JUC第23讲:Java线程池最佳实践
本文是JUC第23讲,先介绍为什么使用线程池;然后结合实际业务,讲解如何使用线程池,以及使用过程中踩过的坑。
1、Java线程池概述
1.1、什么是线程池?
线程池是一种用于管理和复用线程的机制。
线程池的主要组成部分包括工作线程、任务队列、线程管理器等。线程池的设计有助于优化多线程程序的性能和资源利用,同时简化了线程的管理和复用的复杂性。
1.2、为什么要有线程池?
线程池能够对线程进行统一分配,调优和监控:
- 控制和优化系统资源利用,线程池通过控制线程的数量,可以尽可能地压榨机器性能,提高系统资源利用率;
- 提高响应速度,线程池可以预先创建线程且通过多线程并发处理任务,提升任务的响应速度及系统的并发性能;
- 减少线程创建和销毁的开销,线程的创建和销毁需要消耗系统资源,线程池通过复用线程,避免了对资源的频繁操作,从而提高系统性能;
2、Java线程池执行流程

问题1:线程池的核心线程可以回收吗?
ThreadPoolExecutor 默认不回收核心线程,但是提供了 allowCoreThreadTimeOut(boolean value) 方法,当参数为true时,可以在达到线程空闲时间后,回收核心线程,在业务代码中,如果线程池是周期性的使用,可以考虑将该参数设置为true;
ThreadPoolExecutor executor = new ThreadPoolExecutor(3, 5,
5L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1));
// 默认情况下,核心线程不会因为空闲而被终止,我们可以通过以下方法改变这一行为
executor.allowCoreThreadTimeOut(true);
见demo10 核心线程回收
问题2:线程池在提交任务前,可以提前创建线程吗?
ThreadPoolExecutor 提供了两个方法:
1. prestartCoreThread(): 启动一个线程,等待任务,如果核心线程数已达到,这个方法返回false,否则返回true;
2. prestartAllCoreThreads(): 启动所有的核心线程,返回启动成功的核心线程数 。
通过这种设置,可以在提交任务前,完成核心线程的创建,从而实现线程池预热的效果;
// 预热单个核心线程
executorService.prestartCoreThread();
// 输出当前核心线程数
Thread.sleep(100);
System.out.println("Active threads after prestarting one core thread: " + executorService.getPoolSize());
// 预热所有核心线程
executorService.prestartAllCoreThreads();
Thread.sleep(2000);
// 输出当前核心线程数
System.out.println("Active threads after prestarting all core threads: " + executorService.getPoolSize());
见demo11 核心线程池预热
2.1、业务中如何使用线程池
场景1:需要快速响应用户请求
描述:用户发起的实时请求,服务追求响应时间。比如说用户要查看一个商品的信息,那么我们需要将商品维度的一系列信息如商品的价格、优惠、库存、图片等等聚合起来,展示给用户。
// 背景:获取sku信息 0.5s 获取图片信息 0.5s 获取类目属性信息 1s 获取库存信息 0.5s 获取商品详情信息 1s
// 如果顺序调用,那么,用户需要 3.5s 后才能看到商品详情页的内容,很显然是不能接受的。
// 如果有线程池同时完成这 5 步操作,也许只需要 1s 即可完成响应。
// TPS目标 1500
// 机器配置:4C10G(JVM 6G)(6台)
// 核心数:读操作线程池,核心线程数和最大线程数:200个,阻塞队列长度:10000,并通过配置中心可以动态调整线程数和队列长度,保活时间为0,重写线程工厂
// 拒绝策略:重写拒绝策略,跟CallerRunsPolicy一样,超出后需要调用者线程处理,多了记录日志
// demo14
public TestItemDetailThreadPool(int threadSize, int queueLength) {
super(threadSize, threadSize, 0, TimeUnit.SECONDS, new LinkedBlockingDeque<>(queueLength),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r,
NAME + "-" + threadNum.getAndDecrement());
}
}, new RewriteCallerRunsPolicy());
}
/**
* 默认线程大小
*/
public static final int DEFAULT_THREAD_SIZE = 100;
/**
* 默认队列大小
*/
public static final int DEFAULT_QUEUE_SIZE = 10000;
private static final AtomicInteger threadNum = new AtomicInteger(1);
}
/**
* 线程池已经无法处理,重写饱和策略,跟CallerRunsPolicy一样,超出后需要调用者自己的线程处理,多了记录日志
*/
private static class RewriteCallerRunsPolicy implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
log.error("线程池:{} 需要处理的任务已经超过任务队列长度(当前队列长度:{}), 需要当前的工作线程自行处理当前任务", NAME, executor.getQueue().size());
if (!executor.isShutdown()) {
r.run();
}
}
}
场景2:快速处理批量任务
描述:网络货运项目,需要实现批量OCR识图功能,识图使用了腾讯云提供的功能,识别比较慢(大概2~3s),使用的业务方有运营平台和司机端,因此使用多线程加速OCR识图。
// 背景:司机端上传的认证信息,需要支持OCR识别,识别如下信息:身份证、行驶证、驾驶证识别;从业资格证、道路运输证,用户注册信息会批量上传
// 因此,使用ocr识图专用线程池,快速处理批量任务
// 机器配置:2C4G JVM(2G)
// 核心数:核心线程数和最大线程数:5个,阻塞队列长度:100,保活时间为0,重写线程工厂
// 拒绝策略:重写拒绝策略,跟AbortPolicy一样,超出后直接抛出异常,多了记录日志
// 见demo12
@Bean(name = "asyncImgOcrThreadPool")
public Executor asyncImgOcrThreadPool() {
final AtomicInteger threadNum = new AtomicInteger(1);
return new LazyTraceThreadPoolExecutor(
5,
5,
0,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(100),
r -> new Thread(r, "asyncImgOcrThreadPool-" + threadNum.getAndDecrement()),
(r, executor) -> {
log.error("线程池:{} 需要处理的任务已经超过任务队列长度(当前队列长度:{}), 直接抛出异常", "asyncImgOcrThreadPool", executor.getQueue().size());
throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + executor);
});
}
场景3:延迟执行线程池
描述:在智能策略中可以选择智能系统设置策略的执行条件,执行动作选择智能系统的操作,可通过定时、实时与手动方式执行策略。例如:创建一个每天中午12点执行一次,每次执行间隔为1小时的任务,执行5次。
// 背景:管理员填写智能策略,任务按配置周期执行,调用量较少
// 机器配置:无权限查看
// 核心数:核心线程数1,最大线程数:Integer.MAX_VALUE,阻塞队列长度:Integer.MAX_VALUE,保活时间为60s,
// 拒绝策略:默认的拒绝策略,AbortPolicy,超出后直接抛出异常
// 待改进的地方:由于阻塞队列为MAX_VALUE,存在OOM的风险,应该使用自定义线程池配置
// demo15
public class ThreadPoolTaskExecutor extends ExecutorConfigurationSupport implements AsyncListenableTaskExecutor, SchedulingTaskExecutor {
private final Object poolSizeMonitor = new Object();
private int corePoolSize = 1;
private int maxPoolSize = Integer.MAX_VALUE;
private int keepAliveSeconds = 60;
private int queueCapacity = Integer.MAX_VALUE;
private boolean allowCoreThreadTimeOut = false;
}
3、Java线程池使用注意事项
问题1:如何选择合适的线程池参数?
public ThreadPoolExecutor(int corePoolSize, // 核心线程数
int maximumPoolSize, //最大线程数
long keepAliveTime, // 线程的空闲时间
TimeUnit unit, // 空闲时间的单位(秒、分、小时等等)
BlockingQueue<Runnable> workQueue, // 等待队列
ThreadFactory threadFactory, // 线程工厂
RejectedExecutionHandler handler) // 拒绝策略
// 拒绝策略
ThreadPoolExecutor.AbortPolicy //丢弃任务并抛出RejectedExecutionException异
ThreadPoolExecutor.DiscardPolicy //也是丢弃任务,但是不抛出异常
ThreadPoolExecutor.DiscardOldestPolicy //丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy //由调用线程直接处理该任务(可能为主线程Main),保证每个任务执行完毕
推荐使用自定义的线程工厂,重写创建线程的方法,支持自定义创建线程的名称、优先级等属性,方便排查问题。
自己扩展RejectedExecutionHandler接口,自定义拒绝策略
见场景1和场景2
问题2:如何选择合适的线程池参数?
1)根据任务场景选择
CPU 密集型任务(N+1) 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1。比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
I/O 密集型任务(2N) 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
2)根据线程池用途选择
用途一:快速响应用户请求
比如说用户查询商品详情页,会涉及查询商品关联的一系列信息如价格、优惠、库存、基础信息等,站在用户体验的角度,希望商详页的响应时间越短越好,此时可以考虑使用线程池并发地查询价格、优惠、库存等信息,再聚合结果返回,降低接口总rt。这种线程池用途追求的是最快响应速度,所以可以考虑不设置队列去缓冲并发任务,而是尽可能设置更大的corePoolSize和maxPoolSize。
用途二:快速处理批量任务
比如说项目中在对接渠道同步商品供给时,需要查询大量的商品数据并同步给渠道,此时可以考虑使用线程池快速处理批量任务。这种线程池用途关注的是如何使用有限的机器资源,尽可能地在单位时间内处理更多的任务,提升系统吞吐量,所以需要设置阻塞队列缓冲任务,并根据任务场景调整合适的corePoolSize。
问题3:如何正确地创建线程池对象?
第一点:线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,同时规避资源耗尽的风险。
Executors各个方法的弊端:
Executors是一个 java.util.concurrent 包中的工具类,可以方便的为我们创建几种特定参数的线程池。
- FixedThreadPool:主要问题是堆积的请求处理队列可能会耗费非常大的内存,甚至OOM。
- CachedThreadPool:主要问题是线程数最大数是Integer.MAX_VALUE,可能会创建数量非常多的线程,甚至OOM。
- SingleThreadPool:单个线程的线程,核心线程数和最大线程数都是1,无界阻塞队列;
第二点:推荐使用饿汉式的单例模式创建线程池对象,支持灵活的参数配置
public class TestThreadPool {
/**
* 线程池
*/
private static ExecutorService executor = initDefaultExecutor();
/**
* 统一的获取线程池对象方法
*/
public static ExecutorService getExecutor() {
return executor;
}
private static final int DEFAULT_THREAD_SIZE = 16;
private static final int DEFAULT_QUEUE_SIZE = 10240;
private static ExecutorService initDefaultExecutor() {
return new ThreadPoolExecutor(DEFAULT_THREAD_SIZE, DEFAULT_THREAD_SIZE,
300, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(DEFAULT_QUEUE_SIZE),
new ThreadPoolExecutor.CallerRunsPolicy());
}
}
4、实战经验
4.1、相互依赖的子任务避免使用同一线程池
相互依赖的任务提交到同一线程池,父任务依赖子任务的执行结果,父任务get()执行结果时可能因为子任务还没执行完导致线程阻塞,如果提交的任务过多,线程池中的线程都被类似的父任务占用并阻塞,导致任务队列中的子任务没有线程去执行,最终出现线程饥饿的死锁现象。
// 见demo3
// 存在的问题:父任务必须拿到子任务执行结果,才能结束
public static ExecutorService executor= TestThreadPool.getExecutor();
public static void main(String[] args) throws Exception {
FatherTask fatherTask = new FatherTask();
Future<String> future = executor.submit(fatherTask);
future.get();
}
/**
* 父任务,里面异步执行子任务
*/
static class FatherTask implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("开始执行父任务");
SonTask sonTask = new SonTask();
Future<String> future = executor.submit(sonTask);
String s = future.get();
System.out.println("父任务已拿到子任务执行结果");
return s;
}
}
/**
* 子任务
*/
static class SonTask implements Callable<String> {
@Override
public String call() throws Exception {
//处理一些业务逻辑
System.out.println("子任务执行完成");
return null;
}
}
优化思路:
1)使用不同的线程池隔离有相互依赖的任务;
2)调用future.get()方法设置超时时间,这样做可以避免线程阻塞,但是依然会出现大量的超时异常。
4.2、合理选择submit()和execute()方法
execute(Runnable r):没有返回值,仅仅是把一个任务提交给线程池处理,轻量级方法,适用于处理不需要返回结果的任务;
submit(Runnable r):返回值为Future类型,future可以用来检查任务是否已经完成,获取任务的结果等,适用于需要处理返回结果的任务;
// demo13
// 线程池submit “吃”掉程序抛出的异常,导致我们对程序的错误一无所知。
// 程序没有任何日志记录,也没有任何错误提示,就好像一切正常。
public class TestTraceThreadpool {
public static class DivTask implements Runnable {
int a, b;
public DivTask(int a, int b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
double re = a / b;
System.out.println(re); // 结果 25.0 33.0 50.0 100.0
}
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ThreadPoolExecutor executorService = new ThreadPoolExecutor(
3,
5,
5,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1));
// 存在问题的代码
for (int i = 0; i < 5; i++) {
executorService.submit(new DivTask(100, i));
}
}
}
问题1:为什么线程池内部的submit方法不抛出异常?
追踪代码到 futureTask
public void run() {
if (state != NEW ||
!UNSAFE.compareAndSwapObject(this, runnerOffset,
null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
此时我们发现,异常已经被捕获了,并且调用了setexception方法。把我们的异常信息给了outcome。
protected void setException(Throwable t) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {
outcome = t;
UNSAFE.putOrderedInt(this, stateOffset, EXCEPTIONAL); // final state
finishCompletion();
}
}
到此我们就明白了为什么submit没有抛出异常了!
异常堆栈缺失问题以及解决方法
解法1:不使用submit,而是使用execute方法,或者使用future接收返回值 ❎
- 存在的问题:只能拿到部分堆栈信息,无法拿到线程池的调用者信息
解法2:使用增强trace的ThreadPool ✅
-
// 能拿到全部堆栈信息 // demo13 public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) { super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue); } @Override public void execute(Runnable command) { super.execute(wrap(command, clientTrace(), Thread.currentThread().getName())); } @Override public Future<?> submit(Runnable task) { return super.submit(wrap(task, clientTrace(), Thread.currentThread().getName())); } private Exception clientTrace() { return new Exception("client stack trace"); } private Runnable wrap(Runnable task, Exception clientTrace, String clientThreadName) { return new Runnable() { @Override public void run() { try { task.run(); } catch (Exception e) { clientTrace.printStackTrace(); throw e; } } }; }
4.3、请捕获线程池中子任务的代码异常
// 见demo2
// 如果线程池中执行任务的线程异常,发生异常的线程会销毁吗?其他任务还能正常执行吗?
public static ExecutorService executor = TestThreadPool.getExecutor();
public static void main(String[] args) {
executor.execute(() -> test("正常"));
executor.execute(() -> test("正常"));
executor.execute(() -> test("任务执行异常"));
executor.execute(() -> test("正常"));
executor.shutdown();
}
public static void test(String str) {
String result = "当前ThreadName为" + Thread.currentThread().getName() + ":结果" + str;
if (str.equals("任务执行异常")) {
throw new RuntimeException(result + "****执行异常");
} else {
System.out.println(result);
}
}
问题1:如果线程池中执行任务的线程异常,发生异常的线程会销毁吗?其他任务还能正常执行吗?

可以发现
1)线程池中执行任务的线程异常,并不会影响其他任务的执行,而且execute()提交任务,直接打印了异常信息。
底层实现:会调用workers.remove()移除当前线程,并调用addWorker()重新创建新的线程。
结论:业务代码中,请捕获子任务中的异常,否则会导致线程池中的工作线程频繁销毁、创建,造成资源浪费,违背了线程复用的设计原则。
5、踩坑记录
5.1、CallerRunsPolicy 拒绝策略踩坑,触发CallerRunsPolicy拒绝策略执行的任务,future.get(timeout)超时时间无效(会造成线上问题)
现象:拒绝策略配置为CallerRun,交给主线程去执行,在使用Future获取线程执行结果时,线程3并不是执行3s,而是10秒后得到响应结果。
// demo7
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 1, 10, TimeUnit.SECONDS
, new ArrayBlockingQueue<>(1)
, new ThreadPoolExecutor.CallerRunsPolicy());
executor.submit(() -> {
System.out.println("线程1开始执行");
sleepQuietly(2 * 60 * 1000);
System.out.println("线程1结束执行");
});
executor.submit(() -> {
System.out.println("线程2开始执行");
sleepQuietly(2 * 60 * 1000);
System.out.println("线程2结束执行");
});
long start = System.currentTimeMillis();
Future<String> future = executor.submit(() -> {
System.out.println("线程3开始执行");
sleepQuietly(10 * 1000);
System.out.println("线程3结束执行");
return LocalDateTime.now().format(DateTimeFormatter.ofPattern("HH:mm:ss"));
});
System.out.println("获取线程3执行结果");
String result = future.get(3, TimeUnit.SECONDS);
System.out.printf("线程3执行结果:%s, 耗时:%d秒", result, (System.currentTimeMillis() - start) / 1000);
执行结果:

原因:如果配置为 CallerRun 拒绝策略,在最大线程池满了后,交给主线程执行,因此专给线程池配置的超时时间会失效,实际执行的如下这个方法,只取决于线程执行时间。
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
5.2、触发 DiscardPolicy 拒绝策略的任务,future.get() 将一直阻塞
现象:如果future.get() 没有配置超时时间,当前线程会一直阻塞,不可用
// demo6
// 我们的期望是:丢弃无法处理的任务,且不会抛出异常
// 但是实际上:future.get() 将一直阻塞
ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 1, 10, TimeUnit.SECONDS
, new ArrayBlockingQueue<>(1)
, new ThreadPoolExecutor.DiscardPolicy() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
System.out.println("丢弃提交的任务");
super.rejectedExecution(r, e);
}
});
executor.submit(() -> {
System.out.println("线程1开始执行");
sleepQuietly(10 * 1000);
System.out.println("线程1结束执行");
});
executor.submit(() -> {
System.out.println("线程2开始执行");
sleepQuietly(10 * 1000);
System.out.println("线程2结束执行");
});
long start = System.currentTimeMillis();
Future<String> future = executor.submit(() -> {
System.out.println("线程3开始执行");
sleepQuietly(10 * 1000);
System.out.println("线程3结束执行");
return LocalDateTime.now().format(DateTimeFormatter.ofPattern("HH:mm:ss"));
});
System.out.println("获取线程3执行结果");
String result = future.get();
System.out.printf("[永远不会执行]线程3执行结果:%s, 耗时:%d秒", result, (System.currentTimeMillis() - start) / 1000);
执行结果:

原因:线程的状态不是完成状态,会被await掉(底层为LockSupport的park方法),除非被唤醒
解法:捕获异常
5.3、大量线程池实例导致内存上涨,ThreadPoolExecutor重写了finalize方法,JVM对于此类对象的回收有专有机制,但缺点之一是回收延迟(从变为可回收到被真正回收的时间间隔)不确定。
案例如下
// demo4
sleepQuietly(2000);
int i = 0;
while (i++ < 100000) {
sleepQuietly(10);
Executors.newSingleThreadExecutor().submit(() -> {
System.out.println(RandomUtils.nextDouble());
});
}
开始执行后通过jmap命令多次查看Finalizer和ThreadPoolExecutor的数量:
jmap -histo
jps | grep ThreadPoolDiscard | awk 'NR==1{print $1}'| grep -E ‘ThreadPoolExecutor$ | Finalizer$’jmap -histo 29996 | grep -E ‘ThreadPoolExecutor$ | Finalizer$’ (先由jps找到对应的进程号)
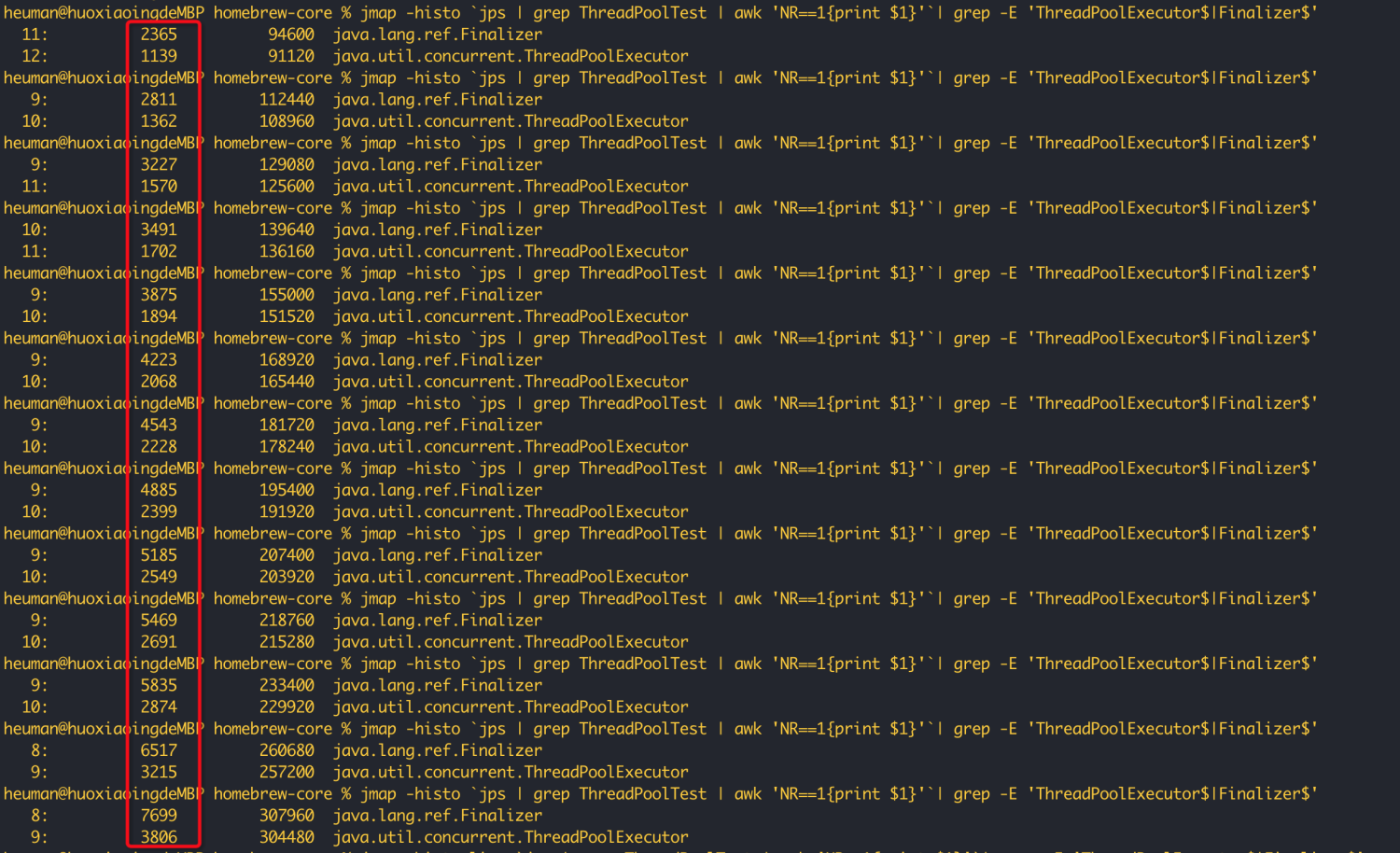
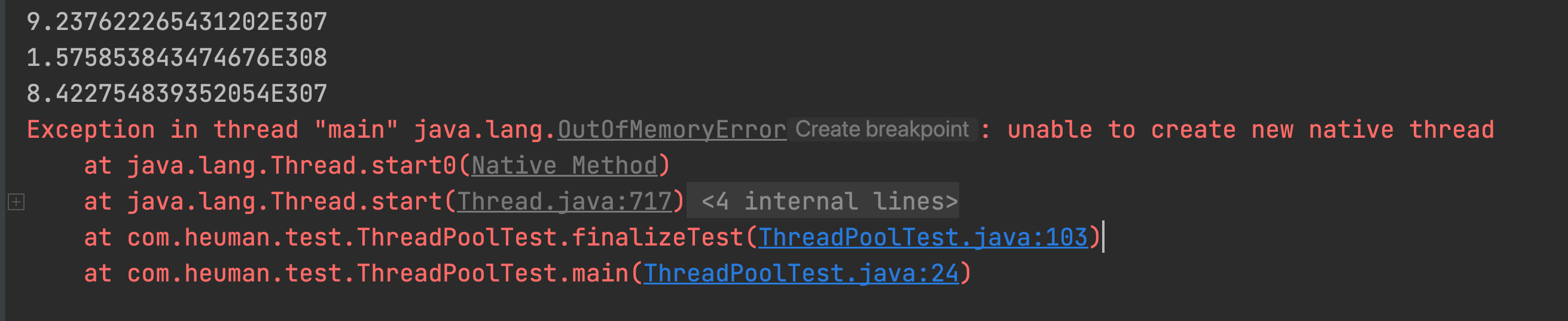
最终JVM也发生OOM:
可以参考这篇文章:JEP 421: Deprecate Finalization for Removal
这个问题带来两个启发:
1)不要在代码中使用局部变量定义线程池对象,这样不仅会导致频繁创建线程池对象,违背了线程复用的设计原则,还有可能造成局部变量的线程池对象无法及时垃圾回收的内存泄漏问题;
2)业务代码中,优先定义静态内部类而不是非静态内部类,可以有效防止内存泄露的风险。
5.4、Spring的@Async注解,如果不使用自定义线程池,默认为核心数8、阻塞队列长度为Integer.MAX_VALUE,会有OOM的风险
解法:应该定义一个自定义的线程池配置,并限制线程数和队列长度。
以下是如何在Spring中配置自定义线程池的示例:
@Configuration
@EnableAsync
public class AsyncConfig implements AsyncConfigurer {
@Bean(name = "taskExecutor")
public Executor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10); // 设置核心线程数
executor.setMaxPoolSize(20); // 设置最大线程数
executor.setQueueCapacity(100); // 设置队列长度
executor.setKeepAliveSeconds(60); // 设置线程空闲时间
executor.setThreadNamePrefix("Async-"); // 设置线程名前缀
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); // 设置拒绝策略
executor.initialize(); // 初始化线程池
return executor;
}
}
使用@Async注解时,你可以指定使用这个自定义的线程池,通过这种方式,你可以更好地控制线程池的行为,避免潜在的OOM风险。
@Service
public class AsyncService {
@Async("taskExecutor")
public CompletableFuture<String> asyncMethodWithConfiguredExecutor() {
// ... 方法实现 ...
}
}
5.5、创建线程或线程池时请指定有意义的线程名称,方便出错时排查
正例:自定义线程工厂,并且根据外部特征进行分组,比如,来自同一机房的调用,把机房编号赋值给 whatFeatureOfGroup:
public class UserThreadFactory implements ThreadFactory {
private final String namePrefix;
private final AtomicInteger nextId = new AtomicInteger(1);
// 定义线程组名称, 在利用 jstack 来排查问题时, 非常有帮助
UserThreadFactory(String whatFeatureOfGroup) {
namePrefix = "FromUserThreadFactory's" + whatFeatureOfGroup + "-Worker-";
}
@Override
public Thread newThread(Runnable task) {
String name = namePrefix + nextId.getAndIncrement();
Thread thread = new Thread(null, task, name, 0, false);
System.out.println(thread.getName());
return thread;
}
}











![[Python学习日记-31] Python 中的函数](https://i-blog.csdnimg.cn/direct/162340e3427b45ecb1fe5cf328876971.png)




![[c++高阶]模版进阶](https://i-blog.csdnimg.cn/direct/87ecf570e70540928d871200d70ec21d.png)

