一、初识
创建项目:
scrapy startproject my_one_project # 创建项目命令
cd my_one_project # 先进去, 后面在里面运行
运行爬虫命令为:scrapy crawl tkspiders下创建test.py
其中name就是scrapy crawl tk ,运行时用的
# spiders脚本
import scrapy
class TkSpider(scrapy.Spider):
name = 'tk' # 运行爬虫命令为:scrapy crawl tk
start_urls = ['https://www.baidu.com/']
def parse(self, response, **kwargs):
print(1111)
print(response.text)运行时:
[scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://www.baidu.com/>
so所以:
settings.py中
访问百度地址就设置这个
ROBOTSTXT_OBEY = False
不想看那么多东西,可以设置这个
LOG_LEVEL = 'ERROR' #分别为 CRITICAL< ERROR < WARNING < INFO < DEBUG (设置为 ERROR ,就不会展示INFO)再次运行

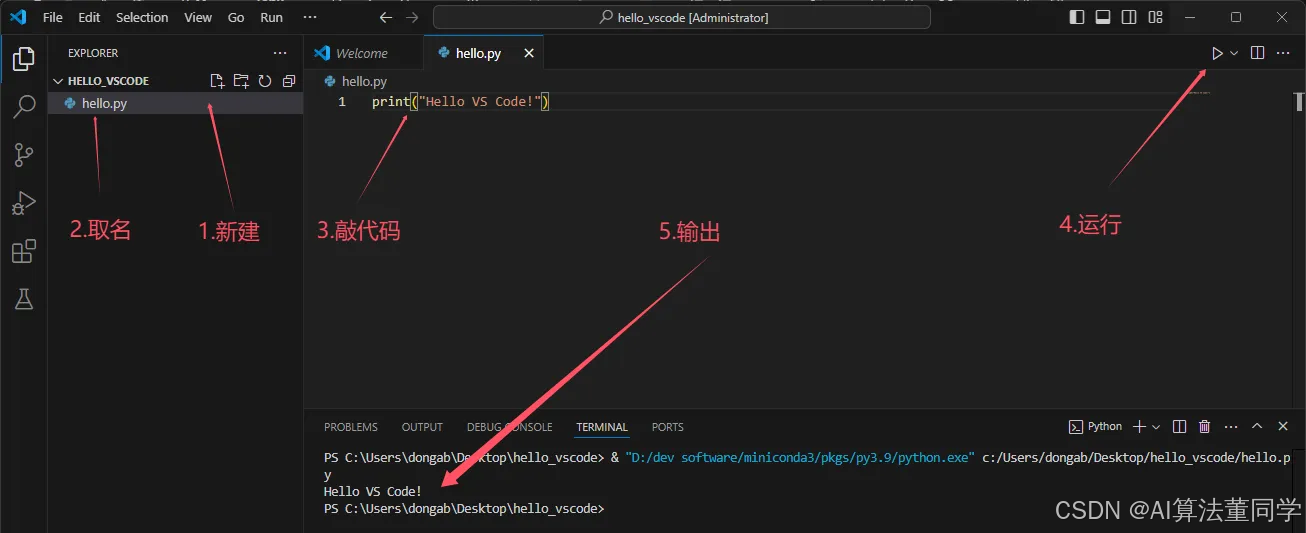
二、内部如何请求的
在执行parse前,实际上是执行了 start_requests的,在这里面实现了请求。如下图1中的内容写了或者不写都是一样的效果。

但是写的话,可以在start_requests方法中,
- 发出请求之前执行一些额外的操作。如放一个cookie值、headers来请求

传递了cookie请求后就能获取响应了 - 请求发出之后,如获取本次请求使用的header




![[产品管理-33]:实验室技术与商业化产品的距离,实验室技术在商业化过程中要越过多少道“坎”?](https://i-blog.csdnimg.cn/direct/3a923d40401249ca97e10cb75ae35c78.png)