当前的单图像超分辨率(SISR)算法有两种主要的深度学习模型,一种是基于卷积神经网络(CNN)的模型,另一种是基于Transformer的模型。前者利用不同卷积核大小的卷积层堆叠来设计模型,使得模型能够更好地提取图像的局部特征;后者利用自注意力机制来设计模型,使得模型能够通过自注意力机制在图像像素点之间建立长程依赖关系,从而更好地提取图像的全局特征。
然而,上述两种方法都面临着问题,因此本文提出了一种基于双向互补卷积和Transformer的新型轻量级多尺度特征融合网络模型,该模型通过双分支网络结构整合Transformer和卷积神经网络各自的特征,实现全局和局部信息的互相融合。
同时,考虑到由深度神经网络训练得到的低像素图像所造成的部分信息损失,本文设计了一种模块化的多级特征补充连接方法,将模型从浅层提取的特征图与从深度层提取的特征图进行融合,以最小化特征图像中的信息损失,从而最大程度地促进图像恢复,有助于获得更高质量的恢复图像。
实际结果最终显示,与具有相同参数数量的其他轻量级模型相比,本文提出的模型在,和图像恢复性能上都是最优的。
I Introduction
单图像超分辨率(SISR)问题是图像超分辨率领域的一个经典问题。这个领域的目标是将给定低分辨率的图像转换并恢复为相应的高分辨率图像。目前,这种技术已在医学影像、遥感、视频监控等图像领域得到广泛应用。近年来,基于深度学习的图像超分辨率算法得到了深入发展,已成为单图像超分辨率任务的主流方法。深度学习超分辨率算法的主要优势在于,它不再需要在早期阶段人为处理数据特征,而是使模型以端到端的方式学习LR和HR之间的映射函数,从而大大提高了相关SISR模型的性能。
在深度学习应用于图像超分辨率问题的初期阶段,主要是 Dong 等人 [7] 的工作。卷积神经网络主要被用于图像超分辨率任务。然而,使用卷积神经网络的SISR模型存在一个问题,即卷积神经网络的性能与其自身大小密切相关,也就是说,模型中的参数数量和计算量决定了卷积神经网络的性能。为了进一步提高和增强卷积神经网络的性能,通常的方法是增加模型的大小和深度。但是,参数过大并且计算和存储能力要求高的模型对硬件设备的要求较高。因此,对非专业设备进行部署和训练具有很大的挑战。所以,有必要研究如何降低图像超分辨率模型的参数数量和计算,同时保持与模型性能的平衡。
此外,随着Transformer在自然语言处理领域近年来的巨大成功,人们开始将Transformer,特别是注意力机制,迁移到计算机视觉领域。在这个背景下,Liu 等人 [9] 提出了尽管Swin Transformer模型在计算机视觉领域取得了巨大成功,但仍存在一个问题:模型内部窗口执行的自注意力计算只有局部注意力,而图像像素之间的全局依赖取决于窗口在网络模型中的移动距离。因此,采用小参数和小网络层数的Swin Transformer模型设计的图像超分辨率网络无法有效建立目标图像的全局依赖,从而性能仍有很大提升空间。
在轻量级单图像超分辨率网络的设计过程中,使用单一卷积神经网络或Transformer来实现人们期望的图像恢复性能是困难的。为了解决以上问题,本文提出了一种基于双路径的轻量级单图像超分辨率网络,其中一部分使用Transformer从图像中提取局部和区域特征,另一部分使用由深层可分卷积和空间自注意力模块组成的卷积神经网络从图像中提取全局细粒度特征。网络在模型中间阶段与每个分支提取的特征信息相互作用,使特征图在信息交互后仍保留有利的信息,从而实现提高模型的图像恢复和图像重建能力。
在双向特征融合方面,本文提出了一种基于多尺度卷积的特征融合模块。这个模块通过输入特征到不同卷积分支进行卷积和通道注意力计算,可以消除融合块处理后双分支特征明显的分界,使局部和全局信息能够完全融合。此外,本文在图像重构模块之前将所有中间阶段特征相加以加,并结合低频和高频信息,以充分利用低频和高频信息,最大限度地保留恢复图像的有效信息。
此外,为了改善模型在训练阶段学习图像特征的能力并在推理阶段减少计算工作量,本文采用repVGG设计思想在卷积分支上进行改进。该模型在模块中间的每个模块中通过添加另一个1x1卷积分支(除退化链接外),使卷积分支具有三个分支。这种设计增加了模型的复杂性,可以提高模型对图像特征的学习能力。在模型推理阶段,该模型然后删除了冗余的1x1卷积分支,这使模型在推理阶段减少了大量计算,并保持了相对稳定的图像恢复性能。
最后,在模型图像重构阶段,本文使用子像素卷积对特征进行上采样,这在该领域中广泛使用。
最终结果显示,与其他轻量级模型相比,本文提出的模型的图像恢复性能最优。
总之,本文的主要工作如下:
(1)设计了一种创新的两向融合网络,充分利用卷积和Transformer分支的特性和双向结构
(2)构建了一种高效的卷积网络分支,通过有序结合分层可分卷积和空间自注意力计算模块,使分支能够关注提取图像的全局细粒度信息和更广泛的图像上下文信息。
(3) 本文提出了一种新的多尺度双路径特征融合模块,该模块使双分支特征通过多次分割输入特征并多次执行卷积或通道注意力计算以及融合来互补信息。这样,不同架构分支的图像特征信息可以有效地集成,实现更详细和精确的超分辨率重建结果。
(4) 本文设计了一种新的特征多路复用模块,该模块通过多阶段特征融合保留有利于图像恢复的低频和高频信息,进一步补偿可能在上一步处理中丢失的高频细节,从而提高图像恢复质量。
II Related Works
Lightweight Single Image Super-Resolution Algorithms
最初,Dong等人[7]提出了一种基于卷积神经网络的单张图像超分辨率模型,称为SRCNN(使用卷积神经网络进行超分辨率)。这是第一个利用深度学习方法处理低分辨率图像恢复的模型,并取得了巨大成功。此后,国内外出现了大量使用深度学习及卷积神经网络来解决单张图像超分辨率问题的方法。对于一般卷积神经网络模型,随着层数和参数的增加,模型的表达能力和性能得到改善。然而,这种提高模型性能的方式有其局限性,因为随着网络大小的增加,大量参数和计算成本将会限制模型在硬件设备上的部署和训练。因此,为了解决这个问题,单张图像超分辨率领域出现了一系列轻量级基于卷积神经网络的方法,包括但不限于递归结构[12]、组卷积[13]等,以减少模型的参数和计算量。在本文中,也采用了基于深度可分卷积的上述方法来减少卷积神经网络的参数和计算量,从而提高了模型性能和计算效率。
Image Degradation Model
在单幅超分辨率研究中,通常假设低分辨率图像是通过图像退化操作从高分辨率图像获得的。因此,假设模型可以容易地建立低分辨率图像和高分辨率内容相同的高分辨率图像之间的映射关系,这也有助于后续的监督训练。基于这一点,单幅超分辨率模型的图像恢复过程可以被视为图像退化操作的逆过程,也可以看作是挖掘低分辨率图像和高分辨率图像之间的映射关系的过程。
图像退化[1]通常包含以下因素:降采样、模糊、几何变换和噪声。高分辨率图像通过选择其中一个或一组这些因素来获得对应 low分辨率图像。降采样方法通常采用双和三重降采样。模糊分为运动模糊和光学模糊。运动模糊是指成像设备(例如相机、移动电话)相对于被拍摄目标的运动所产生的模糊,而光学模糊是指简单的高斯模糊。几何变换是指图像的平移和旋转。另一方面,噪声根据时间分布分为高斯、伽马和指数噪声及其他相关噪声。
可以通过公式提供一个简要的 mass 减少操作概述:
其中 是退化函数 表示噪声。退化解 来源于高分辨率图像 和模糊 Kernel ,通过卷积操作和降采样获取。 表示降采样系数是 。
III Method
在本文中,提出了一种基于Transformer和卷积神经网络融合的新双向轻量级图像超分辨网络,如图2所示。
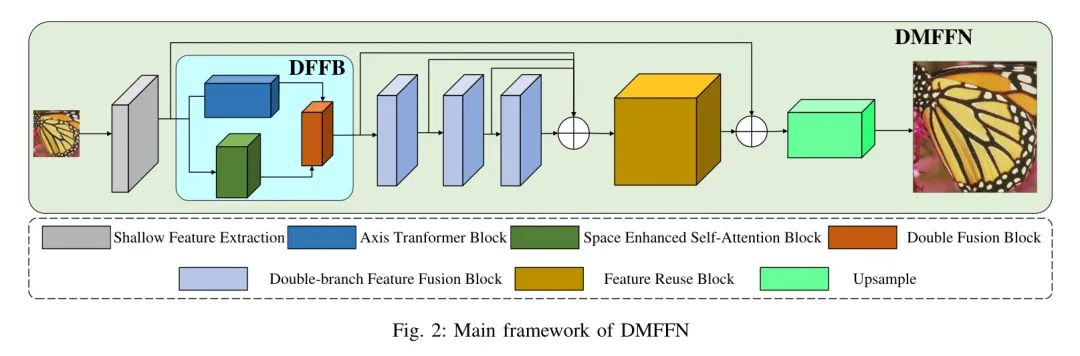
该网络主要由以下模块组成:浅层特征提取模块(SFB: 浅层特征块)、双路特征融合模块(DFFB: 双路特征融合块)、特征重用模块(FRB: 特征重用块)和双三倍上采样模块(上采样)。
模型首先让低分辨率图像通过浅层特征提取模块,该模块包括一个卷积和ELU激活函数,假设输入的低分辨率图像为:
然后,被输入特征提取与融合模块进行特征提取,得到每个阶段的中间特征:
接着,每个中间特征被拼接并输入到多路特征融合模块,得到融合特征图像:
最后,融合图像与浅层特征拼接并上采样,得到 reconstructed 高分辨率图像:
接下来,本文将详细介绍每个模块的内部组成和操作机制,以帮助理解网络的操作过程。
Double-Branch Feature Fusion Block Design
首先,是双特征融合模块(DFFB),其主要结构如图3所示。
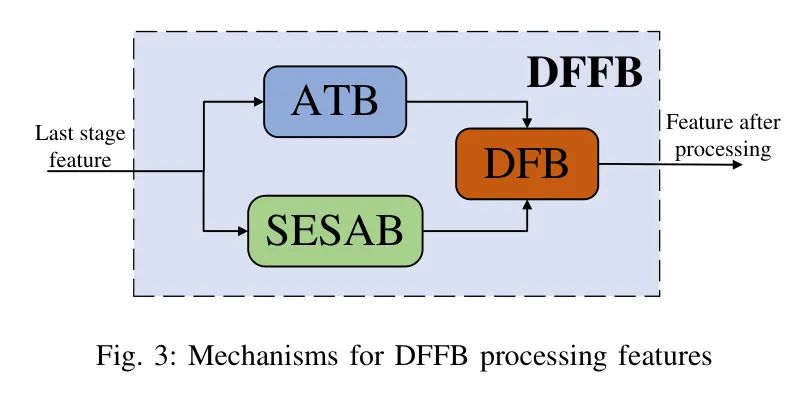
DFFB模块包括三个功能模块,分别是轴 Transformer 模块(ATB:轴 Transformer 模块),空间增强自注意力模块(SESAB:空间增强自注意力模块)和双通道融合模块(DFB:双通道融合模块)。
首先,是轴 Transformer 模块(ATB),其主要结构如图4所示。在DFFB中,ATB模块的主要作用是提取图像的局部和区域特征。通过自注意力机制,它建立图像像素点之间的区域依赖关系,以更好地提取图像的局部低频信息。
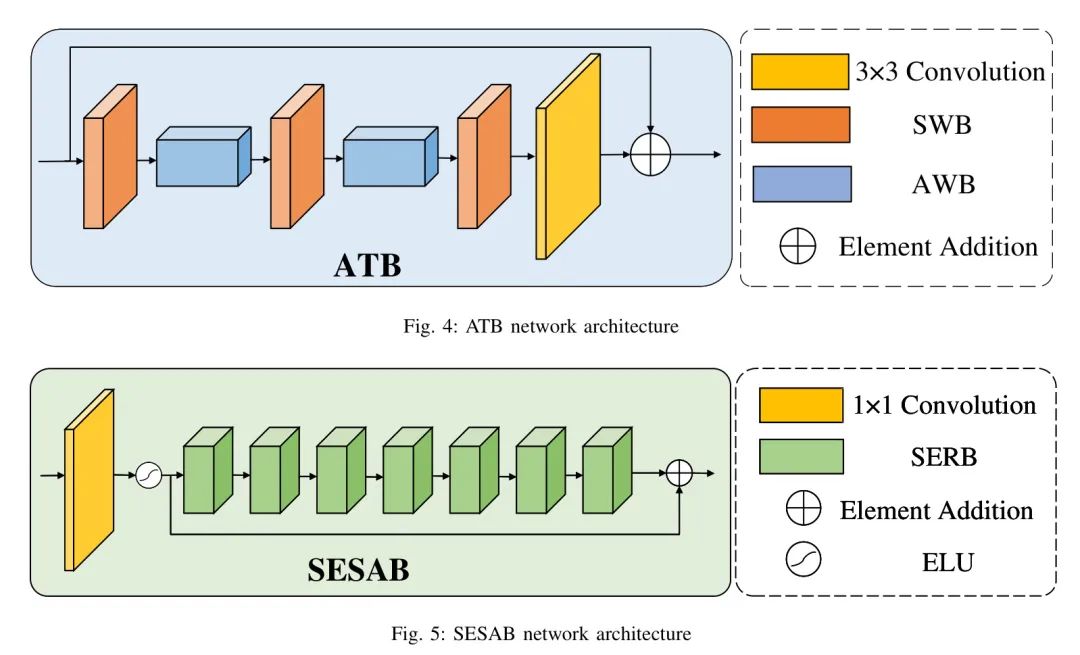
然后是空间增强自注意力模块(SESAB:空间增强自注意力模块),其主要结构如图5所示。DFFB中这个模块的主要作用是提取图像的全局粗糙信息。这个模块有助于模型在训练过程中通过深度可分卷积层的堆叠和通道注意力与空间增强注意力的结合,自适应地提取图像的关键信息,同时抑制图像的非关键信息。这种结合有助于模型有效地提取全局粗糙信息,从而弥补。
最后是双通道融合模块(DFB:双通道融合模块),其主要结构如图6所示。从图3中作者可以知道,前一个模块的特征图进入DFB后,依次经过ATB和SESAB处理,最后所有从两个分支提取的局部区域和全局特征被放入DFB进行融合,两个分支的信息完全破坏和混合,并最终输入到下一阶段进行处理。其公式可以表示为:
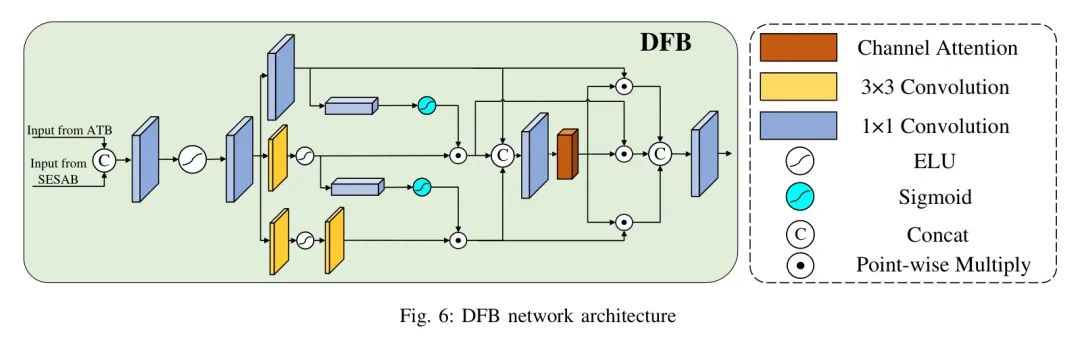
公式6表明,第i个阶段的特征是在前DFB模块处理的特征的输出上,经ATB,SESAB模块处理并融合后的结果。
Iii-B1 Axis Transformer Block
刘等人提出的Swin Transformer模型在计算机视觉领域取得了巨大的成功,该模型通过将图像分块(patch)并设置部分重叠,然后使用多层方形窗口计算块间的自注意力,从而实现图像中更远像素点的长程依赖关系。然而,该模型需要更多的网络层来分割图像以实现方形窗口在图上的移动效果,因此需要更多的计算以发挥其全局建模能力。一些previos研究工作尝试减少Swin Transformer的特征提取层数,然而实验结果显示,一旦Swin Transformer的层数减少,模型的全局特征提取能力将会大大降低,并且会更有偏见地提取图像的区域和局部特征。
为了解决上述问题,本文使用了新的自注意力计算机制,如图7所示。这种自注意力计算机制改变了自注意力窗口的形状,并使用轴式自注意力窗口(图中的红色部分)计算自注意力。使用轴式窗口的优势在于,窗口可以跨多个方形窗口,增加已建立间接依赖像素的数量,同时减少计算直接依赖像素的像素数量,从而让模型可以在更少的网络层下快速建立像素点的全局依赖关系。
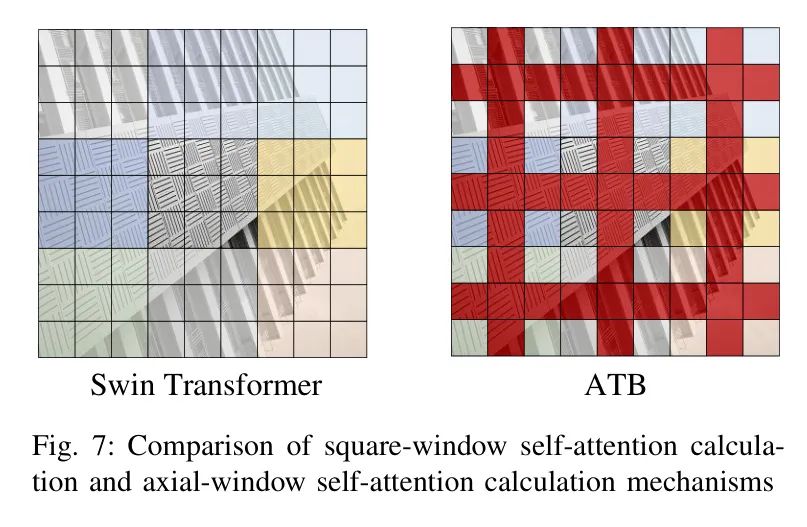
基于图7中的轴式自注意力计算机制,此算法使用轴向Transformer计算模块提取图像的区域和局部特征,如图4所示。其中,AWB(轴窗块)模块是轴式自注意力计算模块,其内部结构参见图8。SWB(方形窗口块)模块是方形窗口自注意力计算模块,其机制与Swin Transformer相同,其内部结构参见图9。Both the AWB模块和SWB模块都是自注意力计算模块,
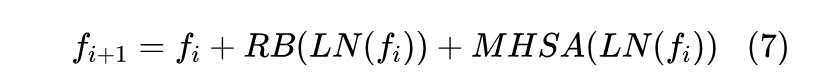
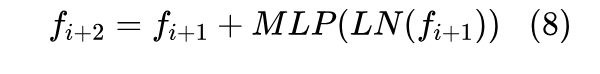
最终得到作为输出特征。
对于进入SWB的特征:
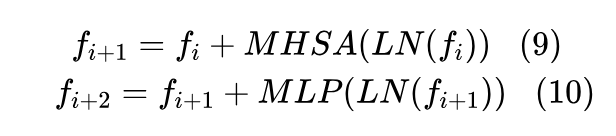
最后,获得 作为输出特征。该方法通过设计轴式注意力窗口和方形窗口的交叉计算,替换了Swin Transformer中的移动窗口机制,从而大大降低了Transformer分支的计算量,有效地建立了像素点之间的长程间接依赖关系。
Iii-A2 Space Enhanced Self-Attention Block
在卷积分支的设计中,该模型是指使用设计的残差卷积块(SERB:空间增强残差块)堆叠以实现图像特征提取的卷积神经网络。同时,为了减轻由于残差卷积块堆叠而导致的模型参数数量增加,部分采用深度可分卷积进行大量轻量级处理,创新地将空间增强注意力模块(ESA:增强自注意力) [15] 和通道注意力模块(CA:通道注意力) [16] 结合在每一个残差卷积块的末端,用于提取通过卷积神经网络进行图像特征的残差卷积块的功能,提高残差卷积块提取图像特征的能力,使得残差卷积块具有提取图像的全局粗粒度特征的能力,便于后续对由ATB模块处理的特征图进行补充。
SERB的主要结构如图10所示:
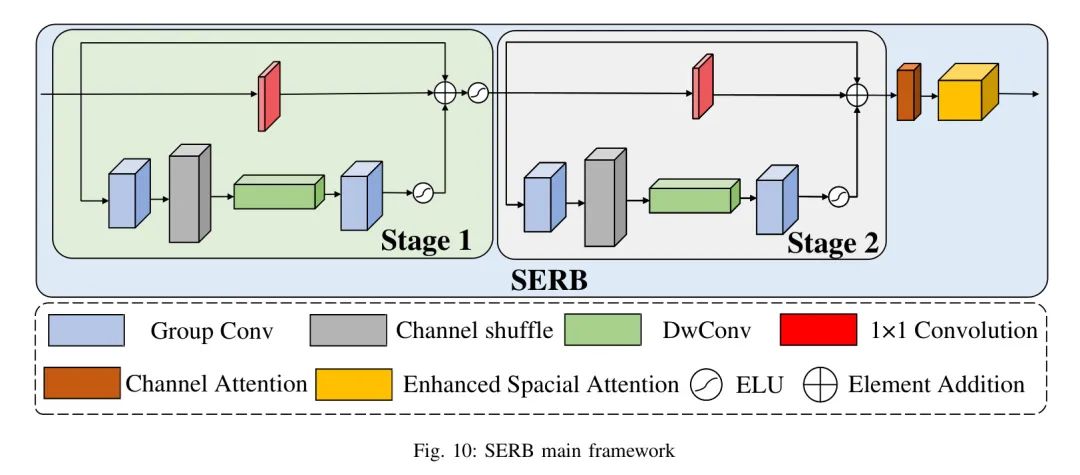
假设输入特征为 :
其中 表示 SERB 阶段1中,从顶部向下计算的第3个分支的特征图。
对于阶段2,本文使用 来表示 SERB 阶段2中,从顶部向下计算的第3个分支的特征图,因此有:
因此 SERB 的输出特征为 。
在构建上述SERB过程中,模型使用空间增强注意力和通道注意力模块。通道注意力模块的主要作用是在训练过程中为每个通道的特征图分配单独的适应性特征权重,以便通过在训练过程中适当地调整特征权重来实现减弱无效特征和加强重要特征的效果,从而提高模型的图像恢复效率和质量。经过通道注意力模块处理后,空间增强注意力模块可以进一步提取图像的全局粗粒度特征,从而提高模型的像素恢复效果。
Feature Reuse Block
在网络深度增加时,实验发现,随着在深度网络中训练的进行,特征图像的一些帮助图像恢复的信息可能会丢失。一些先前的研究也表明,浅层特征图像和深层特征图像具有相同的信息,有助于图像恢复的重建。
鉴于由于特征图像浅层信息损失导致预恢复图像质量下降的现象,本模型在图像重建阶段之前特意设计了一个新的特征重用模块。这一技术采用了与DFB相同的机制,使用四个分支的分步特征融合来完全将浅层特征与更深层特征融合,充分利用浅层特征图中有益的信息以及深层特征图中助于图像恢复的信息,实现图像重建的最大效率和最小特征信息损失。FRB模块的内部结构如图11所示。
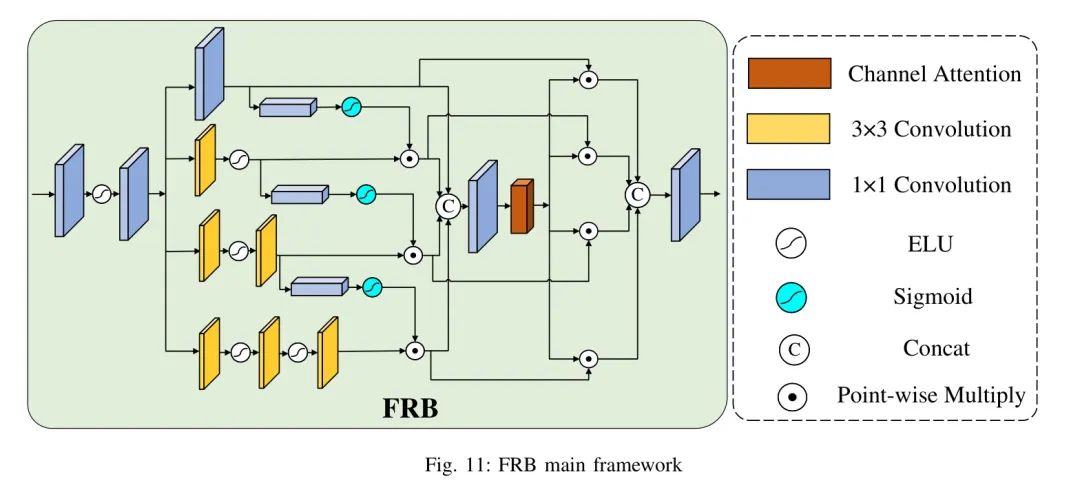
模型在学习过程中增加了第四阶段之前的四个阶段的特征图像的中间特征图像,并将其输入到FRB模块进行深层融合和 Reshape 浅层特征和深层特征,尽量减少训练过程中的信息损失。
IV Experiments Detail
第四实验详细部分的开端。
Dataset
数据集部分的开始。
Iv-A1 Training Dataset
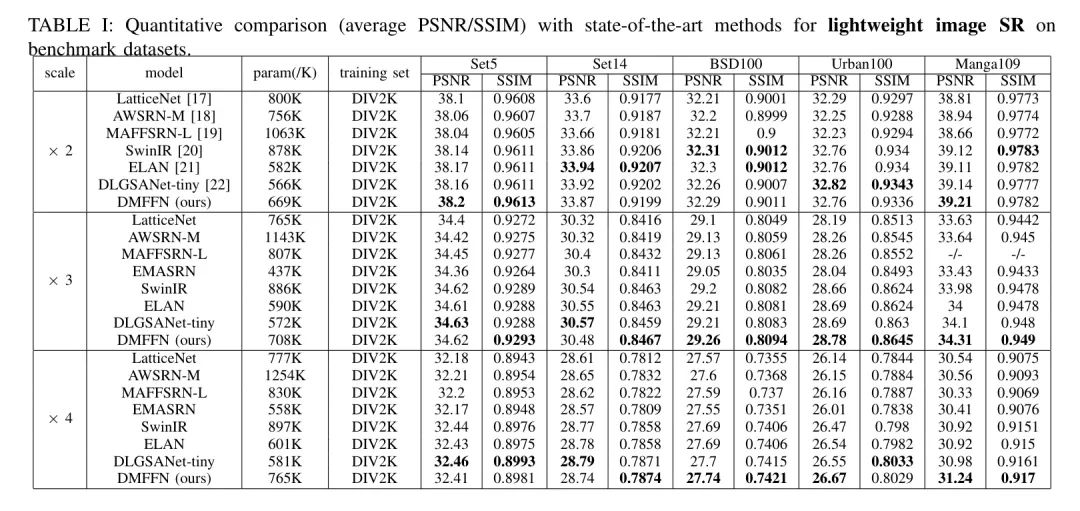
在本篇论文中,作者使用在图像超分辨率领域中广泛使用的DIV2K图像集[23]作为训练集,并用该数据集训练和stage验证设计的模型。该数据集包含800张训练图像(图像编号:1-800)和100张验证图像。在训练过程中,首先使用放大倍数为2的模型进行训练,在放大倍数为2的模型训练完成后,将训练好的模型作为预训练模型移植到后续训练的放大倍数为3和4的模型上。
Iii-A2 Test Dataset
为了确保与其他模型的比较客观,以下实验还使用该领域广泛使用的五种类型的标准验证集进行了验证:Set5 [24],Set14 [25],B100 [26],Urban100 [27],以及 Manga109 [6]。为了与以前的模型进行公平的比较,在每个测试集的 YCbCr 空间中的明度(Y)通道中采用峰值信噪比(PSNR:峰值信噪比)和结构相似度指数(SSIM:结构相似度指数)作为指标,分别计算每个测试集的 PSNR 和 SSIM 值,并单独进行比较。
Experimental Setup
在模型训练期间,每次批量会在48个图像块中随机选择48个。Adam是优化器。在本论文中,作者使用Pytorch框架,2块Nvidia 2080Ti GPU进行模型训练和测试。
Results on Image SR
图像增强部分的结果
Iv-C1 Quantitative comparison
在目标评估指标对比中,选取实验结果来比较平均PSNR和平均SSIM的放大倍数分别为2倍、3倍和4倍,结果如表1所示。这一比较对比了当前模型与过去三年中的经典模型。从结果可以看出,当前模型的平均PSNR和平均SSIM的测试值超过了一部分经典模型,并保持了更优秀的水平。据此,可以得出结论:当前模型的网络架构达到了SOTA水平(State-Of-The-Art)。
Iv-C2 Visual Comparison
图12中展示了Set14测试集和Urban100测试集中的图像分别作为实验结果的样本。原始的HR图像,模型CARN [13],IMDN [28],AWSRN-S [18],LAPAR-A [29],EDSR [30]和SwinIR [20]被用作对照模型以展示模型对图像恢复的主观效果。通过比较,可以看出该模型在图像细节纹理恢复的有效性方面取得了显著的改进。在Barbara图像中,该模型可以轻松区分对角线向上的纹理细节,并且还可以清晰地分辨出距离较薄的条纹的间距。在img085图像中,尽管该模型所复原的图像与原始HR图像相比仍存在一些距离和模糊,但与其他模型的恢复效果进行比较时,该论文中的模型在远程光斑的恢复上具有更丰富和更真实的细节,没有出现缺少细节的问题,而其他图像的细节缺失程度各不相同。

Ablation Study and Discussion
在本文中,作者首先移除了ATB分支,并使用与残差卷积分支相同结构来替换ATB分支,并利用残差卷积组合的两途径同时进行低分辨率图像特征提取以及图像恢复,图像恢复结果如表2第二行所示。
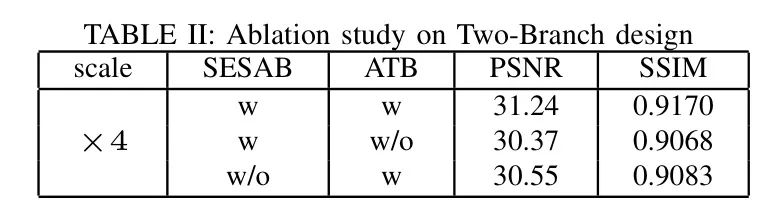
后来,实验移除了SESAB分支,并使用与ATB分支相同结构来替换残差卷积分支,并利用与ATB分支结合的两途径进行后续图像恢复,图像恢复结果如表2第三行所示。实验结果表明,混合双向网络模型在所有Transformer分支的两向网络和所有卷积神经网络分支的两向网络上的表现都优于其他模型。
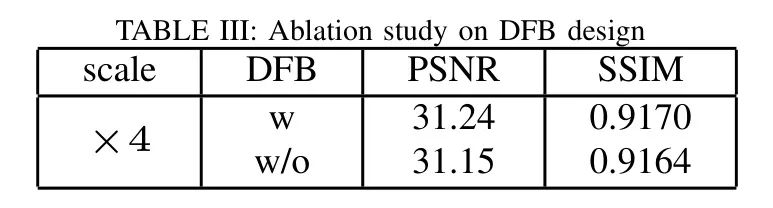
实验三(表4)考察了DFB模块的存在与否对图像恢复结果的影响。在实验中,去掉了DFB模块,改用与通道方向的SPLICE结合的卷积核进行通道方向上的卷积,压缩从4C到C的特征图像,然后进行后续图像的恢复。可以发现,具有DFB模块的网络能够更好地结合两个分支的特征信息。
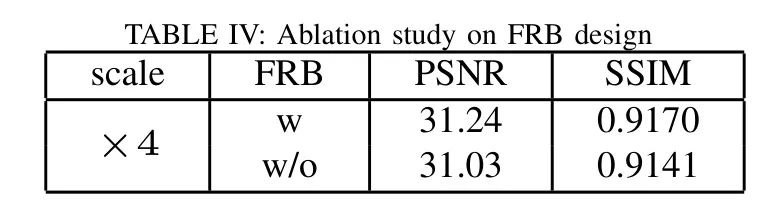
可以看到,带有FRB模块的网络在结合浅层特征和深层特征信息方面更为擅长,从而实现更佳的图像恢复。
V Conclusion
在论文中,作者提出了一种轻量级渐进多尺度特征融合网络,该网络基于双分支卷积神经网络和Transformer。
本文的主要工作是设计一个双向渐进特征多尺度融合块,该块将空间增强注意力模块与传统的单分支卷积网络相结合,并将Transformer分支提取的局部图像特征与卷积分支提取的粗糙全局特征进行融合,以实现最终的利用率和对模型表达能力的优化。
实验结果表明,本文方法有效,无论是从算法设计原则还是具体目标实验看,都证明了模型显著优于现有方法。
参考
[1].Lightweight Multiscale Feature Fusion.
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。