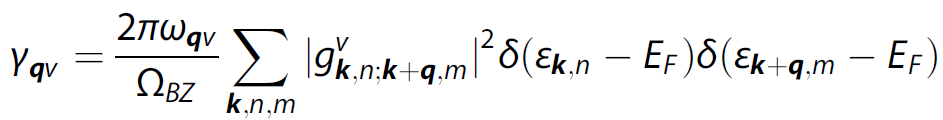机器学习课程学习周报十四
文章目录
- 机器学习课程学习周报十四
- 摘要
- Abstract
- 一、机器学习部分
- 1. EM算法与高斯混合模型
- 2. 概率论复习(三)
- 总结
摘要
本周的学习重点是EM算法与高斯混合模型的应用。单高斯模型无法有效拟合多峰数据分布,因此引入高斯混合模型,通过多个高斯概率密度函数的组合来精确描述数据分布。为了优化高斯混合模型的参数,采用EM算法进行迭代更新。此外,还复习了概率论中的重要概念,为模型的深入理解提供了理论支持。
Abstract
This week’s focus is on the application of the EM algorithm and Gaussian Mixture Models (GMM). A single Gaussian model cannot effectively fit multi-modal data distributions, hence the introduction of GMM, which combines multiple Gaussian probability density functions to accurately describe data distributions. The EM algorithm is employed to iteratively update parameters for optimizing GMM. Additionally, key concepts in probability theory were reviewed to provide theoretical support for deeper model understanding.
一、机器学习部分
1. EM算法与高斯混合模型

如果我们现在有如上图所示的数据分布,能用单高斯模型来拟合这样的数据分布吗?

答案显然是不行的,因为单高斯模型(Single Gaussian Model,SGM)只具有单一的峰值。这种数据分布需要通过混合密度建模,例如使用高斯混合模型(Gaussian Mixture Model, GMM)。

高斯混合模型是单高斯模型的延伸,就是采用多个高斯概率密度函数(正态分布曲线)精确地量化变量分布,是将变量分布分解为若干基于高斯概率密度函数(正态分布曲线)分布的统计模型。高斯混合模型可以平滑地近似任何形状的分布。K个单高斯模型混合在一起的模型,就是高斯混合模型。

上图是使用高斯混合模型拟合这样的数据分布的结果。

现在我们有一数据分布,如上图,它可能从黑色、蓝色或红色的高斯分布中取出,这三种高斯分布对应不同的参数
θ
=
{
μ
,
∑
}
\theta = \left\{ {\mu ,\sum } \right\}
θ={μ,∑},现在我们需要找出能最好拟合这一数据分布的高斯分布是哪一个?是黑色、蓝色、红色?还是其他的高斯分布?对于单高斯模型,我们估计参数
θ
=
{
μ
,
∑
}
\theta = \left\{ {\mu ,\sum } \right\}
θ={μ,∑}可以通过最大似然估计,利用对数似然函数对参数
θ
\theta
θ求偏导得到估计的参数值。

如果对高斯混合模型应用最大似然估计,并不能得到关于参数
θ
\theta
θ的解析解。在上一步推导单高斯模型时,我们是先算出了
μ
M
L
E
{\mu _{MLE}}
μMLE,然后将其带入到
∑
M
L
E
{\sum _{MLE}}
∑MLE的解析式中,算出
∑
M
L
E
{\sum _{MLE}}
∑MLE的值。对于高斯混合模型来说,对数似然函数的
log
\log
log中存在求和,这对于求偏导来说不是一件容易的事,其次即使去求偏导后也无法写出关于参数
θ
\theta
θ的解析解。为了解决这个问题,采用一种迭代的算法,不断地更新参数
θ
\theta
θ,这种算法是EM算法(Expectation Maximization,期望最大算法)。


2. 概率论复习(三)

















总结
通过本周的学习,掌握了高斯混合模型的基本原理及其在复杂数据分布拟合中的优势。通过EM算法的应用,理解了参数优化的过程和挑战,其中的数学原理还需要深究。同时,概率论的复习强化了对随机过程和统计模型的理解,为后续的学习打下了坚实基础。