提示学习(Prompting)是一种自然语言处理(NLP)中的训练技术,它利用预训练的语言模型(如BERT、GPT等)来解决各种下游任务,如文本分类、命名实体识别、问答等。这种方法的关键思想是通过设计合适的提示(Prompt),将下游任务转化为一个填空任务,然后利用预训练的语言模型来预测填空。
例如,对于情感分类任务,我们可以设计一个提示如“这段文本的情感是{mask}”,其中{mask}是需要预测的部分。然后,我们将这个提示和实际的文本一起输入到预训练的语言模型中,模型的任务就是预测{mask}的内容,即文本的情感。

提示学习的优点是可以充分利用预训练语言模型的强大表示能力,而且不需要对模型结构进行大的修改,只需要设计合适的提示即可。但是,如何设计有效的提示是一项挑战,需要大量的实验和经验。
ChatGPTBook/PromptProj
| Name | Last commit message | Last commit date |
|---|---|---|
| parent directory… | ||
| data(Directory) | update code | 3 months ago |
| images(Directory) | update code | 3 months ago |
| pretrain_model(Directory) | update code | 3 months ago |
| prompt_model(Directory) | update code | 3 months ago |
| README.md(File) | update code | 3 months ago |
| data_helper.py(File) | update code | 3 months ago |
| data_set.py(File) | update code | 3 months ago |
| model.py(File) | update code | 3 months ago |
| predict.py(File) | update code | 3 months ago |
| requirements.txt(File) | update code | 3 months ago |
| train.py(File) | update code | 3 months ago |
README.md
本项目为书籍《ChatGPT原理与实战:大型语言模型的算法、技术和私有化》中第5章《提示学习与大模型的涌现》实战部分代码-基于Prompt的文本情感分析实战。
项目简介
针对酒店评论数据集,利用BERT模型在小样本数据下进行模型训练及测试,更深入地了解Prompt任务进行下游任务的流程。
项目主要结构如下:
- data 存放数据的文件夹
- ChnSentiCorp_htl_all.csv 原始酒店评论情感数据 【数据量3MB不到】
- sample.json 处理后的语料样例
- prompt_model 已训练好的模型路径
- config.json
- pytorch_model.bin
- vocab.txt
- pretrain_model 预训练文件路径
- config.json
- pytorch_model.bin 【虽然提示学习是在预训练中结合下游任务一起训练,但这里演示的还是有增量训练的,不过模型参数没有更新,见后】
- vocab.txt
- data_helper.py 数据预处理文件
- data_set.py 模型所需数据类文件
- model.py 模型文件
- train.py 模型训练文件
- predict.py 模型推理文件
注意:由于GitHub不方便放模型文件,因此prompt_model文件夹和pretrain_model文件夹中的模型bin文件,请从百度云盘中下载。
| 文件名称 | 下载地址 | 提取码 |
|---|---|---|
| pretrain_model | 百度云 | tdzo |
| prompt_model | 百度云 | fjd9 |
环境配置
模型训练或推理所需环境,请参考requirements.txt文件。
数据处理
数据预处理需要运行data_helper.py文件,会在data文件夹中生成训练集和测试集文件。
命令如下:
python3 data_helper.py
注意:如果需要修改数据生成路径或名称,请修改data_helper.py文件66-68行,自行定义。
模型训练
模型训练需要运行train.py文件,会自动生成output_dir文件夹,存放每个epoch保存的模型文件。
命令如下:
python3 train.py --device 0 \
--data_dir "data/" \
--train_file_path "data/train.json" \
--test_file_path "data/test.json" \
--pretrained_model_path "pretrain_model/" \
--max_len 256 \
--train_batch_size 4 \
--test_batch_size 16 \
--num_train_epochs 10 \
--token_handler "mean"
注意:当服务器资源不同或读者更换数据等时,可以在模型训练时修改响应参数,详细参数说明见代码或阅读书5.4.4小节。
模型训练示例如下:

模型训练阶段损失值及验证集准确率变化如下:
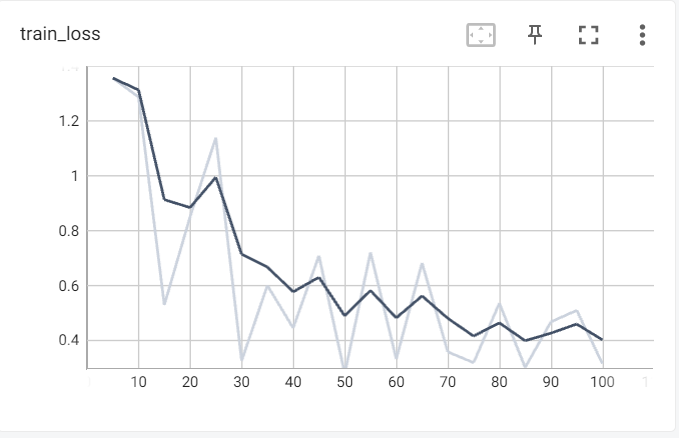
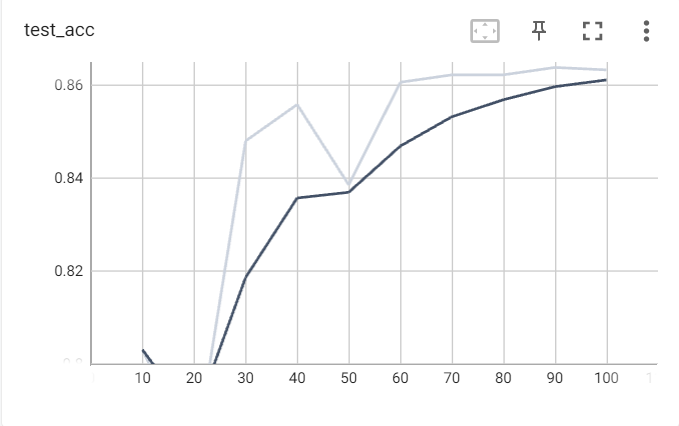
模型推理
模型训练需要运行predict.py文件,可以采用项目中以提供的模型,也可以采用自己训练后的模型。
命令如下:
python3 predict.py --device 0 --max_len 256
注意:如果修改模型路径,请修改–model_path参数。
模型推理示例如下:
样例1:
输入的评论数据:这家酒店是我在携程定的酒店里面是最差的,房间设施太小气,环境也不好,特别是我住的那天先是第一晚停了一会儿电,第二天停水,没法洗漱,就连厕所也没法上,糟糕头顶。
情感极性:负向
样例2:
输入的评论数据:这个宾馆的接待人员没有丝毫的职业道德可言。我以前定过几次这个宾馆,通常情况下因为入住客人少,因此未发生与他们的冲突,此于他们说要接待一个团,为了腾房,就要强迫已入住的客人退房,而且态度恶劣,言语嚣张,还采用欺骗手段说有其他的房间。
情感极性:负向
样例3:
输入的评论数据:香港马可最吸引人的地方当然是她便利的条件啦;附近的美心酒楼早茶很不错(就在文化中心里头),挺有特色的;
情感极性:正向
样例4:
输入的评论数据:绝对是天津最好的五星级酒店,无愧于万豪的品牌!我住过两次,感觉都非常好。非常喜欢酒店配备的CD机,遥控窗帘,卫生间电动百页窗。早餐也非常好,品种多品质好。能在早餐吃到寿司的酒店不多,我喜欢这里的大堂,很有三亚万豪的风范!
情感极性:正向
我自己测试的效果:
开始对评论数据进行情感分析,输入CTRL + C,则退出
输入的评论数据为:这家酒店是我在携程定的酒店里面是有点问题的。
情感极性为:负向
输入的评论数据为:好吧,就这样吧。
情感极性为:负向
输入的评论数据为:好吧
情感极性为:负向
输入的评论数据为:好
情感极性为:负向
输入的评论数据为:豪酒店啊!
情感极性为:负向
输入的评论数据为:好酒店啊!
情感极性为:正向
输入的评论数据为:豪华酒店!
情感极性为:正向
输入的评论数据为:华酒店!
情感极性为:负向
输入的评论数据为:华丽酒店!
情感极性为:正向
我们看下model.py内容:
\# -\*- coding:utf-8 -\*-
from torch.nn import CrossEntropyLoss
import torch.nn as nn
import torch
from transformers.models.bert.modeling\_bert import BertModel, BertOnlyMLMHead, BertPreTrainedModel
class PromptModel(BertPreTrainedModel):
"""Prompt分类模型"""
def \_\_init\_\_(self, config):
super().\_\_init\_\_(config)
"""
初始化函数
Args:
config: 配置参数
"""
self.bert = BertModel(config, add\_pooling\_layer=False)
self.cls = BertOnlyMLMHead(config)
def forward(self, input\_ids, attention\_mask, mask\_index, token\_handler, words\_ids, words\_ids\_mask,
label=None):
"""
前向函数,计算Prompt模型预测结果
Args:
input\_ids:
attention\_mask:
mask\_index:
token\_handler:
words\_ids:
words\_ids\_mask:
label:
Returns:
"""
# 获取BERT模型的输出结果
sequence\_output = self.bert(input\_ids=input\_ids, attention\_mask=attention\_mask)\[0\]
# 经过一个全连接层,获取隐层节点状态中的每一个位置的词表
logits = self.cls(sequence\_output)
# 获取批次数据中每个样本内容对应mask位置标记
logits\_shapes = logits.shape
mask = mask\_index + torch.range(0, logits\_shapes\[0\] - 1, dtype=torch.long, device=logits.device) \* \\
logits\_shapes\[1\]
mask = mask.reshape(\[-1, 1\]).repeat(\[1, logits\_shapes\[2\]\])
# 获取每个mask标记对应的logits内容
mask\_logits = logits.reshape(\[-1, logits\_shapes\[2\]\]).gather(0, mask).reshape(-1, logits\_shapes\[2\])
# 获取答案空间映射的标签向量
label\_words\_logits = self.process\_logits(mask\_logits, token\_handler, words\_ids, words\_ids\_mask)
# 将其进行归一化以及获取对应标签
score = torch.nn.functional.softmax(label\_words\_logits, dim=-1)
pre\_label = torch.argmax(label\_words\_logits, dim=1)
outputs = (score, pre\_label)
# 当label不为空时,计算损失值
if label is not None:
loss\_fct = CrossEntropyLoss()
loss = loss\_fct(label\_words\_logits, label)
outputs = (loss,) + outputs
return outputs
def process\_logits(self, mask\_logits, token\_handler, words\_ids, words\_ids\_mask):
"""
获取答案空间映射的标签向量,用于分类判断
Args:
mask\_logits: mask位置信息
token\_handler: 多token操作策略,包含first、mask和mean
words\_ids: 标签词id矩阵
words\_ids\_mask: 标签词id掩码矩阵
Returns:
"""
# 获取标签词id及掩码矩阵
label\_words\_ids = nn.Parameter(words\_ids, requires\_grad=False)
label\_words\_mask = nn.Parameter(torch.clamp(words\_ids\_mask.sum(dim=-1), max=1), requires\_grad=False)
# 获取mask位置上标签词向量
label\_words\_logits = mask\_logits\[:, label\_words\_ids\]
# 根据多token操作策略进行标签词向量构建
if token\_handler == "first":
label\_words\_logits = label\_words\_logits.select(dim=-1, index=0)
elif token\_handler == "max":
label\_words\_logits = label\_words\_logits - 1000 \* (1 - words\_ids\_mask.unsqueeze(0))
label\_words\_logits = label\_words\_logits.max(dim=-1).values
elif token\_handler == "mean":
label\_words\_logits = (label\_words\_logits \* words\_ids\_mask.unsqueeze(0)).sum(dim=-1) / (
words\_ids\_mask.unsqueeze(0).sum(dim=-1) + 1e-15)
# 将填充的位置进行掩码
label\_words\_logits -= 10000 \* (1 - label\_words\_mask)
# 最终获取mask标记对应的答案空间映射向量
label\_words\_logits = (label\_words\_logits \* label\_words\_mask).sum(-1) / label\_words\_mask.sum(-1)
return label\_words\_logits
提示学习的核心还是在里面:
# 获取每个mask标记对应的logits内容
mask\_logits = logits.reshape(\[-1, logits\_shapes\[2\]\]).gather(0, mask).reshape(-1, logits\_shapes\[2\])
# 获取答案空间映射的标签向量
label\_words\_logits = self.process\_logits(mask\_logits, token\_handler, words\_ids, words\_ids\_mask)
# 将其进行归一化以及获取对应标签
上述模型是一个基于BERT的Prompt分类模型,主要由两部分组成:
-
self.bert:这是BERT模型的主体部分,用于提取输入文本的特征表示。
-
self.cls:这是一个全连接层,用于从BERT模型的输出中获取每个位置的词表。
模型的功能主要是通过BERT模型提取输入文本的特征,然后通过全连接层获取每个位置的词表,最后通过处理logits和计算损失值来进行分类预测。
在前向传播过程中,模型首先获取BERT模型的输出结果,然后经过全连接层获取每个位置的词表,然后获取每个mask标记对应的logits内容,然后获取答案空间映射的标签向量,最后计算损失值。
在处理logits的过程中,模型首先获取标签词id及掩码矩阵,然后获取mask位置上标签词向量,然后根据多token操作策略进行标签词向量构建,然后将填充的位置进行掩码,最后获取mask标记对应的答案空间映射向量。
总的来说,这个模型的主要功能是进行文本分类预测。
【模型训练】
def train(model, device, train\_data, test\_data, args, tokenizer):
"""
训练模型
Args:
model: 模型
device: 设备信息
train\_data: 训练数据类
test\_data: 测试数据类
args: 训练参数配置信息
tokenizer: 分词器
Returns:
"""
tb\_write = SummaryWriter()
if args.gradient\_accumulation\_steps < 1:
raise ValueError("gradient\_accumulation\_steps参数无效,必须大于等于1")
# 计算真实的训练batch\_size大小
train\_batch\_size = int(args.train\_batch\_size / args.gradient\_accumulation\_steps)
train\_sampler = RandomSampler(train\_data)
# 构造训练所需的data\_loader
train\_data\_loader = DataLoader(train\_data, sampler=train\_sampler,
batch\_size=train\_batch\_size, collate\_fn=collate\_func)
total\_steps = int(len(train\_data\_loader) \* args.num\_train\_epochs / args.gradient\_accumulation\_steps)
logger.info("总训练步数为:{}".format(total\_steps))
model.to(device)
# 获取模型所有参数
param\_optimizer = list(model.named\_parameters())
optimizer\_grouped\_parameters = \[
{'params': \[p for n, p in param\_optimizer if not any(
nd in n for nd in args.requires\_grad\_params)\], 'weight\_decay': 0.01},
{'params': \[p for n, p in param\_optimizer if any(
nd in n for nd in args.requires\_grad\_params)\], 'weight\_decay': 0.0}
\]
# 冻结不训练的参数
for name, param in model.named\_parameters():
if not any(r\_name in name for r\_name in args.requires\_grad\_params):
param.requires\_grad = False
# 验证是否冻结成功
requires\_grad\_params = \[\]
for name, param in model.named\_parameters():
if param.requires\_grad:
requires\_grad\_params.append(name)
print("需要训练参数为{},大小为{}".format(name, param.size()))
# 设置优化器
optimizer = AdamW(optimizer\_grouped\_parameters,
lr=args.learning\_rate, eps=args.adam\_epsilon)
scheduler = get\_linear\_schedule\_with\_warmup(optimizer, num\_warmup\_steps=int(args.warmup\_proportion \* total\_steps),
num\_training\_steps=total\_steps)
# 清空cuda缓存
torch.cuda.empty\_cache()
# 将模型调至训练状态
model.train()
tr\_loss, logging\_loss, min\_loss = 0.0, 0.0, 0.0
global\_step = 0
words\_ids = train\_data.words\_ids.to(device)
words\_ids\_mask = train\_data.words\_ids\_mask.to(device)
# 开始训练模型
for iepoch in trange(0, int(args.num\_train\_epochs), desc="Epoch", disable=False):
iter\_bar = tqdm(train\_data\_loader, desc="Iter (loss=X.XXX)", disable=False)
for step, batch in enumerate(iter\_bar):
# 获取模型训练每个批次所需的输入内容,并放到对应设备上
input\_ids = batch\["input\_ids"\].to(device)
attention\_mask = batch\["attention\_mask"\].to(device)
mask\_index = batch\["mask\_index"\].to(device)
label = batch\["label"\].to(device)
# 获取训练结果
outputs = model.forward(input\_ids=input\_ids, attention\_mask=attention\_mask, mask\_index=mask\_index,
token\_handler=args.token\_handler,
words\_ids=words\_ids, words\_ids\_mask=words\_ids\_mask,
label=label)
loss = outputs\[0\]
tr\_loss += loss.item()
# 将损失值放到Iter中,方便观察
iter\_bar.set\_description("Iter (loss=%5.3f)" % loss.item())
# 判断是否进行梯度累积,如果进行,则将损失值除以累积步数
if args.gradient\_accumulation\_steps > 1:
loss = loss / args.gradient\_accumulation\_steps
# 损失进行回传
loss.backward()
torch.nn.utils.clip\_grad\_norm\_(model.parameters(), args.max\_grad\_norm)
# 当训练步数整除累积步数时,进行参数优化
if (step + 1) % args.gradient\_accumulation\_steps == 0:
optimizer.step()
scheduler.step()
optimizer.zero\_grad()
global\_step += 1
# 如果步数整除logging\_steps,则记录学习率和训练集损失值
if args.logging\_steps > 0 and global\_step % args.logging\_steps == 0:
tb\_write.add\_scalar("lr", scheduler.get\_lr()\[0\], global\_step)
tb\_write.add\_scalar("train\_loss", (tr\_loss - logging\_loss) /
(args.logging\_steps \* args.gradient\_accumulation\_steps), global\_step)
logging\_loss = tr\_loss
# 每个Epoch对模型进行一次测试,记录测试集的损失
eval\_loss, eval\_acc = evaluate(model, device, test\_data, args)
tb\_write.add\_scalar("test\_loss", eval\_loss, global\_step)
tb\_write.add\_scalar("test\_acc", eval\_acc, global\_step)
print("test\_loss: {}, test\_acc:{}".format(eval\_loss, eval\_acc))
model.train()
# 每个epoch进行完,则保存模型
output\_dir = os.path.join(args.output\_dir, "checkpoint-{}".format(global\_step))
model\_to\_save = model.module if hasattr(model, "module") else model
model\_to\_save.save\_pretrained(output\_dir)
tokenizer.save\_pretrained(output\_dir)
# 清空cuda缓存
torch.cuda.empty\_cache()
关键代码:
for name, param in model.named_parameters():
if not any(r\_name in name for r\_name in args.requires\_grad\_params):
param.requires\_grad = False
这段代码的作用是冻结模型中的某些参数,使它们在训练过程中不会被更新。
具体来说,model.named_parameters()是一个迭代器,它返回模型中所有参数的名称(name)和值(param)。然后,对于每一个参数,它检查参数的名称是否包含在args.requires_grad_params列表中。如果参数的名称不在这个列表中,那么就将这个参数的requires_grad属性设置为False,这意味着在训练过程中,这个参数的值不会被更新。
这种技术通常用于迁移学习,当我们想要固定预训练模型的某些层,只训练模型的其他部分时,就会用到这种技术。
最后如果您也对AI大模型感兴趣想学习却苦于没有方向👀
小编给自己收藏整理好的学习资料分享出来给大家💖

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉如何学习AI大模型?👈
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。