最近这一两周不少大厂都已经开始秋招面试了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
- 《大模型面试宝典》(2024版) 正式发布
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,文末加入我们星球
最近出现了在构建聊天机器人方面的应用浪潮,这主要得益于LlamaIndex 和 LangChain 这样的框架。许多这类应用都采用了用于检索增强生成(RAG)的标准技术栈,其中包括以下关键步骤:
-
向量存储库: 使用向量存储库来存储非结构化文档,即知识语料库。
-
检索模型: 针对查询使用检索模型,通过嵌入相似性检索语料库中的相关文档。
-
回答模型: 使用合成模型生成响应,结合检索和生成的优势,提高聊天机器人的效果。
RAG关键优势在于在生成响应时结合了检索和生成的优势,从而提高了聊天机器人的性能。 但此种流程也存在的不足之处,如不够精确、可能返回不相关的上下文等问题。
改进方向:重排序改进
什么是重排序?
重排序是信息检索系统中的一个重要步骤,它发挥着优化检索结果的关键作用。在初始检索阶段,系统根据某种标准(如相似度)返回一组文档。然而,由于初始排序可能并不总是能够准确反映文档与查询的真实相关性,因此需要进行重排序来提升检索结果的质量。

不同的重排序方法
-
使用检索模型进行二次检索:一种常见的重排序方法是使用检索模型进行二次检索。在初始检索后,通过利用更复杂的模型,例如基于嵌入的检索模型,可以再次检索相关文档。这有助于更精确地捕捉文档与查询之间的语义关系。
-
使用交叉模型进行打分:另一种方法是利用交叉模型进行文档打分。这种模型可以考虑文档和查询之间的交互特征,从而更细致地评估它们之间的关联度。通过结合不同特征的交互,可以得到更准确的文档排序。
-
利用大模型进行重排序:大型语言模型(LLM)等大模型的崛起为重排序提供了新的可能性。这些模型通过对整个文档和查询进行深层次的理解,能够更全面地捕捉语义信息。
方法1:交叉模型进行重排序
与嵌入模型不同,重新排序器使用问题和文档作为输入,直接输出相似度而不是嵌入。通过将查询和段落输入到重新排序器中,你可以获得相关性分数。重新排序器是基于交叉熵损失进行优化的,因此相关性分数不受限于特定范围。
BGE Reranker
https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
这个重新排序器是从xlm-roberta-base初始化的,并在混合的多语言数据集上进行训练:
-
中文:来自T2ranking、MMmarco、dulreader、Cmedqa-v2和nli-zh的788,491个文本对。
-
英文:来自msmarco、nq、hotpotqa和NLI的933,090个文本对。
-
其他语言:来自Mr.TyDi的97,458个文本对(包括阿拉伯语、孟加拉语、英语、芬兰语、印度尼西亚语、日语、韩语、俄语、斯瓦希里语、泰卢固语、泰语)。
CohereRerank
# pip install cohere
import cohere
api= ""
co = cohere.Client(api)
query = "What is the capital of the United States?"
docs = [
"Carson City is the capital city of the American state of Nevada. At the 2010 United States Census, Carson City had a population of 55,274.",
"The Commonwealth of the Northern Mariana Islands is a group of islands in the Pacific Ocean that are a political division controlled by the United States. Its capital is Saipan.",
"Charlotte Amalie is the capital and largest city of the United States Virgin Islands. It has about 20,000 people. The city is on the island of Saint Thomas.",
"Washington, D.C. (also known as simply Washington or D.C., and officially as the District of Columbia) is the capital of the United States. It is a federal district. The President of the USA and many major national government offices are in the territory. This makes it the political center of the United States of America.",
"Capital punishment (the death penalty) has existed in the United States since before the United States was a country. As of 2017, capital punishment is legal in 30 of the 50 states. The federal government (including the United States military) also uses capital punishment."]
results = co.rerank(query=query, documents=docs, top_n=3, model='rerank-english-v2.0') # Change top_n to change the number of results returned. If top_n is not passed, all results will be returned.
实验结果
从数据中清晰可见重新排序器在优化搜索结果方面的重要性。几乎所有嵌入都受益于重新排序,表现出改善的命中率和MRR。

-
bge-reranker-large:对于多个嵌入,该重新排序器经常提供了最高或接近最高的MRR,有时其性能与CohereRerank相媲美甚至超过。
-
CohereRerank:在所有嵌入上一致提升性能,往往提供最佳或接近最佳的结果。
方法2:大模型进行重排序
现有的涉及LLM的重排方法大致可以分为三类:用重排任务微调LLM,使用prompt让LLM进行重排,以及利用LLM做训练数据的增强。
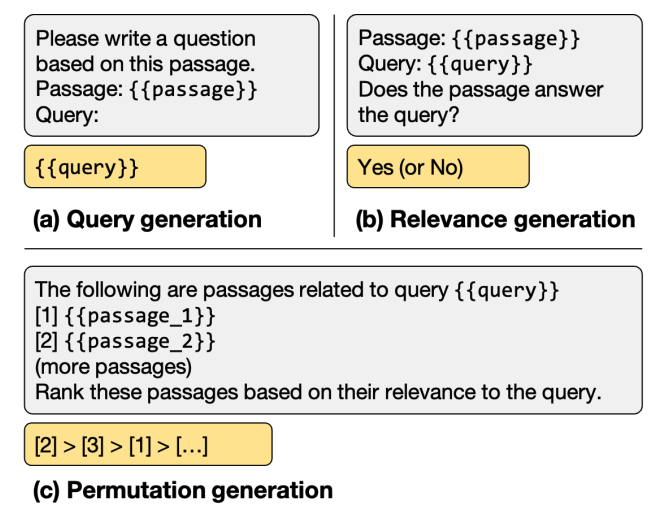
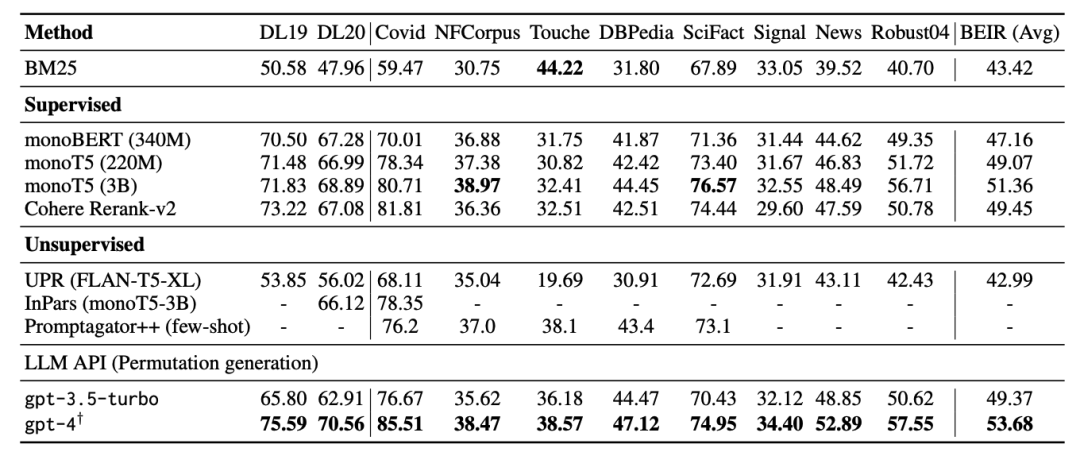
如下表所示,所有模型都重新排名相同的BM25前100个段落。使用gpt-4重新排名由gpt-3.5-turbo重新排名的前30个段落。
参考文献
-
https://arxiv.org/pdf/2304.09542.pdf
-
https://arxiv.org/pdf/2308.07107v2.pdf
-
https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83
-
https://blog.llamaindex.ai/using-llms-for-retrieval-and-reranking-23cf2d3a14b6
技术交流

通俗易懂讲解大模型系列
-
重磅消息!《大模型面试宝典》(2024版) 正式发布!
-
重磅消息!《大模型实战宝典》(2024版) 正式发布!
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法