想看Java基础扫盲(一)的可以观看我的上篇文章Java基础扫盲
目录
String为什么设计为不可变的
String有长度限制吗
为什么JDK9将String的char[]改为byte[]
泛型中K,T,V,E,Object,?等都代表什么含义
怎么修改一个类中使用了private修饰的String类型的变量
1. 使用 Setter 方法
2. 使用反射
String为什么设计为不可变的
关于String为什么设计为不可变的,可以从缓存、安全性、线程安全和性能等角度出发的。
缓存:
字符串是使用最广泛的数据结构。大量的字符串的创建是非常耗费资源的,所以,Java提供了对字符串的缓存功能,可以大大的节省堆空间。
JVM中专门开辟了一部分空间来存储Java字符串,那就是字符串池。
通过字符串池,两个内容相同的字符串变量,可以从池中指向同一个字符串对象,从而节省了关键的内存资源
String s = "abcd";
String s2 = s;对于这个例子,s和s2都表示"abcd",所以他们会指向字符串池中的同一个字符串对象:
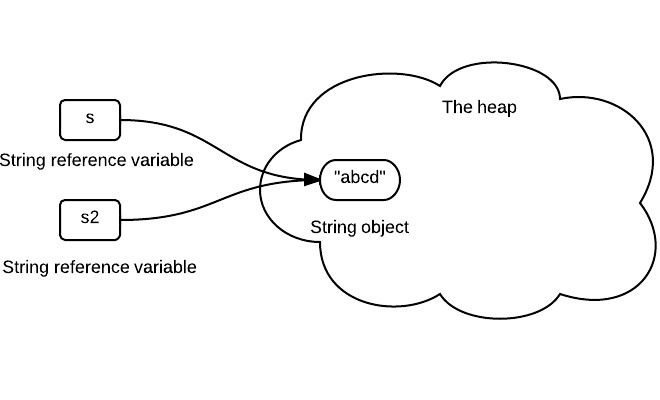
但是,之所以可以这么做,主要是因为字符串的不变性,如果字符串是可变的,我们一旦修改了s的内容,那必然导致s2的内容也被动的改变了。
hashcode缓存
由于字符串对象被广泛地用作数据结构,它们也被广泛地用于哈希实现,如HashMap、HashTable、HashSet等。在对这些散列实现进行操作时,经常调用hashCode()方法。
不可变性保证了字符串的值不会改变。因此,hashCode()方法在String类中被重写,以方便缓存,这样在第一次hashCode()调用期间计算和缓存散列,并从那时起返回相同的值。
安全性:
字符串在Java应用程序中广泛用于存储敏感信息,如用户名、密码、连接url、网络连接等。JVM类加载器在加载类的时也广泛地使用它。
因此,保护String类对于提升整个应用程序的安全性至关重要。
当我们在程序中传递一个字符串的时候,如果这个字符串的内容是不可变的,那么我们就可以相信这个字符串中的内容。
但是,如果是可变的,那么这个字符串内容就可能随时都被修改。那么这个字符串内容就完全不可信了。这样整个系统就没有安全性可言了。
线程安全性:
不可变会自动使字符串成为线程安全的,因为当从多个线程访问它们时,它们不会被更改。
因此,一般来说,不可变对象可以在同时运行的多个线程之间共享。它们也是线程安全的,因为如果线程更改了值,那么将在字符串池中创建一个新的字符串,而不是修改相同的值。因此,字符串对于多线程来说是安全的。
性能:
字符串池、hashcode缓存等,都是提升性能的体现。
因为字符串不可变,所以可以用字符串池缓存,可以大大节省堆内存。而且还可以提前对hashcode进行缓存,更加高效
由于字符串是应用最广泛的数据结构,提高字符串的性能对提高整个应用程序的总体性能有相当大的影响。
String有长度限制吗
String时有长度限制的,编译期和运行期不一样。
编译期需要用CONSTANT_Utf8_info 结构用于表示字符串常量的值,而这个结构是有长度限制,他的限制是65535。
运行期,String的length参数是Int类型的,那么也就是说,String定义的时候,最大支持的长度就是int的最大范围值。根据Integer类的定义,java.lang.Integer#MAX_VALUE的最大值是2^31 - 1;
常量池限制:
javac是将Java文件编译成class文件的一个命令,那么在Class文件生成过程中,就需要遵守一定的格式。
根据《Java虚拟机规范》中常量池的定义,CONSTANT_String_info 用于表示 java.lang.String 类型的常量对象,格式如下:
CONSTANT_String_info {
u1 tag;
u2 string_index;
}其中,string_index 项的值必须是对常量池的有效索引, 常量池在该索引处的项必须是 CONSTANT_Utf8_info 结构,表示一组 Unicode 码点序列,这组 Unicode 码点序列最终会被初始化为一个 String 对象。CONSTANT_Utf8_info 结构用于表示字符串常量的值:
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}其中,length则指明了 bytes[]数组的长度,其类型为u2,u2表示两个字节的无符号数,那么1个字节有8位,2个字节就有16位。16位无符号数可表示的最大值位2^16 - 1 = 65535。也就是说Class文件中常量池的格式规定了,其字符串常量的长度不能超过65535。
private void checkStringConstant(DiagnosticPosition var1, Object var2) {
if (this.nerrs == 0 && var2 != null && var2 instanceof String && ((String)var2).length() >= 65535) {
this.log.error(var1, "limit.string", new Object[0]);
++this.nerrs;
}
}代码中可以看出,当参数类型为String,并且长度大于等于65535的时候,就会导致编译失败。
运行期限制:
上面提到的这种String长度的限制是编译期的限制,也就是使用String s= “”;这种字面值方式定义的时候才会有的限制。String类中有很多重载的构造函数,其中有几个是支持用户传入length来执行长度的:
public String(byte bytes[], int offset, int length)这里面的参数length是使用int类型定义的,那么也就是说,String定义的时候,最大支持的长度就是int的最大范围值。根据Integer类的定义,java.lang.Integer#MAX_VALUE的最大值是2^31 - 1;这个值约等于4G,在运行期,如果String的长度超过这个范围,就可能会抛出异常。(在jdk 1.9之前)。int 是一个 32 位变量类型,取正数部分来算的话,他们最长可以有
2^31-1 =2147483647 个 16-bit Unicodecharacter
2147483647 * 16 = 34359738352 位
34359738352 / 8 = 4294967294 (Byte)
4294967294 / 1024 = 4194303.998046875 (KB)
4194303.998046875 / 1024 = 4095.9999980926513671875 (MB)
4095.9999980926513671875 / 1024 = 3.99999999813735485076904296875 (GB)大约有4GB左右。
为什么JDK9将String的char[]改为byte[]
在Java 9之前,字符串内部是由字符数组char[] 来表示的。
/** The value is used for character storage. */
private final char value[];由于Java内部使用UTF-16,每个char占据两个字节,即使某些字符可以用一个字节(LATIN-1)表示,但是也仍然会占用两个字节。所以,JDK 9就对他做了优化。
Latin1(又称ISO 8859-1)是一种字符编码格式,用于表示西欧语言,包括英语、法语、德语、西班牙语、葡萄牙语、意大利语等。它由国际标准化组织(ISO)定义,并涵盖了包括ASCII在内的128个字符。 Latin1编码使用单字节编码方案,也就是说每个字符只占用一个字节,其中第一位固定为0,后面的七位可以表示128个字符。这样,Latin1编码可以很方便地与ASCII兼容。
这就是Java 9引入了"Compact String"的概念:每当我们创建一个字符串时,如果它的所有字符都可以用单个字节(Latin-1)表示,那么将会在内部使用字节数组来保存一半所需的空间,但是如果有一个字符需要超过8位来表示,Java将继续使用UTF-16与字符数组。
泛型中K,T,V,E,Object,?等都代表什么含义
E – Element (在集合中使用,因为集合中存放的是元素)
T – Type(Java 类)
K – Key(键)
V – Value(值)
N – Number(数值类型)
? – 表示不确定的java类型(无限制通配符类型)
S、U、V – 这几个有时候也有,这些字母本身没有特定的含义,它们只是代表某种未指定的类型。一般认为和T差不多。
Object – 是所有类的根类,任何类的对象都可以设置给该Object引用变量,使用的时候可能需要类型强制转换,但是用使用了泛型T、E等这些标识符后,在实际用之前类型就已经确定了,不需要再进行类型强制转换。
示例1:使用T作为泛型类型参数,表示任何类型
// 示例1:使用T作为泛型类型参数,表示任何类型
public class MyGenericClass<T> {
private T myField;
public MyGenericClass(T myField) {
this.myField = myField;
}
public T getMyField() {
return myField;
}
}示例2:使用K、V作为泛型类型参数,表示键值对中的键和值的类型
// 示例2:使用K、V作为泛型类型参数,表示键值对中的键和值的类型
public class MyMap<K, V> {
private List<Entry<K, V>> entries;
public MyMap() {
entries = new ArrayList<>();
}
public void put(K key, V value) {
Entry<K, V> entry = new Entry<>(key, value);
entries.add(entry);
}
public V get(K key) {
for (Entry<K, V> entry : entries) {
if (entry.getKey().equals(key)) {
return entry.getValue();
}
}
return null;
}
private class Entry<K, V> {
private K key;
private V value;
public Entry(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
}
}示例3:使用E作为泛型类型参数,表示集合中的元素类型
// 示例3:使用E作为泛型类型参数,表示集合中的元素类型
public class MyList<E> {
private List<E> elements;
public MyList() {
elements = new ArrayList<>();
}
public void add(E element) {
elements.add(element);
}
public E get(int index) {
return elements.get(index);
}
}示例4:使用Object作为泛型类型参数,表示可以接受任何类型
// 示例4:使用Object作为泛型类型参数,表示可以接受任何类型
public class MyGenericClass {
private Object myField;
public MyGenericClass(Object myField) {
this.myField = myField;
}
public Object getMyField() {
return myField;
}
}怎么修改一个类中使用了private修饰的String类型的变量
在Java中,String 类型确实是不可变的。这意味着一旦一个 String 对象被创建,其内容就不能被改变。任何看似修改了 String 值的操作实际上都是创建了一个新的 String 对象。
当然,如果不考虑这个可不可变的问题,新建一个也算改了的话。那么就有以下几种方式:
1、在Java中,private 访问修饰符限制了只有类本身可以访问和修改其成员变量。如果需要在类的外部修改一个 private 修饰的 String 参数,通常有几种方法:
1. 使用 Setter 方法
这是最常用且最符合对象导向设计原则的方法。在类内部提供一个公开的 setter 方法来修改 private 变量的值。
public class MyClass {
private String myString;
public void setMyString(String value) {
this.myString = value;
}
}
// 使用
MyClass obj = new MyClass();
obj.setMyString("new value");2. 使用反射
如果没有 setter 方法可用,可以使用反射。这种方法可以突破正常的访问控制规则,但应谨慎使用,因为它破坏了封装性,增加了代码的复杂性和出错的可能性。并且性能并不好。
import java.lang.reflect.Field;
public class MyClass {
private String myString = "initial value";
}
// 使用反射修改
MyClass obj = new MyClass();
try {
Field field = MyClass.class.getDeclaredField("myString");
field.setAccessible(true); // 使得private字段可访问
field.set(obj, "new value");
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}