一、前言
本文内含YOLOv11网络结构图 + 训练教程 + 推理教程 + 数据集获取等有关YOLOv11的内容!

官方代码地址:https://github.com/ultralytics/ultralytics/tree/main/ultralytics/cfg/models/11
二、整体网络结构图

三、环境搭建
项目环境如下:
解释器:Python:3.9.19
框 架:Pytorch:2.0.1
系 统:Win10
IDEA : Pycharm
四、数据集获取
免费数据集网站Roboflow一键导出Voc、COCO、Yolo、Csv等格式
随便下载了一个 数据集用它导出YOLO的数据集,自动给转换成txt的格式,yaml文件也已经配置好了,直接用就可以。

五、模型获取

代码地址:https://github.com/ultralytics/ultralytics
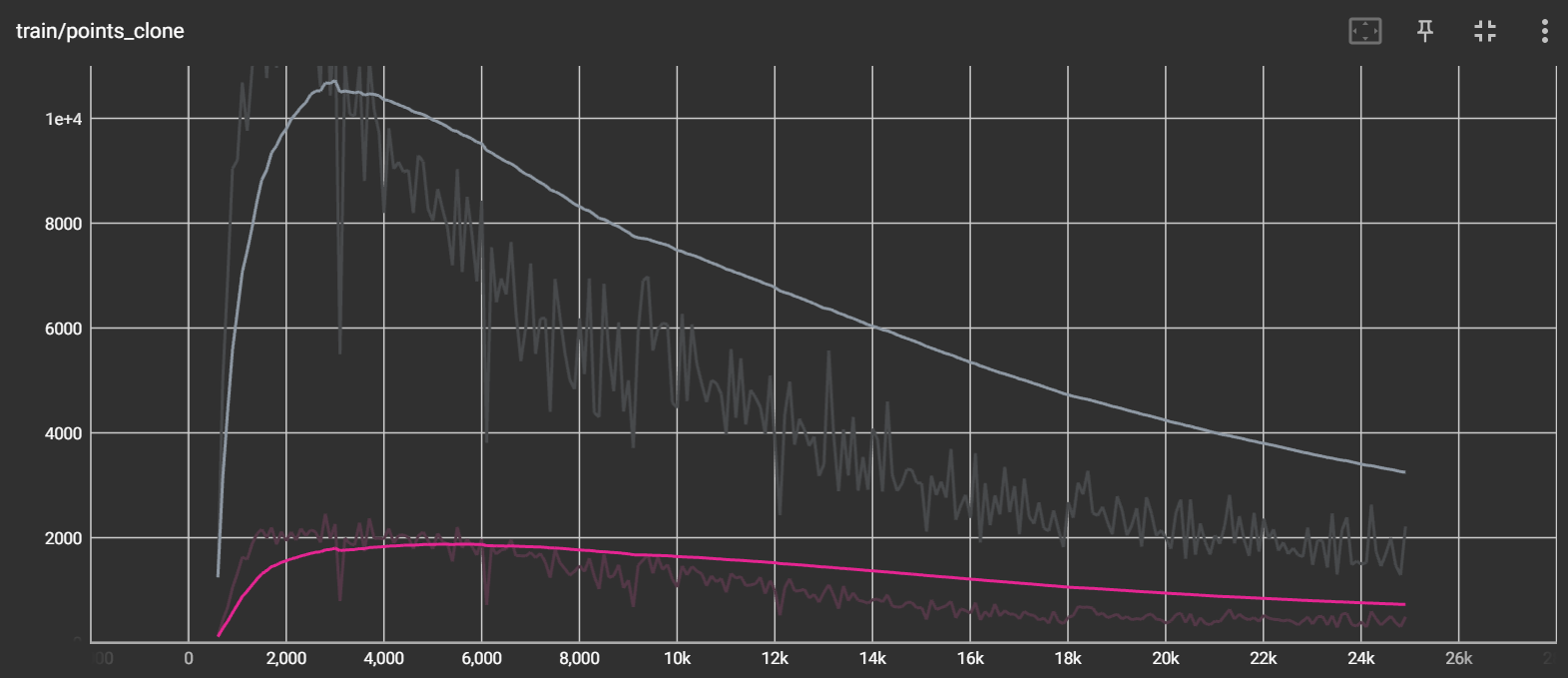
六、模型训练
下载好的模型代码用Pycharm打开后,我们需要添加自己的数据集:

train.py文件的代码我直接给出:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(r'D:\yolo\yolov11\ultralytics-main\datasets\yolo11.yaml')
model.train(data=r'D:\yolo\yolov11\ultralytics-main\datasets\data.yaml',
cache=False,
imgsz=640,
epochs=100,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
device='0',
optimizer='SGD',
amp=True,
project='runs/train',
name='exp',
)
注释:D:\yolo\yolov11\ultralytics-main\datasets\yolo11.yaml中的yolo11.yaml是我从ultralytics/cfg/models/11/yolo11.yaml中复制到datasets文件夹里的
打印模型结构:

七、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv11改进有效涨点专栏,本专栏目前为新开的,后期我会根据各种前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
YOLOv11有效涨点专栏









![[Cocoa]_[初级]_[绘制文本如何设置断行方式]](https://i-blog.csdnimg.cn/direct/80eea92949db49ecb5ac0a6297af9243.png)