要点速读
2024 年 9 月 12 日,OpenAI 发布了其最新的人工智能模型——o1(Learning to Reason with LLMs[1]),这是一款经过强化学习训练的大型语言模型,能够执行复杂的推理任务。相比于此前的 GPT-4o(GPT-4o:OpenAI 发布最强人机交互模型,OpenAI 生态布局:GPT-4o 免费或许只是一个开始...,ChatGPT 全新升级:GPT-4o Mini 取代 GPT-3.5,免费、快速、更强大!),o1 展示出了卓越的推理能力,特别是在数学、编程和科学领域的基准测试中表现出色。OpenAI 还推出了该模型的预览版(o1-preview,Introducing OpenAI o1-preview[2]),并已在 ChatGPT 中投入使用,未来也将向部分 API 用户开放。
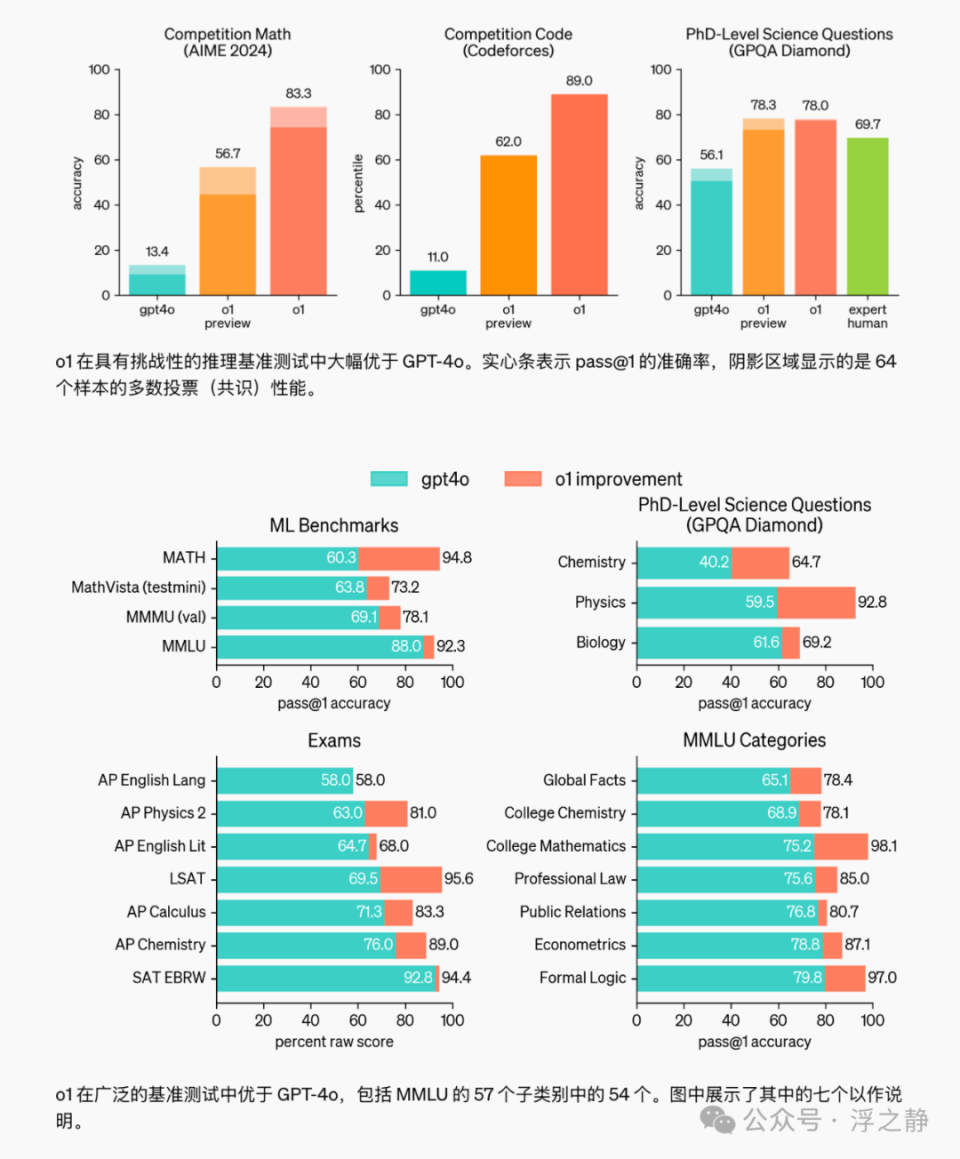
📌ChatGPT Plus 和团队用户可以通过模型选择器手动使用 o1-preview 和 o1-mini,初期的消息限制为每周 30 条(o1-preview)和 50 条(o1-mini)。ChatGPT 企业版和教育版用户将在下周获得访问权限。API 用户也可以开始使用这些模型进行原型开发,初期速率限制为每分钟 20 次请求,会在模型测试后逐步提升。未来 OpenAI 还将逐步开放更多功能,包括文件和图片上传、浏览功能等。
模型
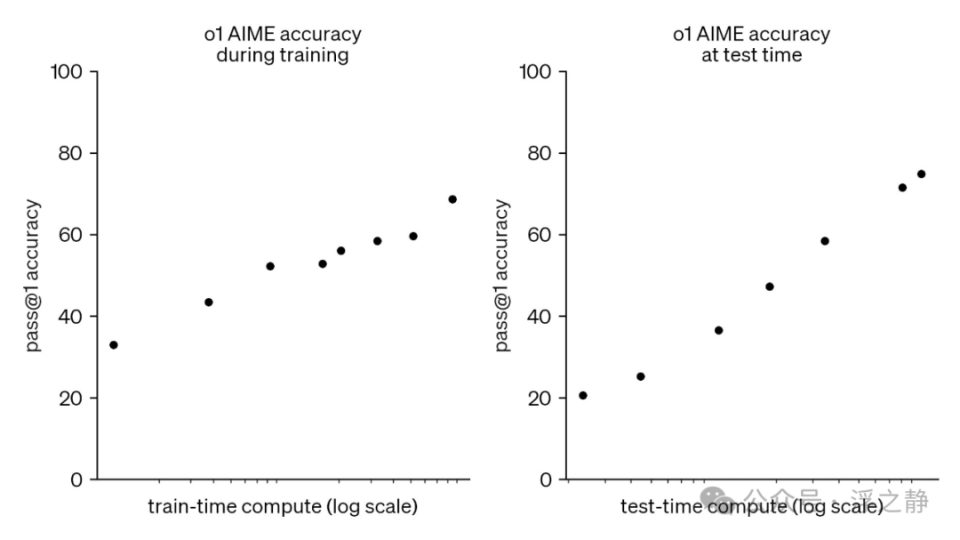
OpenAI 的大规模强化学习算法通过高效利用数据的训练过程,教会模型如何利用思维链进行高效的思考。OpenAI 发现,随着更多的强化学习(train-time compute)和更多的思考时间(test-time compute),o1 的性能会持续提升。扩展这种方法的限制与大型语言模型预训练的限制有很大不同,OpenAI 正在继续研究这些差异。
o1 模型的推出,为从事科学、编程、数学等领域的专业人士带来了显著的优势。例如,医疗研究人员可以利用 o1 来注释细胞测序数据,物理学家可以使用 o1 来生成复杂的量子光学公式,开发者则可以借助该模型自动化处理多步骤的工作流。
为了提供更加高效的编程解决方案,OpenAI 同时推出了 OpenAI o1-mini[3]。这是 o1 系列中的一个小型模型,专注于代码生成和调试,且成本仅为 o1-preview 的 20%。o1-mini 尽管较小,但其推理能力依然强大,特别适合那些需要编程推理但不依赖广泛世界知识的应用场景。
思维链
o1 模型采用了全新的“思维链”(CoT,Chain-of-Thought)推理机制,类似于人类在回答问题前需要深入思考的过程。该模型会在作出最终回答之前,构建一条详细的内部推理链,通过强化学习不断优化其思考过程。模型能够自我纠正错误,尝试不同的策略,并将复杂的步骤分解为更简单的部分,从而大幅提高其推理能力。
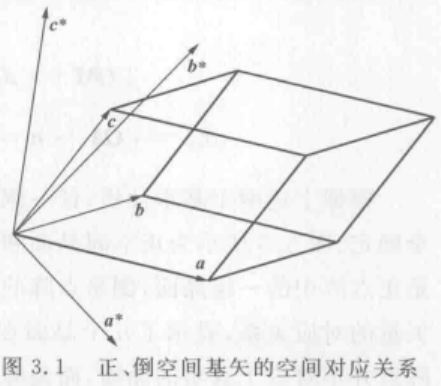
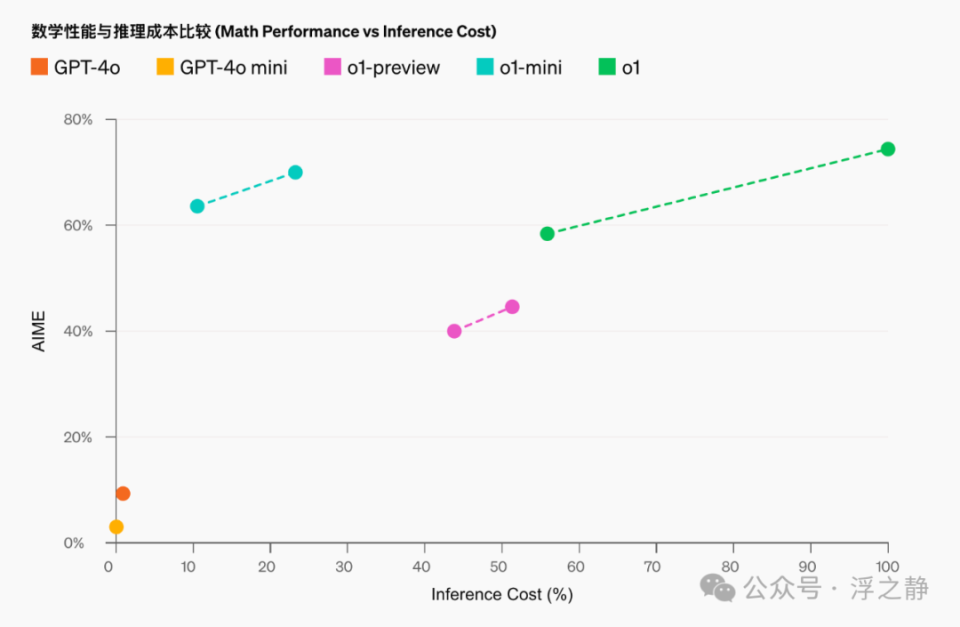
在实际测试中,o1 模型在科学、数学、编程等多项复杂任务中表现出色。例如,在美国数学奥林匹克预选赛(AIME)上,GPT-4o 只解决了 12% 的问题,而 o1 的解题率高达 74% 至 93%。在国际编程竞赛 Codeforces 中,o1 的能力达到了竞争者中的 89 百分位。此外,在博士级科学问题的测试中,o1 也超过了人类专家的表现。
安全性
为了确保模型的安全性,OpenAI 开发了新的安全训练方法,利用模型的推理能力增强其遵守安全和对齐准则的能力。通过上下文中的推理,o1 模型能够更加有效地执行和应用安全规则。在越界测试中,o1-preview 取得了远超 GPT-4o 的高分(84 分对比 22 分),显示出其强大的抗越界能力和安全性。
为了推进 AI 安全,OpenAI 还与美国和英国的 AI 安全机构建立了合作关系,并向这些机构提供了 o1 研究版的早期访问权限,以进行深入的测试与评估。
Jim Fan[4] 给出深度见解
OpenAI 推出了 Strawberry(o1)!我们终于看到了推理阶段扩展这一范式得以普及并投入实际应用。正如 Sutton 在《痛苦的教训》中所说的,只有两种技术能随着计算量的增加无限扩展:学习和搜索。现在是时候将重点转向后者了。
•你不需要庞大的模型来进行推理。大量参数用于记忆事实,以在诸如问答基准测试中表现良好。但实际上可以将推理从知识中分离出来,比如一个小的“推理核心”可以调用工具,如浏览器和代码验证器。这意味着预训练所需的计算量可能会减少。
•大量计算资源从预训练/后处理转移到了推理阶段。大型语言模型是基于文本的模拟器,通过在模拟器中展开多种可能的策略和场景,模型最终会收敛到好的解决方案。这个过程类似于像 AlphaGo 的蒙特卡洛树搜索(MCTS)等问题,已有大量研究。
•OpenAI 很早就应该已经发现了推理扩展法则,而学术界最近才开始认识到这一点。上个月有两篇论文在一周内发布在 Arxiv 上:
•《Large Language Monkeys: Scaling Inference Compute with Repeated Sampling[5]》。Brown 等人发现,DeepSeek-Coder 在 SWE-Bench 上从一次采样的 15.9% 提升至 250 次采样的 56%,击败了 Sonnet-3.5。
•《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters[6]》。Snell 等人发现,在 MATH 基准测试中,PaLM 2-S 通过测试时的搜索击败了一个大 14 倍的模型。
•将 o1 投入生产比完成学术基准测试要困难得多。在实际推理问题中,如何决定何时停止搜索?奖励函数是什么?成功的标准是什么?什么时候在循环中调用诸如代码解释器等工具?如何考虑这些 CPU 进程的计算成本?他们的研究帖子并未提供太多细节。
•Strawberry 很容易变成一个数据飞轮。如果答案是正确的,整个搜索轨迹就会变成一个包含正面和负面奖励的微型训练数据集。
这反过来会提升未来 GPT 版本的推理核心,就像 AlphaGo 的价值网络(用于评估每个棋局位置的质量)随着 MCTS 生成越来越多精细的训练数据而改进一样。
o1-mini
推进高效推理,降低成本
OpenAI o1-mini 是一款具有成本效益的推理模型。o1-mini 在 STEM 领域(特别是数学和编程)表现出色,其评估基准几乎与 OpenAI o1 持平(如 AIME 和 Codeforces)。OpenAI 预计 o1-mini 将成为需要推理但不依赖广泛世界知识的应用场景中的一个更快、更具性价比的模型。由于专注于 STEM 推理能力,o1-mini 在非 STEM 话题(如历史日期、传记、琐事知识)上的表现与小型语言模型(如 GPT-4o mini)相当。OpenAI 将在未来版本中改进这些局限,并尝试将模型扩展到 STEM 之外的其他模式和专业领域。
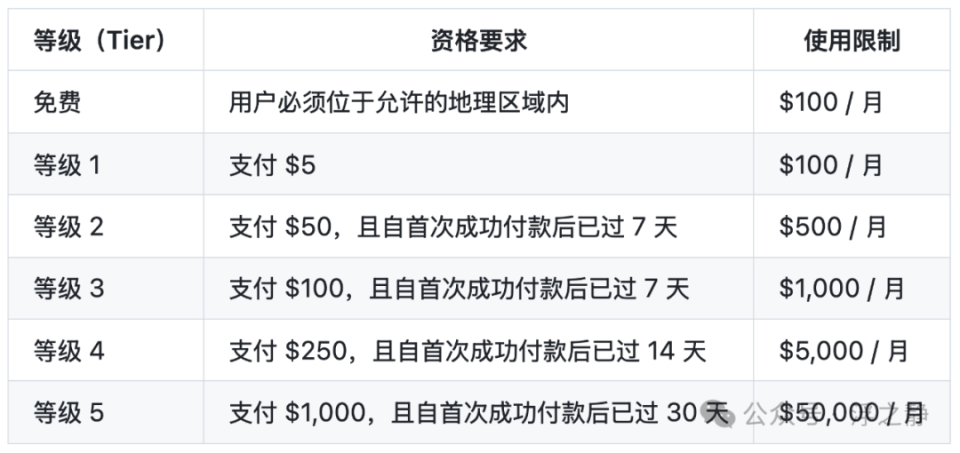
目前,OpenAI 已向第 5 层级(Tier 5) API 用户推出了 o1-mini,价格比 OpenAI o1-preview 便宜 80%。ChatGPT Plus、团队版、企业版和教育版用户也可以将 o1-mini 作为 o1-preview 的替代方案,享受更高的速率限制和更低的延迟。
📌 服务层级可以在账户设置的限制部分查看你所在组织的费率和使用限制。随着对 OpenAI API 的使用量和 API 支出增加,OpenAI 会自动将你的账户升级到下一个使用等级。这通常会导致大多数模型的速率限制增加。
STEM 推理优化
像 o1 这样的语言模型经过了大规模文本数据的预训练,尽管这些高容量模型具有广泛的世界知识,但在实际应用中,可能会显得昂贵且速度较慢。相较之下,o1-mini 是一个更小的模型,在预训练时专门针对 STEM 推理进行了优化。通过与 o1 相同的高计算量强化学习(RL)管道进行训练,o1-mini 在许多有用的推理任务中实现了类似的性能,同时显著降低了成本。
在需要智能和推理的评估基准中,o1-mini 的表现与 o1-preview 和 o1 相比非常接近。然而,o1-mini 在需要非 STEM 知识的任务中表现较弱。
数学
在高中 AIME 数学竞赛中,o1-mini 的得分为 70.0%,与 o1(74.4%)相当,且成本更低。同时,它大幅超过了 o1-preview(44.6%)。o1-mini 的得分(大约 11/15 题)将其置于全美前 500 名高中生之列。
编程
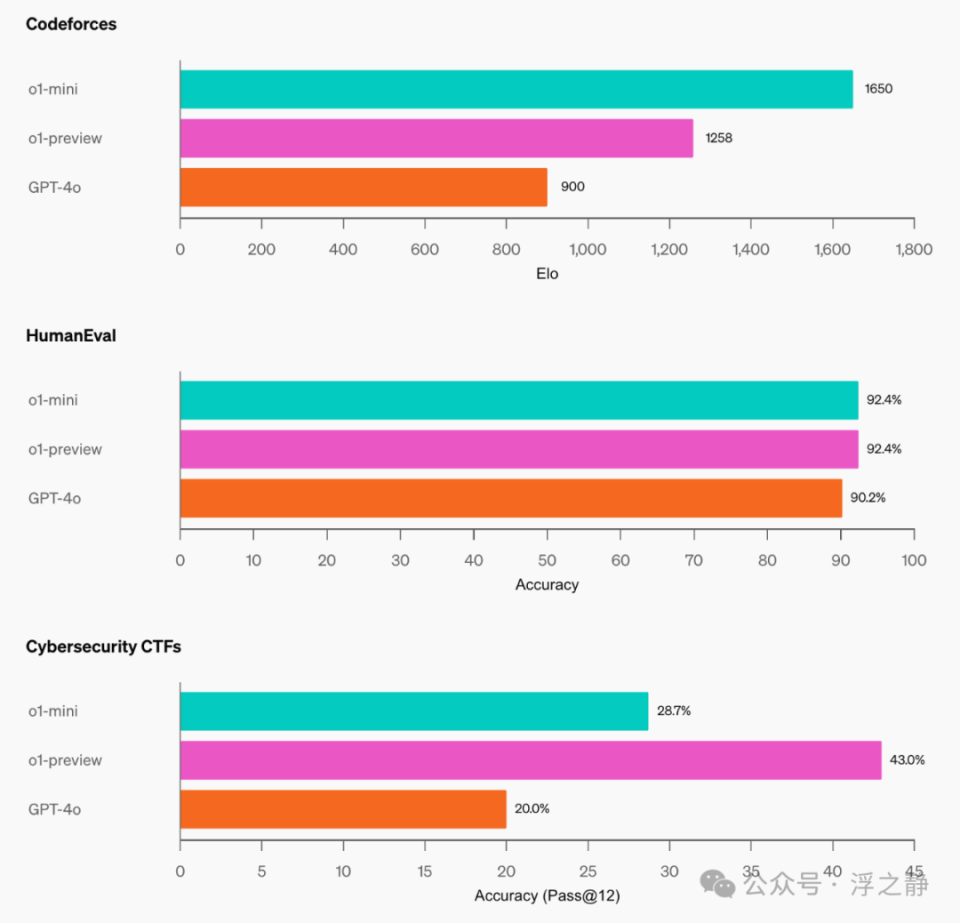
在 Codeforces 编程竞赛网站上,o1-mini 达到了 1650 Elo 分数,与 o1(1673)相当,并且高于 o1-preview(1258)。这一 Elo 分数将该模型置于 Codeforces 平台上约 86% 的程序员之上。o1-mini 在 HumanEval 编程基准测试和高中级别的网络安全夺旗赛(CTFs)中也表现出色。
STEM
在一些需要推理的学术基准测试中,如 GPQA(科学)和 MATH-500,o1-mini 表现优于 GPT-4o。然而,由于缺乏广泛的世界知识,o1-mini 在 GPQA 上的表现不如 o1-preview。
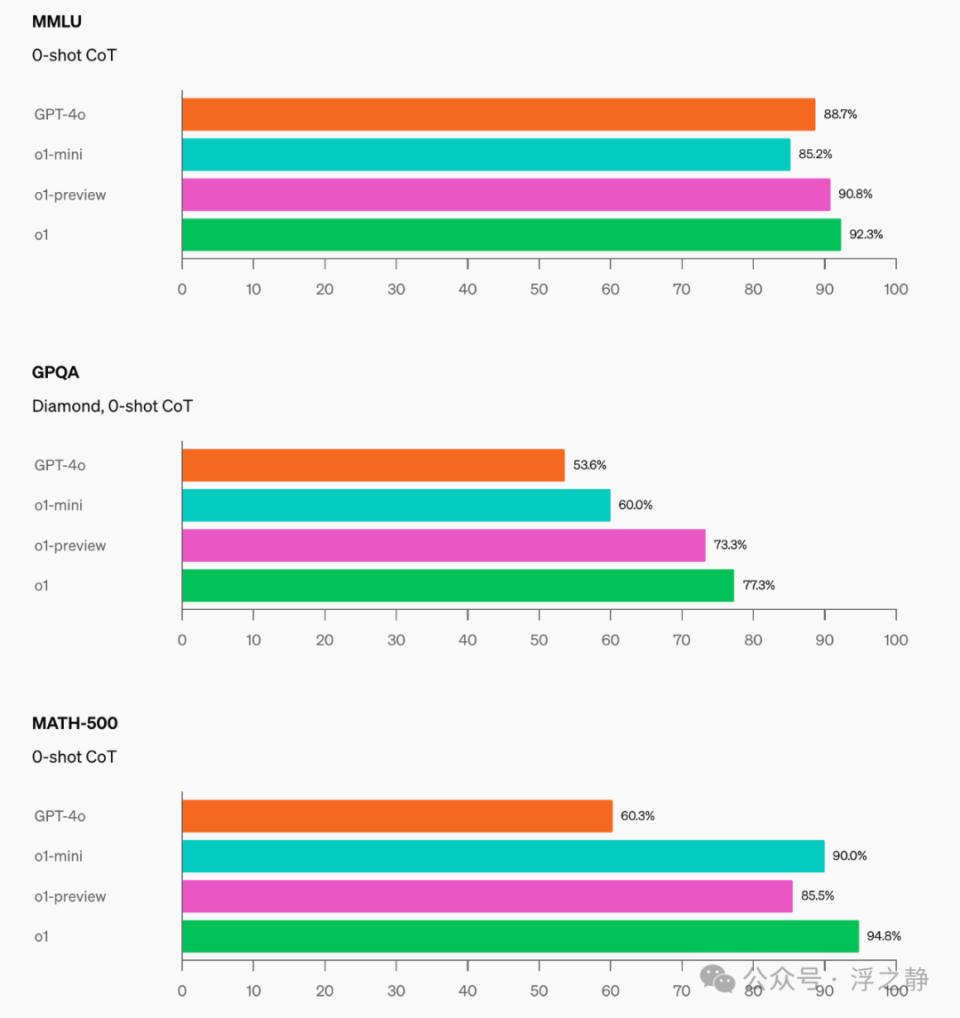
人类偏好评估
OpenAI 让人类评估者在各种领域的开放式提示上将 o1-mini 与 GPT-4o 进行了对比,使用了与 o1-preview 对比 GPT-4o 相同的方法。与 o1-preview 类似,o1-mini 在推理密集的领域中被优选,但在语言类任务中则不如 GPT-4o。
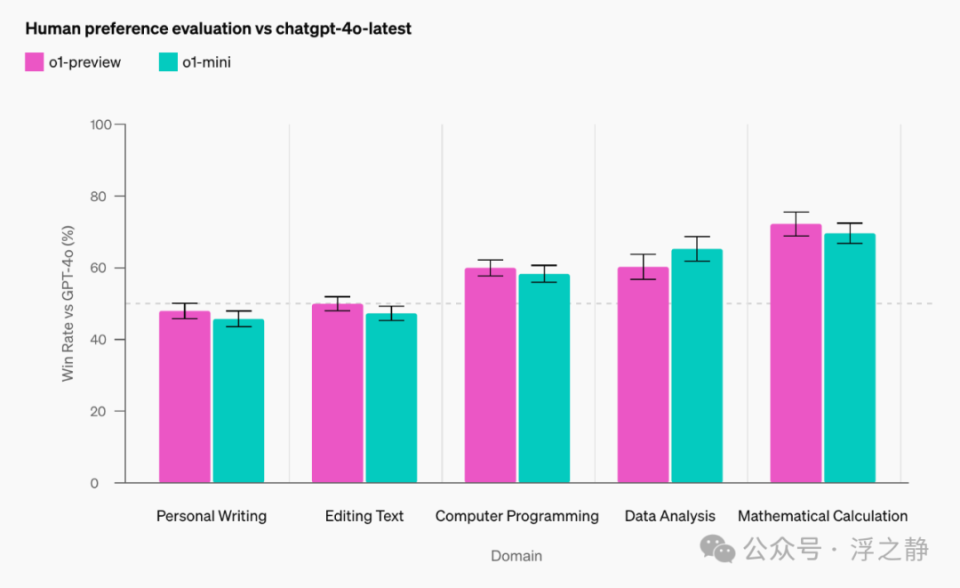
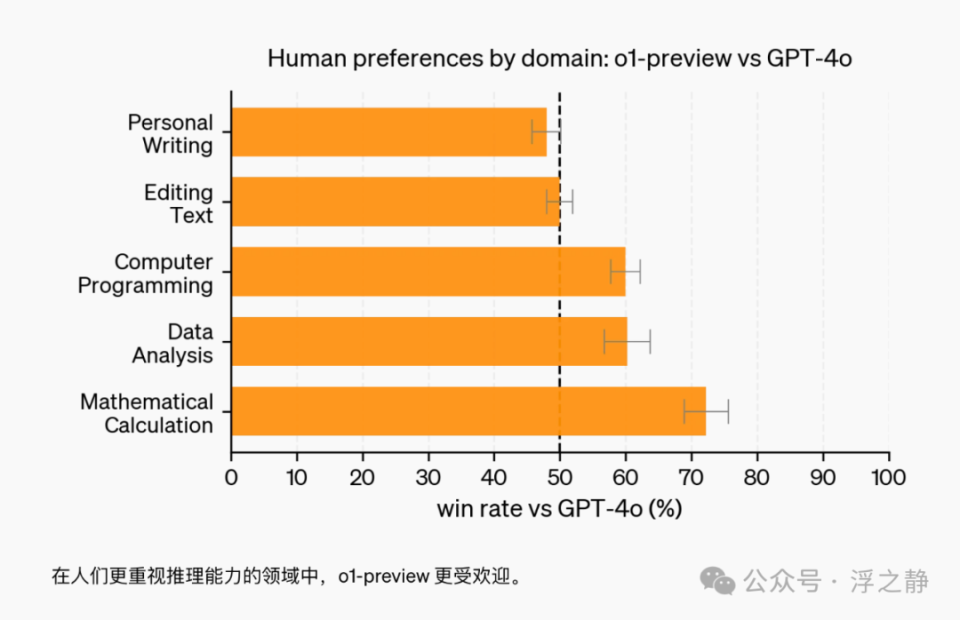
模型速度
作为具体示例,OpenAI 比较了 GPT-4o、o1-mini 和 o1-preview 在一个词语推理问题上的响应。虽然 GPT-4o 并未回答正确,但 o1-mini 和 o1-preview 都答对了,而 o1-mini 的解答速度约为 o1-preview 的 3 到 5 倍。

注:聊天速度对比,GIF 使用 x2 倍速播放。
安全性
o1-mini 使用与 o1-preview 相同的对齐和安全技术进行训练。在内部版本的 StrongREJECT 数据集上,o1-mini 的越界抵抗力比 GPT-4o 高出 59%。在部署前,OpenAI 使用与 o1-preview 相同的预备方法、外部红队测试和安全评估对 o1-mini 进行了严格的安全风险评估。评估结果将在随附的系统卡中详细展示(OpenAI o1 System Card[8])。

o1 API
目前 o1 API 中提供了两个推理模型:
-
•o1-preview:这是 o1 模型的早期预览版,设计用于利用广泛的世界知识推理复杂问题。
-
•o1-mini:这是 o1 的更快、更便宜版本,尤其擅长处理不需要广泛通识知识的编程、数学和科学任务。
o1 模型在推理方面有显著的进步,但并不适合替代所有使用场景中的 GPT-4o。对于需要图像输入、函数调用或持续快速响应的应用,GPT-4o 和 GPT-4o mini 仍然是最佳选择。然而,如果希望开发需要深度推理并能容忍较长响应时间的应用,o1 模型可能是一个很好的选择。
o1 模型目前处于功能有限的 Beta 版阶段。访问权限仅限于第 5 层级开发者,且速率限制较低(每分钟 20 次请求)。OpenAI 正在努力添加更多功能、提高速率限制,并在未来几周内向更多开发者开放访问权限!
快速开始
o1-preview 和 o1-mini 都可通过 chat completions[9] 来使用。以 Python 为例:
根据模型解决问题所需的推理量,这些请求可能需要几秒到几分钟不等的时间。
Beta 限制
在 Beta 期间,许多聊天补全 API 参数尚未提供。尤其是:
-
•模态:仅支持文本,不支持图像。
-
•消息类型:仅支持用户和助手消息,不支持系统消息。
-
•流式传输:不支持。
-
•工具:不支持工具、函数调用和响应格式参数。
-
•Logprobs:不支持。
-
•其他:temperature、top_p 和 n 固定为 1,presence_penalty 和 frequency_penalty 固定为 0。
-
•助手与批处理:这些模型不支持 Assistants API 或 Batch API。
OpenAI 将在未来几周内增加对部分参数的支持,并在 o1 系列的未来模型中包含多模态和工具使用等功能。
推理的工作原理
o1 模型引入了 reasoning tokens(推理 token)。模型使用这些推理 token 进行“思考”,分解对提示的理解,并考虑生成响应的多种方法。在生成推理 token 后,模型会生成作为可见补全 token 的答案,并从上下文中丢弃推理 token。以下是用户与助手之间的多步骤对话示例,每个步骤的输入和输出 token 都会传递,而推理 token 则会被丢弃。
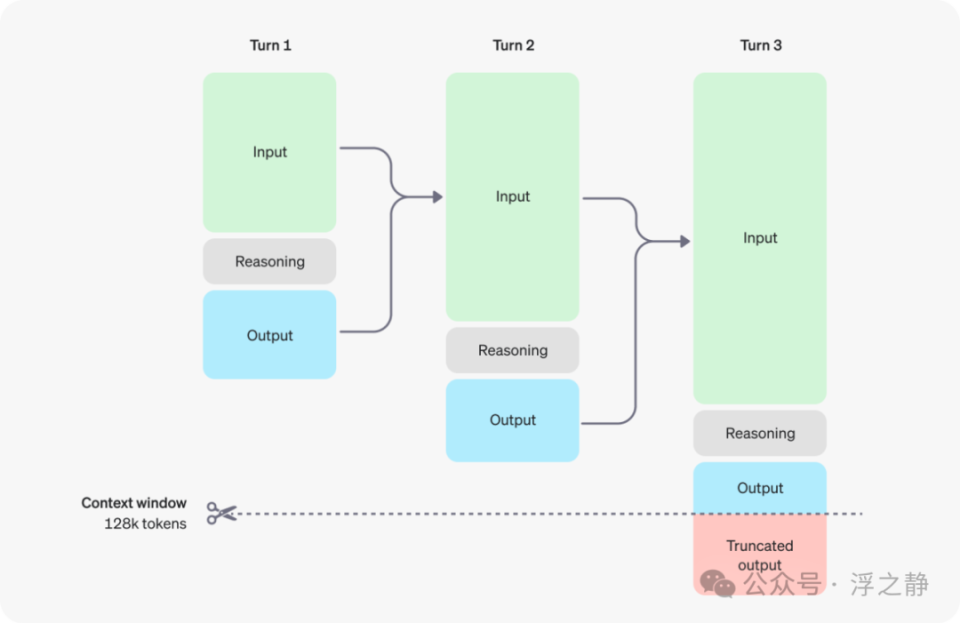
😅虽然推理 token 通过 API 不可见,但它们仍然占用模型上下文窗口中的空间,并作为输出 token 计费。
o1-preview 和 o1-mini 模型提供了 128,000 个 token 的上下文窗口。每次补全有一个输出 token 的上限——这包括不可见的推理 token 和可见的补全 token。最大输出 token 限制如下:
-
•o1-preview:最多 32,768 个 token
-
•o1-mini:最多 65,536 个 token
在创建补全时,确保上下文窗口中有足够的空间容纳推理 token。根据问题的复杂性,模型可能会生成几百到几万个推理 token。具体使用的推理 token 数量可以在聊天补全响应对象的 usage 对象中的 completion_tokens_details 下查看。
usage: {
total_tokens: 1000,
prompt_tokens: 400,
completion_tokens: 600,
completion_tokens_details: {
reasoning_tokens: 500
}
}
控制成本
为了控制 o1 系列模型的成本,你可以使用 max_completion_tokens 参数限制模型生成的 token 总数(包括推理 token 和补全 token)。
在之前的模型中,max_tokens 参数同时控制生成的 token 数量和可见 token 数量,二者始终相等。然而,在 o1 系列中,由于内部推理 token 的存在,生成的总 token 数可能超过可见 token 数。
因为一些应用程序依赖于 max_tokens 与从 API 接收的 token 数量相匹配,o1 系列引入了 max_completion_tokens 参数,以明确控制模型生成的总 token 数,包括推理 token 和可见的补全 token。这样可以确保现有应用在使用新模型时不会出现问题。max_tokens 参数在之前的所有模型中继续按原样运行。
为推理留出空间
如果生成的 token 达到上下文窗口的限制或设置的 max_completion_tokens 值,你将收到一个 finish_reason 为 length 的聊天补全响应。这可能在生成任何可见补全 token 之前发生,这意味着你可能会为输入和推理 token 支付费用,却未收到可见响应。
为避免这种情况,请确保上下文窗口中有足够的空间,或将 max_completion_tokens 值调整到更高的数值。OpenAI 建议在开始实验这些模型时,为推理和输出预留至少 25,000 个 token。随着你熟悉提示所需的推理 token 数量,可以相应调整此缓冲区。
提示建议
这些模型在处理简单提示时表现最佳。某些提示工程技术(如少样本提示或指示模型“逐步思考”)可能不会提高性能,有时甚至会影响性能。以下是一些最佳实践:
-
•保持提示简洁直接:这些模型擅长理解和回应简短、明确的指令,无需过多指导。
-
•避免链式思维提示:由于这些模型在内部执行推理,因此提示它们“逐步思考”或“解释你的推理”是不必要的。
-
•使用分隔符保持清晰:使用三重引号、XML 标签或章节标题等分隔符清楚地标明输入的不同部分,有助于模型正确解读各部分内容。
-
•限制检索增强生成(RAG)中的附加上下文:提供附加上下文或文档时,仅包括最相关的信息,以防模型过度复杂化其响应。
案例分享
韩文解密
视频展示了如何使用 OpenAI o1 模型破解一个复杂的韩文密码。该密码因结构破损而难以阅读,GPT-4o 无法正确理解,但 o1 通过推理,成功解码了这段文本。韩文由元音和辅音组合形成字符,密码的损坏源自额外辅音的添加,这给 AI 模型带来了难度。然而,o1 利用推理能力有效解析了字符,破解了密码。视频强调了推理在解决复杂问题中的关键作用。
📌 Prompt
![]() 点击画面,查看详情广告剩余: 5秒 关闭广告
点击画面,查看详情广告剩余: 5秒 关闭广告
年龄谜题
视频展示了如何利用 OpenAI o1 来解决复杂的逻辑谜题。视频中选取了一个经典的王子与公主年龄的谜题:公主的年龄与王子未来的年龄相同,当公主的年龄是王子过去年龄的两倍时,公主的年龄又等于两人当前年龄和的一半。问题要求推断出王子和公主的当前年龄。
在视频中,o1 模型将该谜题转化为一组数学方程,并通过推理求解方程。最终得出的答案是,公主的年龄为 6 * k,而王子的年龄为 8 * k,其中 k 是一个自然数。该解法展示了 OpenAI o1 在将语言描述的逻辑问题转化为数学模型,并精准求解的强大能力。
📌 PromptA princess is as old as the prince will be when the princess is twice as old as the prince was when the princess's age was half the sum of their present age. What is the age of prince and princess? Provide all solutions to this question
00:00
/
02:00
倍速
字符计数
演讲者首先从一个简单的例子切入:统计单词“草莓”(strawberry)中字母 "R" 的出现次数。接着,他指出传统模型(如 GPT-4)在这类任务上容易出错,因为这些模型主要处理文本信息,而非字符精确处理。然后,他介绍了 OpenAI o1,这是一款通过推理避免错误的新模型。在输出结果之前,OpenAI o1 会对问题进行深入思考,这使其在各类任务中表现更为出色。
00:04
/
01:28
倍速
物理世界推理
演讲者提出了一个传统语言模型难以应对的简单物理问题:将草莓放入杯子,倒置杯子放在桌上,然后将杯子放入微波炉中。问题是草莓此时的位置以及原因。演讲者展示了 OpenAI o1 如何通过推理物理世界的逻辑关系,正确解决了这个问题。这证明了 OpenAI o1 在理解物体交互和物理规律方面的优越性。
00:00
/
01:16
倍速
代码编写
演讲者详细描述了传统语言模型(如 GPT-4)在编写代码时所面临的挑战,随后介绍了 OpenAI o1。这款新模型在应对这些挑战时表现卓越。通过 OpenAI o1,演讲者成功编写出可视化 Transformer 自注意力机制的代码,其质量显著超越了手动编写的代码。
00:01
/
02:45
倍速
基因研究
作为一名遗传学家,演讲者研究罕见疾病。她发现 OpenAI o1 在研究过程中非常有帮助,能够从大量文本中提取关键信息,并引导她找到相关的研究文献。此外,OpenAI o1 还能帮助她更好地理解基因功能,从而为罕见病的治疗探索新的途径。
00:00
/
02:56
倍速
贪吃蛇游戏
视频演示了如何利用 OpenAI o1 在 HTML、CSS 和 JavaScript 中实现经典的贪吃蛇游戏。演讲者首先向观众询问他们喜欢的游戏,然后决定实现贪吃蛇游戏。通过 Web 开发工具,OpenAI o1 提供了游戏的完整代码。演讲者将代码复制到浏览器中,成功运行了游戏。随后,他进一步指示模型添加带有 “AI” 字母的障碍物,以增加游戏难度。
00:00
/
03:07
倍速
编写诗歌
视频展示了 OpenAI o1 在创作诗歌任务上的卓越表现。o1 在生成最终答案前,会对候选方案进行深入推理,确保高质量的输出。例如,在创作一首六行诗,要求主题围绕树袋熊和松鼠踢足球,且需满足特定限制:第二行最后一个词以 “i” 结尾、第三行第二个词以 “u” 开头、第五行倒数第二个词为“桉树”,且最后一行的每个词都需有两个音节。o1 展现了其强大的推理能力,通过分析押韵单词、调整句式和词序,以及组合两个音节的词汇,最终生成了一首完美符合所有限制条件的诗歌。
00:01
/
02:41
倍速
数织游戏
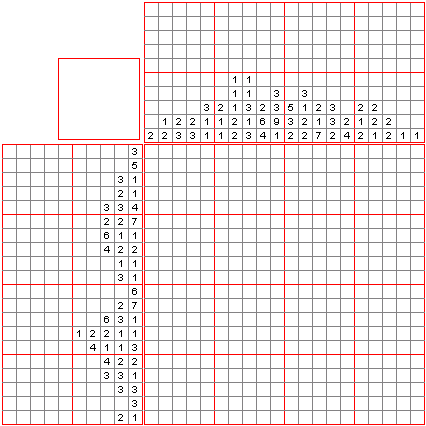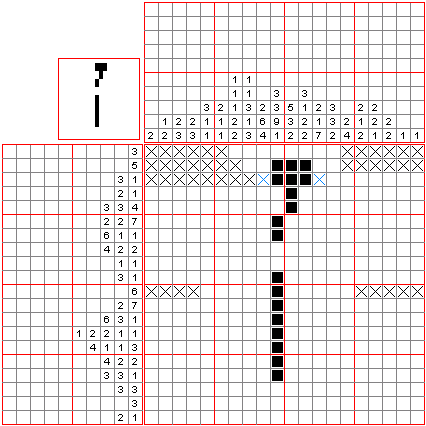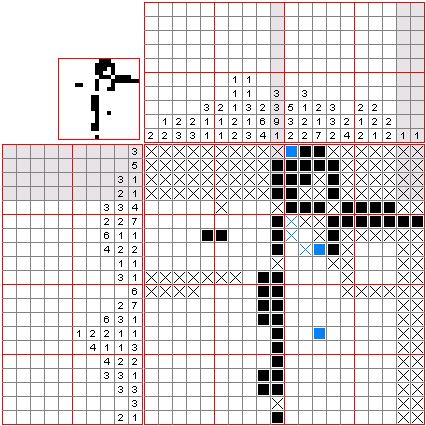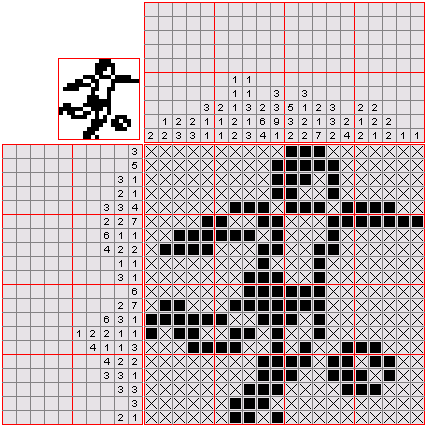
视频中演示了 OpenAI o1 如何解决数织(nonogram)谜题。数织是一种逻辑填字游戏,玩家根据数字线索填充方格,最终绘制出图案。o1 生成了一个 5x5 的数织谜题,并准确解答。通过分析候选解,验证解答的正确性和唯一性,o1 展现出其强大的推理和问题解决能力。
00:01
/
02:17
倍速
📌数织[11]是一种逻辑游戏,以猜谜的方式绘画黑白位图。在一个网格中,每一行和列都有一组数,玩家需根据它们来填满或留空格子,最后就可以由此得出一幅图画。例如,“4 8 3” 的意思就是指该行或列上有三条独立的线,分别占了 4、8 和 3 格,而每条线最少要由一个空格分开。传统上,玩家是以黑色填满格子,和以 “×” 号标记一定不需要填充的格子。数织是一个 NP 完全的问题。
数织是在 1987 年由日本人西尾彻也发明的。数织的日文名称是“お絵かきロジック”,意思是“绘画逻辑”。初见于日本的解谜者杂志,玩家用纸和笔来玩。随后,任天堂以 “Mario's Picross” 为名推出了两款 Game Boy 和九款超级任天堂游戏。现时任天堂 DS 上亦有名为 Picross DS 的同款游戏。2015 年 12 月,任天堂推出了名为 “Pokémon Picross” 的 3DS 游戏。
Squirrel Finder
该视频展示了 OpenAI o1 如何创建简单的 “Squirrel Finder” 游戏,玩家通过控制一只考拉躲避弹跳的草莓,找到松鼠获胜。视频演示了 o1 生成的代码,包括游戏布局、元素及说明。最终,代码被成功执行,展示了游戏运行效果。




![[大语言模型-论文精读] Diffusion Model技术-通过时间和空间组合扩散模型生成复杂的3D人物动作](https://i-blog.csdnimg.cn/direct/036b96f856d24e0da802ef18ab88d59b.png)










![[spring]用MyBatis XML操作数据库 其他查询操作 数据库连接池 mysql企业开发规范 动态sql](https://i-blog.csdnimg.cn/direct/f2b12158898c4aec9f16b03f8f0f30c2.png)