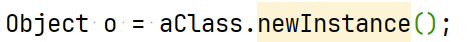cscircles.cemc.uwaterloo.ca/java_visualize/#mode=display
public class ClassNameHere {
public static void main(String[] args) {
Walrus a = new Walrus(1000, 8.3);
Walrus b;
b = a;/*由于缺少函数,导致两个对象指向的是同一份*/
b.weight = 5;
System.out.println(a);
System.out.println(b);
int x = 5;
int y;
y = x;
x = 2;
System.out.println("x is :" + x);
System.out.println("y is :" + y);
}
public static class Walrus {
public int weight;
public double tuskSize;
public Walrus(int w, double ts) {
weight = w;
tuskSize = ts;
}
public String toString() {
return String.format("weight:%d,tusk size:%.2f", weight, tuskSize);
}
}
}
nslookup -type=NS https://csdiy.wiki/
通过此查询DNS,知道服务器一个实例化的对象,如海象,new给了32位和64位的空间并且都是0,然后返回地址。但是java会给64位盒子无论是什么数据类型,当其中数据不是NULL时,会让框的指针指向数据,那个64位盒子就会保存地址
 这就是传参的奥秘,
这就是传参的奥秘,
那么当我们向函数传递参数会如何?

第6集讲了数组
第7集的链表
public class IntList {
public int first;
public IntList rest;
public static void main(String[] args){
IntList L = new IntList();
L.first=5;
L.rest=null;
L.rest=new IntList();
L.rest.first=10;
L.rest.rest=new IntList();
L.rest.rest.first=20;
}
}使用起来很不爽,语言上的重复迭代让人改进:如下
public class IntList {
public int first;
public IntList rest;
public IntList(int f,IntList r) {
first = f;
rest = r;
}
public static void main(String[] args) {
IntList L =new IntList(15,null);
L=new IntList(10,null);
L=new IntList(5,null);
}
}如何加一些呢?我们添加size or iterativeSize功能
public int size(){
if(rest==null){
return 1;
}
return 1+this.rest.size();
}
public int ierativeSize(){
IntList p=this;
int totalSize=0;
while(p!=null){
totalSize+=1;
p=p.rest;
}
return totalSize;
}
现在要求get()返回list的第i个项目 
public int get(int i){
if(i==0){
return first;
}
return rest.get(i-1);
}SLLists and Avoiding Nakedness
接下来,Josh说这是裸体naked的all along,很难使用 。即发现IntList类中它的数据结构有一些裸露,即所有的方法、变量、构造方法都在一个类中。这不太符合Java语言创造数据结构的习惯。所以在这一章中,我们希望可以创造一件“衣服”,通过这个“衣服”,即中间类,架起外部类接触到内部数据结构的桥梁。实现左 to 右


我们剥离了所有功能,写写如下代码
/** An SLlist is a list of integers,which hides the terrible truth
* of the nakedness within*/
public class SLList{
public IntNode first;
public SLList(int x){
first =new IntNode(x,null);
}
/*Adds x to the front of the list*/
public void addFirst(int x){
first = new IntNode(x,first);
}
/*Return the first item in the list*/
public int getFirst(){
return first.item;
}
public staticvoid main (String[] args){
/*creates a list of one integer,namely 10*/
SLList L = new SLList(10);
L.addFirst(1);
L.addFirst(10);
System.out.println(L.getFirst());
}
}
public class IntNode{
public int item;
public IntNode next;
public IntNode (int i,IntNode n)
{
item = i;
next = n;
}
}
比较一下在这两种情况

可能有一个 列表的前面,这涉及到递归,但另一个涉及到中间人正如上图所示。
第四集,josh表示由于权限设定不明显,可以做出无限循环 链表的语句,如最后一个指针指向某元素such他自己
引入private 是为了向类的用户隐藏实现细节,用户无需知道,将其视为幕后事件,SLList就像一个黑匣子,不必了解内部的递归数据结构,
 允许绕过private,就像cpp中的友元
允许绕过private,就像cpp中的友元
 嵌套类在前和在后什么顺序都没关系
嵌套类在前和在后什么顺序都没关系
后三张图需和字幕进行配对



那么为什么呢?嵌套类有什么好处?好吧,每当您声明的类不独立时,每当很明显 IntNode 实际上只是 SLList 且仅由 SLLists 使用的东西时,它们就很有用。它在某种程度上从属于 SLList 类。现在,有时,您实际上希望外部程序能够创建 IntNode 的实例或以某种方式直接操作它们。所以我可以,例如 - 这将是非常奇怪的行为 - 但我可以做类似 public IntNode getFrontNode 的事情,在这种情况下,我确实需要将 IntNode 类公开,以便有人实际上能够创建 IntNode 或拥有引用给他们。但在这样的类中,用户甚至不需要知道 IntNode,我们可以将其设为私有。所以这样一来,这说明 IntNodes 永远不能由外部用户创建。因此,如果我们有 SLList 用户,则无法创建 IntNode。但我们有点吹毛求疵。对于视频来说,这可能有点无聊。但基本的经验法则是,如果没有其他人需要 IntNode 引用,请将其设为私有。现在,更深入一点——我不想过多地了解 Java 的细节——但如果是嵌套类的情况——所以我说如果没有外部类使用 IntNodes,则将其设为私有,好吧——这又是一件类似的事情。如果 IntNode 类从不使用 SLList 类的任何细节,如果嵌套类从不需要查找,则可以在此处添加 static 一词。现在,“静态”这个词似乎出现在很多奇怪的地方。我现在不打算讨论为什么我决定使用 static 这个词,但你可以想象这个关键字永远不会向外看。但事实并非如此。它是静态的。这意味着,对于 IntNode 类,我无法在这里编写首先使用的方法。那是不允许的。因此,由于这不是类,如果你看一下它,它有自己的项目、自己的下一个构造函数,但它从不尝试使用 SLList 的任何东西——没有它的方法、没有它的构造函数、没有它的任何东西。变量。所以我们可以将其设为静态。现在,那有什么好处呢?嗯,它为每个 IntNode 节省了一点点内存。您可以在书中查找更多详细信息。但基本思想很简单,静态的嵌套类无法访问外部类的任何内容。现在,我确信我已经将你推向了你大脑中无需任何练习就能容纳的语法数量的极限,所以不要太担心。这是你将有机会在项目 1 中探索一点的东西。冒着让本次讲座变得更无聊、更分钟的风险,我会做一个非常小的说明,每当你做一个对于私有嵌套类,这些访问修饰符不再重要。但这不是一个重要的 Java 细节。这些是我们基本上可以对 SLList 类进行的一些改进。我们可以将这个类设为私有静态嵌套类,并且可以将第一个变量设为私有。
现在,我们对SLList有了四个改进 更名:IntList->IntNode
管理的新类:SLList
访问控制:public和private
嵌套类:将 IntNode 引入 SLList,
有了两个方法addFirst和getFirst,接下来我们添加addLast(int x)和size()
public void addLast(int x){
IntNode p=first;
/*move p until it reaches the end of list*/
while(p.next!=null){
p=p.next;
}
p.next = new IntNode(x,null);
}如果在可视化界面运行上述代码,你会看到一个嵌套界面
现在进行size方法,但是递归return first.next.size()显然有点奇怪,所以老师推荐大家使用私有静态帮助器private static,
/*returns the size of the list that starts at IntNode p*/
private static int size(IntNode p){
if(p==null){
return 1;
}
return 1 + size(p.next);
}
public int size(){
if(first==null){return 1;}
return size().first;
}但是这种方法显然很慢,最差时间复杂度是O(N),因此我们预先定义一个size,每次add时加1即可。
private int size = 1;
public int size(){
return size;
}
接下来我们实例化一个空列表,

假设我们有一个空列表,如果first=null, p也就=null,但是addlast里面要求p.next!=null,因此到下一个空变量,这会导致空指针,
解决此问题的一种方法是new 一个新的链表
但是这很难看,因为当转移到树或者多个链表的复杂结构,导致难办
现在,空列表将不会有空指针,相反他将指向一个节点,我将其称为哨兵节点,一个始终存在的节点
public class SLList{
private static class IntNode{
public int item;
public IntNode next;
public IntNode (int i, IntNode n)
{
item = i;
next = n;
}
};
/*The first item (if it exists) is at sentinel.next*/
private IntNode sentinel;
private int size;
public SLList(){
sentinel =new IntNode(63,null);
size = 0;
}
public SLList(int x){
sentinel =new IntNode(63,null);
sentinel.next = new IntNode(x,null);
size = 1;
}
/*Adds x to thr front of the list*/
public void addFirst(int x)
{
sentinel.next = new IntNode(x,sentinel.next);
size++;
}
public int getFirst(){
return sentinel.next.item;
}
public void addLast(int x){
size+=1;
IntNode p=sentinel;
while(p.next!=null){
p=p.next;
}
p.next = new IntNode(x,null);
}
public int size()
{
return size;
}
public static void main(String[] args)
{
SLList L=new SLList();
L.addLast(20);
System.out.println(L.size());
}
}

但是他只能保存整数接下来进行拓展
DLList and Arrays
添加和会很快,但是删除会很慢
启示在于意识到如果每个节点都有一个指向前一个节点的指针,我们就不需要从头开始扫描以找到前一个节点。换句话说,如果50有一个指向包含9的节点的指针,而包含9的节点有一个指向3的节点的指针,这个节点又有一个指向哨兵(sentinel)的指针,那么如果我们想要找到任何一个前一个节点,我们只需要跟随那个指针即可。因此,我们最终得到了这种拓扑结构,其中每个节点不仅有项和下一个指针,还有上一个指针。然后这种方式通常被称为双向链表,每个节点有两个链接,这与我们之前只有单向指针的单向链表相反。现在你知道了,所以这种方法的优点是,一旦我们添加了这两个链接,我们的添加方法变得快速,获取方法变得快速,从任一端移除的方法也变得快速,因此涉及列表两端的操作将花费常数时间,尽管中间的操作会较慢,我们稍后会讨论处理这些操作的替代方法,但从链表的角度来看,这是通常实现链表的方式。

虽然这种方法很好且易于编码,但我认为还有一种更好的方法。这就是如果你爬到山顶,去找正在山顶寺庙里修行的和尚,并问什么是真正的双向链表,经过漫长而艰难的攀登后,你真的在寻求答案,这便是你会得到的答案。在这个方法中,不是在每一端都放置一个哨兵,而是在两端同时使用一个哨兵。你可能会问,这怎么可能?山上的和尚可能会说,当你有一个空列表时,前一个是哨兵本身,后一个也是哨兵本身。这时你可能对和尚感到有些恼火,你只想得到答案,你需要反思一下,这是某些最美丽想法的一部分,它们需要大量的深思才能真正理解。

在这种情况下,当你向列表前端添加项目时,你会发现有一个非常自然的位置来添加它们。例如,在添加数字3和9之后,我们会说哨兵的下一个是指向3,这是我们添加的第一个项目,然后它的下一个是指向9,再接下来是指向哨兵。因此,实际上就像地球是圆的一样,如果我沿着一个方向不断前进,最终会回到起点。例如,如果我对哨兵执行.next.next.next,我就会回到起点。因此,虽然这个想法可能看起来更令人困惑,有点傻,但我鼓励你在做项目一时采用这种方法,正确地理解山顶和尚的智慧,这样你就能获得顿悟。这就是关于双向链表的拓扑改进的全部内容。

总结一下,改进是为最后一个项目添加一个.last指针,并让所有节点都向后看,但是这个问题在于每个方法都出现了特殊情况,因为这种特定情况。为了避免每个方法中的这些特殊情况,我们可以通过拥有两个哨兵或使列表循环来解决。这是我推荐用于project 1的方法,因为它很酷。
总结我们在前一讲中所做的所有事情,我们对SLList进行了1到6的改进,在这一讲中,我们对DLList进行了7和8的改进。因此,还有很多其他功能,比如添加异常等,我们需要加入才能与Java等内置的链表相匹敌。
拓展列表类型到string,double等等,这节没有什么明显的重点


两级视频都需要总结汇总

在 Java 中,像类和数组几乎总是使用 new 关键字进行实例化。对于字符串,我们可以不使用 new。对于数组来说,大多数情况下会使用 new。在 Java 中,有三种定义数组的语法,第一种是简单地创建一个数组,但不指定值。
这第一种语法是变量 x,假设之前已经声明过,我想把它放入一个 64 位的框中,里面存放的是我正在创建的数组的地址。这个数组将由三个 32 位的盒子组成。对于 Java 中的数组,当你创建一个数组时,它会获得一个默认值,我们将通过可视化来看看这是什么意思。
第二种语法是 x = new int[] { ... },这里我们可以放入实际的默认值。在这种情况下,我们没有明确说明数组的大小,但 Java 能够智能地判断出,我们想要一个大小为 5 的数组,并将这些值填入其中。请注意,当你在 Java 中创建一个数组时,它总是会获得一个默认值,所以如果你说 new int[1000000],它会分配一百万个盒子,并将它们都写成零,这在创建数组时会有一些开销。
接下来是我们的最后一种略显奇怪的语法,它与上面的语法相似,但我们不使用 new int。有趣的是,这种语法只有在同时声明变量时才能使用。例如,我可以说 int[] y,这样我在声明的同时就可以不使用 new 关键字进行实例化。为什么会这样呢?我也不知道,但请注意,你不能将这种语法与已经声明的变量一起使用。
这三种语法都做同样的事情:它们创建一个数组,有一些链接,并且有 n 个盒子。对于那些对底层实现感兴趣的人,可以想象一个数组大约是 32 位的链接加上每个盒子 K 位,总共是 32 + K * n。在典型的实现中,实际上可能会多出一些。
public class ArrayBasics {
/**
* ArrayBasics
*/
public static void main(String[] args) {
int[] z = null;
int[] x, y;
x = new int[]{1, 2, 3, 4, 5};
y = x;
x = new int[]{-1, 2,5,4, 99};
y = new int[3];
z = new int[0];
int xL = x.length;
String[] s = new String[6];
s[4] = "ketchup";
s[x[3] - x[1]] = " muffins";
int[] b = {9, 10, 11};
System.arraycopy(b, 0, x, 3, 2);
}
}好,现在我们通过一个例子来演示。我想你在project0和本讲座中看到的内容,你可以逐步完成并绘制一个漂亮的盒子和指针图,除了最后一步。让我们运行这个例子,你可以跟着我的步骤,尝试猜测会发生什么。在java visualizer
代码开始于 x = new int[5],这将创建一个 64 位的盒子,里面存放的是一个地址。Java 类型只有九种:八种基本类型和一种引用类型,这里存放的是对整数的引用。所以我们有 64 位的盒子,里面全是零。
接下来,我们还会给 x 和 y 这两个盒子分配 64 位,但可视化工具没有显示这两个盒子,但你可以想象它们在这里。然后我们说 x = new int[5],我们找一个内存位置来存放五个整数,得到这个位置的地址,然后 x 将记录这个数组的内存地址。
注意,工具没有明确显示存储数组链接的整数,但它确实存在。接下来,y = x 会复制位,因此 y 和 x 将指向同一个对象。
然后,我们说 y = new int[3],这意味着我们会丢弃这些位,替换为新的大小为 3 的数组的地址。这里有趣的地方是,创建一个array,都是默认值0,就像class一样。

下一步,创建一个字符串数组的挑战:你能猜出创建了多少个盒子吗?这很简单,每个盒子中有多少位?答案是六个盒子,每个盒子 64 位,,都保持字符串引用和默认值为零(也就是 null)。所以我们得到六个 64 位的盒子,每个盒子可以存放字符串引用,默认值为全零。然后我们进入这个数组,获取第四个盒子的值,并将其赋值为新的字符串ketchup。然后就是muffins
接下来,创建一个整数数组 b,这与之前一样,但现在多了一个 System.arraycopy 的调用,System.arraycopy 的作用是从数组 b 复制到数组 x,从位置 0 开始,并复制到 x 的位置 3。这个语法有点难以记住,但基本上,它会从 b 的 0 位置开始复制两个数字到 x 的位置 3。在python就是x[3:5]=b[0:2] 5个 源数组,源头中的起始位置,目标序列,目标的起始位置,复制编号
为什么我们需要复制一个数组呢?单纯的 y = x 只是将数组的引用从一个变量复制到另一个变量,这会导致两个引用指向同一个数组。如果我们想写一个非破坏性的函数,传入一个数组并对每个元素进行平方,就必须以某种方式复制它,否则会破坏原始数组。
这里有两种复制方式:一种是逐项复制,另一种是使用 array copy。System.arraycopy 采用五个参数,它会从数组 b 复制,起始索引为 0,目标数组为 x,目标位置为 3,复制两个元素。
使用 arraycopy 的优势在于,特别是对于大型数组,性能可能更好,因为 Java 解释器更接近硬件,所以它可以利用更底层的知识进行优化。同时,代码也更简洁,易于阅读,但有人可能会觉得不容易理解,因为需要记住所有参数的含义。
2D arrays
作为对我们对数组深入理解的测试,让我们来谈谈Java中的二维数组。虽然我们不会在课堂上立即使用这些内容,但为了让大家熟悉它们,今天我们先来了解一下。
public class ArrayBasics2 {
public static void main(String[] args) {
int[][] pascalsTriangle;
pascalsTriangle = new int[4][];
int[] rowZero = pascalsTriangle[0];
pascalsTriangle[0] = new int[]{1};
pascalsTriangle[1] = new int[]{1, 1};
pascalsTriangle[2] = new int[]{1, 2, 1};
pascalsTriangle[3] = new int[]{1, 2, 3, 1};
int[] rowTwo = pascalsTriangle[2];
rowTwo[0] = -5;
int[][] matrix;
matrix = new int[4][];
matrix = new int[4][4];
int[][] pascalAgain = new int[][]{{1}, {1, 1}, {1, 2, 1}, {1, 3, 3, 1}};
}
}这里我将展示一些代码,直接跳到可视化部分,这将允许我们创建数组引用的数组。在Java中,创建通常所说的二维数组的语法如下:当我写下 int[][] 时,它表示的是一个整型数组引用的数组。
因此,这里我们得到一个盒子,它可以存储一个整型数组引用的列表。让我们来看一个例子。当我说 pascalTriangle = new int[3][]; 时,这将会创建一个整型数组引用的数组,每个元素都可以指向一个数组。这里的 64 位地址是这个数组引用数组的地址。不用担心细节,正如我们可以随时创建这些盒子类型的变量一样,每个盒子在这里的类型都是整型数组引用,所以我可以创建一个新的这样的变量并赋值为它的副本。

接下来,我有一个更有趣的例子。比如说,我不希望这些引用为空,实际上我希望它们指向整型数组,因为这就是它们的作用。所以我们将要创建一个大小为1的数组,该数组包含值1,并将这个引用指向(我们的可视化工具将为我们完成这一操作)。下一步,我不希望这个引用为空,所以我要创建一个大小为2的新数组,并将这个引用指向它。这种画法可能有点奇怪,但就是这样。现在我们说,同样的道理,我们要重复这个过程,创建两个更多的整型数组并将它们的引用指向这里。
ps:实际上,如果你稍后自己进行可视化,为了方便参考,有一个选项是偏好非嵌套布局,这样我们会得到盒指图,同时也会有垂直布局。所以如果我们现在重新运行,可能会更容易阅读。
接下来我们看到这一行代码,它创建了一个64位的盒子,可以存储一个整型数组的引用,然后我们将这个引用指向 pascalTriangle[2]。我们做了什么?我们复制了引用。这个箭头指向了 pascalTriangle[2]。有趣的是,这意味着我们实际上可以通过这个引用修改原始的 pascalTriangle 对象。当你考虑它时,你可以认为这是一个数组序列,被称为帕斯卡三角形,我可以实际地获得其中间的一个引用,就像进入帕斯卡三角形的内部,例如,我可以设置 roadTo[1] = -5。请注意这是可能的,因为总是有其他的方式来实例化一个数组。
我们已经看到了这种方式,如果我们说 matrix = new int[3][4]; 实际上我的首选是垂直布局。创建这样一个数组的一种方法是我们之前见过的语法,所以它会像我们之前看到的一样,创建一个数组引用的数组,但是Java实际上还允许我们在括号内指定一个数字。这个数字的意思是,我不只是想要一堆空的数组引用,我还希望Java为我创建一个默认大小为4的数组,这些数组都将获取该类型的默认值。换句话说,这个新的矩阵声明不仅会创建一个整型引用的数组,还会创建这些实际的整型数组。因此,这条线创建了一个数组,而实际上创建了五个数组:一个引用数组加上四个整型数组。如果你想要创建一个字面量数组,如果你决定不想用这么冗长的方式声明帕斯卡三角形,那么对于二维数组有一个字面量表示法。在这种情况下,我们只会以稍微不同的方式排列相同的东西。
 这就是使二维数组成为二维数组的核心所在,实际上是引用的引用。你可能会觉得这有点难以完全理解,但没关系,因为当我们做名为“接缝雕刻”的作业时,你会有更好的理解。这只是重复了一些我在前面演示中提到的要点。所以,非常第一行创建了一个64位的盒子,可以引用一个整型数组。而下一行在这个案例中创建了四个额外的盒子,每个都是空的。所以这是一个盒子,下面是四个盒子。如果我们看看这一行,只是为了挑出它做了什么,总的来说,它首先创建了一个有三个盒子的数组,将数字1、2、1放入其中,然后将地址分配给这个盒子。
这就是使二维数组成为二维数组的核心所在,实际上是引用的引用。你可能会觉得这有点难以完全理解,但没关系,因为当我们做名为“接缝雕刻”的作业时,你会有更好的理解。这只是重复了一些我在前面演示中提到的要点。所以,非常第一行创建了一个64位的盒子,可以引用一个整型数组。而下一行在这个案例中创建了四个额外的盒子,每个都是空的。所以这是一个盒子,下面是四个盒子。如果我们看看这一行,只是为了挑出它做了什么,总的来说,它首先创建了一个有三个盒子的数组,将数字1、2、1放入其中,然后将地址分配给这个盒子。
这就是整个集合,在这个一之前创建了一个总数组,这里是五个数组。一些术语的亮点可能听起来不是特别有趣,但你可以说服自己这些陈述的真实性。现在,我想给你一个练习,让你思考一下。知道我们刚刚说的,仅仅看着我做这些可能不会带来很大的理解,我想要你告诉我,当这段代码运行并创建这些其他变量时,x[0][0] 和 w[0][0] 的值会是什么,当代码执行完毕时。在这种情况下,我想要你们做的是,如果你想查看答案,点击答案链接;如果你真的不喜欢去网站打开幻灯片并点击链接,我已经把它放在顶部了,所以你可以直接输入。
Arrays vs classes
 当涉及到实现数据结构,比如列表、集合、映射或其他一些东西时,数组和类都可以用来组织一系列的内存单元。它们有不同的风格,例如,对于行星类,我们有一系列命名的字段,这里我构造了一个名为地球的行星,它有一个字符串类型的名字和一个双精度浮点数类型的质量。相比之下,数组是一组编号的内存单元序列,所有元素必须是相同的类型,如果我们想要访问它们,就使用方括号表示法。而类中的字段可以是不同的类型,我们使用点表示法来访问它们。在这两种情况下,我们都有一组固定数量的内存单元,这个数量在Java语言中是不能改变的,其他语言可能会更宽松。
当涉及到实现数据结构,比如列表、集合、映射或其他一些东西时,数组和类都可以用来组织一系列的内存单元。它们有不同的风格,例如,对于行星类,我们有一系列命名的字段,这里我构造了一个名为地球的行星,它有一个字符串类型的名字和一个双精度浮点数类型的质量。相比之下,数组是一组编号的内存单元序列,所有元素必须是相同的类型,如果我们想要访问它们,就使用方括号表示法。而类中的字段可以是不同的类型,我们使用点表示法来访问它们。在这两种情况下,我们都有一组固定数量的内存单元,这个数量在Java语言中是不能改变的,其他语言可能会更宽松。
 让我们想象一下这两种方式之间真正的不同是什么,这里有什么哲学上重要的区别呢?其中一个非常大的区别是,我们可以实际上在运行时计算出数组的索引。想象以下情况,我们构造了一个整数数组,然后询问用户“你想要哪个索引?”假设我们运行这个程序(虽然我现在不会现场演示),它会问:“你想要哪个索引?”我们编译并运行这个程序,也许输入数字2,那么我们现在有了一个感兴趣的索引——这是在编译时不知道的。然后我们可以说:“给我返回这个数组中的第2个元素”,当我们打印出来时,会得到102。相反,对于类来说,我们不能在运行时计算这些字段。例如,假设我们有兴趣的字段是质量,然后我们尝试获取这个感兴趣的字段。在这种情况下,而不是询问用户,我只是将字符串硬编码到这个字段中。当试图从地球对象中获取感兴趣字段时,类会说:“不行,这不是我的字段。”编译器也会说:“不行,你不能说地球.感兴趣字段,这是不允许的。”原因是Java就是这样设计的,你不能随意指定一个特定的字段并获取它。语言就是这样设计的,会说需要数组,但找到了一个行星对象。你可能会尝试变得更聪明,说我将使用点表示法,因为我知道这应该是类的情况。但在这种情况下,当我输入地球.感兴趣字段时,我会得到一个错误,意思是找不到名为感兴趣字段的东西,它是行星类的一部分,但请注意,我有质量,我有名字,我没有感兴趣字段。所以在Java中,你就是不能这样做。不过,我稍微撒了个谎,因为技术上有一种方法可以做到这一点,如果你愿意,可以点击这个链接了解所谓的反射API,但这不是被认为好的风格。
让我们想象一下这两种方式之间真正的不同是什么,这里有什么哲学上重要的区别呢?其中一个非常大的区别是,我们可以实际上在运行时计算出数组的索引。想象以下情况,我们构造了一个整数数组,然后询问用户“你想要哪个索引?”假设我们运行这个程序(虽然我现在不会现场演示),它会问:“你想要哪个索引?”我们编译并运行这个程序,也许输入数字2,那么我们现在有了一个感兴趣的索引——这是在编译时不知道的。然后我们可以说:“给我返回这个数组中的第2个元素”,当我们打印出来时,会得到102。相反,对于类来说,我们不能在运行时计算这些字段。例如,假设我们有兴趣的字段是质量,然后我们尝试获取这个感兴趣的字段。在这种情况下,而不是询问用户,我只是将字符串硬编码到这个字段中。当试图从地球对象中获取感兴趣字段时,类会说:“不行,这不是我的字段。”编译器也会说:“不行,你不能说地球.感兴趣字段,这是不允许的。”原因是Java就是这样设计的,你不能随意指定一个特定的字段并获取它。语言就是这样设计的,会说需要数组,但找到了一个行星对象。你可能会尝试变得更聪明,说我将使用点表示法,因为我知道这应该是类的情况。但在这种情况下,当我输入地球.感兴趣字段时,我会得到一个错误,意思是找不到名为感兴趣字段的东西,它是行星类的一部分,但请注意,我有质量,我有名字,我没有感兴趣字段。所以在Java中,你就是不能这样做。不过,我稍微撒了个谎,因为技术上有一种方法可以做到这一点,如果你愿意,可以点击这个链接了解所谓的反射API,但这不是被认为好的风格。
 因此,在Java中,当你使用一个类时,访问类成员的唯一简单方法就是我所说的硬编码点表示法。例如,如果我想获取质量,我只能通过说P.质量来实现,我不能说P.感兴趣字段或P[感兴趣字段],这都不会工作。所以,Java编译器最终的想法是,它不会将点号两边的任何东西视为表达式,它不会实际评估这个东西,因此这不会工作。如果你对这类哲学问题感兴趣,比如说你是一个喜欢深入思考的人,我鼓励你以后学习编译器或编程语言课程,这将更深入地探讨这些问题的哲学背景。当然,如果你想做一些奇怪的事情,也是可能的,但是Java不允许这样做,主要是因为它保持代码的简洁性。反射会导致丑陋的代码、奇怪的代码。如果Java真的允许你这样做,它会引起很多麻烦。因此,Java的设计者说不,并决定如果你真的想这样做,可以使用反射API,但大家都知道,使用反射来做这种事情被认为是极差的风格,原因很简单,在大型程序中,这只是你需要考虑的额外事情之一。所以语言被设计成限制你可以做出的选择,这再次成为了支持Java的一个强有力的理由。好了,这就是这些视频的全部内容,接下来我们将开始构建基于数组的...
因此,在Java中,当你使用一个类时,访问类成员的唯一简单方法就是我所说的硬编码点表示法。例如,如果我想获取质量,我只能通过说P.质量来实现,我不能说P.感兴趣字段或P[感兴趣字段],这都不会工作。所以,Java编译器最终的想法是,它不会将点号两边的任何东西视为表达式,它不会实际评估这个东西,因此这不会工作。如果你对这类哲学问题感兴趣,比如说你是一个喜欢深入思考的人,我鼓励你以后学习编译器或编程语言课程,这将更深入地探讨这些问题的哲学背景。当然,如果你想做一些奇怪的事情,也是可能的,但是Java不允许这样做,主要是因为它保持代码的简洁性。反射会导致丑陋的代码、奇怪的代码。如果Java真的允许你这样做,它会引起很多麻烦。因此,Java的设计者说不,并决定如果你真的想这样做,可以使用反射API,但大家都知道,使用反射来做这种事情被认为是极差的风格,原因很简单,在大型程序中,这只是你需要考虑的额外事情之一。所以语言被设计成限制你可以做出的选择,这再次成为了支持Java的一个强有力的理由。好了,这就是这些视频的全部内容,接下来我们将开始构建基于数组的...