Time-MoE : 时间序列领域的亿级规模混合专家基础模型

时间序列预测一直是量化研究和工业应用中的重要课题。随着深度学习技术的发展,大规模预训练模型在自然语言处理和计算机视觉领域取得了显著进展,但在时间序列预测领域,这些模型的规模和运算成本仍然限制了其在实际应用中的效能。为此,本文介绍了TIME-MOE,这是一种可扩展的统一架构,旨在通过减少推理成本来预训练更大、更强的时间序列预测基础模型。TIME-MOE利用稀疏混合专家(MoE)设计,通过为每个预测激活网络的子集来提高计算效率,从而在不增加推理成本的情况下实现模型规模的有效扩展。TIME-MOE由一系列仅解码器的Transformer模型组成,以自回归方式运行,支持灵活的预测范围和变化的输入上下文长度。研究者们首次将时间序列基础模型扩展到24亿参数,并在新引入的大规模数据集Time-300B上进行了预训练,该数据集涵盖了9个领域,包含超过3000亿个时间点。实验结果表明,TIME-MOE在预测精度上取得了显著提升,并在多个真实世界的基准测试中优于同等计算预算的密集模型。
1. 引言
时间序列数据是现实世界动态系统中的主要模态,在诸如能源、气候、教育、量化金融和城市计算等各个领域的应用中至关重要。尽管传统的预测方法在特定任务中表现出了竞争力,但直到最近,随着一些通用预测基础模型的出现,该领域才开始走向统一。尽管这些模型前景广阔,但与特定领域的模型相比,它们的规模通常较小,任务解决能力有限,这限制了它们在实际应用中的预测精度与计算预算之间的平衡。
2. 相关工作
在过去的十年中,深度学习模型已经成为时间序列预测的强大工具。这些模型可以分为单变量模型和多变量模型,其中多变量模型包括基于Transformer的方法和非Transformer模型。尽管这些模型在各自的领域内取得了有竞争力的性能,但它们通常是任务特定的,并且在跨领域数据的少样本或零样本场景中泛化能力不足。
3. 方法论
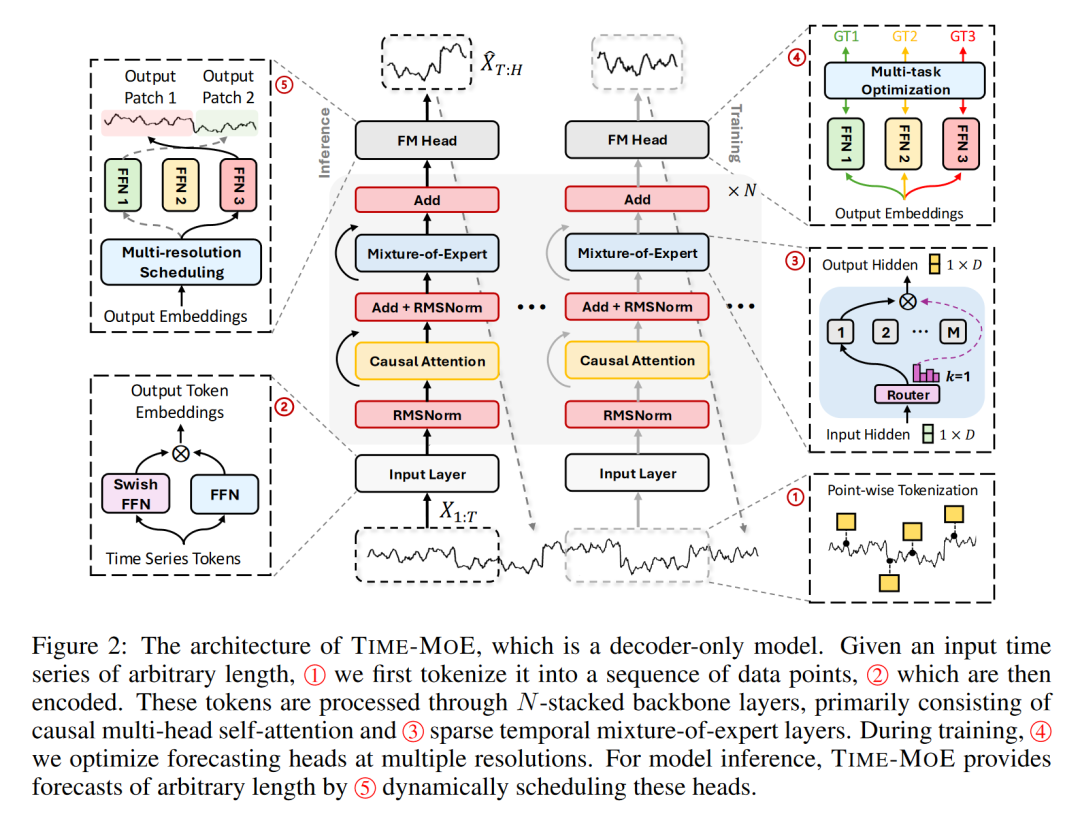
TIME-MOE模型的核心在于其创新的架构设计,该设计基于混合专家(Mixture-of-Experts, MoE)的解码器-only Transformer架构,旨在实现大规模预训练的同时降低推理成本。本章详细介绍了TIME-MOE的三个关键组成部分:输入令牌嵌入、MoE Transformer块和多分辨率预测。
3.1 TIME-MOE概览
TIME-MOE模型的设计理念是为了解决时间序列预测中的两个主要挑战:模型规模的扩展和计算效率的提升。以下是TIME-MOE模型的三个主要组成部分:
3.1.1 输入令牌嵌入
输入令牌嵌入是模型的第一层,它将原始时间序列数据转换为模型可以处理的形式。TIME-MOE采用逐点标记化策略,确保时间信息的完整性。每个时间序列数据点通过SwiGLU函数进行嵌入,得到相应的隐藏状态。
3.1.2 MoE Transformer块
MoE Transformer块是TIME-MOE的核心组件,它基于标准的Transformer解码器,并引入了混合专家层来提高计算效率。这些混合专家层由多个专家网络组成,每个网络只对一部分输入数据进行计算,从而实现模型的稀疏激活。这种设计不仅提升了模型处理大规模数据的能力,还减少了推理时的计算负担。
3.1.3 多分辨率预测
多分辨率预测是TIME-MOE的另一个创新点。它通过多个输出层来支持不同预测范围的预测任务,使得模型能够灵活地处理不同长度的预测问题。这种设计提高了模型在多样化预测任务中的适用性和准确性。
3.2 模型训练
TIME-MOE的训练过程包括了数据集的构建、损失函数的选择和模型配置的确定。
3.2.1 TIME-300B数据集
为了训练TIME-MOE模型,研究者们构建了一个名为Time-300B的大规模时间序列数据集。这个数据集涵盖了9个不同的领域,包含了超过3000亿个时间点。为了确保数据质量,研究者们开发了一个数据清洗流程,以处理缺失值和无效观测等问题。
3.2.2 损失函数
TIME-MOE模型采用了Huber损失函数来提高训练的稳定性。Huber损失函数对异常值具有更好的鲁棒性,有助于模型在面对噪声数据时保持稳定的性能。
3.2.3 模型配置和训练细节
TIME-MOE模型有三种不同的规模:基础版(50M激活参数)、大型版(200M激活参数)和超大型版(2.4B参数)。每种模型都经过了精心设计,以适应不同的计算环境和应用需求。模型训练使用了AdamW优化器,并采用了线性预热和余弦退火的学习率调度策略。

4. 主要结果
研究者们通过一系列详尽的实验,验证了TIME-MOE模型在不同规模和设置下的有效性。本章详细介绍了零样本预测、领域内预测、消融研究、可扩展性分析和训练精度分析等方面的结果。
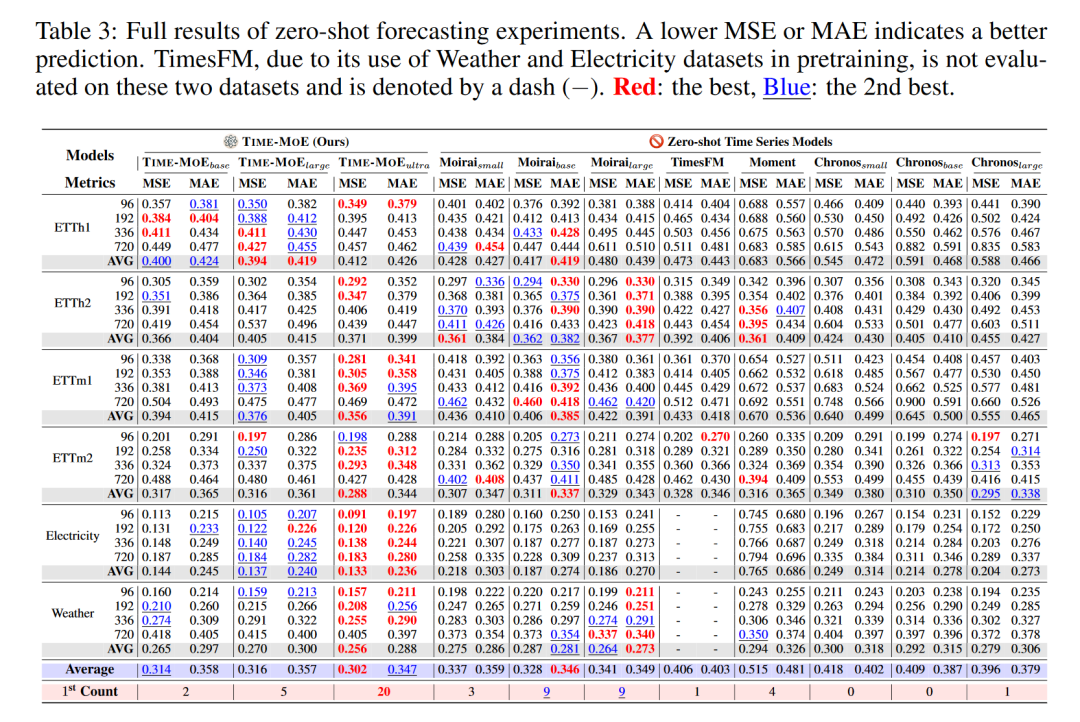
4.1 零样本预测
在零样本预测设置中,TIME-MOE模型接受了未包含在其预训练数据中的六个长期预测基准数据集的测试。这些数据集覆盖了不同的领域,包括温度、电力消耗和天气等。实验结果表明,TIME-MOE在所有测试基准上都实现了显著的性能提升。
4.1.1 实验设置
-
数据集:包括ETTh1、ETTh2、ETTm1、ETTm2、天气和电力消耗等六个数据集。
-
预测范围:选择了96、192、336和720时间步长作为预测范围。
-
评估指标:使用均方误差(MSE)和平均绝对误差(MAE)作为评估指标。
4.1.2 结果
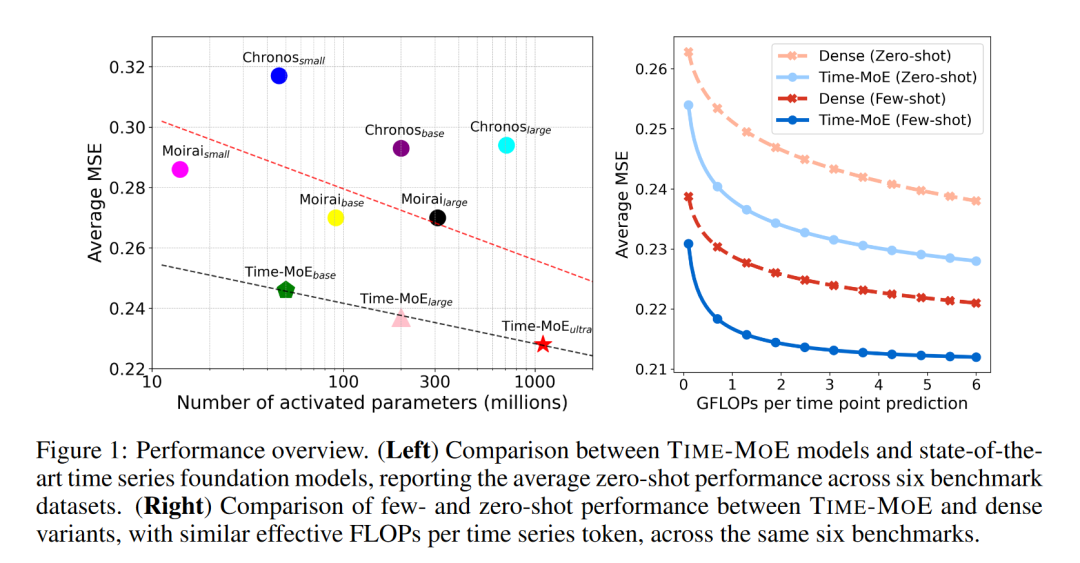
TIME-MOE在所有基准测试中均取得了最低的MSE和MAE值,与现有的最先进模型相比,平均MSE降低了23%以上。这一结果证明了TIME-MOE模型在零样本学习环境下的强大预测能力。
4.2 领域内预测
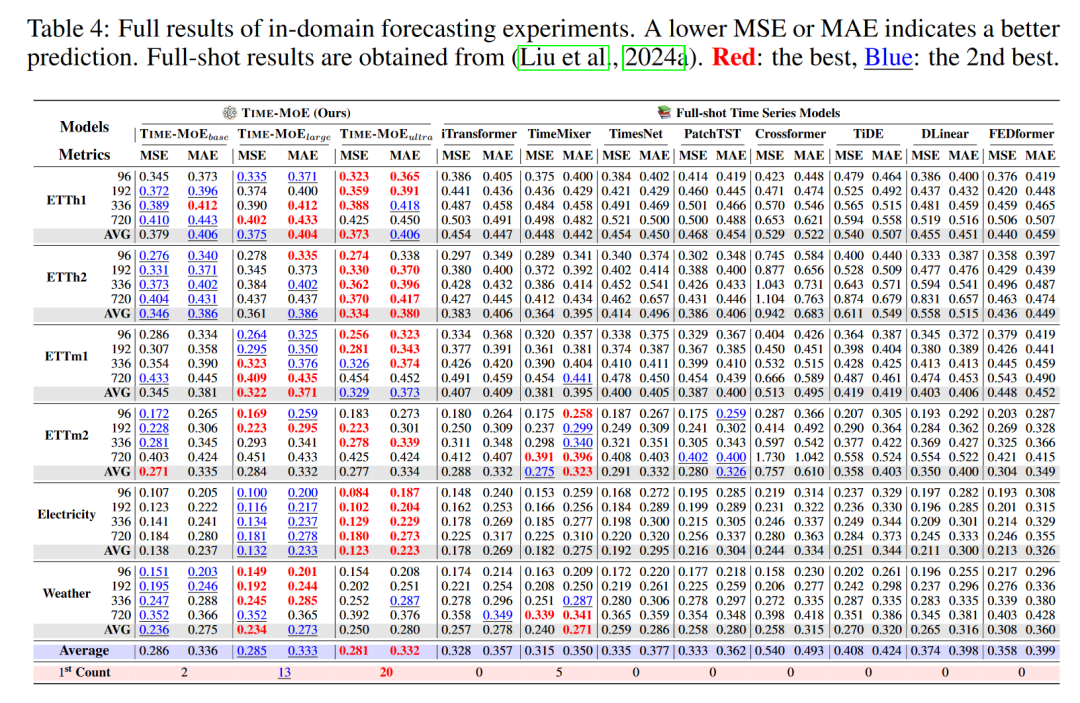
领域内预测(也称为全样本预测)测试了TIME-MOE模型在经过特定领域数据微调后的性能。这种设置模拟了实际应用中常见的情况,即模型在特定任务上进行优化。
4.2.1 实验设置
-
数据集:使用与零样本预测相同的六个基准数据集。
-
训练周期:每个模型仅进行一次训练周期的微调。
4.2.2 结果
TIME-MOE在所有测试基准上均实现了显著的性能提升,平均MSE降低了25%。这一结果展示了TIME-MOE模型在经过少量微调后,能够快速适应特定领域数据的强大能力。
4.3 消融研究
消融研究旨在评估TIME-MOE模型中关键组件的贡献,包括混合专家(MoE)层、多分辨率预测层和Huber损失函数。

4.3.1 实验设置
-
组件移除:分别移除MoE层、多分辨率预测层和Huber损失函数,以评估它们对模型性能的影响。
4.3.2 结果
-
MoE层:移除MoE层后,模型性能显著下降,证明了稀疏激活设计对提高模型性能的重要性。
-
多分辨率预测层:移除多分辨率预测层后,模型在处理不同预测范围时的性能略有下降,表明多分辨率预测层在捕捉不同时间依赖性方面的重要性。
-
Huber损失函数:使用Huber损失函数的模型在处理异常值时表现更稳定,提高了训练的鲁棒性。
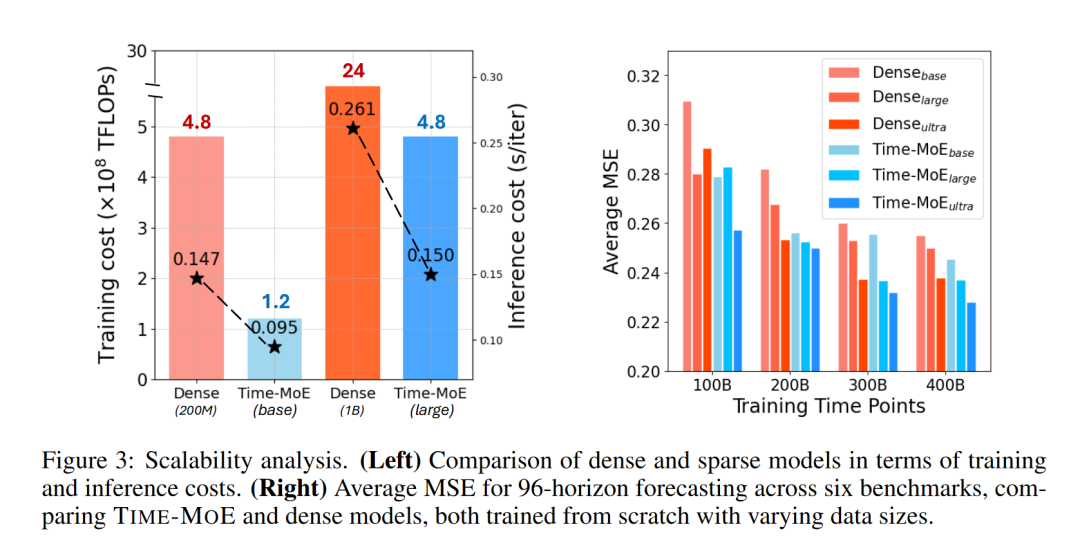
4.4 可扩展性分析
可扩展性分析探讨了TIME-MOE模型在不同数据规模和模型规模下的性能和效率。
4.4.1 实验设置
-
模型规模:比较了不同规模的TIME-MOE模型(基础版、大型版和超大型版)。
-
数据规模:在不同规模的数据集上训练模型,以评估数据规模对模型性能的影响。
4.4.2 结果
-
模型规模:随着模型规模的增加,TIME-MOE模型的性能持续提升,证明了模型规模扩展的有效性。
-
数据规模:在更大数据集上训练的模型表现出更好的泛化能力,强调了大规模数据在提升模型性能中的作用。
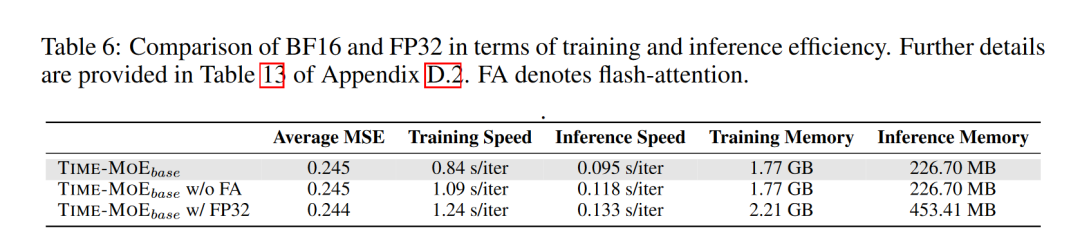
4.5 训练精度分析
训练精度分析比较了使用不同数值精度(bfloat16和float32)进行训练的TIME-MOE模型的性能和效率。
4.5.1 实验设置
-
精度比较:训练了两个版本的TIME-MOE模型,一个使用bfloat16精度,另一个使用float32精度。
4.5.2 结果
-
性能:两种精度的模型在预测性能上相当,表明使用bfloat16精度不会牺牲模型的预测能力。
-
效率:bfloat16精度的模型在训练速度和内存使用上均优于float32精度的模型,展示了在保持性能的同时提高效率的潜力。
5. 结论
本文介绍的TIME-MOE模型,通过利用专家混合的稀疏设计,提高了计算效率,同时在多个基准测试中实现了显著的预测精度提升。TIME-MOE证明了在时间序列预测中扩展模型规模的可行性,并确立了自己作为解决现实世界预测挑战的最新解决方案的地位。