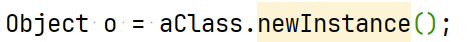1. 算法题:路径总和三
求一棵树中所有路径和为targetsum的值,其实有点像和为k的数组,用前缀和来做
先求出前缀和数组,再类似两数之和问题,每次插入一个数,如果target-当前数在哈希表里存在,更新;
搞不懂啊,真搞不懂
想到了,遍历到每个节点时,实际上不是树,就是一条路径而已,所以和数组差不多,只不过外面要用dfs来套,而且前缀和遍历左边和右边数组要记得更新一下前缀和
(代码没写)
2. xgboost如何对两个指标做预测?
本身xgb无法做多目标排序模型的,如果要用多目标排序模型的思路,就是将xgboost当成一个专家(?)也不行,xgb预测出来的是一个值,而不是多个值
用MultiOutputRegressor是可以做多任务回归的。但似乎本质上还是多个模型预测多个值。
可行方法:将多个目标线性组合成一个目标 比如点击率和完播率
点击率的label一般是0/1,完播率的label是10%,20%这样
就可以建模
3. 完播率如何建模?
(1)视频播放时长建模
播放时长建模是去直接预估一个播放时长,不是0-1之间的,而是一个时长值
按照王树森的说法,标签是历史数据,假设历史数据中,用户看了t分钟,那么标签y=t/(1+t).
而模型预估出一个值z(z不是01之间的,是随便一个数),然后算出一个概率p,p=exp(z)/(1+exp(z)),用p拟合y,这样p越接近y,exp(z)就越接近播放时长。
预测的时候,就用模型输出的值z,计算exp(z) 来预估播放时长。
(2)视频完播率预估
有两种方法建模,一是回归方法,比如10min视频看了4min,标签y=0.4
用交叉熵来预估
(所以说在推荐中,交叉熵是可以用在回归任务的)
二是二元分类方法,假设完播率>80%是正样本,<80%是负样本,用二分类来算
但是算出的结果还是01之间的连续值。。因为要拿来排序啊
但是最后在排序的时候,不能直接拿完播率去排序
预估分数=预估完播率/f(视频长度)
这里f是一个负增长函数,视频长度越长,f越小,预估分数越大。
(这个f具体怎么算的?)
但是还有个问题,我既然是实际用到了xgb,那我用xgb是如何预测一个值的?也就是回归问题?我到底用xgb预测了完播率了吗?
3. 分类损失函数有哪些?针对负样本构建的有哪些?
(1)交叉熵损失
(2)Hinge loss:用于SVM中找最大间隔的场景
(3)balanced cross entropy:用于处理类别不均衡样本的问题,降低易分类样本的权重,强调难分类样本。对正负样本设置不同权重,权重值为正负样本的比例。
但是缺点在于,难以区分简单、难分样本
(4)Focal loss:用于处理正负样本比例失调的情况。bce的改进多增加了一个调制因子,控制简单、难分样本数量失衡。

4. 回归损失函数有哪些?
(1)均方误差损失函数:MSE

(2)L1距离(平均绝对误差,MAE)

(3)RMSE:均方根误差
MSE开根号
(4)Huber 损失(Huber Loss)

5. 我在cv项目里考虑用过的损失函数有哪些?
(1)sMAPE
sMAPE 对称平均绝对百分比误差(symmetric Mean Absolute Percentage Error )
(2)梯度loss
(3)SSIM
6. BatchNorm和LayerNorm的区别?什么时候用?

BatchNorm适合cv,因为不同通道之间保证相同分布,Layernorm适合nlp,因为是每个句子之间保证相同分布
7. SSIM、PSNR公式


SSIM是用图像的平均值、标准差、协方差来评估的,更偏重感知的相似
PSNR是用图像的logMSE来评估的,与MSE更类似
8. Xgboost如何做回归模型预测的?
应该每一棵树预测的都是一个值,那这样应该是离散数而不是连续值?
如果是回归任务,就可以借鉴决策树回归的原理(CART树,可以做分类和回归),它是根据分割把数据分成不同的子区域,(分裂条件是MSE最小),然后每个子区域(代表这个节点)计算子区域所有训练样本的平均值,作为这个叶子节点的输出。
如何用一阶导数和二阶导数?是泰勒展开法
导数是相减的导数,不对啊那这个导数是哪个函数的导数?

为啥要用二阶导?因为是用泰勒展开法来估计前向分布算法。
f(x+t) = f(x) + f'(x)*t+1/2*f''(x)t^2;

所以基本上用MSE和交叉熵,都是可以求导的
MSE导数很简单,交叉熵导数就得分类求,是k类和不是k类
9. Deepfm比直接用DNN好在哪?
1. 自动学习特征交互(特别是低阶交互)
- DeepFM中的FM部分:FM 模型擅长建模特征之间的二阶交互(pairwise interactions)。通过因子分解,它能够有效地捕捉特征之间的低阶交互,即使在数据稀疏的情况下,也能很好地学习到不同特征之间的关系。
- 直接使用DNN:DNN 在理论上也可以建模特征交互,但它主要擅长学习高阶、复杂的非线性交互。对于低阶交互,DNN并不具备FM那样的高效性。通常,需要大量数据和训练时间才能让DNN有效地学习到这些简单的二阶交互。(会过拟合)
2. 高效的参数共享和稀疏数据处理
- DeepFM中的FM部分:FM的因子分解机制通过引入隐向量(embedding),使得模型可以在不同特征之间共享参数,从而减小了参数量。这使得FM部分在处理稀疏数据(如点击率预估、广告推荐等场景中常见的高维、稀疏特征)时非常有效。
- 直接使用DNN:DNN对稀疏特征数据的建模通常需要先对特征进行嵌入(embedding),然后输入神经网络。虽然它可以通过层次化结构捕捉到复杂的高阶特征,但对稀疏数据的处理并不像FM那样高效。尤其是在数据量相对较少的情况下,DNN可能过拟合或表现不佳。
3. 端到端训练
- DeepFM:与传统的二阶段模型不同,DeepFM是一个端到端训练的模型,即FM部分和DNN部分共享特征输入,同时进行训练。这意味着特征的低阶交互(由FM建模)和高阶交互(由DNN建模)可以在一个模型中共同学习和优化,提升整体的推荐效果。
- 直接使用DNN:DNN主要依赖神经网络来自动学习特征交互,但对于低阶特征交互的学习没有FM部分那样直接。很多场景下,需要通过特征工程手动构造低阶交互特征来帮助DNN学习。
4. 减少对特征工程的依赖
- DeepFM:通过结合FM和DNN,DeepFM在低阶特征和高阶特征交互的学习上相对自动化,不需要依赖复杂的人工特征工程。FM部分处理低阶交互,DNN部分学习高阶复杂交互,两者互补,使得DeepFM可以更少地依赖手工设计的交互特征。
- 直接使用DNN:通常需要大量的特征工程来提前构建有意义的特征交互,尤其是在模型捕捉不到简单的交互时,工程师需要手动构造这些交互特征,从而增加了工作的复杂性。
5. 模型复杂度与性能权衡
- DeepFM:由于FM部分通过嵌入和因子分解来高效地建模二阶特征交互,其计算复杂度较低,同时DNN部分可以进一步建模复杂的高阶交互,因此DeepFM在复杂度和性能之间达到了较好的平衡。
- 直接使用DNN:虽然DNN能够捕捉高阶的复杂特征交互,但这通常伴随着更高的计算开销和复杂度。此外,DNN需要更多的训练数据来避免过拟合,尤其在面对稀疏数据时,训练DNN可能会较为困难。
6. 数据稀疏性下的性能优势
- DeepFM:对于用户行为数据这种稀疏、类别型特征占主导的场景,FM的嵌入机制特别有效,而DNN部分则可以进一步建模特征的非线性交互。因此,DeepFM在面对高维稀疏数据时表现优异。
- 直接使用DNN:DNN在处理稀疏特征时往往需要更多数据来学习有意义的特征交互,性能可能较为依赖数据量和深度特征工程。
10. python语法:call,iter,getitem,contains
__call__ 方法使得一个类的实例像函数一样可以被调用。换句话说,定义了 __call__ 方法的类的对象可以像函数一样使用。

__iter__ 方法使类的实例可以返回一个迭代器,使得对象可以用于 for 循环或任何需要迭代的地方。

__getitem__ 方法用于使类的实例可以通过索引进行访问,就像访问列表或字典一样。

在这个例子中,my_list[0] 实际上调用的是 my_list.__getitem__(0),从而实现了类似于列表的索引操作。
__contains__ 方法用于定义对象是否包含某个值,使得对象可以用于 in 关键字操作。

11. deepfm里,因子分解的交叉和DNN的交叉有什么区别?
因子分解的交叉是向量维度的,DNN的交叉是位维度的,先把特征concat起来,再输入到网络里,相当于每个值都会做交叉,而因子分解是两个向量计算内积。
12. bert主要结构,和transformer的应用场景有什么区别?
bert是双向编码解码器,transformer的encoder也是双向的,会考虑输入序列每个位置其他位置的信息,能捕捉全局上下文
解码部分是单向的,在机器翻译任务这种,防止未来的信息泄露。
mask的作用?
mask目的是根据上下文预测这些被掩蔽的词,允许模型同时利用上下文信息,理解句子的含义。
mask还可以强化词语之间的联系,捕捉词义的变化。
还可以避免信息泄露,不会完全依赖特定词,而是根据需要来推理,提高模型泛化性。
训练多样性:让模型在训练过程中接触到上下文变体,提高学习的全面性。
13. 实现rotate函数
原地实现方式:
先反转整个数组,再反转左边,再反转右边
反转方法:reserve,原地的话直接交换就行了
14. 过拟合的解决方式:
(1)数据角度:数据增强,变换
(2)模型角度:减少参数数量,降低模型复杂度,用dropout层,剪枝
(3)优化角度:目标函数加上正则化项,惩罚
(4)交叉验证:用k折交叉验证帮助是否过拟合
(5)early stopping:提前停止训练
(6)bagging,boosting提高稳健性
15. stacking?
stacked generalization,堆叠泛化
是指训练一个模型用于组合 (combine)其他各个模型。即首先我们先训练多个不同的模型,然后再以之前训练的各个模型的输出为输入来训练一个模型,以得到一个最终的输出。
Stacking有两层,一层是不同的基学习器(classifiers/regressors),第二个是用于组合基学习器的元学习器
16.Adam用二阶有什么好处?
Adam通过计算梯度的一阶和二阶矩的指数加权平均来调整学习率,从而实现自适应学习。
Adam和RMSprop,动量法都是可以自适应学习率的
矩就是对梯度的期望值
增加二阶矩的好处:
-
自适应学习率:通过计算梯度平方的平均值,Adam能够为每个参数动态调整学习率。这使得算法在不同参数和不同迭代中都能适应变化,特别是对稀疏和噪声数据。
-
稳定性:二阶矩能够平滑梯度的变化,减少更新中的震荡,使优化过程更加稳定。
-
快速收敛:结合一阶和二阶矩,Adam在许多任务中表现出更快的收敛速度,尤其是在复杂的损失面上。
-
减少手动调参:由于学习率是自适应的,通常不需要频繁调整,简化了超参数选择。
17. GRU具体的原理
recurrent CNN为啥不用,不是老早就有了吗
BART
ERINE
BERT-WWM
全卷积
OOV问题
class Animal:
num = 0
def __getattr__(self):
return 1
def __init__(self):
pass
animal = Animal()
print(animal.num)模型蒸馏对于hard label和soft label的区别,分别用什么loss学习
拓扑排序
混合精度训练
R2HF
KMP算法