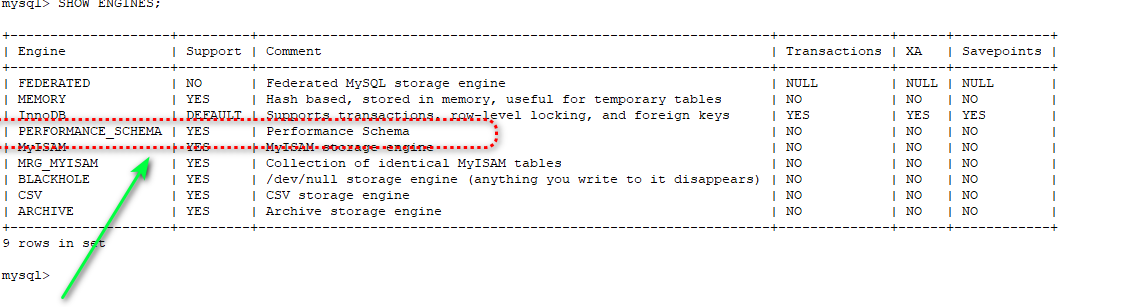
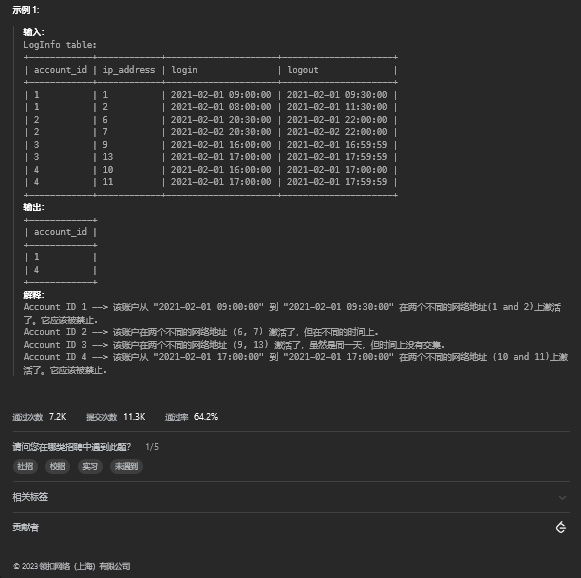
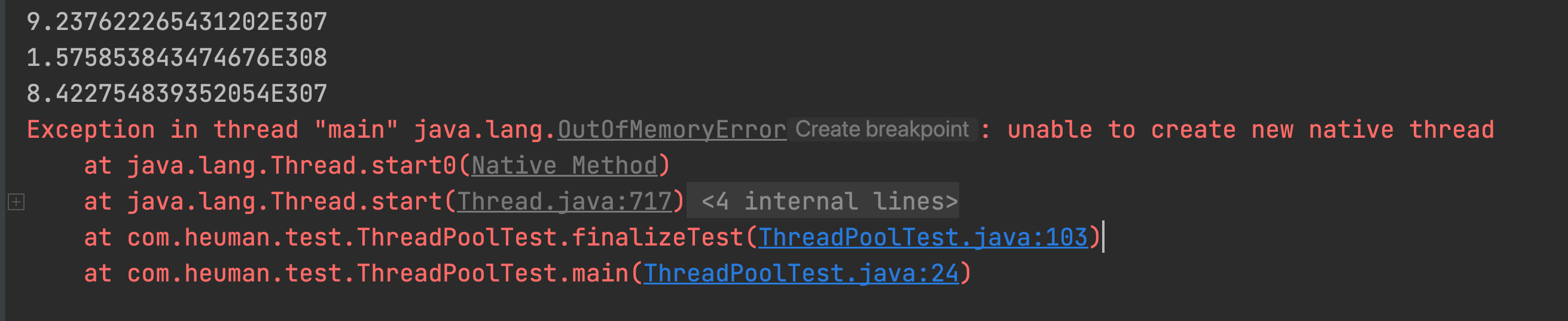
2、Stable Diffusion
Stable Diffusion 是一种高效的文本到图像生成模型,它利用扩散模型(Diffusion Model)技术将自然语言描述转换为高质量的图像。其工作原理是通过反向扩散过程,逐渐将噪声引导到符合输入文本描述的图像上。相比其他生成模型(如 GANs),扩散模型在训练稳定性和图像生成质量方面具有显著优势。
Diffusion Model
Diffusion Model论文链接:Denoising Diffusion Probabilistic Models.
在介绍Stable Diffusion之前,必须先对Diffusion Model的原理有所了解,Stable Diffusion就是以Diffusion Model为基础进行构建,Diffusion Model(扩散模型) 是一种生成模型,近年来在图像生成任务中表现优异,尤其是在高质量图像生成方面,如 DALL·E 2 和 Stable Diffusion 等模型的基础就是扩散模型。其核心思想是通过对数据添加噪声,然后逐步学习去噪的过程,从而生成新数据。
本文只介绍他的大致原理,至于为什么公式推导,可以查看Diffusion Model论文原文
扩散模型的工作机制分为两个阶段:正向扩散过程 和 逆向去噪过程。

左边为正向扩散,右边为逆向去噪。在 Diffusion Model 中,逆向过程通常使用U-Net 神经网络来进行训练,该网络通过预测输入噪声中的噪声成分,逐步将噪声图像转换为清晰的图像。同时,利用时间嵌入使模型能够处理不同时间步长的去噪任务,通过最小化噪声预测的损失函数,使模型在去噪过程中逐步恢复图像的细节。
正向扩散过程
在正向过程中,扩散模型对真实数据(如图像)逐步加入噪声,直到将数据变成完全的高斯噪声。这个过程可以通过一系列步骤来模拟,逐步将原始数据扰动成噪声,正向扩散过程遵循预设的马尔可夫链规则。

逆向去噪过程
逆向过程是生成数据的关键,它从完全的噪声图像开始,逐步去除噪声,以恢复真实的高质量数据。模型在每一步预测并去除噪声,逐渐重建出与训练数据相似的图像。这一步骤类似于学习一个去噪自编码器,通过模型学习每一步去噪操作,逆转噪声的扩散过程,最终生成类似原始分布的数据。
其中,模型需要学习参数化的 μθ和 Σθ,即如何从噪声数据逐渐还原出清晰的图像。实际上就是计算方差和均值。

损失函数
通常使用均方误差(MSE)作为损失函数,具体形式如下:
这里,ϵ是添加的真实噪声,而 ϵθ是模型输出的噪声预测。通过最小化该损失,模型能够逐步学会如何从噪声中恢复原始图像。

图像直观解释
上面为正向扩散过程,下面为逆向去噪

Stable Diffusion
Stable Diffusion论文链接:High-Resolution Image Synthesis with Latent Diffusion Models
上文介绍了Diffusion Model,Stable Diffusion 正是在 Diffusion Model 的基础上进行了改进。简单来说,Stable Diffusion 在逆向去噪过程中,不仅依赖于生成时的噪声信息,还能够引入更多的辅助信息来帮助模型更好地进行逆向去噪。只要这些辅助信息能够被编码成固定维度,就可以融入逆向还原的过程中,从而提升模型训练效果和生成结果的质量。
模型架构图
从图中可以看出,左边粉色的框中是U-Net 编码器-解码器结构,中间绿色框为噪声注入与去噪过程,右边为生成辅助信息的模块(本文使用CLIP),下面将分别解释各个结构的作用与细节。

U-Net 编码器-解码器结构
上图中左边粉色的框中是U-Net 编码器-解码器结构:
编码器:U-Net 结构的一部分,用于提取图像中的特征。编码器逐步将图像中的信息压缩成低维表示,并捕捉多尺度特征,这对于生成过程中的逐步去噪至关重要。
解码器:U-Net 结构的另一部分,逐步还原图像。解码器通过多次跳跃连接(skip connections)从编码器中获取不同层级的特征,并将噪声图像逐渐恢复为高质量图像。
噪声注入与去噪过程
中间绿色框为噪声注入与去噪过程:
- 正向扩散过程中,Stable Diffusion 将随机噪声逐渐添加到图像中,直到图像变成完全的噪声。
- 逆向扩散过程通过逐步去除噪声来重建图像,Stable Diffusion 使用 U-Net 结构和条件信息来预测并执行去噪。与传统扩散模型不同,Stable Diffusion 在逆向去噪过程中引入了辅助信息(如文本或其他条件),使得去噪过程不仅依赖于噪声,还能够根据条件输入生成目标结果。具体来说,U-Net 的每一层都应用了注意力机制,允许模型更加有效地捕捉长距离依赖关系。在这个过程中,U-Net 使用图像本身生成查询(q),而使用辅助信息生成键(k)和值(v)。通过计算 q 和 k之间的相似性,模型能够动态地加权和选择与当前特征相对应的值(v),从而实现对特征的生成和优化。这种机制增强了模型在生成图像时的表达能力,使其能更好地符合输入的条件。
生成辅助信息的模块
论文中使用文本数据作为辅助数据进行辅助,那么就使用到将文本翻译成图像特征的模型。
CLIP 是一个能够将图像和文本映射到相同特征空间中的模型。在 Stable Diffusion 中,CLIP 主要用于提供文本指导,即根据输入的文本描述来生成符合语义的图像。CLIP 提供的文本和图像特征嵌入被整合到扩散模型的逆向去噪过程中,以确保生成的图像与输入文本描述相符。
加入了辅助信息,为什么可以使用和Diffusion Model一样的原理?
由上文中给出Diffusion Model的正向扩散和逆向去噪过程的公式证明,同样的加入辅助信息后,证明仍使用贝叶斯公式,只是加了一个辅助公式。
在 Stable Diffusion 中,我们引入了条件信息 c(例如文本嵌入),以帮助生成与特定条件相符的图像。在逆向去噪过程中,辅助信息的引入不会改变基本的推理逻辑。可以通过以下步骤证明这一点:
- 引入条件信息
在逆向去噪的情况下,模型不仅依赖于噪声图像 Xt,还依赖于条件信息 c。因此,逆向去噪的公式可以扩展为:
- 预测均值与方差的条件化
在这个公式中,μθ和 Σθ 的计算是条件化的,即它们不仅依赖于当前的噪声图像 Xt,还依赖于辅助信息 c。例如,模型可以用 CLIP 提供的文本嵌入作为条件信息,来影响去噪的均值和方差的预测。
- 保持逆向逻辑不变
尽管我们引入了辅助信息,逆向去噪的推理逻辑仍然保持不变,因为模型的目标仍然是最小化与真实数据分布的距离。损失函数的形式可以写作:
这里 ϵθ 是模型预测的噪声,依然使用均方误差(MSE)来计算模型输出与真实噪声之间的差异。
- 总结
因此,Stable Diffusion 在引入辅助信息的同时,可以仍然使用与传统扩散模型相同的逆向去噪推理逻辑。这是因为辅助信息通过影响模型的均值和方差预测来引导生成过程,而不改变生成的基础机制。模型依然在每个时间步上逐步去噪,通过保留原有的逆向逻辑,结合条件输入,从而生成符合条件的高质量图像。


![HTB:Three[WriteUP]](https://i-blog.csdnimg.cn/direct/79f3c888792f464fa19e23134d6b117d.png)