下面我们讨论另一种关于多样性的观点。我们知道,对被测对象而言,测试输入空间代表的是各种可能的外部环境条件。如果两个测试输入点距离比较远,说明在这两个点上,被测对象所面对的外部环境条件很不一样,所以我们说,这两个点差异性比较大,或者说,多样性比较好;但是如果我们考察被测对象的内部,有可能发现,被测对象在这两个点上的反应是类似的,比如说,执行的都是同一条程序路径。从这个角度看,我们会认为这两个点的差异性并不大,多样性并不好。基于执行档案的测试,就是从这个角度来理解多样性的。
执行档案是什么概念呢?执行档案是一种结构化信息,描述的就是被测对象在某个测试输入点上的反应。比如执行一个用例t,覆盖了被测程序的第1-6行和第8、9行代码:
我们就可以将t的执行档案定义成这样一个向量:
![]()
向量里一共有10个分量,对应被测程序的10行代码,被覆盖的代码行赋值为1,没被覆盖的代码行赋值为0。执行一个用例,就会产生这样一个执行档案。通常情况下,重复执行同一个用例,产生的执行档案是相同的,除非被测对象的行为有一定的随机性。另一方面,同一个执行档案可能对应到多个不同的用例。
所有可能的执行档案构成了一个新的空间,我们叫它执行档案空间。可以说,执行档案空间是测试输入空间的投影,是测试输入空间在被测对象内心世界里的投影:
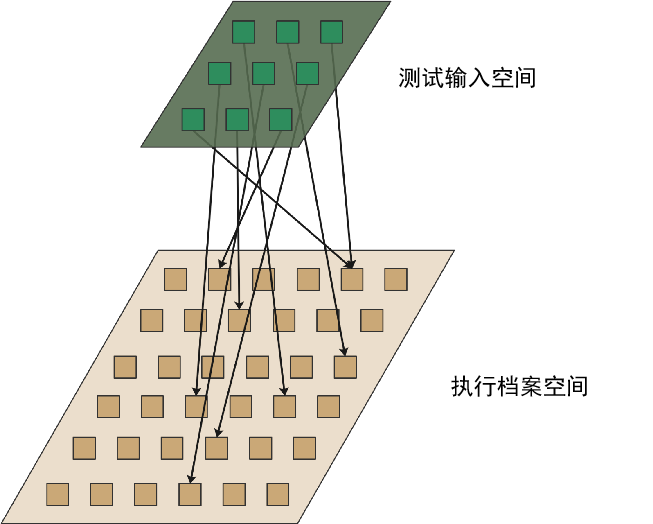
测试输入空间中表现出来的多样性,反映的是被测对象外部环境条件的多样性;而执行档案空间中表现出来的多样性,反映的是被测对象内部行为的多样性。
基于执行档案的测试怎么做呢?举个例子。这是GCC编译器的执行档案空间:

我们可以利用反随机测试或自适应随机测试的算法,从这里面选择那些差异比较大的点,再回溯到测试输入空间,找到对应的测试输入点,这样就完成了测试选择。可以看到,执行档案空间的右下角,有一小撮不合群的点,很扎眼。实际上,这些点对应的是一类很特殊的、没有经过优化的编译行为。在执行档案空间里,按多样化的原则来选点的话,一定不会错过这些点。但是如果对应到测试输入空间里,这些点的分布特征就没这么明显了。