- 全量参数微调:所有参数都被微调,计算和存储开销大,适用于资源充足且需要最大化模型性能的场景。
- LoRA:通过插入低秩矩阵,减少了训练参数数量,显著节省资源,适合资源有限的场景。
- QLoRA:在 LoRA 的基础上增加了4-bit量化,进一步减少显存和计算开销,适合极大规模模型的高效微调。
- 部署
- ![[Pasted image 20241001145502.png]]
- ![[Pasted image 20241001145545.png]]
- ![[Pasted image 20241001145629.png]]
- ![[Pasted image 20241001145654.png]]