背景
在机器学习中,特征的重要性是了解模型如何做出预测的关键指标之一,在树模型中,特征重要性通常通过特征的分裂节点来衡量,通过观察特征在模型中的贡献,可以对数据集中的重要特征有更深入的理解,之前的文章中,分别介绍了如何通过RF、 XGBoost 和 LightGBM 来提取特征贡献度,在本篇文章中,将加入 CatBoost 模型,并进行可视化综合比较这些树模型中的特征重要性
加载数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
plt.rcParams['font.family'] = 'Times New Roman'
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_excel('气象、环境、火灾烧毁.xlsx')
# 划分特征和目标变量
X = df.drop(['month', 'day', 'area'], axis=1)
y = df['area']
# 划分训练集和测试集
# 注意:random_state=42 是为了确保结果的可复现性,并且针对该数据集进行了特定处理。读者在使用自己的数据时,可以自由修改此参数。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=42)
df.head()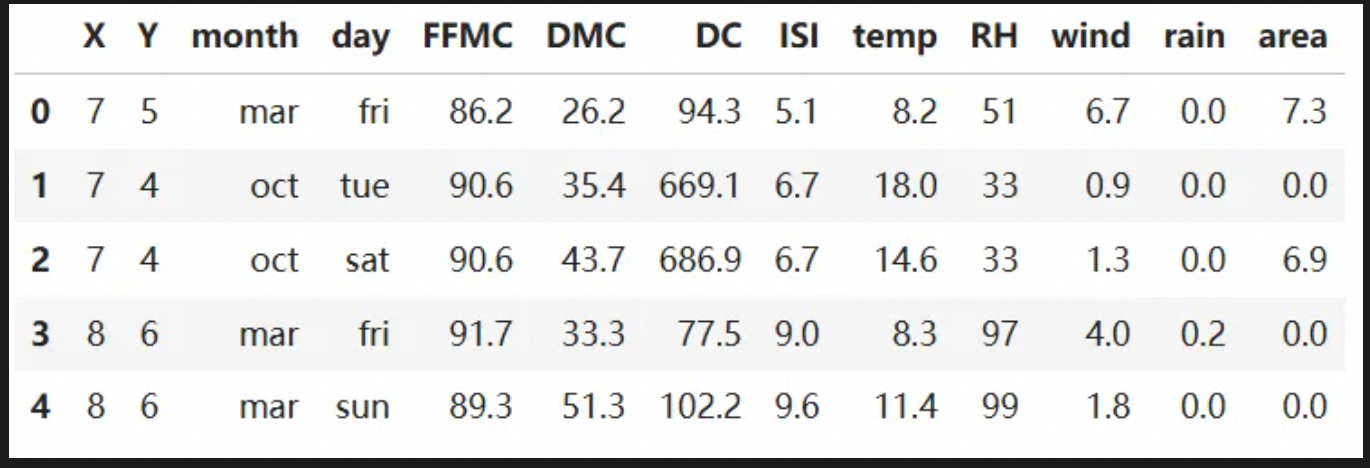
"这个数据集包含了气象、环境和火灾信息,其中X、Y表示地理位置,month和day是日期信息,FFMC、DMC、DC、ISI是火灾相关的气象指数,temp表示温度,RH是湿度,wind是风速,rain是降雨量,area是火灾烧毁的面积,在建模时,我们未使用日期信息(month 和 day)
多个模型训练
对四种常用的树模型(随机森林、XGBoost、LightGBM 和 CatBoost)的回归任务进行建模,首先,为每个模型设置初始参数,并定义用于网格搜索的超参数范围(如,树的数量、深度、学习率等),然后,通过 GridSearchCV 对每个模型进行 5 折交叉验证,在不同的超参数组合下寻找最佳模型配置,优化评价指标为负均方误差(MSE),模型训练完成后,还原计算最优模型的均方根误差(RMSE),作为模型性能的评估标准。最后,使用这些最优参数重新训练模型以得到最终模型
from sklearn.ensemble import RandomForestRegressor
# 创建随机森林回归器实例,并设置参数
rf_regressor = RandomForestRegressor(
n_estimators=100, # 'n_estimators'是森林中树的数量。默认是100,可以根据需要调整。
criterion='squared_error', # 'criterion'参数指定用于拆分的质量指标。'squared_error'(默认)表示使用均方误差,另一选项是'absolute_error'。
max_depth=None, # 'max_depth'限制每棵树的最大深度。'None'表示不限制深度。
min_samples_split=2, # 'min_samples_split'指定一个节点分裂所需的最小样本数。默认是2。
min_samples_leaf=1, # 'min_samples_leaf'指定叶子节点所需的最小样本数。默认是1。
min_weight_fraction_leaf=0.0, # 'min_weight_fraction_leaf'与'min_samples_leaf'类似,但基于总样本权重。默认是0.0。
random_state=42, # 'random_state'控制随机数生成,以便结果可复现。42是一个常用的随机种子。
max_leaf_nodes=None, # 'max_leaf_nodes'限制每棵树的最大叶子节点数。'None'表示不限制。
min_impurity_decrease=0.0 # 'min_impurity_decrease'在分裂节点时要求的最小不纯度减少量。默认是0.0。
)
# 训练模型
rf_regressor.fit(X_train, y_train)
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
# XGBoost回归模型参数
params_xgb = {
'learning_rate': 0.02, # 学习率,控制每一步的步长,用于防止过拟合。典型值范围:0.01 - 0.1
'booster': 'gbtree', # 提升方法,这里使用梯度提升树(Gradient Boosting Tree)
'objective': 'reg:squarederror', # 损失函数,这里使用平方误差,适用于回归任务
'max_leaves': 127, # 每棵树的叶子节点数量,控制模型复杂度
'verbosity': 1, # 控制 XGBoost 输出信息的详细程度,0表示无输出,1表示输出进度信息
'seed': 42, # 随机种子,用于重现模型的结果
'nthread': -1, # 并行运算的线程数量,-1表示使用所有可用的CPU核心
'colsample_bytree': 0.6, # 每棵树随机选择的特征比例,用于增加模型的泛化能力
'subsample': 0.7, # 每次迭代时随机选择的样本比例,用于增加模型的泛化能力
'eval_metric': 'rmse' # 评价指标,这里使用均方根误差(rmse)
}
# 初始化XGBoost回归模型
model_xgb = xgb.XGBRegressor(**params_xgb)
# 定义参数网格,用于网格搜索
param_grid = {
'n_estimators': [100, 200, 300, 400, 500], # 树的数量
'max_depth': [3, 4, 5, 6, 7], # 树的深度
'learning_rate': [0.01, 0.02, 0.05, 0.1], # 学习率
}
# 使用GridSearchCV进行网格搜索和k折交叉验证
grid_search = GridSearchCV(
estimator=model_xgb,
param_grid=param_grid,
scoring='neg_mean_squared_error', # 评价指标为负均方误差
cv=5, # 5折交叉验证
n_jobs=-1, # 并行计算
verbose=1 # 输出详细进度信息
)
# 训练模型
grid_search.fit(X_train, y_train)
# 输出最优参数
print("Best parameters found: ", grid_search.best_params_)
print("Best RMSE score: ", (-grid_search.best_score_) ** 0.5) # 还原RMSE
# 使用最优参数训练模型
best_model_xgboost = grid_search.best_estimator_
import lightgbm as lgb
# LightGBM回归模型参数
params_lgb = {
'learning_rate': 0.02, # 学习率,控制每一步的步长,用于防止过拟合
'boosting_type': 'gbdt', # 提升方法,这里使用梯度提升决策树
'objective': 'regression', # 损失函数,这里使用回归任务
'num_leaves': 127, # 每棵树的叶子节点数量,控制模型复杂度
'verbosity': 1, # 控制 LightGBM 输出信息的详细程度
'seed': 42, # 随机种子,用于重现模型的结果
'n_jobs': -1, # 并行运算的线程数量,-1表示使用所有可用的CPU核心
'colsample_bytree': 0.6, # 每棵树随机选择的特征比例,用于增加模型的泛化能力
'subsample': 0.7, # 每次迭代时随机选择的样本比例,用于增加模型的泛化能力
'metric': 'rmse' # 评价指标,这里使用均方根误差(rmse)
}
# 初始化LightGBM回归模型
model_lgb = lgb.LGBMRegressor(**params_lgb)
# 定义参数网格,用于网格搜索
param_grid = {
'n_estimators': [100, 200, 300, 400, 500], # 树的数量
'max_depth': [3, 4, 5, 6, 7], # 树的深度
'learning_rate': [0.01, 0.02, 0.05, 0.1], # 学习率
}
# 使用GridSearchCV进行网格搜索和k折交叉验证
grid_search = GridSearchCV(
estimator=model_lgb,
param_grid=param_grid,
scoring='neg_mean_squared_error', # 评价指标为负均方误差
cv=5, # 5折交叉验证
n_jobs=-1, # 并行计算
verbose=1 # 输出详细进度信息
)
# 训练模型
grid_search.fit(X_train, y_train)
# 输出最优参数
print("Best parameters found: ", grid_search.best_params_)
print("Best RMSE score: ", (-grid_search.best_score_) ** 0.5) # 还原RMSE
# 使用最优参数训练模型
best_model_lgb = grid_search.best_estimator_
import catboost as cb
# CatBoost回归模型参数
params_catboost = {
'learning_rate': 0.02, # 学习率,控制每一步的步长
'loss_function': 'RMSE', # 损失函数,这里使用均方根误差(RMSE)
'eval_metric': 'RMSE', # 评价指标,这里同样使用RMSE
'random_seed': 42, # 随机种子
'verbose': 100, # 控制 CatBoost 输出信息的详细程度,输出每100次迭代的进度
'thread_count': -1, # 使用所有可用的CPU核心
'bootstrap_type': 'Bernoulli', # 自举类型,用于控制模型的泛化能力
'subsample': 0.7, # 每次迭代时随机选择的样本比例
'colsample_bylevel': 0.6 # 每层随机选择的特征比例,用于增加模型的泛化能力
}
# 初始化CatBoost回归模型
model_catboost = cb.CatBoostRegressor(**params_catboost)
# 定义参数网格,用于网格搜索
param_grid = {
'iterations': [100, 200], # 迭代次数(等价于树的数量)
'depth': [3, 4], # 树的深度
'learning_rate': [0.05, 0.1], # 学习率
}
# 使用GridSearchCV进行网格搜索和k折交叉验证
grid_search = GridSearchCV(
estimator=model_catboost,
param_grid=param_grid,
scoring='neg_mean_squared_error', # 评价指标为负均方误差
cv=5, # 5折交叉验证
n_jobs=-1, # 并行计算
)
# 训练模型
grid_search.fit(X_train, y_train)
# 输出最优参数
print("Best parameters found: ", grid_search.best_params_)
print("Best RMSE score: ", (-grid_search.best_score_) ** 0.5) # 还原RMSE
# 使用最优参数训练模型
best_model_catboost = grid_search.best_estimator_多模型特征重要性提取
提取和排序随机森林、XGBoost、LightGBM 和 CatBoost 模型的特征重要性,生成一个包含各模型特征贡献度的 DataFrame,以便比较不同模型对特征重要性的评估差异,代码在获取特征贡献度时,随机森林、XGBoost 和 LightGBM 都通过各自的 feature_importances_ 属性提取特征重要性,而 CatBoost 则使用 get_feature_importance() 方法获取
# 获取RandomForest特征重要性并排序
rf_feature_importances = rf_regressor.feature_importances_
rf_sorted_indices = np.argsort(rf_feature_importances)[::-1]
rf_sorted_features = X_train.columns[rf_sorted_indices]
rf_sorted_importances = rf_feature_importances[rf_sorted_indices]
# 获取XGBoost特征重要性并排序
xgb_feature_importances = best_model_xgboost.feature_importances_
xgb_sorted_indices = np.argsort(xgb_feature_importances)[::-1]
xgb_sorted_features = X_train.columns[xgb_sorted_indices]
xgb_sorted_importances = xgb_feature_importances[xgb_sorted_indices]
# 获取LightGBM特征重要性并排序
lgb_feature_importances = best_model_lgb.feature_importances_
lgb_sorted_indices = np.argsort(lgb_feature_importances)[::-1]
lgb_sorted_features = X_train.columns[lgb_sorted_indices]
lgb_sorted_importances = lgb_feature_importances[lgb_sorted_indices]
# 获取CatBoost特征重要性并排序
catboost_feature_importances = best_model_catboost.get_feature_importance()
catboost_sorted_indices = np.argsort(catboost_feature_importances)[::-1]
catboost_sorted_features = X_train.columns[catboost_sorted_indices]
catboost_sorted_importances = catboost_feature_importances[catboost_sorted_indices]
# 创建一个DataFrame来保存所有模型的特征重要性
feature_importance_df = pd.DataFrame({
"RandomForest_Feature": rf_sorted_features,
"RandomForest_Importance": rf_sorted_importances,
"XGBoost_Feature": xgb_sorted_features,
"XGBoost_Importance": xgb_sorted_importances,
"LightGBM_Feature": lgb_sorted_features,
"LightGBM_Importance": lgb_sorted_importances,
"CatBoost_Feature": catboost_sorted_features,
"CatBoost_Importance": catboost_sorted_importances
})
feature_importance_df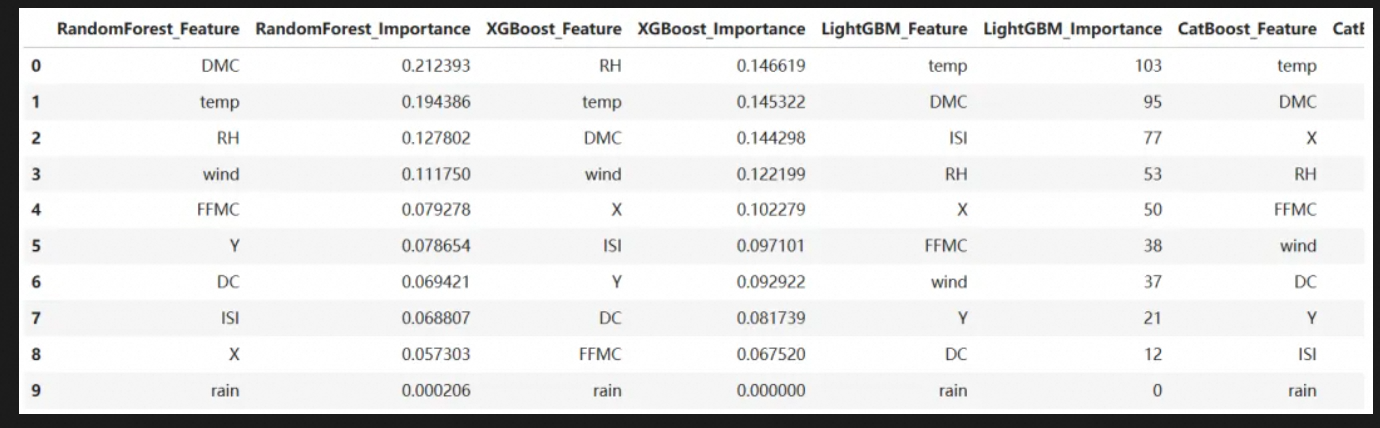
特征重要性可视化比较
使用 NetworkX 库构建了一个有向图,用于可视化多个模型中提取的特征重要性排名的比较
展示了四种不同机器学习模型(随机森林、XGBoost、LightGBM 和 CatBoost)中的特征重要性排名对比。每个圆圈代表一个特征,其在垂直方向上的位置表示该特征在相应模型中的重要性排名。颜色从深蓝色(重要性高)到浅蓝色(重要性低)逐渐变化【针对第一个模型后面为相同特征相同颜色】,以突出每个特征的排名顺序。箭头用于连接相同的特征,帮助比较这些特征在不同模型中的重要性变化。例如,“DMC”和“temp”在大多数模型中都被认为是较为重要的特征,而像“rain”这样的特征在各个模型中的排名较低。通过节点之间的连接,可以直观地看到每个特征在不同模型中的重要性是如何变化的
import networkx as nx
feature = feature_importance_df[['RandomForest_Feature', 'XGBoost_Feature', 'LightGBM_Feature', 'CatBoost_Feature']]
plt.figure(figsize=(12, 8), dpi=1200)
# 创建一个有向图
G = nx.DiGraph()
unique_features = pd.unique(feature.values.ravel('K'))
# 使用一个色系的渐变色
colors = plt.cm.Blues_r(np.linspace(0.3, 0.9, len(unique_features)))
feature_color_map = {feature_name: colors[i % len(colors)] for i, feature_name in enumerate(unique_features)}
pos = {}
for i, model in enumerate(feature.columns):
for j, feature_name in enumerate(feature[model]):
# 添加节点
G.add_node(f'{model}_{feature_name}', label=feature_name)
pos[f'{model}_{feature_name}'] = (i, -j)
if i > 0:
previous_model = feature.columns[i - 1]
for prev_j, prev_feature_name in enumerate(feature[previous_model]):
if feature_name == prev_feature_name:
G.add_edge(f'{previous_model}_{prev_feature_name}', f'{model}_{feature_name}', color='black') # 固定边的颜色为黑色
node_labels = nx.get_node_attributes(G, 'label')
node_colors = [feature_color_map[node_labels[node]] for node in G.nodes()]
nx.draw(G, pos, labels=node_labels, with_labels=True, node_color=node_colors, node_size=3000, font_size=10)
edges = G.edges()
nx.draw_networkx_edges(G, pos, edge_color='black', arrowstyle='-|>', arrowsize=20, width=2)
for i, model in enumerate(feature.columns):
plt.text(i, -len(feature), model, horizontalalignment='center', fontsize=12, fontweight='bold')
plt.gca().set_axis_off()
plt.title('Feature Ranking Comparison Across Models with Gradual Color Scheme and Styled Arrows')
plt.savefig("Feature Ranking Comparison Across Models with Gradual Color Scheme and Styled Arrows.pdf",bbox_inches='tight')
plt.show()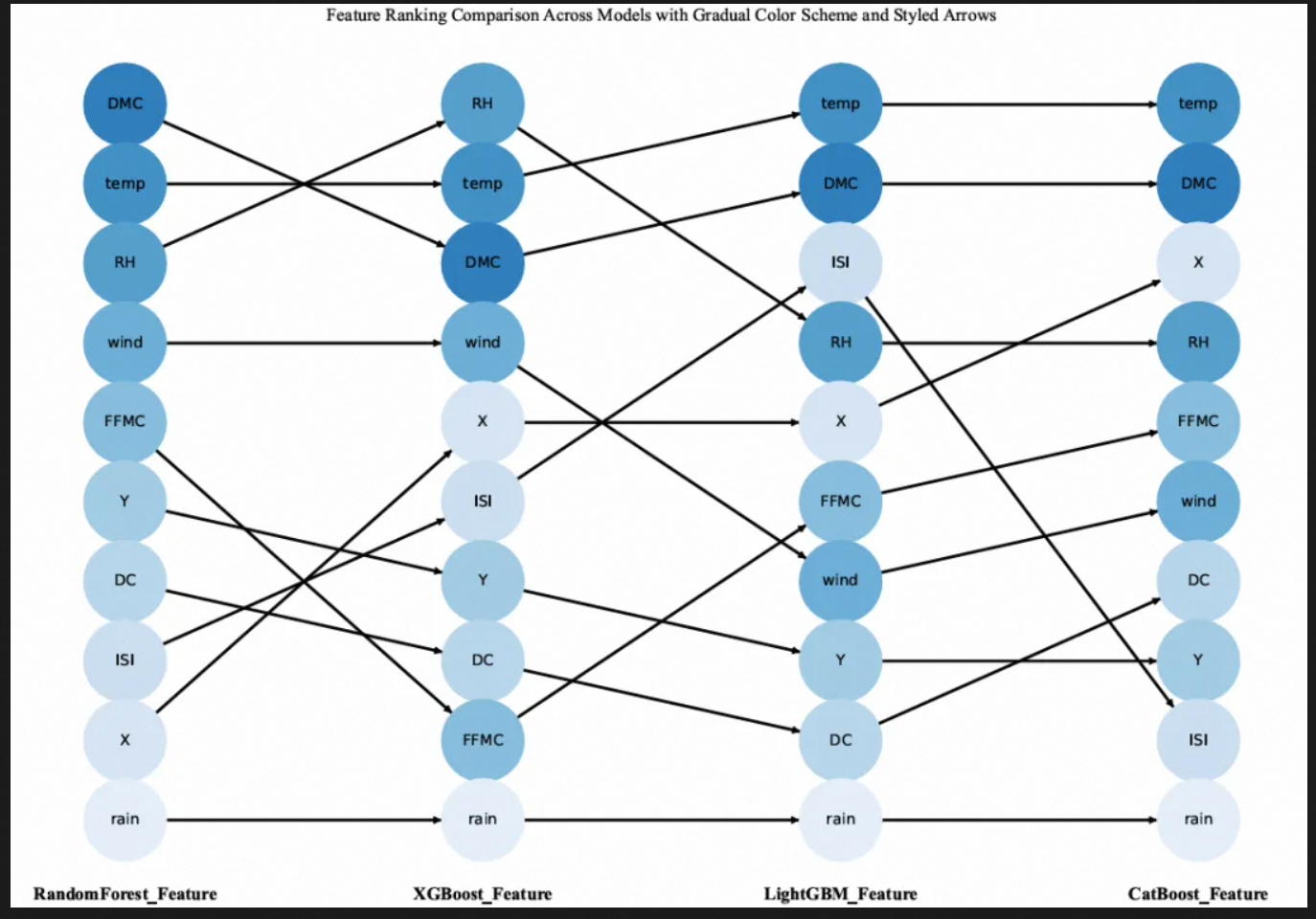














![[数据集][目标检测]辣椒缺陷检测数据集VOC+YOLO格式695张5类别](https://i-blog.csdnimg.cn/direct/fe807c92e6a6466facf5814713ed790d.png)


![[Python学习日记-30] Python中数据类型与文件操作的补充(Bytes 类型、字符编码的转换、深浅 Copy)](https://i-blog.csdnimg.cn/direct/c61c4f5463204867977d5df8528101a2.png)
