文章目录
- 一、实战概述
- 二、图片网站
- 三、爬取图片
- 1、编写程序,实现功能
- 2、运行程序,查看结果
- 四、实战小结
一、实战概述
- 在本实战项目中,我们编写了一个Python程序,用于从指定的图片网站(https://pic.netbian.com/4kfengjing/)爬取图片。程序首先发送HTTP请求获取网页内容,然后利用
lxml库的etree模块解析HTML,通过XPath定位并提取所有<img>标签的src属性,即图片的URL。最后,程序遍历所有图片URL,下载图片并保存到本地目录。运行程序后,我们可以通过控制台输出信息来确认图片是否下载成功,并查看保存在本地的图片。
二、图片网站
- https://pic.netbian.com/4kfengjing/

三、爬取图片
1、编写程序,实现功能
- 创建
爬取网页图片.py程序

'''
功能:爬取网页图片
作者:华卫
日期:2024年9月26日
'''
import requests
from lxml import etree
# 定义网页地址
url = 'https://pic.netbian.com/4kfengjing/'
# 定义headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'
}
# 发送请求,获取网页内容
response = requests.get(url, headers=headers)
content = response.content.decode('gbk') # 根据网页编码方式解码,这里假设为gbk
# 解析网页内容
html = etree.HTML(content)
# 使用XPath提取所有图片链接
img_elements = html.xpath("//img/@src")
# 下载并保存图片
for img_src in img_elements:
# 构建完整的图片URL
img_url = 'https://pic.netbian.com' + img_src if not img_src.startswith('http') else img_src
# 获取图片内容
img_response = requests.get(img_url, headers=headers)
img_content = img_response.content
# 构建图片标题
img_title = img_src.split('/')[-1]
# 保存图片到本地
with open('images/%s.jpg' % img_title, 'wb') as f:
f.write(img_content)
print('图片[{}]下载并保存成功~'.format(img_title))
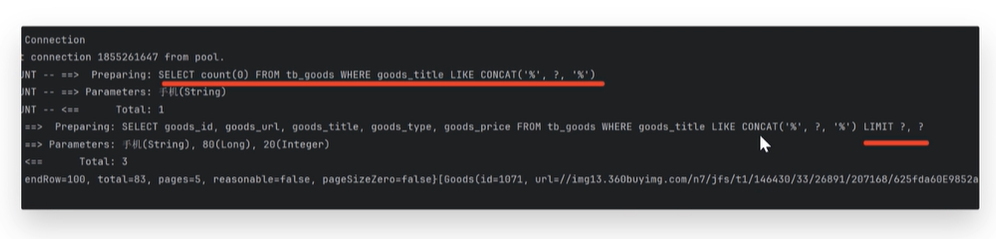
2、运行程序,查看结果
- 查看控制台输出信息

- 查看爬取到本地的图片

四、实战小结
- 在本次实战中,我们成功实现了一个Python脚本,用于从彼岸图网的指定页面爬取4K风景图片。通过分析网页结构,我们利用
requests库获取网页内容,并使用lxml库的XPath功能提取图片URL。脚本下载图片并保存到本地目录,整个过程自动化,无需人工干预。此次实践不仅加深了对Python网络请求和解析库的理解,也锻炼了实际问题解决能力。













![[数据结构] 二叉树题目(一)](https://i-blog.csdnimg.cn/direct/31d50c17f6c446d4878d60f27e621ff0.png)