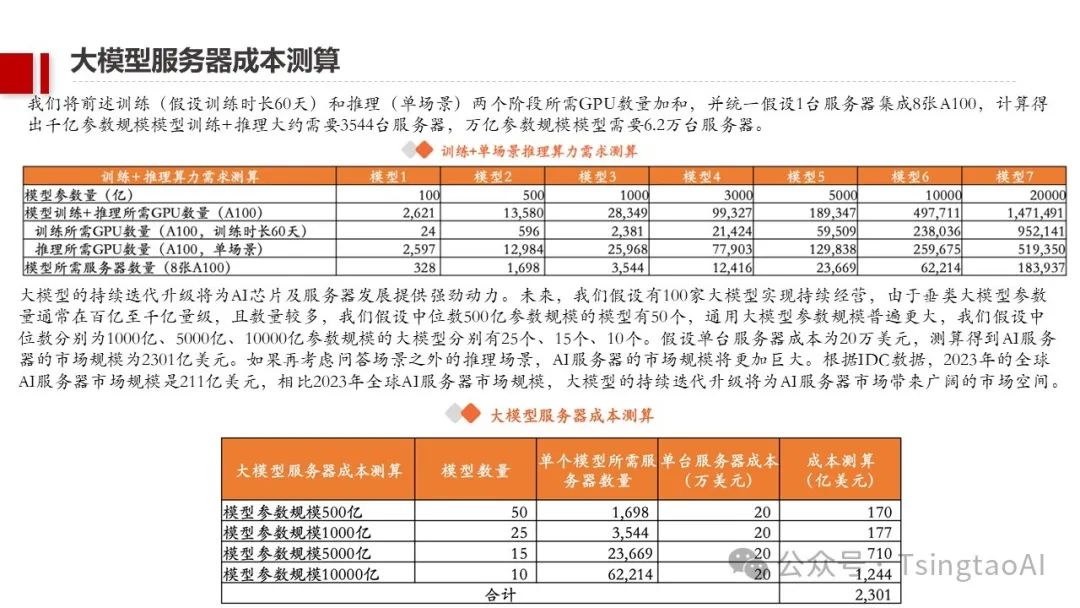
目录
- 实验1 Python语言基础一
- 1、下载安装Python,贴出验证安装成功截图
- 2、建立test.py文件,运行后贴出截图,思考if __name==”__main__”的意思和作用
- 3、分别运行下面两种代码,分析运行结果产生的原因。记牢python中重要语法“tab”的作用。
- 6、编写.py文件,练习元组数据结构的创建和使用。思考当创建元组时单个元素的元组没有加上逗号会发生什么
- 7、编写.py文件,练习列表数据结构的创建和使用
- 8、编写.py文件,练习字典数据结构的创建和使用
- 9、编写.py文件,练习集合数据结构的创建和使用,思考集合与列表和字典的异同
实验1 Python语言基础一
【实验目的】掌握Python及其集成开发环境的下载安装及其简单应用
【实验内容】下载安装Python,实验python基本语法
【实验要求】写明实验步骤,必要时补充截图
1、下载安装Python,贴出验证安装成功截图

2、建立test.py文件,运行后贴出截图,思考if __name==”main”的意思和作用
意思和作用:
__name__是Python中一个内置的特殊变量,当Python文件被直接运行时,__name__的值被设置为 “__main__”,但如果该文件是被其他文件通过 import 语句导入的,__name__
的值则会被设置为该模块的名字(即文件名,不包括 .py 后缀)。 因此,if__name__== “__main__”:
这行代码的作用是:如果这个Python文件被直接运行,那么紧随其后的缩进代码块将被执行;如果这个文件是被导入到其他文件中作为模块使用的,那么这些代码块将不会被执行。
test文件和import_test文件:


分别执行test文件和import_test文件的结果:


3、分别运行下面两种代码,分析运行结果产生的原因。记牢python中重要语法“tab”的作用。

6、编写.py文件,练习元组数据结构的创建和使用。思考当创建元组时单个元素的元组没有加上逗号会发生什么
#例7-1:创建元组
item=('cat',-6,(1,2))
print(item)#('cat', -6, (1, 2))
print(type(item))#<class 'tuple'>
print(item[0],item[1],item[2])#cat -6 (1, 2)
item=('cat')
print(item)#cat
print(type(item))#<class 'str'>
print(item[0])#c
item=('cat',)
print(item)#('cat',)
print(type(item))#<class 'tuple'>
print(item[0])#cat
item=()
print(item)#()
print(type(item))#<class 'tuple'>
创建元组时单个元素的元组没有加上逗号:
①item=(‘cat’,-6,(1,2)):这是一个标准的元组定义,包含三个元素:一个字符串’cat’,一个整数-6,以及另一个元组(1,2)。
②item=(‘cat’):这里你似乎想创建一个只包含一个元素的元组,但由于没有逗号,,Python将其视为一个字符串’cat’,而不是一个元组。
③item=(‘cat’,):这里通过在’cat’后面加上逗号,,明确地告诉Python这是一个元组,即使它只包含一个元素。
④item=():这是一个空元组的定义,它不包含任何元素。
#例7-2:访问元组的元素
fruit=('apple',"banana","grape",'orange')
print(fruit[-1])#orange
print(fruit[-2])#grape
fruit1=fruit[1:3]#切片,从第2个到第3个元素,不包括第4个
fruit2=fruit[0:-2]#切片,从第1个到倒数第2个元素,不包括倒数第2个
fruit3=fruit[2:-2]#切片,从第3个到倒数第2个元素,不包括倒数第2个
print(fruit1)#('banana', 'grape')
print(fruit2)#('apple', 'banana')
print(fruit3)#()
fruit1=("apple","banana")
fruit2=("grape","orange")
fruit=(fruit1,fruit2)
print(fruit)#(('apple', 'banana'), ('grape', 'orange'))
print("fruit[0][1]=",fruit[0][1])#fruit[0][1]= banana#访问第一个元组中的第2个元素
print("fruit[1][1]=",fruit[1][1])#fruit[1][1]= orange#访第二个元组中的第2个元素
print("fruit[1][2]=",fruit[1][2])#访问第二个元组中的第3个元素索引越界,报错
#例7-3:操作元组
t1 =(1,'two',3)
t2 =(t1,'four')
#连接
print(t1+t2)#(1, 'two', 3, (1, 'two', 3), 'four')
#索引
print((t1+t2)[3])#(1, 'two', 3)
#分片
print((t1+t2)[2:5])#(3, (1, 'two', 3), 'four')
#单元素元组
t3=("five",)
print(t1+t2+t3)#(1, 'two', 3, (1, 'two', 3), 'four', 'five')
7、编写.py文件,练习列表数据结构的创建和使用
#例7-5:创建列表
numbers1=[7,-7,2,3,2]
print(numbers1)#[7, -7, 2, 3, 2]
print(type(numbers1))#<class 'list'>
numbers2=[7]
print(numbers2)#[7]
print(type(numbers2))#<class 'list'>
numbers3=[]
print(numbers3)#[]
print(type(numbers3))#<class 'list'>
展示了如何创建不同类型的列表,包括一个包含多个元素的列表、一个只包含一个元素的列表,以及一个空列表。
#例7-6:使用列表
numbers=[7,-7,2,3,2]
print(numbers)#[7, -7, 2, 3, 2]
print(numbers+numbers)#[7, -7, 2, 3, 2, 7, -7, 2, 3, 2]
print(numbers*2)#[7, -7, 2, 3, 2, 7, -7, 2, 3, 2]
# 这里使用了列表的乘法操作,将numbers列表重复两次,结果同样是一个新的列表,
lst=[3,(1,),'dog','cat']
print(lst[0])#3
print(lst[1])#(1,)
print(lst[2])#dog
print(lst[1:3])#[(1,), 'dog']
print(lst[2:])#['dog', 'cat'] # 通过切片访问列表从第三个元素开始到列表末尾的所有元素。
print(lst[-3:])#[(1,), 'dog', 'cat']# 通过负索引和切片访问列表从倒数第三个元素开始到列表末尾的所有元素。
print(lst[:-3])#[3]# 通过切片访问列表从开始到倒数第三个元素之前的所有元素(不包括倒数第三个元素)。
for i in range(len(lst)):#遍历列表lst
print(lst[i],end=' ')
#3 (1,) dog cat
#注意:元组(1,)在输出时会被加上括号,以区分它和整数1。
8、编写.py文件,练习字典数据结构的创建和使用
#例7-19:字典的创建、添加、删除和修改orange'}
dict={'a':"apple",'b': 'banana','g':'grape','o':'orange'} # 创建字典
print(dict)#{'a': 'apple', 'b': 'banana', 'g': 'grape', 'o': 'orange'}
dict['w']='watermelon'#添加字典元素
print(dict)#{'a': 'apple', 'b': 'banana', 'g': 'grape', 'o': 'orange', 'w': 'watermelon'}
del dict['a'] #删除字典中键为'a'的元素
print(dict)#{'b': 'banana', 'g': 'grape', 'o': 'orange', 'w': 'watermelon'}
dict['g']='grapefruit'#修改字典中键为"g’的值
print(dict)#{'b': 'banana', 'g': 'grapefruit', 'o': 'orange', 'w': 'watermelon'}
#例7-20:字典函数的应用
#创建字典
dict={'a':'apple','b':'banana','c':'grape','d':'orange'}
#输出 keys的列表
print(dict.keys())#dict_keys(['a', 'b', 'c', 'd'])
#输出value的列表
print(dict.values())#dict_values(['apple', 'banana', 'grape', 'orange'])
#获取字典中的元素
print(dict.get('c'))#grape
print(dict.get('e'))#None
#字典的更新
dict1={'a':'apple','b':'banana'}
print(dict1)#{'a': 'apple', 'b': 'banana'}
dict2={'c':'grape','d':'orange'}
print(dict2)#{'c': 'grape', 'd': 'orange'}
dict1.update(dict2)
print(dict1)#{'a': 'apple', 'b': 'banana', 'c': 'grape', 'd': 'orange'}
# 将dict2中的键值对更新到dict1中。
# 如果dict2中的键在dict1中已经存在,则对应的值会被dict2中的值覆盖;
# 如果键在dict1中不存在,则这个键值对会被添加到dict1中
9、编写.py文件,练习集合数据结构的创建和使用,思考集合与列表和字典的异同
#例7-24:创建集合
basket =['apple','orange', 'apple', 'pear', 'orange', 'banana']
print(basket)# ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
print(type(basket))# <class 'list'>
# create a set without duplicates
fruit = set(basket)
print(fruit)# {'orange', 'banana', 'apple', 'pear'}
print(type(fruit))# <class 'set'>
# fast membership testing
print('orange'in fruit ) # True
print('crabgrass'in fruit)# False
#例7-25:集合运算
a= set('abracadabra')
b= set('alacazam')
# unique letters in a
print(a) #{'r', 'c', 'd', 'a', 'b'}
# unique letters in b
print(b) #{'c', 'z', 'm', 'l', 'a'}
#差运算# letters in a but not in b
print(a - b)#{'b', 'r', 'd'}
#或运算# letters in either a or b
print(a | b)#{'r', 'c', 'z', 'm', 'd', 'l', 'a', 'b'}
#并运算# letters in both a and b
print(a & b)#{'a', 'c'}
#异或运算# letters in a or b but not both
print(a ^ b)#{'z', 'm', 'r', 'l', 'd', 'b'}
集合与列表和字典的异同:
列表(List) 有序:列表中的元素是有序的,即元素的插入顺序会被保留。 可重复:列表中的元素可以重复。
可变:列表是可变的,可以添加、删除或修改元素。 用途:通常用于需要保持元素顺序的场景,如记录一系列的操作步骤或数据项。
字典(Dictionary) 无序: 字典是无序的,其中的元素没有固定的顺序。 键值对:字典由键值对组成,每个键都是唯一的,但值可以重复。
可变:字典是可变的,可以添加、删除或修改键值对。 用途:通常用于存储具有唯一标识符(键)的数据项,以便快速检索。 集合(Set)
无序:集合中的元素是无序的,即元素的插入顺序不会被保留。 唯一性:集合中的元素必须是唯一的,不能重复。
可变:集合是可变的,可以添加或删除元素,但不能直接修改元素(因为元素是唯一的,修改通常意味着删除旧元素并添加新元素)。
用途:通常用于需要快速检查元素是否存在、去除重复元素或进行数学集合操作的场景(如并集、交集、差集等)。











![[数据结构] 二叉树题目 (二)](https://i-blog.csdnimg.cn/direct/afcc4c2a4ebd48b4bc1a5d62b2cb9192.png)






